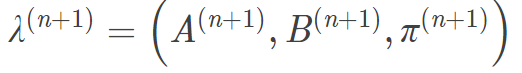因子隐马尔可夫(FHMM)由Ghahramani在1997年提出,是一种多链隐马尔可夫模型,适合动态过程时间序列的建模,并具有强大的时序模型的分类能力,特别适合非平稳、再现性差的序列的分析。
1. 马尔可夫链
随机过程的研究对象是随时间演变的随机现象,它是从多维随机变量向一族(无限多个)随机变量的推广。设T是一个集合,是随机试验的样本空间。
是定义在T和
上的二元实函数,对于每个
,
是一个确定的时间函数,对每个
,
是一个随机变量。则
称为随机过程,简记为或者
。其中每一函数称为随机过程的样本函数,T称为参数集。
马尔可夫过程是满足无后效性的随机过程。假设一个随机过程中,时刻的状态
的条件分布,仅仅与其前一个状态
有关,即
,则将其称为马尔可夫过程,时间和状态的取值都是离散的马尔可夫过程也称为马尔可夫链。设
是一齐次马尔可夫链,则对任意,有
即为C-K方程,含义为“从时刻s所处的状态出发,经时刻
到状态
,
”。
2.马尔可夫模型
马尔可夫模型是一个双重随机过程,其中一重随机过程是描述的基本的状态转移,而另一重随机过程是描述状态与观察值之间的对应关系。
马尔可夫模型假设是五元组(与下方HMM的三元组对应),
是初始化状态概率向量,
是状态i在初始状态下的概率,
是概率状态转移矩阵,隐状态之间的转移概率,即
,
,
是观测状态矩阵,是隐状态生成显状态的概率,也叫作发射概率(Emission Probability),即
,
,Q是所有可能状态集合,V是所有可能的观测序列集合。
3. 隐马尔可夫模型
隐马尔可夫描述的是一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测二产生观测随机序列的过程。隐藏的马尔可夫链随机生成的状态的序列,成为状态序列;每个状态生成一个观测,而由此产生的观测的随机序列,称为观测序列。
隐马尔可夫模型由初始概率分布、状态转移概率分布
以及观测概率分布
确定。隐马尔可夫模型的形式定义如下:
设Q是所有可能的状态的集合,V是所有可能的观测的集合。
其中,N是可能的状态数,M是可能的观测数。
I是长度为T的状态序列,O是对应的观测序列。
A是状态转移概率矩阵:
其中,是在时刻t处于状态
的条件下在时刻t+1转移到状态
的概率。
B是观测概率矩阵:
其中,是在时刻t处于状态的条件下生成观测的概率。
是初始状态概率向量:
其中,是时刻t=1处于状态
的概率。
隐马尔可夫模型由初始状态概率向量,状态转移概率矩阵和观测概率矩阵决定,状态转移概率矩阵与初始状态概率向量确定了隐藏的马尔可夫链,生成不可观测的状态序列。观测概率矩阵确定了如何从状态生成观测,与状态序列综合确定了如何产生观测序列。
隐马尔可夫模型的两个基本假设:
-
齐次马尔可夫假设,即假设隐藏的马尔可夫链在任意时刻t的状态只依赖于其前一时刻的状态,与其他时刻的状态及观测无关,也与时刻t无关。
-
观测独立性假设,即假设任意时刻的观测只依赖于该时刻的马尔可夫链的状态,与其他观测及状态无关。
隐马尔可夫模型有3个基本问题:
-
概率计算问题。给定模型
和观测序列
,计算在模型
下观测序列O出现的概率
。
-
学习问题。已知观测序列
-
预测问题,也称为解码问题。已知模型
。即给定观测序列,求最有可能的对应的状态序列。
3.1 概率计算问题
主要有两种计算方式,前向(forward)与后向(backward)算法来计算观测序列概率。
- 定义(前向概率)
给定隐马尔可夫模型,定义到时刻t部分观测序列
且状态为
的概率为前向概率,记为
可以递推求得前向概率及观测序列概率
。
算法
输入:隐马尔可夫模型,观测序列
;
输出:观测序列概率;
(a)初值
(b)递推 对,
(c)终止
例子
条件:考虑盒子和球模型,状态集合
,观测集合
,
,
,
。
设定T=3,,试用前向算法计算
。
解:
(a)计算初值
(b)递推计算
t=1时:
t=2时:
(c)终止
- 定义(后向概率)
给定隐马尔可夫模型,定义到时刻t状态为
的的条件下,从
到T部分观测序列为
的概率为后向概率,记为
可以递推求得后向概率及观测序列概率
。
算法
输入:隐马尔可夫模型,观测序列
;
输出:观测序列概率
(a)初值
(b)递推 对,
(c)终止
例子
条件:考虑盒子和球模型,状态集合
,观测集合
,
,
,
。
设定T=3,,试用后向算法计算
。
解:
(a)计算初值
(b)递推计算
t=T-1,即t=2时:
t=T-2,即t=1时:
(c)得到最终值
3.2 学习问题
学习算法是已知观测序列,估计模型参数
,使得在该模型下观测序列概率
最大。即用EM(Baum-Welch)的方法估计参数。
3.3 预测问题
隐马尔可夫模型预测有两种算法:近似算法和维特比算法(Viterbi algorithm)。
维特比算法是用动态规划解隐马尔可夫模型预测问题,即用动态规划求概率最大路径。此时一条路径对应着一个状态序列。首先导入两个变量和
,定义在时刻t状态为i的所有单个路径中概率最大值为
由定义可得变量的递推公式:
定义在时刻t状态为i的所有单个路径中概率最大的路径的第t-1个结点为
算法
输入:模型和观测
;
输出:最优路径;
(a)初始化
(b)递推,对t=2,3,...,T
(c)终止
(d)最优路径回溯。对t=T-1,T-2,..1
得到最优路径
。
例子
条件:考虑盒子和球模型,状态集合
,观测集合
,
,
,
。
设定T=3,,试用最优状态序列。
(a)初始化
(b)递推,
t=2时
t=3时
(c)最优路径概率
最优路径
(d)由最优路径的终点,逆向找到
:
t=2时,
t=1时,
即最优状态序列为
4.HMM三种方式的实现
代码参考:Python实现HMM的前向-后向算法和维特比算法_vincent1y的博客-CSDN博客
4.1.前向算法
(1)算法思路

