项目介绍
本次结合的是一份淘宝大数据数据,数据集的大小共177MB,数据一共有3182261份(三百多万份数据集),一般的软件是无法计算和分析的,比如Excel,MySQL,Python这些都无法较好的完成相关数据分析。
1.Excel一般是一万多行的数据就不可以了。
2.Python与MySQL虽然可以,但是查询的效率却不敢保证,容易出现电脑死机或者卡死,这个与电脑本身的配置有关,所以对于大数据的数据集,我们提供了Hadoop,伪分布式的储存机制,这样的结构与特点让我们的数据集,可以容纳到TB级以上,较有规律的查询和优化的查询,可以让我们的数据分析事半功倍。
本次的数据集在这里下载
数据表里面的字段如下
| user_id age gender item_id behavior_type item_category time Province |
|---|
| 用户ID,性别,商品ID,用户行为,商品种类,发生日期,发生省份 |
项目准备
前期准备
如果你想要使用Hadoop集群来操作这次案例,就必须要已经完全配置好了的才能完成下面的操作,必须要包含:hdfs,hbase,hive,flume,sqoop等插件,如果有需要的可以私信我,文件压缩包7-8GB,只能用百度云盘分享给你,解压之后直接可以使用,一步到位
注意:虚拟机首先是必须要有的,不然有我发的镜像文件也不可以的
项目开展
项目导入
如果你是第一次使用我推荐的系统,需要进行下面的一些简单操作:
1.启动和拷贝hive包到相应的目录下面,这个是为了利用flume导入而准备的
start-all.sh
cd ${HIVE_HOME}/hcatalog/share/hcatalog/
cp * ${FLUME_HOME}/lib/
cd ${FLUME_HOME}/lib/
ll
本次我将讲解两种导入的方法,一种是hive直接加载本地文件,另一种是利用flume自动导入数据,作为商业大数据数据,我们更倾向于后者,因为在平时采集日志或数据集,都是自动化的,自动化分布式爬虫,自动化导入,自动化分析,这样才是老板时刻想要的数据结果展示,所以作为数据分析师,在以后的工作之中如何把工作一键化是非常的重要的,但是平时自己练习的时候,基于一些少量的数据集,我们采用本地加载的方法还是比较的简单方便,各有各的优势,我们自己去取舍。
把下面的配置参数加入hive-site.xml文件里面全选覆盖即可
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://localhost:3306/hive?useSSL=false&allowPublicKeyRetrieval=true&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value>
</property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value>
</property><property><name>javax.jdo.option.ConnectionPassword</name><value>root</value>
</property><property><name>hive.support.concurrency</name><value>true</value>
</property>
<property><name>hive.exec.dynamic.partition.mode</name><value>nonstrict</value>
</property>
<property><name>hive.txn.manager</name><value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
</property>
