文章目录
- Flink两阶段提交
- 1.EXACTLY_ONCE语义
- 2.Kafka的幂等性和事务
- 2.1 幂等性
- 2.2 事务
- 3.两阶段提交协议
- 4.TwoPhaseCommitSinkFunction
- 参考文献
Flink两阶段提交
1.EXACTLY_ONCE语义
EXACTLY_ONCE语义简称EOS,指的是每条输入消息只会影响最终结果一次,注意这里是影响一次,而非处理一次,Flink一直宣称自己支持EOS,实际上主要是对于Flink应用内部来说的,对于外部系统(端到端)则有比较强的限制
- 外部系统写入支持幂等性
- 外部系统支持以事务的方式写入
Flink在1.4.0版本引入了TwoPhaseCommitSinkFunction接口,并在Kafka Producer的connector中实现了它,支持了对外部Kafka Sink的EXACTLY_ONCE语义。
2.Kafka的幂等性和事务
Kafka在0.11版本之前只能保证At-Least-Once或At-Most-Once语义,从0.11版本开始,引入了幂等发送和事务,从而开始保证EXACTLY_ONCE语义,下面来看看Kafka中幂等发送和事务的原理:
2.1 幂等性
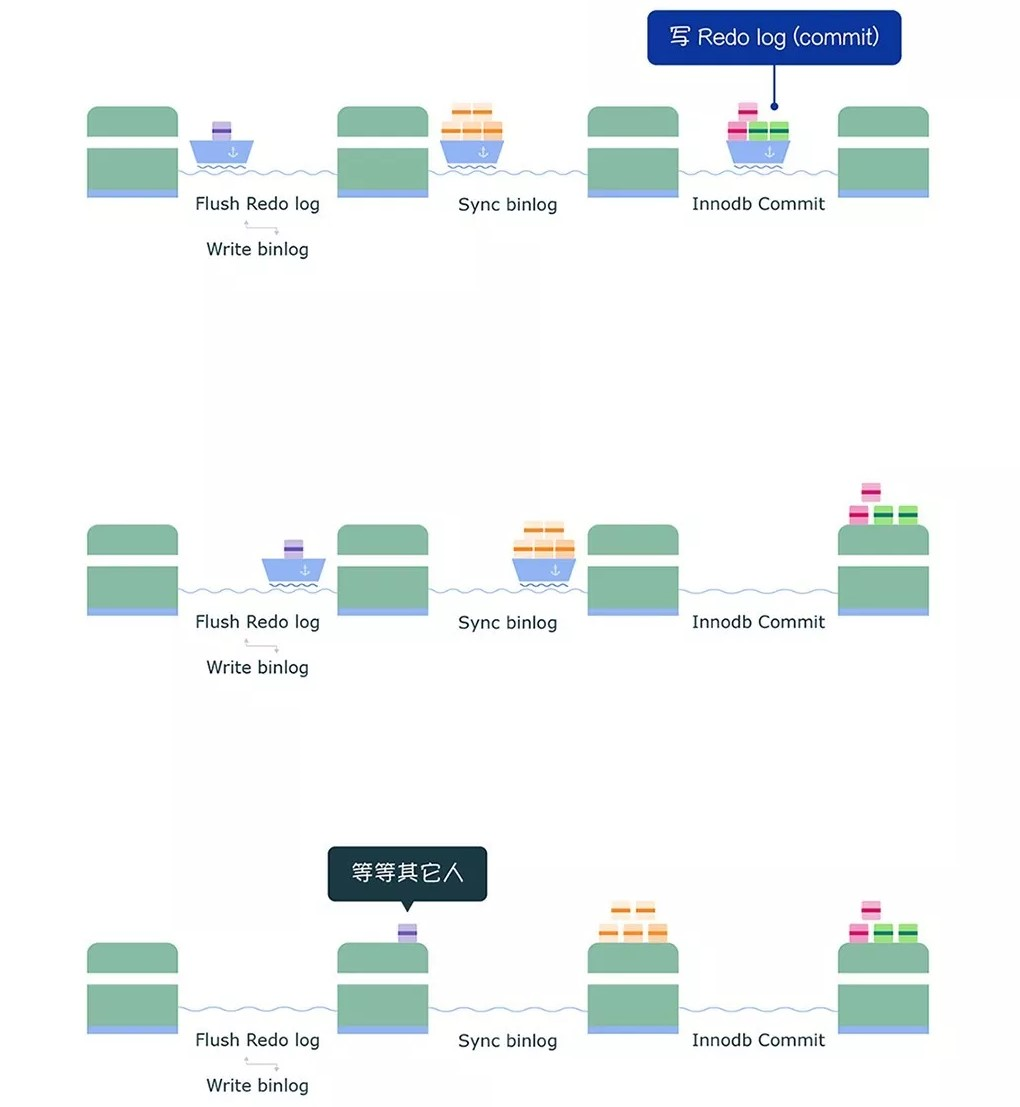
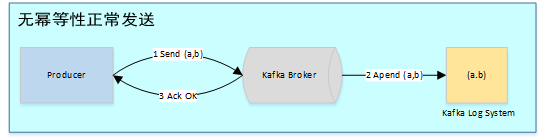
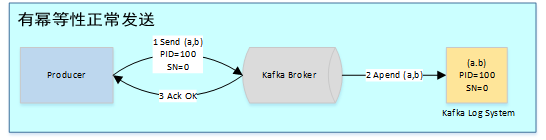
在未引入幂等性时,Kafka正常发送和重试发送消息流程图如下:
为了实现Producer的幂等语义,Kafka引入了Producer ID(即PID)和Sequence Number。每个新的Producer在初始化的时候会被分配一个唯一的PID,该PID对用户完全透明而不会暴露给用户。
Producer发送每条消息<Topic, Partition>对于Sequence Number会从0开始单调递增,broker端会为每个<PID, Topic, Partition>维护一个序号,每次commit一条消息此序号加一,对于接收的每条消息,如果其序号比Broker维护的序号(即最后一次Commit的消息的序号)大1以上,则Broker会接受它,否则将其丢弃:
- 序号比Broker维护的序号大1以上,说明存在乱序。
- 序号比Broker维护的序号小,说明此消息以及被保存,为重复数据。
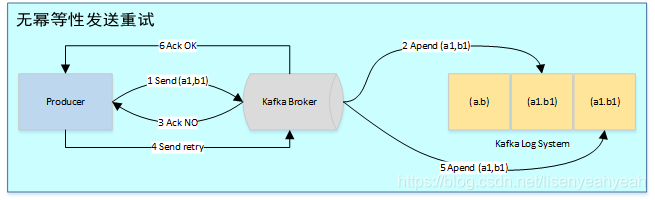
有了幂等性,Kafka正常发送和重试发送消息流程图如下:
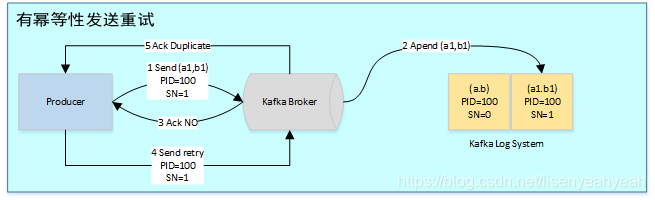
幂等性机制仅解决了单分区上的数据重复和乱序问题,对于跨session和所有分区的重复和乱序问题不能得到解决。于是需要引入事务。
2.2 事务
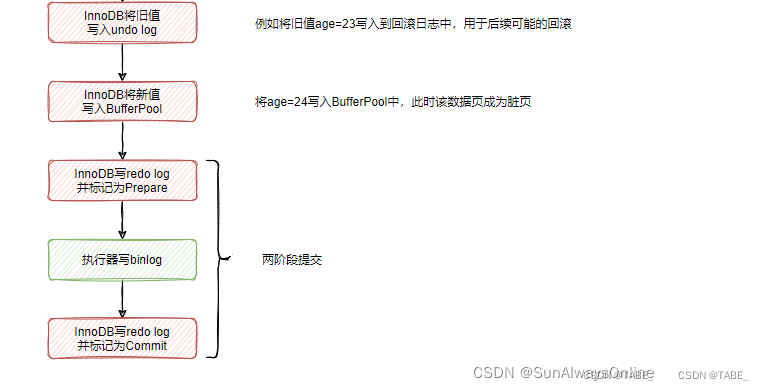
事务是指所有的操作作为一个原子,要么都成功,要么都失败,而不会出现部分成功或部分失败的可能。举个例子,比如小明给小王转账1000元,那首先小明的账户会减去1000,然后小王的账户会增加1000,这两个操作就必须作为一个事务,否则就会出现只减不增或只增不减的问题,因此要么都失败,表示此次转账失败。要么都成功,表示此次转账成功。分布式下为了保证事务,一般采用两阶段提交协议。
为了解决跨session和所有分区不能EXACTLY-ONCE问题,Kafka从0.11开始引入了事务。
为了支持事务,Kafka引入了Transacation Coordinator来协调整个事务的进行,并可将事务持久化到内部topic里,类似于offset和group的保存。
