上一节,咱们整理了DOM系列中的第一篇,主要介绍浏览器与DOM相关的知识。从标题中我们可以看出来,今天所要学的东西包含两个部分,第一部分是DOM树,第二部分是遍历DOM。如果你和我一样对于DOM树和遍历DOM是初次接触,那个人建议您花点时间好好看看这两部分的知识。
DOM树
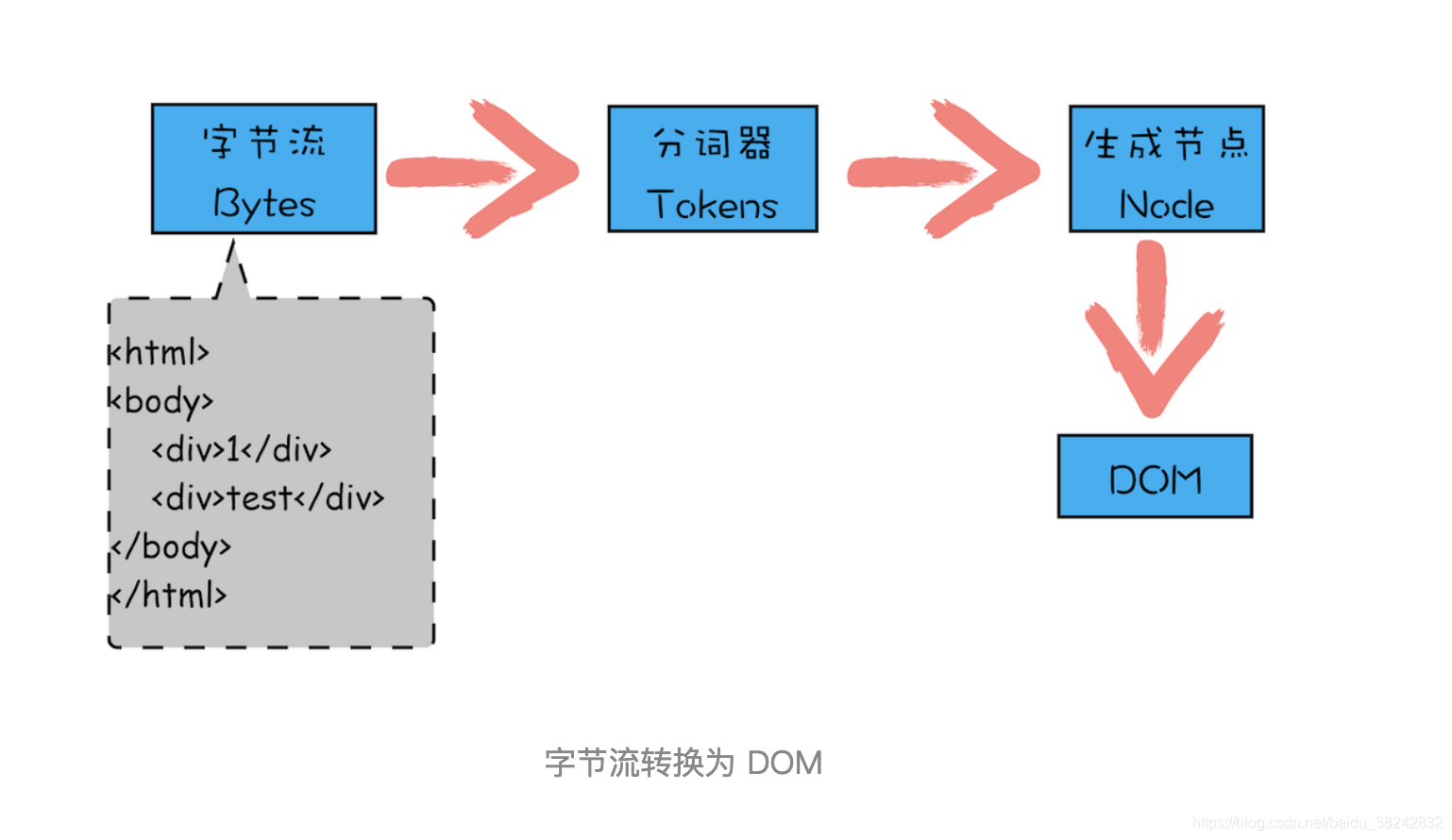
众所周之,HTML文档的主干就是标记(也就是大家熟悉的HTML标签元素)。
根据文档对象模型(即:DOM),每个HTML标签事实上都是一个对象。嵌套的标签被称为之元素(或子标签)。除此之外,标签内的文本也是一个对象。而这些对象都可以使用JavaScript访问。
那么啥是DOM树呢?我们先来看看现实生活中的例子。想象一棵与所有世代有关系的家庭树(大家熟知的族谱),其包括了:祖父母、父母、孩子、兄弟姐妹等等。我们通常以等级的方式组织豪庭树(族谱)。

