目录
零.前言
1.区分贪心算法和动态规划
1.动态规划
2.贪心算法
3.共通点
2.贪心算法得到最优解的条件
1.具有优化子结构
2.具有贪心选择性
3.任务安排问题
1.问题定义
2.优化子结构
3.证明贪心选择性
4.总结
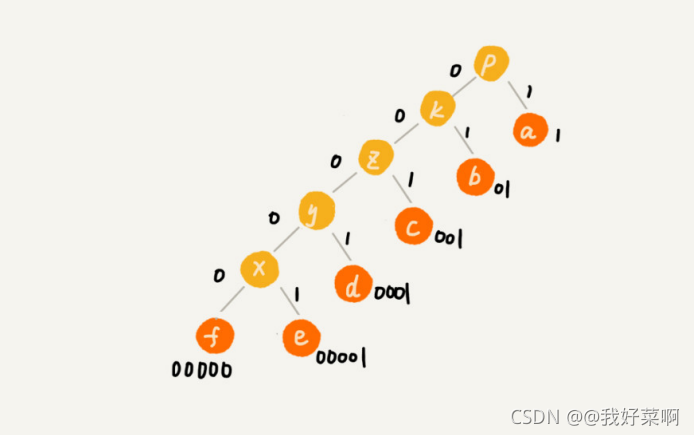
4.哈夫曼编码问题
1.问题定义
2.优化子结构
3.贪心选择性
4.伪代码实现
5.最小生成树
1.问题定义
2.kruskal算法
1.贪心选择性
2.优化子结构
3.算法复杂性
3.prim算法
1.贪心选择性
2.优化子结构
3.算法复杂度
6.附加题
1.问题定义
2.优化子结构
3.贪心选择性
7.总结
零.前言
贪心算法是设计算法中最容易进行操作的,但我们需要想清楚它的原理是什么,即什么时候贪心算法可以得到全局最优解,什么时候贪心算法只能得到局部最优解。
1.区分贪心算法和动态规划
1.动态规划
动态规划的主要特点就是自底向上运算,我们需要先计算并记录子问题的解,然后再将这些子问题的解通过递归表达式进行运算,然后进行比较作为问题的解。需要先计算子问题,然后才能进行一次选择。这是因为子问题是重叠的。
2.贪心算法
贪心算法的特点是自上而下计算,在进行第一次选择的时候不需要求解任何子问题,选择当前看起来最优的即可。
3.共通点
当我们可以应用动态规划或者贪心算法时,该问题一定具有优化子结构,即一个问题的最优解包含子问题的最优解。所以我们在处理问题时,当计算完优化子结构之后,可以先不使用动态规划,看看能不能用贪心算法,因为贪心算法比动态规划简单的多,杀鸡焉用牛刀。
2.贪心算法得到最优解的条件
1.具有优化子结构
2.具有贪心选择性
当一个优化问题的全局优化解可以通过局部优化解来得到时,则称该问题具有贪心选择性。这个证明通常首先考察某个子问题的最优解,然后用贪心选择替换某个其他选择来修改此解,从而得到一个相似但更小的子问题。
证明了这两个问题,我们就可以使用贪心算法进行求解了。而且求出的解一定是最优解。
那么为什么证明了这两点贪心算法就适用了呢?