用户为应用提供一个全局的Transacation ID,应用重启后Transacation ID不会改变。为了保证新的Producer启动后,旧的具有相同Transaction ID的Producer即失效,每次Producer通过Transaction ID拿到PID的同时,还会获取一个单调递增的epoch。由于旧的Producer的epoch比新Producer的epoch小,Kafka可以很容易识别出该Producer是老的Producer并拒绝其请求。有了Transaction ID后,Kafka可保证:
- 跨Session的数据幂等发送。当具有相同Transaction ID的新的Producer实例被创建且工作时,旧的Producer停止工作。
- 跨Session的事务恢复。如果某个应用实例宕机,新的实例可以保证任何未完成的旧的事务要么Commit要么Abort,使得新实例从一个正常状态开始工作。
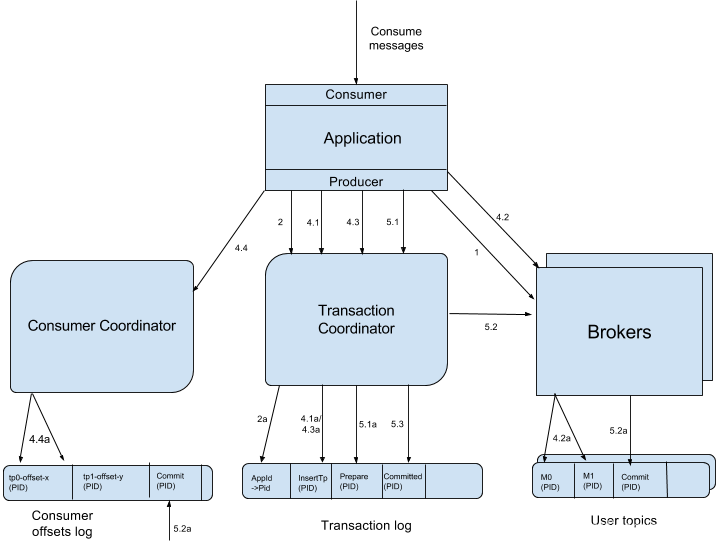
KPI-98对Kafka事务原理进行了详细介绍,完整的流程图如下:
-
Producer向任意一个brokers发送 FindCoordinatorRequest请求来获取Transaction Coordinator的地址
-
找到Transaction Coordinator后,具有幂等特性的Producer必须发起InitPidRequest请求以获取PID。
2.1 当设置了TransactionalId
如果开启了事务特性,设置了TransactionalId,则TransactionalId会和InitPidRequest请求一起传递,并且在步骤2a中将TransactionalId和对应的PID持久化到事务日志中,这使我们能够将TransactionalId的相同PID返回给producer的未来实例,从而使恢复或中止先前未完成的事务成为可能。除了返回PID外,InitPidRequest还会执行如下任务:- 增加该PID对应的epoch。具有相同PID但epoch小于该epoch的其它Producer(如果有)新开启的事务将被拒绝。
- 恢复(Commit或Abort)之前的Producer未完成的事务(如果有)。
注意:InitPidRequest的处理过程是同步阻塞的。一旦该调用正确返回,Producer即可开始新的事务。
2.2 当没有设置TransactionalId
如果事务特性未开启,InitPidRequest可发送至任意Broker,并且会得到一个全新的唯一的PID。该Producer将只能使用幂等特性以及单一Session内的事务特性,而不能使用跨Session的事务特性。 -
调用beginTransaction()方法开启一个事务,Producer本地会记录已经开启了事务,但Transaction Coordinator只有在Producer发送第一条消息后才认为事务已经开启。
-
Consume-Transform-Produce
这一阶段,包含了整个事务的数据处理过程,并且包含了多种请求。4.1 AddPartitionsToTxnRequest
一个Producer可能会给多个<Topic, Partition>发送数据,给一个新的<Topic, Partition>发送数据前,它需要先向Transaction Coordinator发送AddPartitionsToTxnRequest。Transaction Coordinator会将该<Transaction, Topic, Partition>存于Transaction Log内,并将其状态置为BEGIN,如上图中步骤4.1所示。有了该信息后,我们才可以在后续步骤中为每个Topic, Partition>设置COMMIT或者ABORT标记(如上图中步骤5.2所示)。另外,如果该<Topic, Partition>为该事务中第一个<Topic, Partition>,Transaction Coordinator还会启动对该事务的计时(每个事务都有自己的超时时间)。4.2 ProduceRequest
