1.Kafka数据积压如何处理?
1. 实时/消费任务挂掉导致的消费滞后
a. 任务重新启动后直接消费最新的消息,对于"滞后"的历史数据采用离线程序进行"补漏"。b. 任务启动从上次提交offset处开始消费处理
如果积压的数据量很大,需要增加任务的处理能力,比如增加资源,让任务能尽可能的快速消费处理,并赶上消费最新的消息
2. Kafka分区少了
如果数据量很大,合理的增加Kafka分区数是关键。如果利用的是Spark流和Kafka direct approach方式,也可以对KafkaRDD进行repartition重分区,增加并行度处理。
3. 由于Kafka消息key设置的不合理,导致分区数据不均衡
可以在Kafka producer处,给key加随机后缀,使其均衡。
2.Kafka的分区为什么没有设计读写分离?
主写从读也就是读写分离,可以均摊一定的负载,却不能做到完全的负载均衡。
比如对于数据写压力很大而读压力很小的情况,从节点只能分摊很少的负载压力,而绝大多数压力还是在主节点上。
而在 Kafka 中却可以达到很大程度上的负载均衡,而且这种均衡是在主写主读的架构上实现的。
Kafka 的生产消费模型,如下图所示。

在 Kafka 集群中有3个分区,每个分区有3个副本,正好均匀地分布在 3个 broker 上。
灰色阴影的代表 leader 副本,非灰色阴影的代表 follower 副本,虚线表示 follower 副本从 leader 副本上拉取消息。
当生产者写入消息的时候,都写入 leader 副本,对于图中的情形,每个 broker 都有消息从生产者流入。
当消费者读取消息的时候,也是从 leader 副本中读取的,对于图中的情形,每个 broker 都有消息流出到消费者。
我们很明显地可以看出,每个 broker 上的读写负载都是一样的,这就说明 Kafka 可以通过主写主读实现主写从读实现不了的负载均衡。
总的来说,Kafka 只支持主写主读有几个优点:
1.可以简化代码的实现逻辑,减少出错的可能;
2.将负载粒度细化均摊,与主写从读相比,不仅负载效能更好,而且对用户可控;
3.没有延时的影响;
4.在副本稳定的情况下,不会出现数据不一致的情况。
3. Kafka为什么读写效率高
1.partition 并行处理
2.顺序写磁盘,充分利用磁盘特性
3.利用了现代操作系统分页存储 Page Cache 来利用内存提高 I/O 效率
4.采用了零拷贝技术。Producer 生产的数据持久化到 broker,采用 mmap 文件映射,实现顺序的快速写入。Customer 从 broker 读取数据,采用 sendfile,将磁盘文件读到 OS 内核缓冲区后,转到 NIO buffer进行网络发送,减少 CPU 消耗。
4. kafka中生产数据的时候,如何保证写入的容错性?
1.Topic 分区副本
Kafka 的分区多副本架构是 Kafka 可靠性保证的核心,把消息写入多个副本可以使 Kafka 在发生崩溃时仍能保证消息的持久性。
2.Producer 往 Broker 发送消息
Kafka 在 Producer 里面提供了消息确认机制。也就是说我们可以通过配置来决定消息发送到对应分区的几个副本才算消息发送成功。通过 request.required.acks 参数设置,参数支持以下三种值:
acks = 0:意味着如果生产者能够通过网络把消息发送出去,那么就认为消息已成功写入 Kafka 。
acks = 1:意味若 Leader 在收到消息并把它写入到分区数据文件(不一定同步到磁盘上)时会返回确认或错误响应。
acks = all(这个和 request.required.acks = -1 含义一样):意味着 Leader 在返回确认或错误响应之前,会等待所有同步副本都收到悄息。
根据实际的应用场景,我们设置不同的 acks,以此保证数据的可靠性。
**3.Producer 发送消息还可以选择同步(默认,通过 producer.type=sync 配置) 或者异步(producer.type=async)模式。**如果设置成异步,虽然会极大的提高消息发送的性能,但是这样会增加丢失数据的风险。如果需要确保消息的可靠性,必须将 producer.type 设置为 sync。
4.Leader 选举
