论文链接:https://arxiv.org/abs/1912.10832
代码链接:https://github.com/didi/hetsann
Abstract
针对HIN(Heterogeneous Information Network)的表示学习,提出 HetSANN(Heterogeneous Graph Structural Attention Neural Network) 模型,不使用元路径(mate-path)直接编码HIN中的信息。通过以下两种方法表示异构信息:
- 将异构节点映射到低维实体空间
- 通过Attention机制,应用GNN聚合投影后邻居节点间的各种关系
除此之外,还提出了关于HetSANN的三个扩展:
- voices-sharing product attention for the pairwise relationships in HIN
- cycle-consistency loss to retain the transformation between heterogeneous entity spaces
- multi-task learning with full use of information。
Introduction
目前在HIN(heterogeneous information network)上的大多数方法都是基于元路径,将异构图修转化为同构图,再用同构图的嵌入式表式方法来学习网络的向量表示,从而获取异构图的低维向量空间。
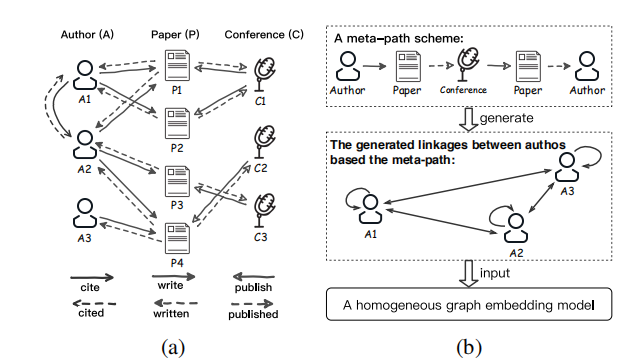
但上述的方法存在两个major challenge:
- C1:如何对不同类型的节点建模?
- C2:如何保留不同关系间的语义信息?
当前很多的HIN嵌入学习都基于元路径,如matepath2vec,HAN。存在两个主要问题
- 元路径的定制需要由领域专家来完成,但很难手工选出全部有价值的元路径
- 存在信息损失,异构节点或边的特征在基于元路径生成节点对时可能会丢失,甚至会导致较差的嵌入性能。
本文提出新的方法,不需要元路径直接对HIN的结构信息进行编码,提出了一种既能保留结构和语义信息的HIN低维空间向量学习方法。具体的来说,利用GNN来传递HIN的结构信息,通过task-guided的目标函数来进行训练(本文中为节点分类损失)。为了应对HIT中的挑战,设计了类型感知注意力层(Type-aware Attention Layer )来替代传统GNN中的卷积层。对每个Type-aware Attention Layer,定义了一种从不同实体空间的顶点投射到相同的低维目标空间的方法,用于异构节点间的交互(C1)。并采用注意力机制,将含有不同语义信息的不同类型的边用于邻居节点的聚合(C2),还设计了两种注意力打分函数concat product and voices-sharing product
本文贡献:
- 提出HetSANN,不用元路径,直接使用结构信息实现更多信息表示
- 提出HetSANN的3个扩展
- E1:通过多任务学习提高信息共享。Enhance the extent of sharing information with multi-task learning
- E2:考虑有向边和反向边之间的成对关系。Take the pairwise relationship between the directed edge and the reversed edge into account (voices-sharing product).
- E3:对转化操作引入限制以保持循环一致性。Introduce a constraint to the transformation operation to keep cycle consistent.