上图是一个家族族谱的图。其中Tossico、Akikazu、Hitomi和Takemi是祖父母。而Toshiaki和juliana是父母。另外TK、Yuji、Bruno和Kaio是父母的孩子(其实也是我的兄弟姐妹们)。
除了家族族谱之外,生活中还有另一个示例,那就是一个组织的结构层次,比如:

而在HTML中,DOM其实也类似一棵树的,它和前面所举例的家族族谱,组织机构图是类似的,HTML中DOM就是一棵树。

DOM的一个示例
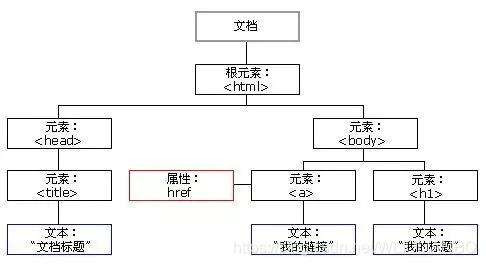
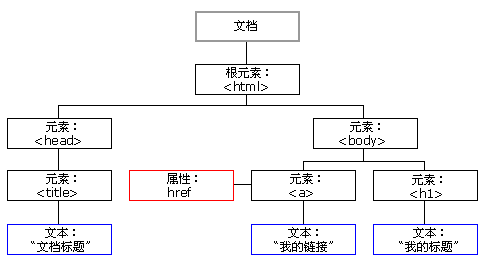
我们来看一个DOM的示例,比如下面这样的一个HTML文档:
<!DOCTYPE HTML>
<html> <head> <title>About elks</title> </head> <body> The truth about elks.
</body>
</html>
DOM将HMTML表示为标记的树结构(也就是大家所说的DOM树),就如下面这样的样子:
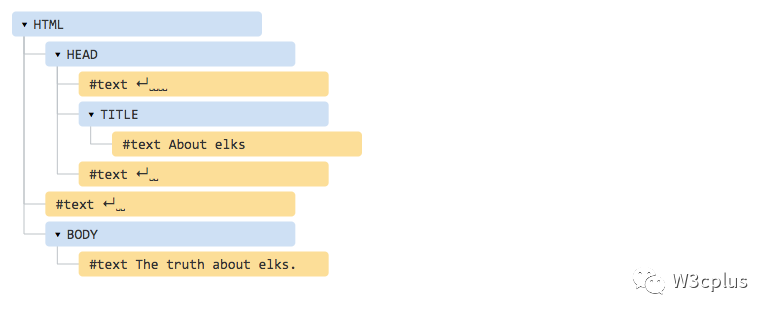
在上面的图中,你可以单击元素的节点,它们的子节点可以展开或者收缩,如下图所示:

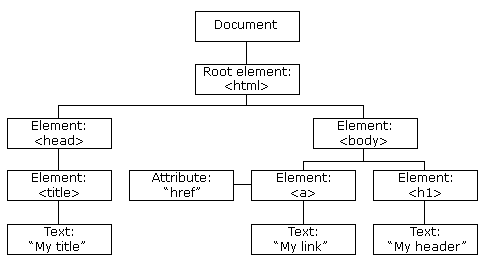
HTML的标签被称为元素(element)节点(或只是元素)。嵌套标签成为一个子元素(也被称为子)。因此,对于一个HTML文档而言,<html>是一个根节点(也被称为根元素),然后<head>和<body>是<html>的子元素。
元素内的文本被称这文本节点,标记为#text。文本节点仅包含一个字符串。它可能没有子元素,也就是说它永远只是树的叶子(没有成为树枝的可能)。
除此之外,要注意文本节点中的两个特殊字符:
换行符:
↵(对应JavaScript中的\n)空白符:
␣
空格和换行符是完全有效的字符,它们形成文本节点并成为DOM的一部分。因此,例如在<head>标签之上的示例中,在<title>这前包含了一些空格,并且该文本成为一个#text节点(它只包含一条换行符和一些空格)。
不过要注意的是,有两个将会除外:
在
<head>标签之前的空格和换行符由于历史原因将被忽略如果我们将一些东西放在
</body>之后,那么它就会自动地移到</body>的前面,正如HTML规范要求的一样,所有内容必须在</body>中一样。因此,在</body>之后可能没有空格
在其他情况之下,一切都很简单。如果文档中有空格(就像任何字符一样),那么它们就会成为DOM中的文本节点,如果我们删除它们,那么就不会有任何东西,也不再会有空格符或换行符的节点。
比如下面这个示例:
<!DOCTYPE HTML><html><head><title>About elks</title></head><body>The truth about elks.</body></html>
上面的HTML结构对应的DOM树如下图所示:
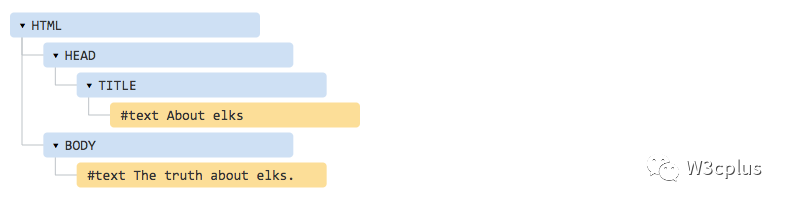
相比上面的截图可以看出来,没有了空格符和换行符的文本节点。
通过上面的示例,可能你对DOM树有一定的了解了。但对一些一技术的定义估计还不是非常的了解,接下来花点时间来说一下DOM中的一些技术定义。
DOM中的技术定义
DOM树(tree)是一个DOM节点(nodes)的集合(拿到生活中来说,树是称为节眯的实体集合)。而其中节点由边(edges)连接。每个节点(node)都包含一个值(value)或数据(data),它可能或有可能没有子节点(child node)。

tree的first node称为root节点。如果root节点由另一个节点连接,则root节点是父节点,连接的节点是子节点。
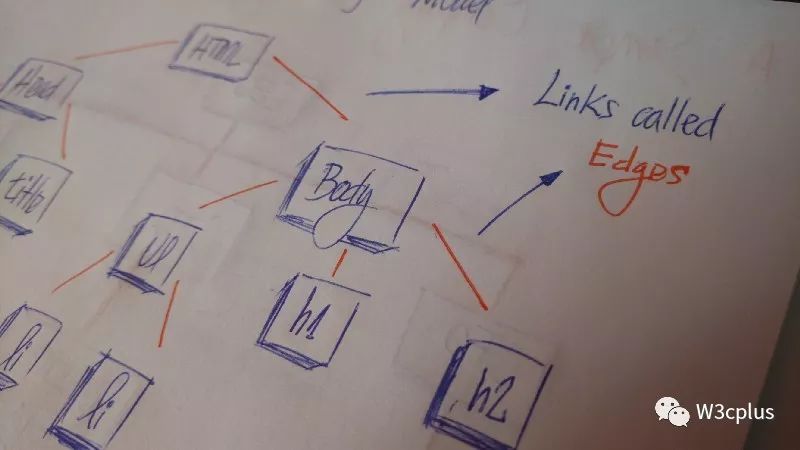
所有的树节点(Tree nodes)都被edges连接在一起。它是树(trees)的重要组成部分,因为它管理节点(nodes)之间的关系。