贪心选择性:每一步贪心选择得到的解一定是子问题的一部分。
优化子结构:每一步贪心选择之后会剩下一个子问题,贪心选择出来的解和子问题的最优解构成原问题的解。
3.任务安排问题
1.问题定义
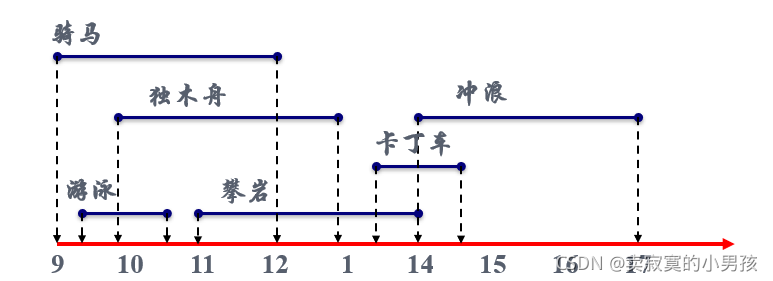
有很多种活动需要对同一个体育场进行占用,且同一个时间只能在体育场内进行一种活动,每个活动的开始和结束时间是固定的,问如何安排可以使体育场内活动最多。
我们把这个问题抽象出来:
给定了活动集合S={a1,a2,a3……an},
每个活动开始时间集合M={s1,s2,s3,s4……sn}
每个活动结束集合F={f1,f2,f3,f4……fn},假设活动已经按结束时间单调递增顺序排序。
问如何安排活动使在时间段内使得一共进行的活动数最多。
2.优化子结构
令Sij表示在ai结束后开始,aj开始前结束的所有活动的集合,在这段时间内我们要求解的就是如何安排不兼容(即无交集)的活动使得安排的活动数最大。
假设Sij中集合Aij表示不兼容且活动数最多的集合,即为Sij的最优解,假设Aij包含活动ak,那么可以得到在Sij中的求最优解的两个子问题,即在Sik中求最优解,和在Sk+1 j中求最优解。
首先设Aik=Aij∩Sik,Ak+1,j=Aij∩Sk+1,j此时Aij=Aik∪ak∪Ak+1,j。
|Aij|=|Aik|+|Ak+1,j|+1。我们要证明|Aik|在Sik中的各种组合中最小。
假设有一个更优解|Aik'|>|Aik|那么|Aik'|+|Ak+1,j|+1>Aij,与Aij为最优解不符,所以假设不成立。因此Aik,Ak+1,j分别为Sik,Sk+1 j的最优解。
不使用反证法也可以这样去看:设Aik为Sik中的包含不兼容元素的集合,Ak+1,j是Sk+1,j中包含不兼容元素的集合,Aij是Sij中包含不兼容元素的集合,ak为某一个元素,此时同样满足|Aij|=|Aik|+|Ak+1,j|+1由于|Aik|与|Ak+1,j|没有任何联系,1为一个常数,所以当|Aij|最大时,|Aik|,|Ak+1,j|一定都最大,所以具有优化子结构。
3.证明贪心选择性