- 用三个异构图数据集对HetSANN的效果进行评估。结果表名HetSANN的优越性。
Heterogeneous Graph Structural Attention Neural Network (HetSANN)
异构图 G = { V , E } G=\{V,E\} G={V,E},节点类型集 A A A,边集合类型 R R R,节点 i i i到 j j j的边用 e = ( i , j , r ) e=(i,j,r) e=(i,j,r)表示, r r r是relationship type, r ∈ R r \in R r∈R。反边表示为 e ~ = ( i , j , r ~ ) \tilde{e}=(i,j, \tilde{r}) e~=(i,j,r~),跟节点 j j j相邻的边集合为 ε j = { ( i , j , r ) ∈ ε ∣ i ∈ V , r ∈ R } \varepsilon_j=\{(i,j,r)\in \varepsilon|i\in V,r\in R\} εj={(i,j,r)∈ε∣i∈V,r∈R}
本文目标为节点为 ϕ ( i ) \phi(i) ϕ(i)类型的节点生成它的低维表示 h i ∈ R n ϕ ( i ) h_i\in \mathbb{R}^{n_{\phi(i)}} hi∈Rnϕ(i)其中 n ϕ ( i ) n_{\phi(i)} nϕ(i)为嵌入空间的维度。可能会出现各种关系类型。为了处理节点见存在多种关系的情况,提出HetSANN
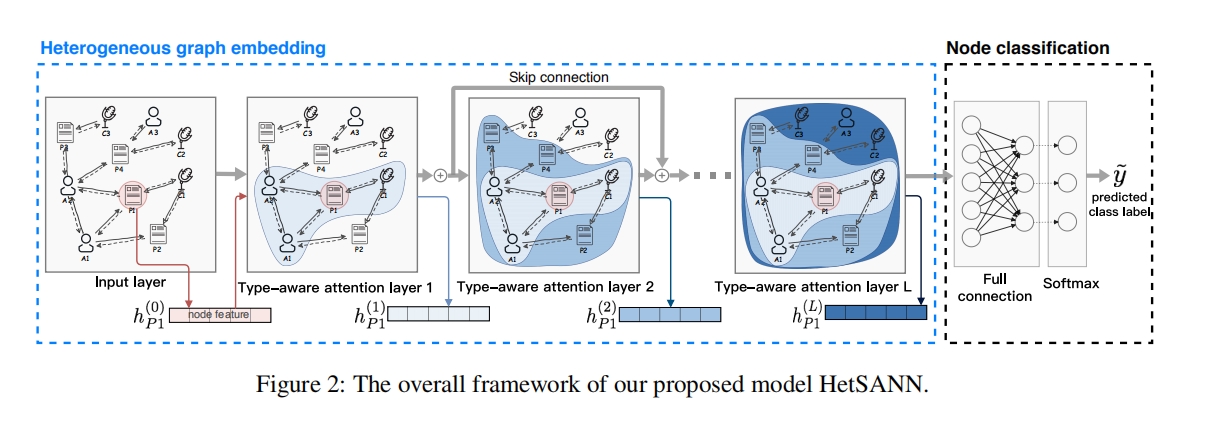 模型整体结构如上所示,其中核心是type-aware attention laye。
模型整体结构如上所示,其中核心是type-aware attention laye。
Type-aware Attention Layer (TAL)
进行嵌入学习前,对每个节点 i i i,先为其添加闭环(self-loop relation),并为其添加冷启动初始状态 h i 0 ∈ R n ϕ ( i ) ( 0 ) h_i^{0}\in \mathbb{R}^{n^{(0)}_{\phi(i)}} hi0∈Rnϕ(i)(0).冷启动状态为节点的属性特征,对没属性的节点则可用零向量或one-hot向量。
每个TAL都采用多头注意力机制。
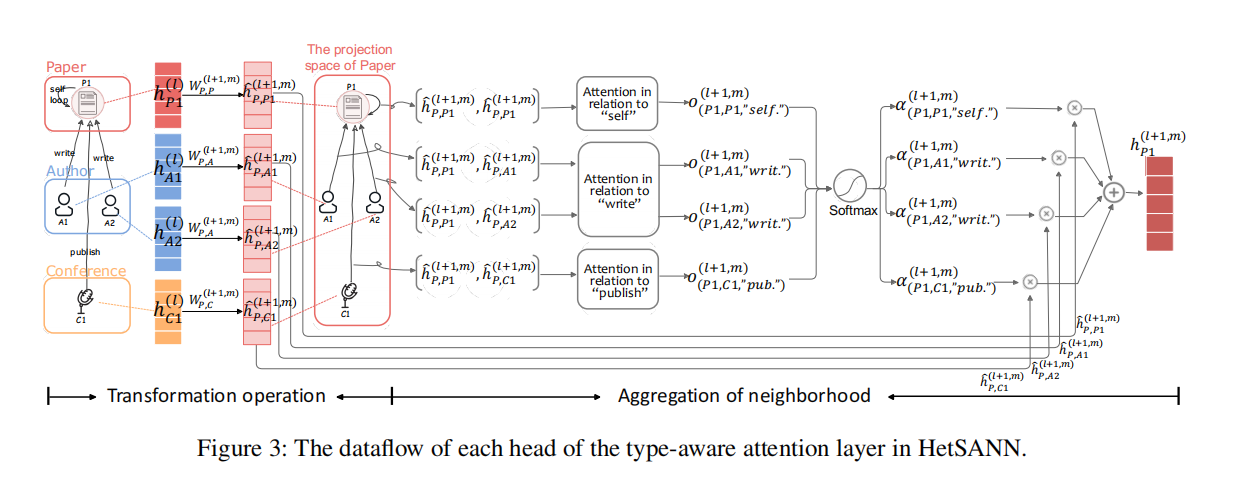
如上图所示,每个头部由两个部分构成:转化操作和邻域信息的聚合
-
Transformation Operation (C1) :
首先,应用线性变化W对节点 j j j的邻居节点进行转换,例如上图中作者A1映射到文章空间P1.
h ^ ϕ ( j ) , i ( l + 1 , m ) = W ϕ ( j ) , ϕ ( i ) ( l + 1 , m ) h i ( l ) \hat{h}^{(l+1,m)}_{\phi(j),i}=W^{(l+1,m)}_{\phi(j),\phi(i)}h_i^{(l)} h^ϕ(j),i(l+1,m)=Wϕ(j),ϕ(i)(l+1,m)hi(l)
其中, l l l表示第 l l l层。 -