每个分区的 leader 会维护一个 ISR 列表,ISR 列表里面就是 follower 副本的 Borker 编号,只有跟得上 Leader 的 follower 副本才能加入到 ISR 里面,这个是通过 replica.lag.time.max.ms 参数配置的。只有 ISR 里的成员才有被选为 leader 的可能。
当 Leader 挂掉了,而且 unclean.leader.election.enable=false 的情况下,Kafka 会从 ISR 列表中选择第一个 follower 作为新的 Leader,因为这个分区拥有最新的已经 committed 的消息。通过这个可以保证已经 committed 的消息的数据可靠性。
综上所述,为了保证数据的可靠性,我们最少需要配置一下几个参数:
producer 级别:acks=all(或者 request.required.acks=-1),同时发生模式为同步 producer.type=sync
topic 级别:设置 replication.factor>=3,并且 min.insync.replicas>=2
broker 级别:关闭不完全的 Leader 选举,即 unclean.leader.election.enable=false
5. 说说Kafka的ISR副本同步队列
每个分区的 leader 会维护一个 ISR 列表,ISR 列表里面就是 follower 副本的 Borker 编号,只有跟得上 Leader 的 follower 副本才能加入到 ISR 里面,这个是通过 replica.lag.time.max.ms 参数配置的。只有 ISR 里的成员才有被选为 leader 的可能。
当 Leader 挂掉了,Kafka 会从 ISR 列表中选择一个 follower 作为新的 Leader。
6. 哪些场景你会选择Kafka?
消息系统: Kafka 和传统的消息系统一样都具备系统解耦、冗余存储、流量削峰、缓冲、异步通信、扩展性、可恢复性等功能。与此同时,Kafka 还提供了大多数消息系统难以实现的消息顺序性保障及回溯消费的功能。
存储系统: Kafka 把消息持久化到磁盘,相比于其他基于内存存储的系统而言,有效地降低了数据丢失的风险。也正是得益于 Kafka 的消息持久化功能和多副本机制,我们可以把 Kafka 作为长期的数据存储系统来使用,只需要把对应的数据保留策略设置为“永久”或启用主题的日志压缩功能即可。
流式处理平台: Kafka 不仅为每个流行的流式处理框架提供了可靠的数据来源,还提供了一个完整的流式处理类库,比如窗口、连接、变换和聚合等各类操作。
7.Kafka 分区的目的?
分区对于 Kafka 集群:实现负载均衡。
分区对于消费者来说,可以提高并发度,提高吞吐量。
8. Kafka 高效文件存储设计特点?
文件分段: Kafka把topic中一个parition大文件分成多个小文件段(默认1G),通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。
跳表设计: 通过索引信息可以快速定位message和确定response的最大大小。
索引元数据存内存:通过index元数据全部映射到memory,可以避免IO磁盘操作。
稀疏索引: 通过索引文件稀疏存储,可以大幅降低index文件元数据占用空间大小。
9.Kafka 是如何实现高吞吐率的?
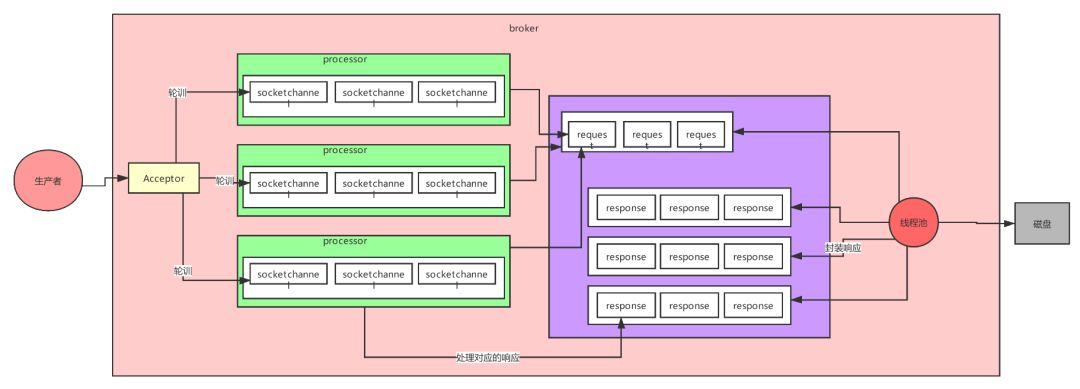
1)三层网络架构设计
Kafka的网络通信模型,主要采用了1(1个Acceptor线程)+ N(N个Processor线程)+ M(M个业务处理线程)。
可以看出Kafka的Broker NIO异步并发处理消息,实现了IO线程异步并发处理消息的机制,大大提升的数据的吞吐量。
三层网络架构的架构图:

2)顺序读写
3)零拷贝
非零拷贝的情况要经过用户缓冲区user space

在Linux kernel2.2之后出现了一种叫做“零拷贝(zero-copy)”系统调用机制,就是跳过“用户缓冲区”的拷贝,建立一个磁盘空间和内存的直接映射,数据不再复制到“用户态缓冲区”。
系统上下文切换减少为2次,可以提升一倍的性能;