<property><name>hive.compactor.initiator.on</name><value>true</value>
</property>
<property><name>hive.compactor.worker.threads</name><value>1</value><!--这里的线程数必须大于0 :理想状态和分桶数一致-->
</property>
<property><name>hive.enforce.bucketing</name><value>true</value>
</property></configuration>
创建文件夹,便于后续操作
mkdir -p /home/hadoop/taobao/data
mkdir -p /home/hadoop/taobao/tmp/point
创建配置文件,帮助我们导入到hive里面(flume组件配置)
vi taobao.properties
#定义agent名, source、channel、sink的名称
agent3.sources = source3
agent3.channels = channel3
agent3.sinks = sink3
#具体定义source
agent3.sources.source3.type = spooldir
agent3.sources.source3.spoolDir = /home/hadoop/taobao/data
agent3.sources.source3.fileHeader=false#设置channel类型为磁盘
agent3.channels.channel3.type = file
#file channle checkpoint文件的路径
agent3.channels.channel3.checkpointDir=/home/hadoop/taobao/tmp/point
# file channel data文件的路径
agent3.channels.channel3.dataDirs=/home/hadoop/taobao/tmp#具体定义sink
agent3.sinks.sink3.type = hive
agent3.sinks.sink3.hive.metastore = thrift://hadoop:9083
agent3.sinks.sink3.hive.database = taobao_data
agent3.sinks.sink3.hive.table = data
agent3.sinks.sink3.serializer = DELIMITED
agent3.sinks.sink3.serializer.delimiter = ","
agent3.sinks.sink3.serializer.serdeSeparator = ','
agent3.sinks.sink3.serializer.fieldnames = id,user_id,age,gender,item_id,behavior_type,item_category,time,Province
agent3.sinks.sink3.batchSize = 90#组装source、channel、sink
agent3.sources.source3.channels = channel3
agent3.sinks.sink3.channel = channel3
在hive里面创建相应的表(利用flume导入的时候)
create database taobao_data;
use taobao_data;
create table `taobao_data`.`data` (`id` varchar(255) ,`user_id` varchar(255) ,`age` varchar(255) ,`gender` varchar(255),`item_id` varchar(255),`behavior_type` varchar(255),`item_category` varchar(255),`time` varchar(255),`Province` varchar(255)