Producer通过一个或多个ProduceRequest发送一系列消息。除了应用数据外,该请求还包含了PID,epoch,和Sequence Number。该过程如上图中步骤4.2所示。4.3 AddOffsetCommitsToTxnRequest
为了提供事务性,Producer新增了sendOffsetsToTransaction方法,该方法将多组消息的发送和消费放入同一批处理内。该方法先判断在当前事务中该方法是否已经被调用并传入了相同的Group ID。若是,直接跳到下一步;若不是,则向Transaction Coordinator发送AddOffsetsToTxnRequests请求,Transaction Coordinator将对应的所有<Topic, Partition>存于Transaction Log中,并将其状态记为BEGIN,如上图中步骤4.3所示。该方法会阻塞直到收到响应。TxnOffsetCommitRequest作为sendOffsetsToTransaction方法的一部分,在处理完AddOffsetsToTxnRequest后,Producer也会发送TxnOffsetCommit请求给Consumer Coordinator从而将本事务包含的与读操作相关的各<Topic, Partition>的Offset持久化到内部的__consumer_offsets中,如上图步骤4.3a
4.4 TxnOffsetCommitRequest
作为sendOffsetsToTransaction方法的一部分,在处理完AddOffsetsToTxnRequest后,Producer也会发送TxnOffsetCommit请求给Consumer Coordinator从而将本事务包含的与读操作相关的各<Topic, Partition>的Offset持久化到内部的__consumer_offsets中,如上图步骤4.4所示。在此过程中,Consumer Coordinator会通过PID和对应的epoch来验证是否应该允许该Producer的该请求。
这里需要注意:- 写入__consumer_offsets的Offset信息在当前事务Commit前对外是不可见的。也即在当前事务被Commit前,可认为该Offset尚未Commit,也即对应的消息尚未被完成处理。
- Consumer Coordinator并不会立即更新缓存中相应<Topic, Partition>的Offset,因为此时这些更新操作尚未被COMMIT或ABORT。
-
提交或回滚事务
一旦上述数据写入操作完成,应用程序必须调用KafkaProducer的commitTransaction方法或者abortTransaction方法以结束当前事务。5.1 EndTxnRequest
commitTransaction方法使得Producer写入的数据对下游Consumer可见。abortTransaction方法通过Transaction Marker将Producer写入的数据标记为Aborted状态。下游的Consumer如果将isolation.level设置为READ_COMMITTED,则它读到被Abort的消息后直接将其丢弃而不会返回给客户程序,也即被Abort的消息对应用程序不可见。无论是Commit还是Abort,Producer都会发送EndTxnRequest请求给Transaction Coordinator,并通过标志位标识是应该Commit还是Abort。
收到该请求后,Transaction Coordinator会进行如下操作
- 将PREPARE_COMMIT或PREPARE_ABORT消息写入Transaction Log,如上图中步骤5.1所示