当证明完优化子结构的时候我们已经可以根据ak的位置写出递归方程使用动态规划进行求解了,但我们可以先证明能否使用贪心算法来解决问题,即问题是否具有贪心选择性。
首先假设Aij为Sij的最优解,am是Sij中最早结束的活动,设aj为Aij中最早结束的活动,我们要证明的是am同样被包含在一个最优解中:
如果am∈Aij即am=aj则am包含在最优解Aij中,如果am!=aj,由于am的结束时间比aj早,所以Aij-{aj}+{am}依然构成一个最优解,所以am一定被包含在一个最优解中。
4.总结
既然可以使用贪心算法,那么就每次选择最早结束的活动即可得到最优解。
4.哈夫曼编码问题
1.问题定义
我们都知道哈夫曼编码的操作流程,你会发现它是符合贪心算法的,即每次选择权值最小两个模块,我们要研究的是为什么可以使用贪心算法这样计算。
当我们使用01序列来表示每一个元素时(这里用字母表举例),我们希望对于经常出现的字母,表示它所用的01序列越短越好。那么编码的优劣可以用树的权值来表示,即用每个字母的权值(出现的概率)去乘以路径长(01序列长度),最后求和。
记为:B(T)=ΣdT(c)*f(c)
即证明为什么每次都选择权值最小的元素来构成它的优化前缀树可以使B(T)最小。
2.优化子结构
假设T是字母表C的优化前缀编码树,f(c)是c元素的概率,T'是通过T减去两个叶子节点x和y得到的,z的权值为f(x)+f(y)。 我们要证明的是T'是C'=(C-{x,y})∪{z}的优化前缀编码树。
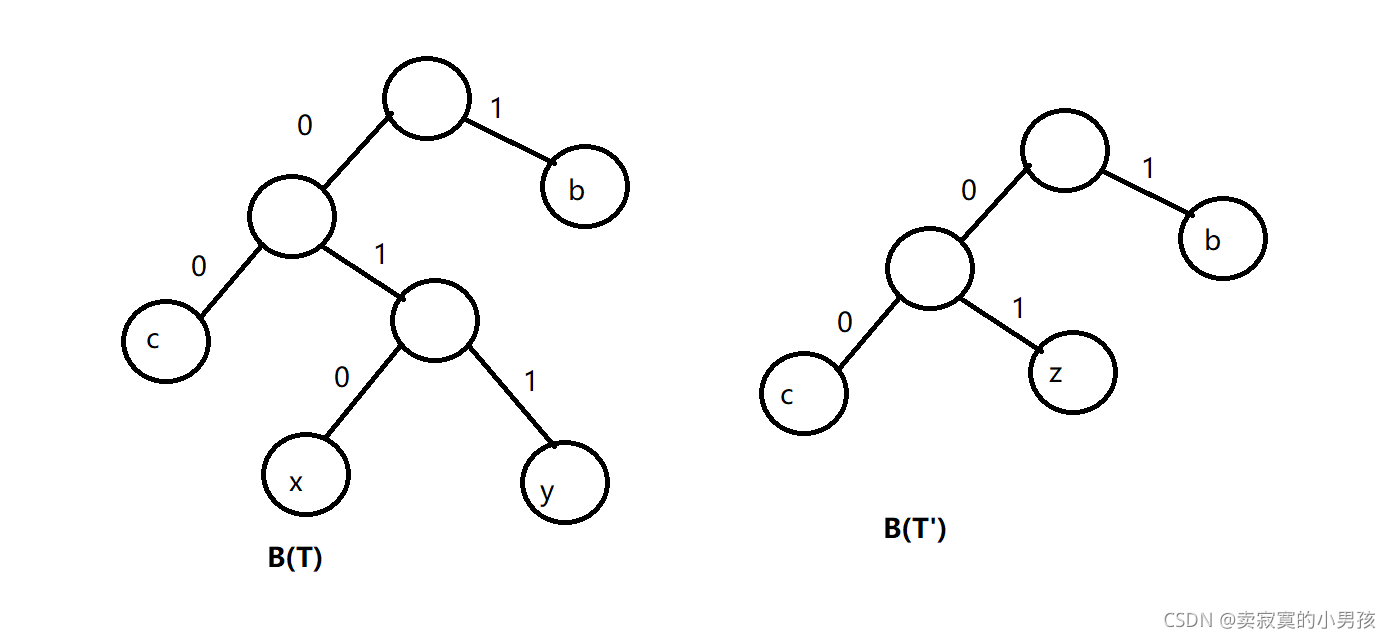
此时B(T)=2*f(c)+1*f(b)+3*f(x)+3*f(y),B(T')=2*f(c)+1*f(b)+2*(f(x)+f(y))
B(T)与B(T')相差的就是两个节点的权值和,这是因为两者的权值赋给了z,权值和是不变的,但是路径都少了一层。
若T'不是C'的最优前缀编码树,则存在T''使得B(T'')<B(T'),因为z是C'中的字符,它一定是T''中的叶子,将x,y加入T''中,得到一棵新的编码树T'''。
B(T''')=B(T")+f(x)+f(y)<B(T')+f(x)+f(y)<B(T)
此时与B(T)是最优解矛盾,所以B(T')是C'的优化编码树。
3.贪心选择性