Aggregation of Neighborhood (C2)
为了保留节点间不同类型的关系,采用 ∣ R ∣ |R| ∣R∣个注意力打分函数,如 F l + 1 , m = { f r ( l + 1 , m ) ∣ r ∈ R } F^{l+1,m}=\{f_r^{(l+1,m)}|r\in R\} Fl+1,m={fr(l+1,m)∣r∈R}。对于节点j的每条边 e = ( i , j , r ) ∈ ε j e=(i,j,r)\in \varepsilon_j e=(i,j,r)∈εj
o e l + 1 , m = σ ( f r ( l + 1 , m ) ( h ^ ϕ ( j ) , j ( l + 1 , m ) , h ^ ϕ ( j , i ) ( l + 1 , m ) ) ) o_e^{l+1,m}=\sigma(f_r^{(l+1,m)}(\hat{h}^{(l+1,m)}_{\phi(j),j},\hat{h}^{(l+1,m)}_{\phi(j,i)})) oel+1,m=σ(fr(l+1,m)(h^ϕ(j),j(l+1,m),h^ϕ(j,i)(l+1,m)))
σ \sigma σ是激活函数LeakyReLU,注意力系数 o e ( l + 1 , m ) o_e^{(l+1,m)} oe(l+1,m)反映边 e e e对节点 j j j的重要性程度。为所有类型的边采用相同形式的注意力机制,但是参数不同,常见的注意力打分函数concat product,GAT也采用这种
f r ( l + 1 , m ) ( e ) = [ h ^ ϕ ( j ) , j ( l + 1 , m ) T ∣ ∣ h ^ ϕ ( j , i ) ( l + 1 , m ) T ] a r ( l + 1 , m ) f^{(l+1,m)}_r(e)=[{\hat{h}^{(l+1,m)}_{\phi(j),j}}^T||{\hat{h}^{(l+1,m)}_{\phi(j,i)}}^T]a_r^{(l+1,m)} fr(l+1,m)(e)=[h^ϕ(j),j(l+1,m)T∣∣h^ϕ(j,i)(l+1,m)T]ar(l+1,m)
其中 a r ( l + 1 , m ) ∈ R 2 n ϕ ( j ) ( l + 1 , m ) a_r^{(l+1,m)}\in \mathbb{R}^{2n_{\phi(j)}^{(l+1,m)}} ar(l+1,m)∈R2nϕ(j)(l+1,m)是可训练的注意力系数,该参数在类型为 r r r的边中共享。对异构的边使用注意力机制,注意力系数归一化如下:
α e ( l + 1 , m ) = e x p ( o e ( l + 1 , m ) ) / ∑ k ∈ ε j e x p ( o k ( l + 1 , m ) ) \alpha_e^{(l+1,m)}=exp(o_e^{(l+1,m)})/\sum_{k\in\varepsilon_j}exp(o_k^{(l+1,m)}) αe(l+1,m)=exp(oe(l+1,m))/k∈εj∑exp(ok(l+1,m))
由此得到了邻居节点和 j j j在同一空间的表示,已经 j j j向量的权重,由此,计算得到节点 j j j的邻居聚合,
