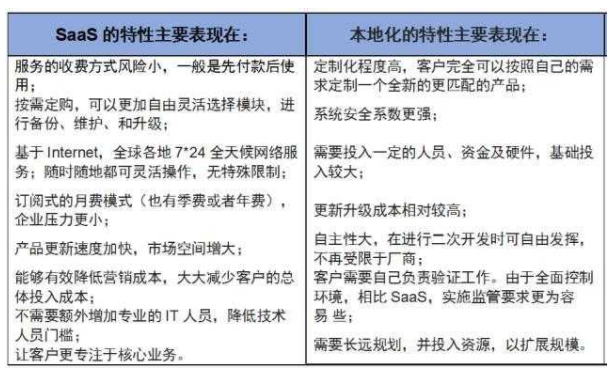
介绍
我们以演进的方式来逐渐认识布隆过滤器。先抛出一个问题爬虫系统中URL是怎么判重的?你可能最先想到的是将URL放到一个set中,但是当数据很多的时候,放在set中是不现实的。
这时你就可能想到用数组+hash函数来实现了。
index = hash(URL) % table.length
即求出URL的hash值对数组长度取模,得到数组的下标,然后设置table[index] = 1,当然数组刚开始的元素都为0
这样每次有新的URL来的时候,先求出index,然后看table[index]的值,当为0的时候,URL肯定不存在,当为1的时候URL可能存在,因为有可能发生hash冲突。即第一次
hash(www.baidu.com) % table.length = 1,table[1]=1,第二次hash(www.javashitang.com) % table.length = 1,此时table[1]=1,系统会认为www.javashitang.com已经爬取过了,其实并没有爬取。
从上面的流程中我们基本可以得出如下结论:hash冲突越少,误判率越低
怎么减少hash冲突呢?
- 增加数组长度
- 优化hash函数,使用多个hash函数来判断
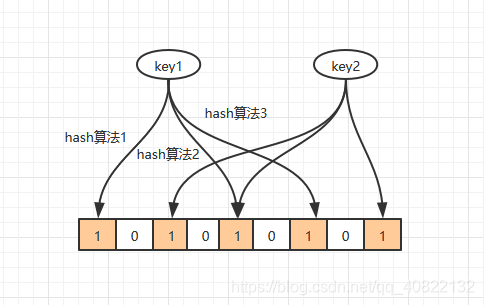
多个hash函数求得数组位置的值都为1时才认为这个元素存在,只要有一个为0则认为这个元素不存在。在一定概率上能降低冲突的概率。
那么hash函数是不是越多越好呢?当然不是了,hash函数越多,数组中1的数量相应的也会增多,反而会增加冲突。所以hash函数不能太多也不能太少。
你可能没意识到布隆过滤器的原理你已经懂了,只不过布隆过滤器存0和1不是用数组,而是用位,我们来算一下申请一个 100w 个元素的位数组只占用 1000000Bit / 8 = 125000 Byte = 125000/1024 kb ≈ 122kb 的空间,是不是很划算?
来总结一下布隆过滤器的特点
- 布隆过滤器说某个元素存在,其实有可能不存在,因为hash冲突会导致误判
- 布隆过滤器说某个元素不存在则一定不存在
使用场景
- 判断指定数据在海量数据中是否存在,防止缓存穿透等
- 爬虫系统判断某个URL是否已经处理过
手写一个布隆过滤器
public class MyBloomFilter {//位数组的大小private static final int DEFAULT_SIZE= 2<<24;//hash函数的种子private static final int[] SEEDS = new int[]{3,13,46};//位数组,数组中的元素只能是0或者是1private BitSet bits = new BitSet(DEFAULT_SIZE);//hash函数private SimpleHash[] func = new SimpleHash[SEEDS.length];public MyBloomFilter(){for(int i=0;i<SEEDS.length;i++){func[i]=new SimpleHash(DEFAULT_SIZE,SEEDS[i]);}}//添加元素到位数组public void add(Object value){for(SimpleHash f:func){bits.set(f.hash(value),true);}}//判断指定元素是否存在于位数组public boolean contains(Object value){boolean ret = true;for(SimpleHash f:func){ret = ret && bits.get(f.hash(value));//Hash函数有一个计算出为false,则直接返回if(!ret){return ret;}}return ret;}//Hash函数类public static class SimpleHash{private int cap;private int seed;public SimpleHash(int cap,int seed){this.cap=cap;this.seed=seed;}public int hash(Object value){int h;return (value==null)?0:Math.abs(seed*(cap-1)&(h=value.hashCode())^(h>>>16));}}public static void main(String[] args) {Integer value1=13423;Integer value2=22131;MyBloomFilter filter = new MyBloomFilter();//falseSystem.out.println(filter.contains(value1));//falseSystem.out.println(filter.contains(value2));filter.add(value1);filter.add(value2);//trueSystem.out.println(filter.contains(value1));//trueSystem.out.println(filter.contains(value2));}
}
利用Google的Guava工具库实现布隆过滤器
生产环境中一般不用自己手写的布隆过滤器,用Google大牛写好的工具类即可。
加入如下依赖
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>27.0.1-jre</version>
</dependency>
public class GoogleGuavaBloom {public static void main(String[] args) {//创建布隆过滤器的对象,最多元素数量为500,期望误报概率为0.01BloomFilter<Integer> filter = BloomFilter.create(Funnels.integerFunnel(),500,0.01);//判断指定元素是否存在//falseSystem.out.println(filter.mightContain(1));//falseSystem.out.println(filter.mightContain(2));//将元素添加进布隆过滤器filter.put(1);filter.put(2);//trueSystem.out.println(filter.mightContain(1));//trueSystem.out.println(filter.mightContain(2));}
}
用Redis中的布隆过滤器
Redis4.0以插件的形式提供了布隆过滤器。来演示一波
使用docker安装并启动
docker pull redislabs/rebloom
docker run -itd --name redis -p:6379:6379 redislabs/rebloom
docker exec -it redis /bin/bash
redis-cli
常用的命令如下
#添加元素
bf.add
#查看元素是否存在
bf.exists
#批量添加元素
bf.madd
#批量查询元素
bf.mexists
127.0.0.1:6379> bf.add test 1
(integer) 1
127.0.0.1:6379> bf.add test 2
(integer) 1
127.0.0.1:6379> bf.exists test 1
(integer) 1
127.0.0.1:6379> bf.exists test 3
(integer) 0
127.0.0.1:6379> bf.exists test 4
(integer) 0