)
clustered by(id) into 3 buckets
row format delimited fields terminated by ','
stored as orc tblproperties('transactional'='true');
首先运行该代码启动(终端命令行)hive --service metastore -p 9083运行下面的代码(终端命令行)flume-ng agent --conf conf --conf-file taobao.properties -name agent3 -Dflume.hadoop.logger=INFO,console
在hive里面创建相应的表(利用本地加载方法)
create database taobao_data;
use taobao_data;create table `taobao_data`.`data` (`id` varchar(255) ,`user_id` varchar(255) ,`age` varchar(255) ,`gender` varchar(255),`item_id` varchar(255),`behavior_type` varchar(255),`item_category` varchar(255),`time` varchar(255),`Province` varchar(255)
)
row format delimited fields terminated by ','
stored as textfile;LOAD DATA LOCAL INPATH '/home/hadoop/data.txt' INTO TABLE data;
全部都在hive里面运行
结果表和接收表的创建:
5.hive里面创建结果表
create table `xsxk`.`whw_2019443818_xsxk_result` (`key` varchar(255) ,`value` varchar(255)) ;
6.MySQL里面创建接收表
CREATE DATABASE xsxk;
create table `taobao`.`data_result` (`key` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,`value` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
经过上述的操作,导入数据就已经成功了
我们可以来看看:

项目分析
本次我给出了8个案例分析,如果你做到了这一步,下面的分析就是看你自己的才华了
你可以按照我的语句来分析,也可以按照你自己想法来实现本次的数据分析,正所谓“万事俱备只欠东风”
为了数据的准确性,下面的用户ID,商品ID,商品种类都是去重之后的,这样才有意义
– 1.统计每个省份的商品种类
SELECT count( DISTINCT d.item_category)as `商品种类`,d.Province `所属地` from `data` as d GROUP BY d.Province ORDER BY `商品种类` DESC;

– 2.统计每个省份的男女用户人数
SELECT DISTINCT d.user_id as `男性用户`,d.Province from `data` as d where d.gender=0 GROUP BY d.Province ;
SELECT DISTINCT d.user_id as `女性用户`,d.Province from `data` as d where d.gender=1 GROUP BY d.Province ;
– 3.统计各省总访问量