- 通过WriteTxnMarker请求以Transaction Marker的形式将COMMIT或ABORT信息写入用户数据日志以及Offset Log中,如上图中步骤5.2所示
- 最后将COMMIT或ABORT信息写入Transaction Log中,如上图中步骤5.3所示。
上述第二步是实现将一组读操作与写操作作为一个事务处理的关键。因为Producer写入的数据Topic以及记录Comsumer Offset的Topic会被写入相同的Transactin Marker,所以这一组读操作与写操作要么全部COMMIT要么全部ABORT。
5.2 WriteTxnMarkerRequest
上面提到的WriteTxnMarkerRequest由Transaction Coordinator发送给当前事务涉及到的每个<Topic, Partition>的Leader。收到该请求后,对应的Leader会将对应的COMMIT(PID)或者ABORT(PID)控制信息写入日志,如上图中步骤5.2所示。该控制消息向Broker以及Consumer表明对应PID的消息被Commit了还是被Abort了。
这里要注意,如果事务也涉及到__consumer_offsets,即该事务中有消费数据的操作且将该消费的Offset存于__consumer_offsets中,Transaction Coordinator也需要向该内部Topic的各Partition的Leader发送WriteTxnMarkerRequest从而写入COMMIT(PID)或COMMIT(PID)控制信息。
5.2 写入最终的COMMIT或ABORT消息
写完所有的Transaction Marker后,Transaction Coordinator会将最终的COMMIT或ABORT消息写入Transaction Log中以标明该事务结束,如上图中步骤5.3所示。此时,Transaction Log中大多数关于该事务的消息全部可以移除。当然,由于Kafka内数据是Append Only的,不可直接更新和删除,这里说的移除只是将其标记为null从而在Log Compact时不再保留。
我们只需要保留已完成事务的PID和时间戳,因此最终可以为生产者删除TransactionalId-> PID映射。
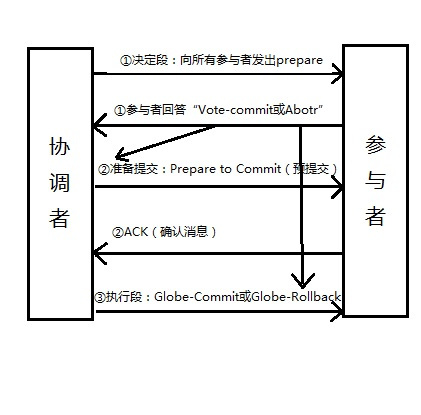
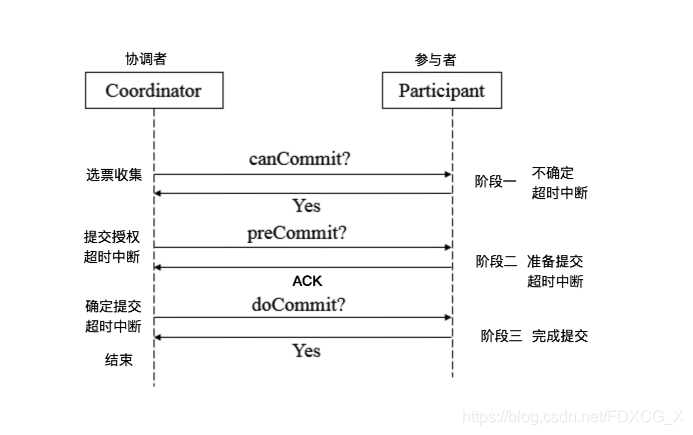
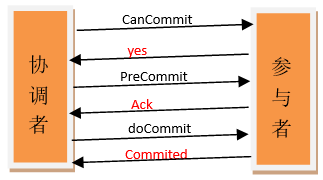
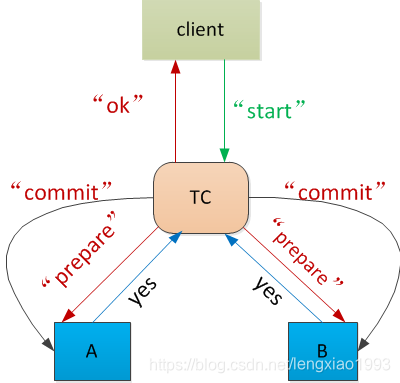
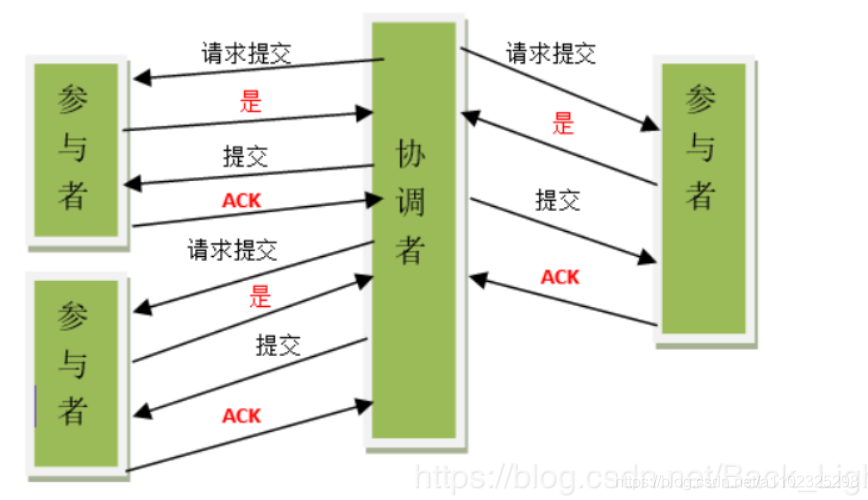
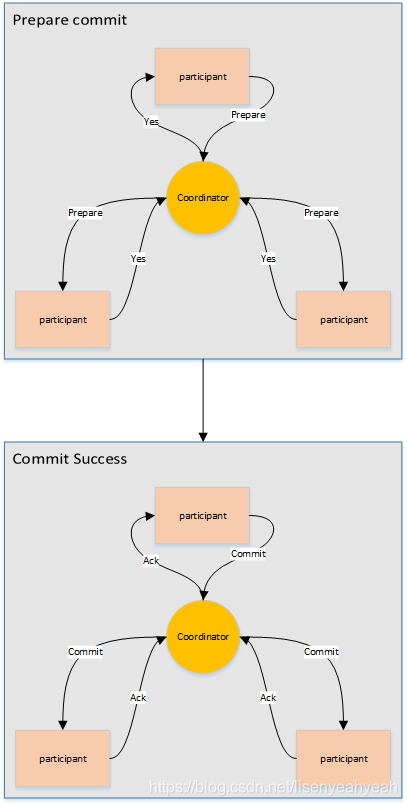
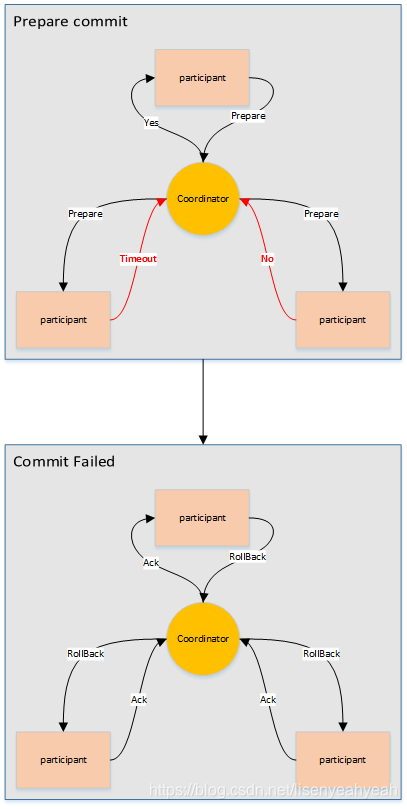
3.两阶段提交协议
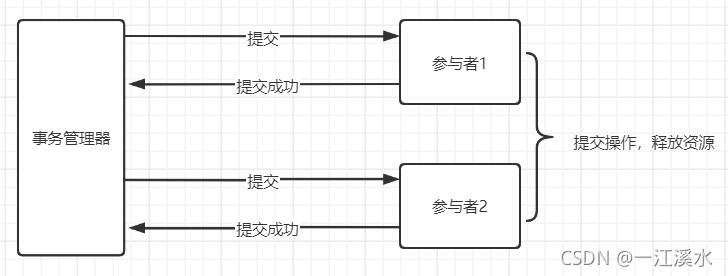
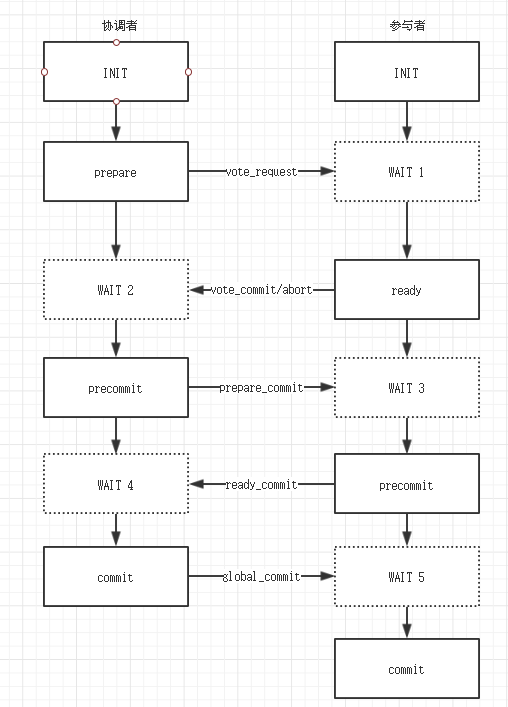
两阶段提交指的是一种协议,经常用来实现分布式事务,可以简单理解为预提交+实际提交,一般分为协调器Coordinator(以下简称C)和若干事务参与者Participant(以下简称P)两种角色。
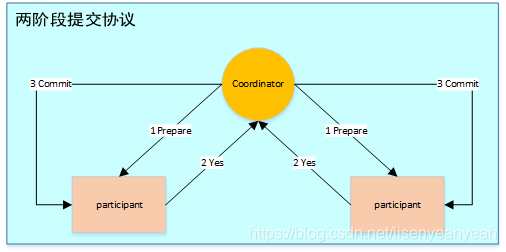
- C先将prepare请求写入本地日志,然后发送一个prepare的请求给P
- P收到prepare请求后,开始执行事务,如果执行成功返回一个Yes或OK状态给C,否则返回No,并将状态存到本地日志。