4)文件分段
Kafka的队列Topic被分为多个Partition,每个Partition又分为多段segment,所以一个队列中的消息实际上是保存在N个多个片段文件中;
通过分段的方式,每次文件操作都是对一个小文件的操作,非常轻便,同时也增加了并行处理的能力;
5)批量发送
Kafka允许进行批量发送消息,先将消息缓存在内存中,然后一次请求批量发送出去比如可以指定缓存的消息达到某个量就发出去,
或者缓存了固定的时间后就发送出去,如100条消息就发送一次,或者每5秒发送一次。这种策略将大大减少服务端的I/O次数
6)数据压缩
Kafka还支持对消息集合进行压缩,Producer可以通过GZIP或Snappy格式对消息集合进行压缩,压缩的好处就是减少传输的数据量,减轻对网络传输的压力。
Producer压缩之后,在Consumer需要进行解压,虽然增加了CPU的工作,但是在大数据处理上瓶颈在网络,而不是在CPU,这个成本比较值得。
10. 可以对Kafka 进行监控的工具,你知道的有哪些?
Kafka manager / Kafka monitor /Jmx tool
11. Kafka 分区数可以增加或减少吗?说说你自己的理解?
只能增加不能减少,
如果减少分区会报The number of partitions for a topic can only be increased.
减少的分区其数据放到哪里去?是删除,还是保留?删除的话,那么这些没消费的消息就丢了。如果保留这些消息如何放到其他分区里面?追加到其他分区后面的话那么就破坏了 Kafka 单个分区的有序性。
12. 比较RabbitMQ与Apache Kafka

13. 说出三个Kafka 与传统消息系统之间的关键区别
**(1)Kafka 持久化日志,**这些日志可以被重复读取和无限期保留
(2)Kafka 是一个分布式系统:它以集群的方式运行,可以灵活伸缩,在内部通过,复制数据提升容错能力和高可用性
(3)Kafka 支持实时的流式处理
14. Kafka中的分区器、序列化器、拦截器是否了解?它们之间的处理顺序是什么?
整个kafka生产者客户端由两条线程协调运行。
这两条线程分别为主线程和sender线程(发送线程)
主线程的作用就是:由KafkaProducer创建消息,然后通过可能的拦截器-》序列化器-》分区器的作用之后缓存到消息累加器
send线程的作用就是:负责将消息累加器中的消息发送到kafka中。
生产者拦截器可以用来在消息发送前做一些准备工作,比如按照某个规则过滤不符合要求的消息,修改消息的内容等,也可以用来在发送回调逻辑前做一些定制化的需求。
生产者需要用序列化器将对象转换成字节数组才能通过网络发送给kafka.当然消费者需要用对应的反序列化器将kafka的字节数组转换为相应的对象。
经过拦截器,序列化器,之后就会需要确定消息要发往的分区,这里会用到分区器,有默认分区器和自定义分区器。
15. Kafka服务器能接收到的最大信息是多少?
Kafka服务器可以接收到的消息的最大大小是1000000字节。
16. kafka producer如何优化打入速度
提高 batch.size
增加更多 producer 实例
增加 partition 数
设置 acks=-1 时,如果延迟增大:可以增大 num.replica.fetchers(follower 同步数据的线程数)来调解;
17. 新增分区Spark 能发现吗
08版本kafka和Spark Streaming结合的DirectStream这种形式的API里面,是不支持kafka新增分区或者topic检测的。
kafka 0.10版本与SparkStreaming结合支持新增分区检测
18. 如果leader crash时,ISR为空怎么办?
kafka在Broker端提供了一个配置参数:unclean.leader.election这个参数有两个值:
true(默认):允许不同步副本成为leader,由于不同步副本的消息较为滞后,此时成为leader,可能会出现消息不一致的情况。
false:不允许不同步副本成为leader,此时如果发生ISR列表为空,会一直等待旧leader恢复,降低了可用性。
19. 如何保证Kafka数据不丢?
Producer端:
1)unclean.leader.election.enable=false (在server.properties文件中配置)
2)min.insync.replicas=总副本数-1 ,即最小同步副本个数=总副本个数-1(在server.properties文件中配置)
3)acks=-1/all,即当所有isr副本数全部收到消费之后再提交ack (在producer端代码里配置)
4)增大副本数。
5)对于一些由于网络故障等造成发送失败的可重试异常,可以通过设置重试次数(retries)来增加可靠性。
6)kafka producer .send(message,Callback) 可以通过回调函数,来处理发送失败的数据。
Consumer端:
消费端尽量保证手动处理偏移量。保证数据能成功消费,不会造成数据丢失的情况。
20. kafka数据重复的问题如何解决?
1)幂等producer 保证单个分区的只会发送一次,不会出现重复消息
2)事务(transation):保证原子性的写入多个分区,即写入到多个分区的消息要么全部成功,要么全部回滚
3)流式EOS:流处理本质上可看成是“”读取-处理-写入的管道“”。此EOS保证整个过程的操作是原子性。注意,只使用kafka Streams
上面3中EOS语义有着不同的应用范围,
幂等producer只能保证单分区上无重复消息;
事务可以保证多分区写入消息的完整性;
而流处理EOS保证的是端到端(E2E)消息处理的EOS。用户在使用过程中需要根据自己的需求选择不同的EOS。
启用方法:
1)启用幂等producer:在producer程序中设置属性enabled.idempotence=true,但不要设置transational_id.注意是不要设置,而不是设置为空字符串。
2)启用事务支持:在producer程序中设置属性transcational.id为一个指定字符串(你可以认为这是你的额事务名称,故最好七个有意义的名字),同时设置enable.idempotence=true
3)启用流处理EOS:在Kafka Streams程序中设置processing.guarantee=exactly_once