select 'PV', u.`总访问量`,u.`Province` as `省份` FROM
(select count(*) AS `总访问量`,`Province` FROM `data` GROUP BY `Province`) u;

– 4.统计各省用户人数
SELECT 'UV', u. `用户数量`,u.`Province` FROM
(SELECT COUNT(DISTINCT user_id) AS `用户数量`,`Province` FROM `data` GROUP BY `Province`) u;

– 5.跳失率
什么是跳失率:

先要输入这一行代码。这个和我们hive里面用varchar类型有关,想知道具体原因请移步到淘宝案例文章:点击这里
set hive.mapred.mode=nonstrict;SELECT "跳失率", u.`总访问量` FROM
(
SELECT b.`仅pv用户` / a.`总用户` AS `总访问量` FROM
(SELECT count( DISTINCT user_id ) AS `总用户` FROM `data`) a,
(SELECT count( DISTINCT user_id ) AS `仅pv用户` from (select * from `data`) as c LEFT JOIN (SELECT DISTINCT user_id as `id` FROM `data` WHERE behavior_type = '2' or behavior_type='3' or behavior_type='4') as d on c.user_id=d.id WHERE d.id is NULL ) as b
) as u;
– 6.有购买行为的用户数量
SELECT COUNT(*) FROM (SELECT u.user_id, SUM( CASE u.behavior_type WHEN '4 ' THEN 1 ELSE 0 END ) AS buy FROM `data` u GROUP BY u.user_id HAVING buy > 0 ) t;

–7. 用户的购物情况
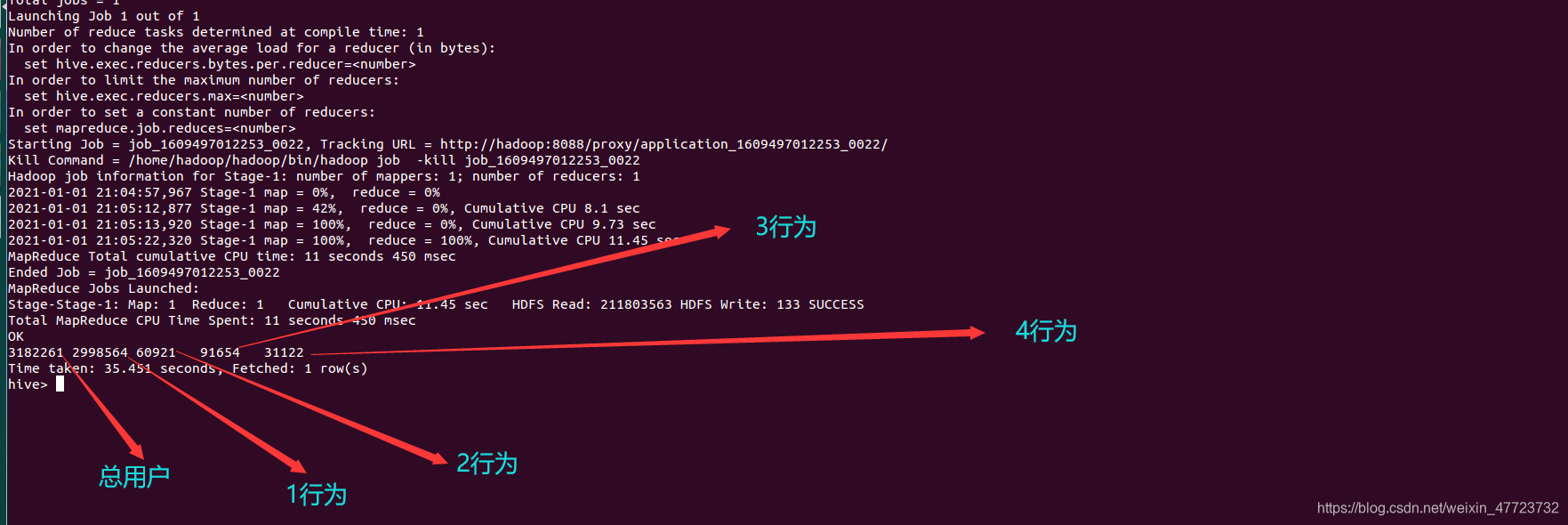
SELECT COUNT(*) AS `总数`, SUM(CASE u.`behavior_type` WHEN '1 ' THEN 1 ELSE 0 END ) AS `点击行为`,SUM(CASE u.`behavior_type` WHEN '2 ' THEN 1 ELSE 0 END ) AS `收藏行为`,SUM(CASE u.`behavior_type` WHEN '3 ' THEN 1 ELSE 0 END ) AS `加购物车行为`,SUM(CASE u.`behavior_type` WHEN '4 ' THEN 1 ELSE 0 END ) AS `购买行为` FROM `data` as u;
– 8.复购率
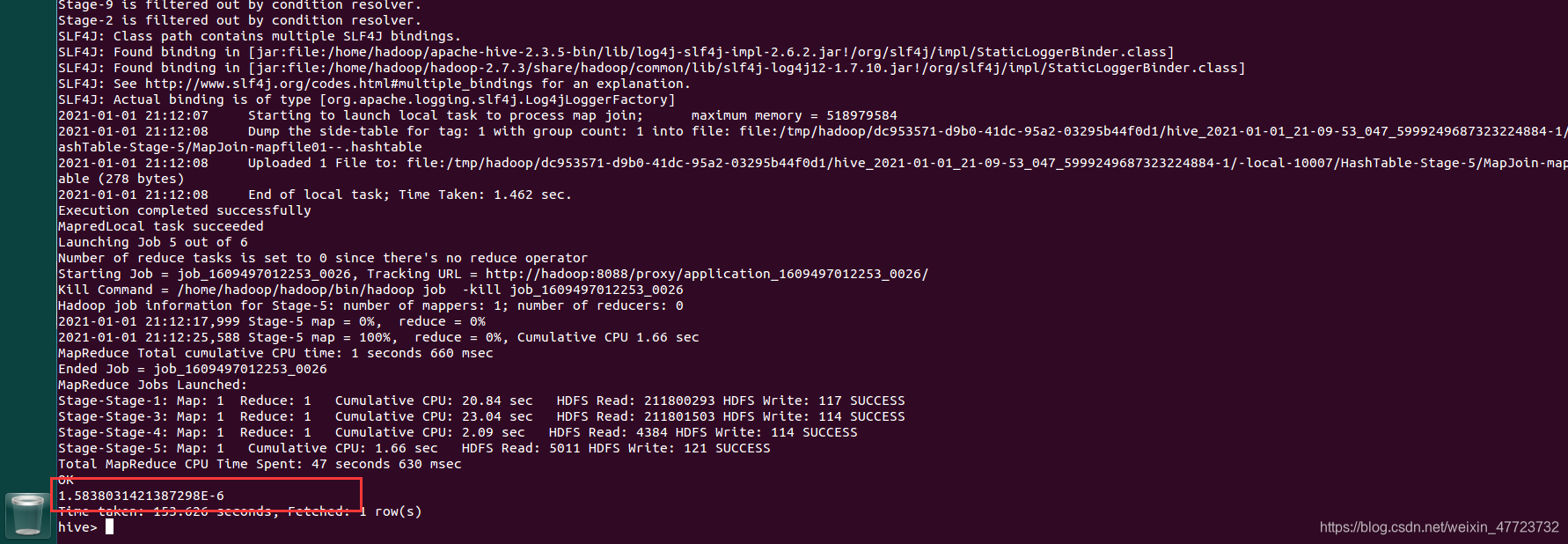
SELECT t2.repeat_buy/t1.total AS `复购率` FROM
(SELECT COUNT(DISTINCT u1.user_id) AS total FROM `data` u1) t1 ,
(SELECT COUNT(1) AS repeat_buy FROM
(SELECT u.user_id, SUM(CASE u.behavior_type WHEN '4 ' THEN 1 ELSE 0 END ) AS buy FROM `data` u GROUP BY u.user_id HAVING buy>1) t) t2;
项目分析
本次数据分析项目采用Python的第三方库的pyecharts这个强大的库,它的特点相信有许多的可视化的小伙伴一定很熟悉,高渲染的可视化效果让我们可以快速的展示!