- C收到P返回的状态,如果每个P的状态都是Yes,则开始执行事务Commit操作,发Commit请求给每个P,P收到Commit请求后各自执行Commit事务操作。如果至少一个P的状态为No,则会执行Abort操作,发Abort请求给每个P,P收到Abort请求后各自执行Abort事务操作。
注:C或P把发送或接收到的消息先写到日志里,主要是为了故障后恢复用,类似WAL
4.TwoPhaseCommitSinkFunction
Flink在1.4.0版本引入了TwoPhaseCommitSinkFunction接口,封装了两阶段提交逻辑,并在Kafka Sink connector中实现了TwoPhaseCommitSinkFunction,依赖Kafka版本为0.11+,TwoPhaseCommitSinkFunction具体实现如下:
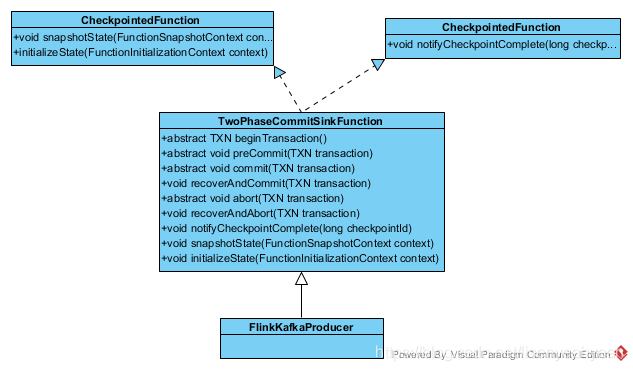
//TwoPhaseCommitSinkFunctionpublic void initializeState(FunctionInitializationContext context) throws Exception {// 当我们通过提交中事务恢复状态时,我们并不知道事务已经提交了,还是在checkpoint执行完成(在master端)和在此处通知checkpoint完成之间失败了。// 通常情况下是已经提交了,因为checkpoint在master执行完成和在此处通知checkpoint完成之间的窗口非常小// 如果在第一次checkpoint完成之前失败,则可能没有任何事务,或者扩容的情况下,会有一部分新的task没有事务// 如果发生缩容事件,或者由于“notifycheckpointcomplete()”方法中讨论的原因,我们可以检查多个事务。state = context.getOperatorStateStore().getListState(stateDescriptor);boolean recoveredUserContext = false;// 从上一次恢复if (context.isRestored()) {for (State<TXN, CONTEXT> operatorState : state.get()) {userContext = operatorState.getContext();List<TransactionHolder<TXN>> recoveredTransactions = operatorState.getPendingCommitTransactions();for (TransactionHolder<TXN> recoveredTransaction : recoveredTransactions) {recoverAndCommitInternal(recoveredTransaction);}recoverAndAbort(operatorState.getPendingTransaction().handle);if (userContext.isPresent()) {finishRecoveringContext();recoveredUserContext = true;}}}if (!recoveredUserContext) {userContext = initializeUserContext();}this.pendingCommitTransactions.clear();//创建生产者事务,并返回句柄currentTransactionHolder = beginTransactionInternal();}public void snapshotState(FunctionSnapshotContext context) throws Exception {long checkpointId = context.getCheckpointId();//预提交,如果语义为EXACTLY_ONCE,执行flush操作preCommit(currentTransactionHolder.handle);//pendingCommitTransactions插入当次检查点对应的currentTransactionHolder,包含事务生产者的实例(对于EXACTLY_ONCE模式)pendingCommitTransactions.put(checkpointId, currentTransactionHolder);//这里又初始化了一次包含事务生产者的实例(对于EXACTLY_ONCE模式),并赋给currentTransactionHoldercurrentTransactionHolder = beginTransactionInternal();//清空statestate.clear();//state.add(new State<>(this.currentTransactionHolder,new ArrayList<>(pendingCommitTransactions.values()),userContext));}public final void notifyCheckpointComplete(long checkpointId) throws Exception {// 可能出现以下几种情况// (1) 从最近的检查点触发并完成的事务恰好只有一个。 这应该很常见,在这种情况下只需提交该事务即可。// (2) 由于上一次checkpoint被跳过导致这里有多个正在进行的事务,这是一种罕见的情况,但可能在以下情况下发生:// - 上一次checkpoint未能持久化metadata(存储系统临时中断)但可以保留一个连续的检查点(此处通知的检查点)// - 其他task未能在上一次checkpoint持久化他们的状态,但未触发失败,因为他们可以保持其状态并将其成功保存在连续的检查点中(此处通知的检查点)// 在这两种情况下,前一个检查点都不会达到提交状态,但此检查点总是希望包含前一个检查点,并覆盖自上一个成功检查点以来的所有更改。因此,我们需要提交所有待提交的事务。// (3) 多个事务处于待提交状态,但检查点完成通知与最新的不相关。这是可能的,因为通知消息可能会延迟(在极端情况下,直到触发下一个检查点之后到达)并且可能会有并发的重叠检查点(新的检查点在上一个完全完成之前启动)。// ==> 永远不会有我们这里没有待提交事务的情况//待提交的事务版本和事务句柄Iterator<Map.Entry<Long, TransactionHolder<TXN>>> pendingTransactionIterator = pendingCommitTransactions.entrySet().iterator();Throwable firstError = null;while (pendingTransactionIterator.hasNext()) {Map.Entry<Long, TransactionHolder<TXN>> entry = pendingTransactionIterator.next();Long pendingTransactionCheckpointId = entry.getKey();TransactionHolder<TXN> pendingTransaction = entry.getValue();if (pendingTransactionCheckpointId > checkpointId) {continue;}try {//提交事务(最终调用commitTransaction)commit(pendingTransaction.handle);} catch (Throwable t) {//}pendingTransactionIterator.remove();}}