假设x,y为权值最小的两个节点,则存在一棵C的优化编码树,使得x,y具有相同的长度,且仅在最后一位不同。
设T是一棵最优前缀编码树。
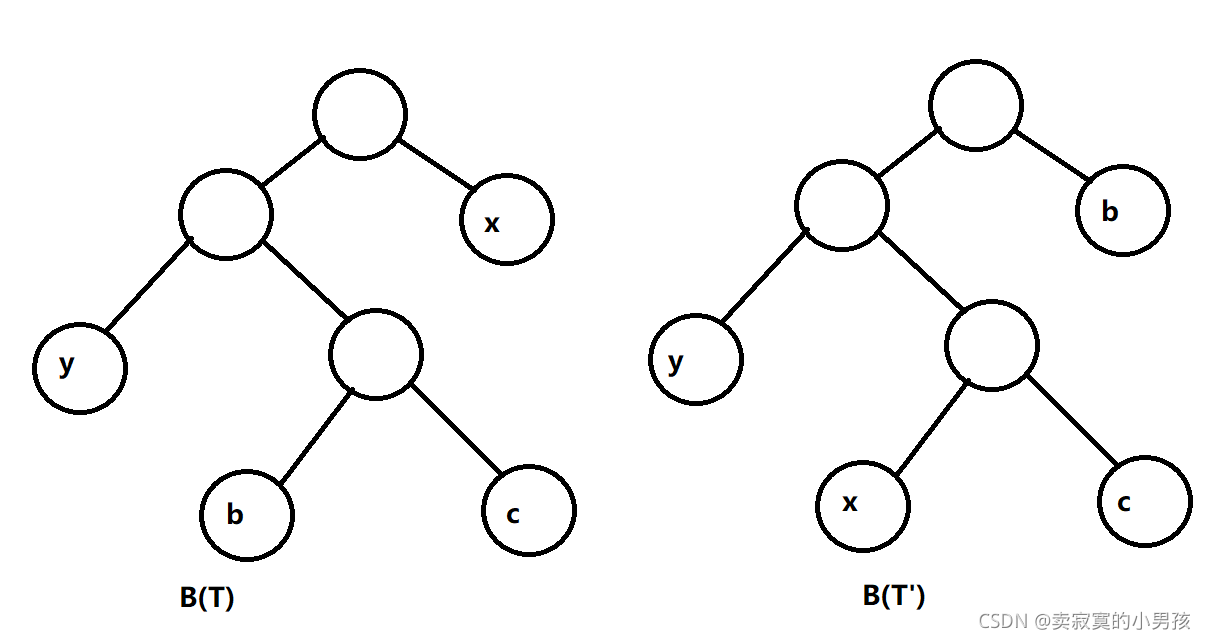
当我们把b节点和x节点换位置时,
B(T)-B(T')=f(x)*1+f(b)*3-f(x)*3-f(b)*1=2(f(b)-f(x))>0,同理将y与b互换位置也是如此,这是因为f(b)>f(x),而高度不同导致f(x)*路径-f(b)*路径的值不同。
因此只有当最小的两个节点路径最大的时候B(T)是最小的,所以满足贪心选择性。
每次选择最小的两个节点构成树即可。
4.伪代码实现
Huffman(C,F)1. n<--|C|;2. Q<--C; /* 用BUILD-HEAP建立堆 */3. FOR i<--1 To n-1 Do4. z<--Allocate-Node( );5. x<--left[z]<--Extract-MIN(Q); /* 堆操作*/ 6. y<--right[z]<--Extract-MIN(Q); /* 堆操作*/ 7. f(z)<--f(x)+f(y);8. Insert(Q, z); /* 堆操作*/ 9. Return第二步用堆排序的BUILD-HEAP实现:O(n)
每个堆操作要求O(logn),循环n-1次,T(n)=O(n)+O(nlogn)=O(nlogn)
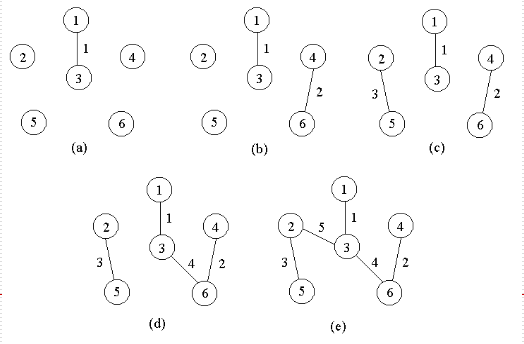
5.最小生成树
1.问题定义
对于一个连通图,如何建立树使得通过一个顶点可以找到其他所有顶点的同时,所有路径的权值和最小。
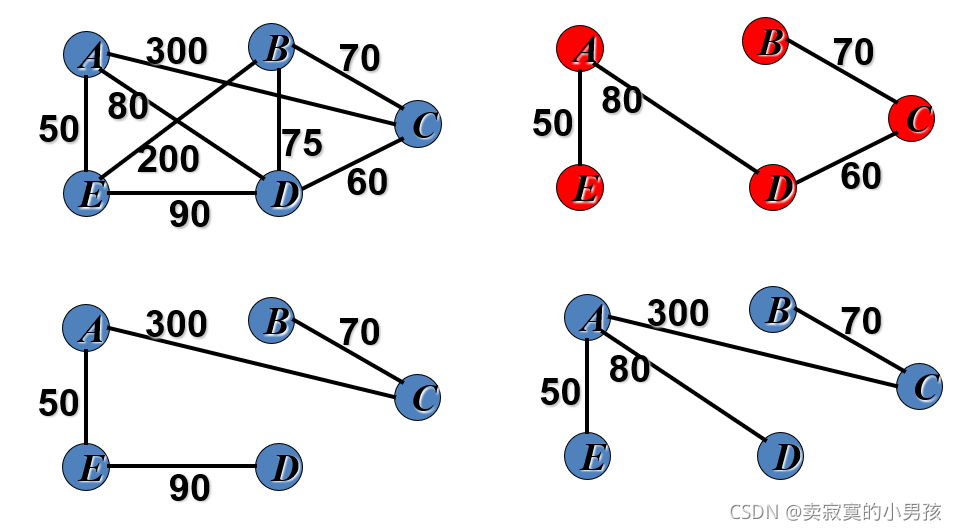
2.kruskal算法
每一次选择最小的边,如果这条边连接的顶点不在一棵树上,那么就记录这条边为最小生成树的一部分。
1.贪心选择性
假设uv是权值最小的边,有一棵最小生成树MST,如果MST包含uv则成立,当MST不包含uv时:
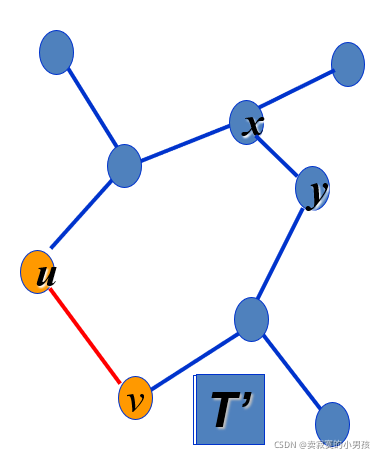
此时T不包含uv,连接uv,并删除MST中最小的边xy得到T',此时e(T')=w(T)-w(xy)+w(uv)<w(T),w()代表树的权值。