下面我们就把刚刚的八个项目可视化出来
由于文章篇幅过于长,我就不完全可视化了
用户行为分析
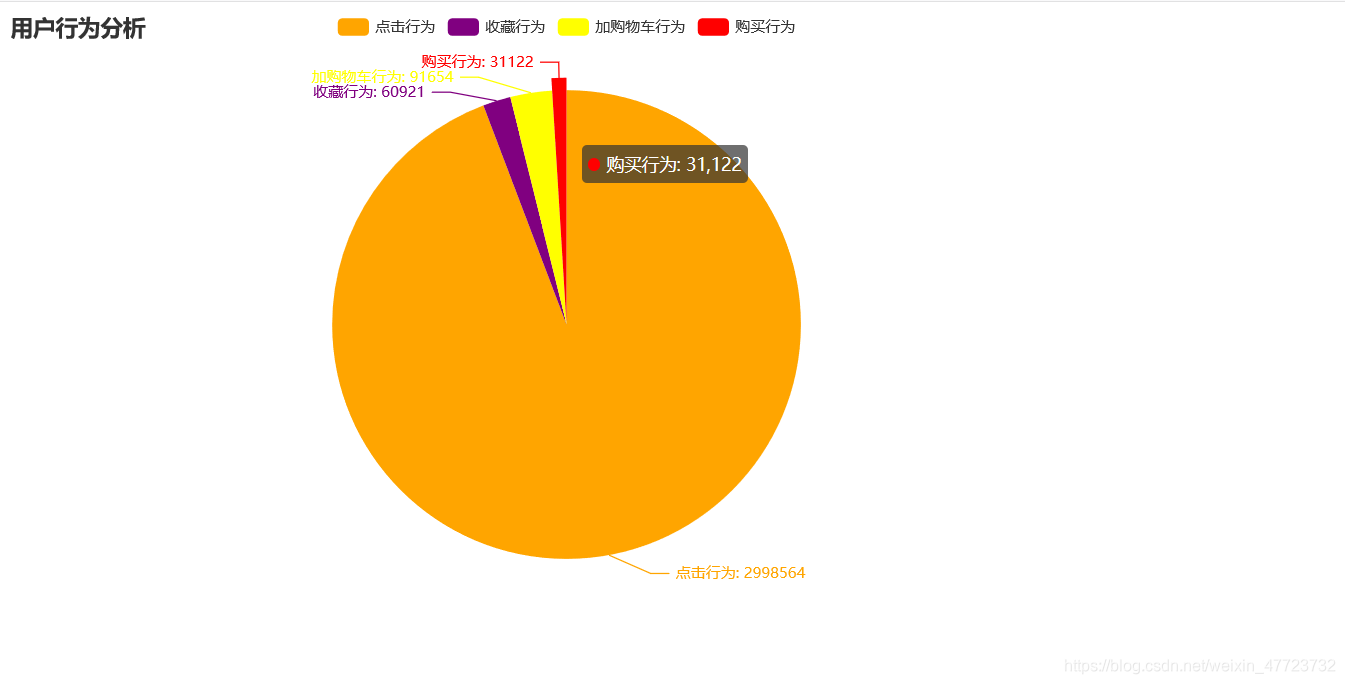

通过这个我们可以发现,大家还是都比较喜欢浏览商品页面,对于加购物车和收藏以及购买,不太多,这也说明了,淘宝里面的特点,丰富的商品让我们有点选择犹豫了。
from pyecharts import options as opts
from pyecharts.charts import Pie
a=["点击行为","收藏行为","加购物车行为","购买行为"]
b=[2998564,60921,91654,31122]
c = (Pie().add("",[list(z) for z in zip(a, b)]).set_colors(["orange", "purple", "yellow", "red", "pink", "purple", "blue"])#颜色设置.set_global_opts(title_opts=opts.TitleOpts(title="用户行为分析")).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"),toolbox_opts=opts.ToolboxOpts()).render("饼图.html")
)
参考这个代码,我们可以直接连接数据库,通过数据的处理分别展示不同的类型数据集

这个跳失率,看起来还是有点不乐观,说明只看不买不收藏的用户有点多,可能是本次的数据集非常的大,所以综合下来大家的平均行为还是浏览页面,以及看商品较多,这在电商大数据集下也是属于正常的结论。
||数据留给你们可视化了,自己去发挥自己的艺术细胞||
PV 93444 四川
PV 94105 福建
PV 93341 重庆市
PV 93796 吉林
PV 93979 湖北
PV 93503 新疆
PV 93671 台湾
PV 93343 河南
PV 93276 广东
PV 94260 宁夏
PV 93881 北京市
PV 93778 上海市
PV 93782 陕西
PV 93666 浙江
PV 93955 内蒙古
PV 93551 贵州
PV 93378 湖南
PV 93724 青海
PV 93336 黑龙江
PV 93544 澳门
PV 93460 甘肃
PV 93556 山西
PV 93178 海南
PV 93688 辽宁
PV 93369 天津市
PV 93899 西藏
PV 93406 河北
PV 93726 安徽
PV 93379 山东
PV 93443 香港
PV 93372 广西
PV 93678 江西
PV 93575 云南
PV 93219 江苏
UV 93756 上海市
UV 93552 云南
UV 93933 内蒙古
UV 93855 北京市
UV 93655 台湾
UV 93773 吉林
UV 93419 四川
UV 93346 天津市
UV 94234 宁夏
UV 93708 安徽
UV 93355 山东
UV 93528 山西
UV 93255 广东