//FlinkKafkaProducer011public void initializeState(FunctionInitializationContext context) throws Exception {//如果检查点未开启,语义设置为NONEif (semantic != Semantic.NONE && !((StreamingRuntimeContext) this.getRuntimeContext()).isCheckpointingEnabled()) {semantic = Semantic.NONE;}nextTransactionalIdHintState = context.getOperatorStateStore().getUnionListState(NEXT_TRANSACTIONAL_ID_HINT_DESCRIPTOR);//初始化事务ID生成器transactionalIdsGenerator = new TransactionalIdsGenerator(getRuntimeContext().getTaskName() + "-" + ((StreamingRuntimeContext) getRuntimeContext()).getOperatorUniqueID(),getRuntimeContext().getIndexOfThisSubtask(),getRuntimeContext().getNumberOfParallelSubtasks(),kafkaProducersPoolSize,SAFE_SCALE_DOWN_FACTOR);if (semantic != Semantic.EXACTLY_ONCE) {nextTransactionalIdHint = null;} else {//如果为EXACTLY_ONCE语义,初始化nextTransactionalIdHint(初始化lastParallelism和nextFreeTransactionalId为0),后面用来生成多个事务IDArrayList<NextTransactionalIdHint> transactionalIdHints = Lists.newArrayList(nextTransactionalIdHintState.get());if (transactionalIdHints.size() > 1) {} else if (transactionalIdHints.size() == 0) {nextTransactionalIdHint = new NextTransactionalIdHint(0, 0);abortTransactions(transactionalIdsGenerator.generateIdsToAbort());} else {nextTransactionalIdHint = transactionalIdHints.get(0);}}//调用父类的initializeState方法super.initializeState(context);}public void snapshotState(FunctionSnapshotContext context) throws Exception {//调用父类的snapshotState方法super.snapshotState(context);//清空nextTransactionalIdHintStatenextTransactionalIdHintState.clear();//避免每个task上做同样的操作,这里只在第一个task上完成nextFreeTransactionalId的初始化if (getRuntimeContext().getIndexOfThisSubtask() == 0 && semantic == Semantic.EXACTLY_ONCE) {long