(2)实现
def forward(Q,V,A,B,O,PI):"""前向算法Q:状态序列V:观测集合A:状态转移概率矩阵B:生成概率矩阵O:观测序列PI:状态概率向量"""N = len(Q) M = len(O)# alphas是前向概率矩阵,每列是某个时刻每个状态的前向概率alphas = np.zeros((N,M))T = M # 时刻for t in range(T):# 当前时刻观测值对应的索引index_O = V.index(O[t])for i in range(N):if t == 0:alphas[i][t] = PI[0][i] * B[i][index_O]#print('alpha1(%d)=p%db%db(o1)=%f' % (i, i, i, alphas[i][t]))else:# 这里使用点积和使用矩阵相乘后再sum没区别alphas[i][t] = np.dot([alpha[t-1] for alpha in alphas],[a[i] for a in A]) * B[i][index_O]#print('alpha%d(%d)=[sigma alpha%d(i)ai%d]b%d(o%d)=%f' % (t, i, t - 1, i, i, t, alphas[i][t]))# 将前向概率的最后一列的概率相加就是观测序列生成的概率P = np.sum([alpha[M-1] for alpha in alphas])print('alphas :')print(alphas)print('P=%5f' % P)4.2.后向算法
(1)算法思路

(2)实现
def backward(Q, V, A, B, O, PI):"""后向算法"""N = len(Q)M = len(O)# betas 是后向概率矩阵,第M列的概率都为1betas = np.zeros((N,M))for i in range(N):#print('beta%d(%d)=1' % (M, i))betas[i][M-1] = 1# 倒着,从后往前递推for t in range(M-2,-1,-1):index_O = V.index(O[t])for i in range(N):betas[i][t] = np.dot(np.multiply(A[i],[b[index_O] for b in B]),[beta[t+1] for beta in betas])realT = t + 1realI = i + 1#print('beta%d(%d)=[sigma a%djbj(o%d)]beta%d(j)=(' % (realT, realI, realI, realT + 1, realT + 1),end='')#for j in range(N):#print("%.2f*%.2f*%.2f+" % (A[i][j], B[j][index_O], betas[j][t + 1]), end='')#print("0)=%.3f" % betas[i][t])index_O = V.index(O[0])P = np.dot(np.multiply(PI,[b[index_O] for b in B]),[beta[0] for beta in betas])print("P(O|lambda)=", end="")for i in range(N):print("%.1f*%.1f*%.5f+" % (PI[0][i], B[i][index_O], betas[i][0]), end="")print("0=%f" % P)print(betas)4.3.维特比算法
(1)算法思路