h j ( l + 1 , m ) = σ ( ∑ e = ( i , j , r ) ∈ ε j α e ( l + 1 , m ) h ^ ϕ ( j ) , i ( l + 1 , m ) ) h_j^{(l+1,m)}=\sigma(\sum_{e=(i,j,r)\in\varepsilon_j}\alpha_e^{(l+1,m)}\hat{h}^{(l+1,m)}_{\phi(j),i}) hj(l+1,m)=σ(e=(i,j,r)∈εj∑αe(l+1,m)h^ϕ(j),i(l+1,m))
当节点 i i i和节点 j j j之间的边存在多种类型,都 j j j的隐状态就要和对应的权重 a l p h a alpha alpha多次相乘。对上式采用M头注意力机制,拼接得到输出
h j ( l + 1 ) = ∣ ∣ m = 1 M h j ( l + 1 , m ) h_j^{(l+1)}=||_{m=1}^M h_j^{(l+1,m)} hj(l+1)=∣∣m=1Mhj(l+1,m)
HetSANN的聚合式基于原始边(raw links)而不是基于元路径的,因此需要更多层,因此HetSANN可以捕获到高阶的相似度信息。为了更好的训练,采用残差连接的机制,重写上式,得到
h j ( l + 1 ) = h j ( l ) + ∣ ∣ m = 1 M h j ( l + 1 , m ) h_j^{(l+1)}=h_j^{(l)}+||_{m=1}^M h_j^{(l+1,m)} hj(l+1)=hj(l)+∣∣m=1Mhj(l+1,m)
Model Training and Three Extensions
TAL输出了每个节点的低维表示,如 h j = h j ( L ) h_j=h_j^{(L)} hj=hj(L),为了面向具体任务(节点分类),采用一层全连接层和一层softmax构成分类器,最小化交叉熵损失
F c l a s s = − ∑ i ∈ V p y i l o g y i ~ F_{class}=-\sum_{i\in V_p} y_i log\tilde{y_i} Fclass=−i∈Vp∑yilogyi~
y i y_i yi和 y i ~ \tilde{y_i} yi~分别为节点 i i i的真实值和预测值
- E1: Multi-task Learning
- E2: Voices-sharing Product
- E3: Cycle-consistency Loss
Experiments
数据集IMDB,DBLP,AMiner,对比其它的模型DeepWalk、metapath2vec、HERec、HAN、GCN、R-GCN、GAT,采用各种变形的方法,其中.M,.R,.V分别对应 multi-task learning to optimize the parameters, voices-sharing product in relations attention mechanism 和cycle-consistency loss to retain the transformation between vertices,