nextFreeTransactionalId = nextTransactionalIdHint.nextFreeTransactionalId;if (getRuntimeContext().getNumberOfParallelSubtasks() > nextTransactionalIdHint.lastParallelism) {nextFreeTransactionalId += getRuntimeContext().getNumberOfParallelSubtasks() * kafkaProducersPoolSize;}nextTransactionalIdHintState.add(new NextTransactionalIdHint(getRuntimeContext().getNumberOfParallelSubtasks(),nextFreeTransactionalId));}}
Flink Kafka Sink执行两阶段提交的流程图大致如下:
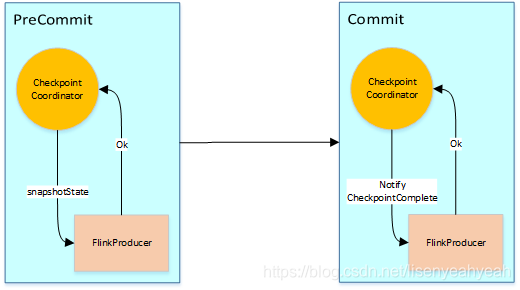
假设一种场景,从Kafka Source拉取数据,经过一次窗口聚合,最后将数据发送到Kafka Sink,如下图:
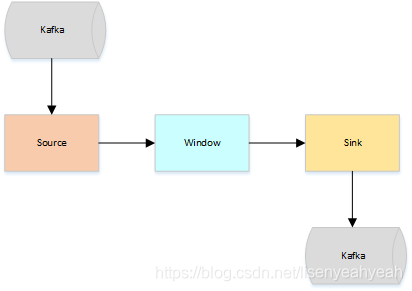
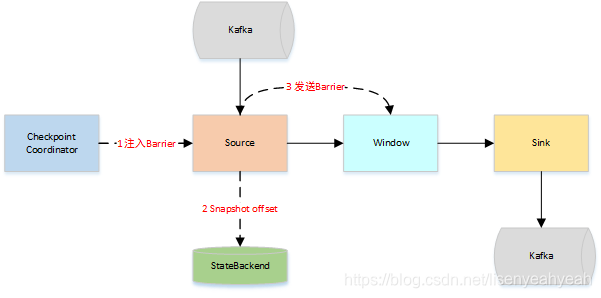
- JobManager向Source发送Barrier,开始进入pre-Commit阶段,当只有内部状态时,pre-commit阶段无需执行额外的操作,仅仅是写入一些已定义的状态变量即可。当chckpoint成功时Flink负责提交这些写入,否则就终止取消掉它们。
- 当Source收到Barrier后,将自身的状态进行保存,后端可以根据配置进行选择,这里的状态是指消费的每个分区对应的offset。然后将Barrier发送给下一个Operator。
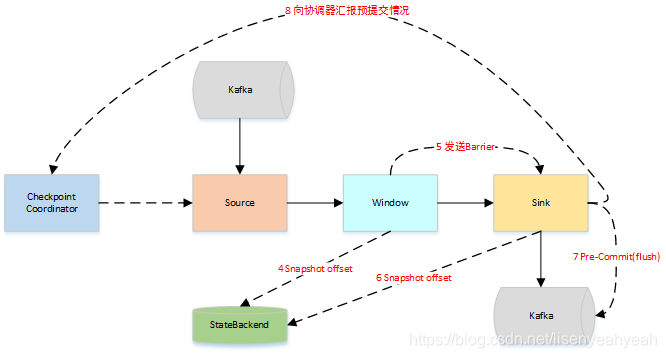
- 当Window这个Operator收到Barrier之后,对自己的状态进行保存,这里的状态是指聚合的结果(sum或count的结果),然后将Barrier发送给Sink。Sink收到后也对自己的状态进行保存,之后会进行一次预提交。
- 预提交成功后,JobManager通知每个Operator,这一轮检查点已经完成,这个时候,Kafka Sink会向Kafka进行真正的事务Commit。
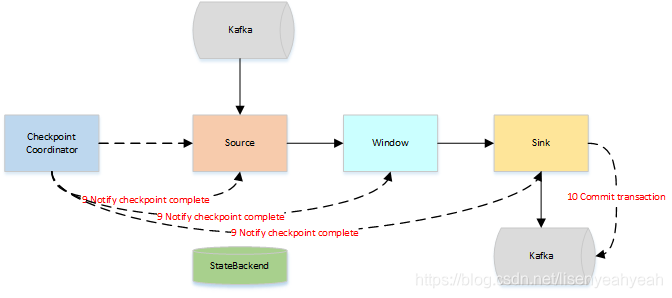
以上便是两阶段的完整流程,提交过程中如果失败有以下两种情况
- Pre-commit失败,将恢复到最近一次CheckPoint位置
- 一旦pre-commit完成,必须要确保commit也要成功
因此,所有opeartor必须对checkpoint最终结果达成共识:即所有operator都必须认定数据提交要么成功执行,要么被终止然后回滚。
参考文献
https://cwiki.apache.org/confluence/display/KAFKA/KIP-98±+Exactly+Once+Delivery+and+Transactional+Messaging#KIP-98-ExactlyOnceDeliveryandTransactionalMessaging-1.Findingatransactioncoordinator–theFindCoordinatorRequest
https://cloud.tencent.com/developer/article/1149669
https://segmentfault.com/a/1190000019329884
https://www.cnblogs.com/felixzh/p/10184762.html