此时T'为最小生成树 ,与T为最小生成树矛盾。所以一棵最小生成树中一定包含其中最短的边,贪心选择性成立。
2.优化子结构
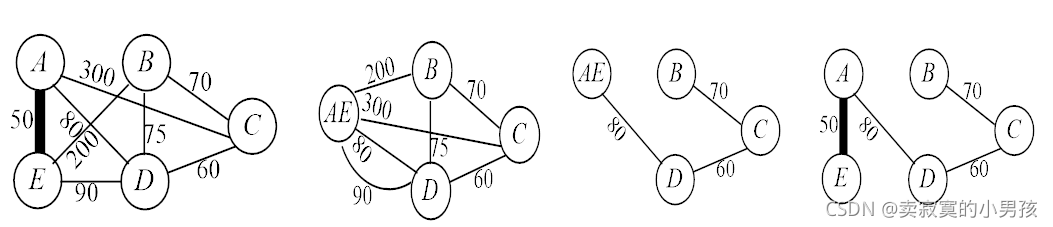
当我们选出其中最短边时,就会留下一个子问题,我们把AE和uv合并作为一个节点,如第二个图,则该图的连接方式就构成了一个子问题。
我们要证明的是当原问题达到最优解时,它的子问题是否也达到了最优解,即设T是图G包含uv的一棵最小生成树,T.uv为G.uv的最小生成树。
首先T.uv是G.uv的一棵生成树,假设G.uv存在另一棵最小生成树T',使得W(T')<W(T.uv),则存在一棵生成树W(T'')=W(T')+W(uv)<W(T.uv)+W(uv)=W(T),与T为最小生成树矛盾。因此具有优化子结构。
所以依靠kruskal算法可以产生最小生成树。
3.算法复杂性
伪代码感觉写的越来越简便和离谱了~这里直接给复杂度吧~
算法复杂度为:O(mlogm)
3.prim算法
先选择一个点作为起点,然后选择与这个点最近的一条边作为最小生成树的一部分。然后依次找出与构成的结构距离最近的点的边作为最小生成树的一部分。
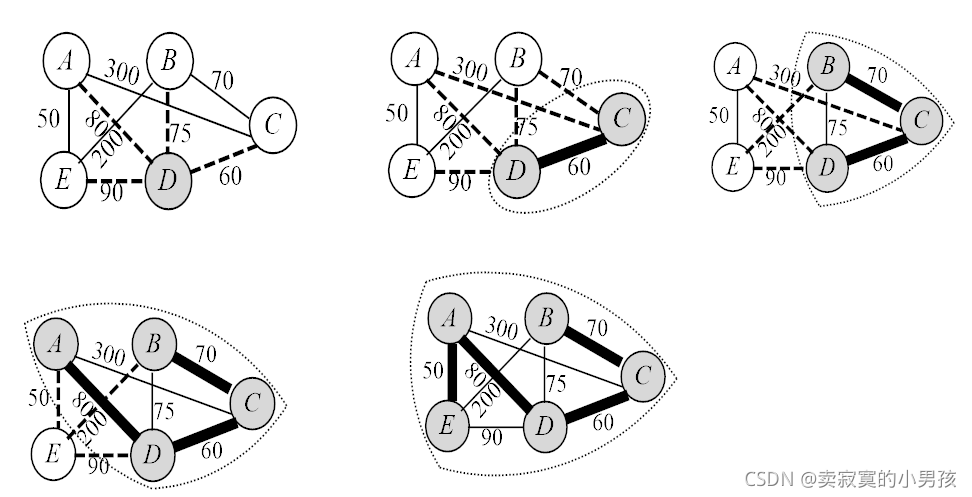
1.贪心选择性
首先选择一个点u,设与它关联的权值最小的的边为uv,则需要证明最小生成树一定包含uv。设T为图G的一棵最小生成树。
假设不包含uv,那么连接uv,产生环,其中u的度为2,则存在uv'∈T,删除uv'得到T',则此时W(T')=W(T)-W(uv')+W(uv)<W(T),与T为最小生成树矛盾,所以T中一定包含uv,所以具有贪心选择性。
2.优化子结构
设uv∈E是与顶点u关联的权值最小的边,设T是G的包含uv的最小生成树,则要证明T.uv是G.uv的一棵最小生成树。
假设G.uv存在另一棵最小生成树T',使得W(T')<W(T.uv),则存在一棵生成树W(T'')=W(T')+W(uv)<W(T.uv)+W(uv)=W(T),与T为最小生成树矛盾。因此具有优化子结构。
所以prim算法可以产生最小生成树。
3.算法复杂度
算法复杂度为O(mlogm)。
6.附加题