(2)实现
def viterbi(Q,V,A,B,O,PI):N = len(Q)M = len(O)-1# deltas是记录每个时刻,每个状态的最优路径的概率deltas = np.zeros((N,M))# psis是记录每个时刻每个状态的前一个时刻的概率最大的路径的节点(psia的记录是比deltas晚一个时刻的)psis = np.zeros((N,M))# I是记录最优路径的I = np.zeros((1,M))for t in range(M):realT = t+1index_O = V.index(O[t])for i in range(N):realI = i+1if t == 0 :deltas[i][t] = PI[0][i] * B[i][index_O]psis[i][t] = 0#print('delta1(%d)=pi%d * b%d(o1)=%.2f * %.2f=%.2f'%(realI, realI, realI, PI[0][i], B[i][index_O], deltas[i][t]))#print('psis1(%d)=0' % (realI))else:deltas[i][t] = np.max(np.multiply([delta[t-1] for delta in deltas],[a[i] for a in A])) * B[i][index_O]psis[i][t] = np.argmax(np.multiply([delta[t-1] for delta in deltas],[a[i] for a in A]))#print('delta%d(%d)=max[delta%d(j)aj%d]b%d(o%d)=%.2f*%.2f=%.5f'%(realT, realI, realT-1, realI, realI,realT, # np.max(np.multiply([delta[t-1] for delta in deltas], [a[i] for a in A])), # B[i][index_O], deltas[i][t]))#print('psis%d(%d)=argmax[delta%d(j)aj%d]=%d' % (realT, realI, realT-1, realI, psis[i][t]))# 直接取最后一列最大概率对应的状态为最优路径最后的节点 I[0][M-1] = np.argmax([delta[M-1] for delta in deltas])for t in range(M-2,-1,-1):# psis要晚一个时间步,起始将最后那个状态对应在psis那行直接取出就是最后的结果# 但是那样体现不出回溯,下面这种每次取上一个最优路径点对应的上一个最优路径点I[0][t] = psis[int(I[0][t+1])][t+1]print(I) 5. hmmlearn应用
5.1 hmmlearn的API
5.1.1 hmmlearn.base
(1)ConvergenceMonitor
监控和报告收敛到sys.stderr,sys.stderr是是用来重定向标准错误信息的。可以自定义收敛方法。

(2)_BaseHMM
隐马尔可夫模型的基类,可以进行HMM参数的简单评估、抽样和最大后验估计。

常见的函数有:

5.1.2 hmmlearn.hmm
总共有三个HMM模型:基于Gaussian的,基于Gaussian mixture,基于multinomial(discrete),具体链接
- 状态序列符合高斯分布
- 状态序列符合高斯混合分布
- 状态序列是离散序列

(1)GaussianHMM

(2)GMMHMM

(3)MultionmialHMM

5.2 hmmlearn的Sample
(1)sample
已知初始概率矩阵,状态转移矩阵,每个成分的均值,每个成分的协方差,并且定义算法参数,然后生成HMM的样本数据,具体实例为,链接:
print(__doc__)import numpy as np
import matplotlib.pyplot as pltfrom hmmlearn import hmm
startprob = np.array([0.6, 0.3, 0.1, 0.0])
# The transition matrix, note that there are no transitions possible
# between component 1 and 3
transmat = np.array([[0.7, 0.2, 0.0, 0.1],[0.3, 0.5, 0.2, 0.0],[0.0, 0.3, 0.5, 0.2],[0.2, 0.0, 0.2, 0.6]])
# The means of each component
means = np.array([[0.0, 0.0],[0.0, 11.0],[9.0, 10.0],[11.0, -1.0]])
# The covariance of each component
covars = .5 * np.tile(np.identity(2), (4, 1, 1))# Build an HMM instance and set parameters
model = hmm.GaussianHMM(n_components=4, covariance_type="full")# Instead of fitting it from the data, we directly set the estimated
# parameters, the means and covariance of the components
model.startprob_ = startprob
model.transmat_ = transmat
model.means_ = means
model.covars_ = covars
# Generate samples
X, Z = model.sample(500)# Plot the sampled data
plt.plot(X[:, 0], X[:, 1], ".-", label="observations", ms=6,mfc="orange", alpha=0.7)# Indicate the component numbers
for i, m in enumerate(means):plt.text(m[0], m[1], 'Component %i' % (i + 1),size=17, horizontalalignment='center',bbox=dict(alpha=.7, facecolor='w'))
plt.legend(loc='best')
plt.show()(2)train & inferring the hidden states
import numpy as np
from hmmlearn import hmmnp.random.seed(42)
#Sample data
model = hmm.GaussianHMM(n_components=3,covariance_type='full')
model.startprob_ = np.array([0.6,0.3,0.1])
model.transmat_ = np.array([[0.7,0.2,0.1],[0.3,0.5,0.2],[0.3,0.3,0.4]])
model.means_ = np.array([[0.0,0.0],[3.0,-3.0],[5.0,10.0]])
model.covars_ = np.tile(np.identity(2),(3,1,1))
X,Z = model.sample(100)#fit & predict
remodel = hmm.GaussianHMM(n_components=3, covariance_type="full", n_iter=100)
remodel.fit(X)
Z2 = remodel.predict(X)#save model
import pickle
with open("filename.pkl", "wb") as file: pickle.dump(remodel, file)
with open("filename.pkl", "rb") as file: pickle.load(file)
参考文献:
《统计机器学习》
hmmlearn Document
机器学习导论
Python实现HMM的前向-后向算法和维特比算法_vincent1y的博客-CSDN博客