UV 93349 广西
UV 93490 新疆
UV 93200 江苏
UV 93650 江西
UV 93383 河北
UV 93324 河南
UV 93635 浙江
UV 93152 海南
UV 93949 湖北
UV 93355 湖南
UV 93522 澳门
UV 93433 甘肃
UV 94073 福建
UV 93869 西藏
UV 93528 贵州
UV 93666 辽宁
UV 93314 重庆市
UV 93765 陕西
UV 93703 青海
UV 93420 香港
UV 93315 黑龙江
男性用户 省份
64772406 新疆
154141792 湖北
133773960 河南
125204052 广东
157079107 吉林
162728279 宁夏
20331578 上海市
28145118 四川
91298044 陕西
6357845 北京市
114749619 福建
162925618 贵州
169151099 湖南
151203745 甘肃
124588307 山西
161838654 海南
138211350 辽宁
182697679 天津市
177735754 浙江
190273854 河北
65841694 安徽
192816511 山东
100761551 广西
137215222 云南
94156421 重庆市
169364076 江西
121102112 香港
82398872 澳门
72957630 内蒙古
2405729 江苏
28518572 西藏
52342755 青海
16147613 台湾
131552233 黑龙江
女性用户 省份
68786611 四川
167664275 福建
125611298 重庆市
80542247 吉林
125574663 湖北
15818895 台湾
197168702 北京市
33734922 浙江
19618892 内蒙古
121152092 青海
157095955 黑龙江
86441455 澳门
98225813 贵州
133159769 河南
59135936 上海市
83870742 广东
167098473 西藏
112385169 新疆
17938248 陕西
115047781 海南
194635526 宁夏
161987546 辽宁
122802547 香港
197657745 江西
6002942 广西
97904095 云南
28987253 山东
71715466 山西
84458523 安徽
159809593 江苏
91157689 湖南
183075750 天津市
51040613 河北
185767669 甘肃
淘宝大数据案例到这里就结束了,从数据导入,到数据处理,最后到数据可视化,都是满满的回忆,虽然过程比较的艰辛,但是我觉得还是较为值得的,本次的课设的小伙伴,希望你们可以顺利取得好成绩,加油!
每文一语
胸怀千秋伟业,恰是百年风华




![[搜片神器]直接从DHT网络下载BT种子的方法](https://common.cnblogs.com/images/copycode.gif)