1.问题定义
输入: N = 10, 输出: 9
输入: N = 2454,输出: 2449
输入: N = 233332,输出: 229999
设strN[i]表示从高位到低位第i个数,我们从高位到低位找到第一个满足strN[i-1]>strN[i]的位置,然后把strN[i-1]-1,再把后面的位置变成9即可。然后检查strN[i-2],如果此时strN[i-2]>strN[i-1]则将strN[i-1]置为9,strN[i-2]-1……直到找到第一个位置j,使得strN[j-1]与strN[j]仍然满足递增关系。停止遍历。

这里的贪心选择指的是每一次选择strN[i-1]<strN[i]的元素,将i-1后面的元素变成9,将strN[i-1]-1,注意这里只是进行一次,并没有考虑子结构等情况。
2.优化子结构
1)如果整个数字 N 本身已经是按位单调递增的,显然成立。
2)如果不是,设M为满足要求的最大整数。我们找到strN中从高位到低位第一个满足 strN[i-1] > strN[i] 的位置,然后把 strN[i-1] 减 1,再把后面的位置都变成 9 。此时strM[1,…,i-1]是此时strN[1,...,i-1]的满足要求的最大整数字符串。
同理,从后往前依次执行贪心操作,执行完第k位时, strM[1,…,k]是此时strN[1,...,k]的满足要求的最大整数字符串。
3.贪心选择性
局部最优:如果strN[i-1]>strN[i], 那么将strN[i-1]自身减1,并将strN[i]变为9,可以保证第i-1位和i位这两位变成最大单调递增整数;
全局最优:按照从后往前依次执行贪心操作,可以保证局部最优便是全局最优(可以用反证法)。
7.总结
这篇完成,三大算法也就告一段落了,我整体的感觉是动态规划最复杂也最难算,贪心算法次之,最后是分治法。最难做的问题依然是我们要证明什么即寻找子问题,我曾经总结过根据解决整个问题的最后一步寻找子问题,但也是只能解决大部分问题,对于一些比较刁钻的也很难看出最后一步是什么,所以寻找子问题构造优化子结构还是需要靠个人的功力的。设计算法也只是有一个大致的模型和模板,不太可能有详细的思考流程来解决所有的题目,因此真正想成为算法大佬还是需要有一定的题量的。