对于一棵树而言,叶子(leaes)是树(tree)上的最后一个节点(nodes)。它们是没有子节点。就像真正的树一样,DOM也是有根(root)、枝(Element)和叶子(文本节点)。
除此之外,其他还需要理解的重要概念是高度(height)和深度(depth)。树的高度是叶子最长路径的长度;节点的深度是路径到其根的长度。用下图来阐述会更形象一些:

简单的总结一些术语:
root(根节点)是树(tree)最顶端的节点edge(边缘)是两个节点(node)之间的连接child(子节点)是具有父节点的节点parent(父节点)是一个节点,它具有子节点的边缘leaf(树叶)是树中没有子节点的节点height(高度)是叶子最长路径的长度depth(深度)是路径到其根的长度
有关于这方面更深入的介绍可以阅读@TK的《Everything you need to know about tree data structures》一文。
另外@TK的文章还涉及到了深度优先遍历和广度优秀遍历,有关于这两个概念的深入介绍,可以阅读:
querySelectorAll和getElementsByTagNameDemystifying Depth-First Search
Breaking Down Breadth-First Search
其实有关于深度优先遍历和广度优秀遍历在DOM树中的作用并不明显,对于后续的DOM遍历还是有很大的影响。
经过的上面的学习,我们对于DOM树有了一定的了解。除此之外,浏览器对于DOM还具有自动较正的特性。
自动校正
如果浏览器遇到格式错误的HTML,它会自动更正它(校正)。
例如,HTML最顶端的标签总是<html>。即使它不存在文档中 —— 它将存在DOM中,浏览器也会创建它。另外<body>也是一样。
例如,HTML文件只包含一个单词Hello,浏览器将它放置在成<html>和<body>中,并且也会添加所需的<head>。其DOM将是:
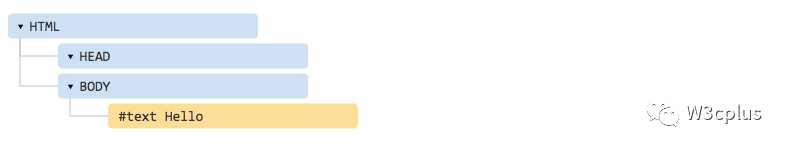
另外,生成DOM时,浏览器会自动处理文档中的错误,比如关闭标签等等。比如下面这样一个无效的文档:
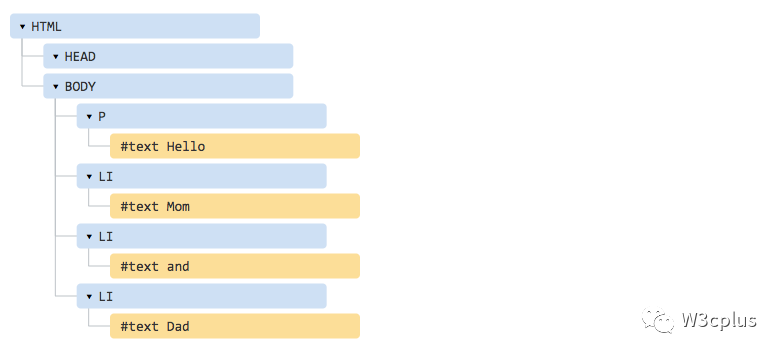
<p>Hello<li>Mom<li>and<li>Dad
事实上,浏览器渲染时,它照样会成为一个正常的 DOM,那是因为浏览器读取标签并会自动修复丢失的部分(比如说关闭标签):
除此之外,还有一个有趣的“特殊情况”,那就是table(表格元素)。根据DOM规范,它必须有<tbody>,但是如果你在HTML文档中忘记写该标签元素时,浏览器会自动在DOM中添加<tbody>标签。比如:
<table id="table"><tr><td>1</td></tr></table>
此时浏览器渲染出来的DOM结构如下:

其他节点类型
我们可以在一个HTML文档中添加更多的标签和在页面中添加注释,比如:
<!DOCTYPE HTML>
<html> <body> The truth about elks.
<ol> <li>An elk is a smart</li> <!-- comment --> <li>...and cunning animal!</li> </ol> </body>
</html>
对于上面的HTML文档,其对应的DOM树如下图所示:

上图中,我们看到了一个新的节点类型 —— 注释节点,标记为 #comment。
你可能会想,为什么要将注释添加到DOM中呢?它不会以任何方式影响视觉上的效果,但是有一个规则,如果某个东西在HTML中,那么它也必须在DOM树中。
HTML中的一切,甚至是注释,都将成为DOM的一部分。
即使是<!DOCTYPE ...>指令也是一个DOM节点。它在DOM树中,在<html>之前。我们不会去触摸那个节点,我们甚至不会在图上画它,但它却实实大大的存在那里。
document对象也是一个DOM节点,表示整个文档。在DOM中,其有12种节点类型。在实际操作中,我们通常使用4种方法:
document:进入DOM的入口点元素节点:HTML标签,树构建块
文本节点:包含文本
注释:有时候我们可以把信息放在这里,但它不会显示出来,不过JavaScript却可以从DOM中读取它
或许你和我一样,希望能对每个HTML文档对应的DOM结构能实时的查看,我们希望有对应的工具能帮助我们。事实上是有类似这样的工具,比如 Live DOM Viewer。只要输入文档,它就会立即显示DOM树结构。
DOM中的空白符
DOM 中的空白符会让处理节点结构时增加不少麻烦。在Mozilla 的软件中,原始文件里所有空白符都会在 DOM 中出现(不包括标签内含的空白符)。这样的处理方式有其必要之处,一方面编辑器中可迳行排列文字、二方面 CSS 里的 white-space: pre 也才能发挥作用。 如此一来就表示:
有些空白符会自成一个文本节点。
有些空白符会与其他文本节点合成为一个文本节点。
换句话说,下面这段 HTML 代码对应的 DOM 节点结构会如附图所示,其中\n代表换行符:
<!-- My document -->
<html> <head> <title>My Document</title> </head> <body> <h1>Header</h1> <p> Paragraph
</p> </body>
</html>
对应的DOM树,如下图所示:

这么一来,要使用 DOM 游走于节点结构间又不想要无用的空白符时,会有点困难。
以下的 JavaScript 代码定义了许多函数,能够让你在处理 DOM 中的空白符时轻松点:

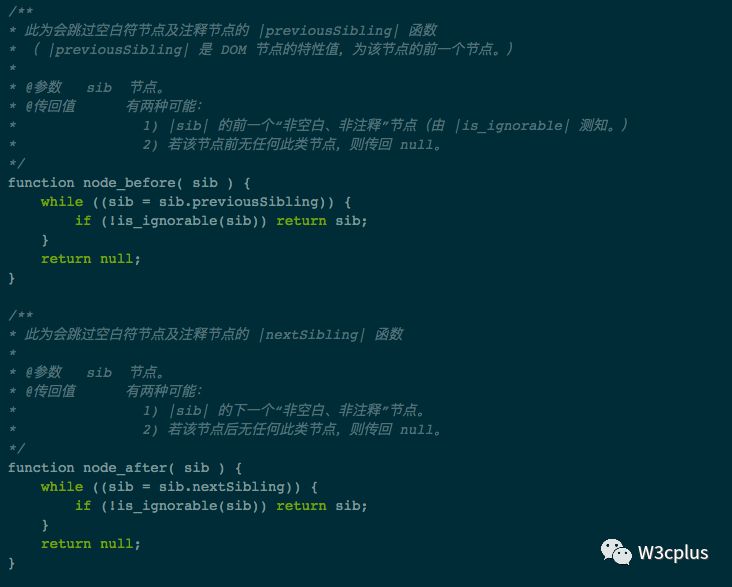


DOM的遍历
如果你阅读了上面的的内容,或许你已经意识到,DOM看起来就像一个巨大的树 —— 一棵巨大的树,它的元素挂载在树枝上。为了获得更多的技术,DOM中的元素被安排在一个层次结构中,它定义了你最终在浏览器中看到的内容:

这个层次结构用于帮助我们组织HTML元素。它还用于帮助你的CSS样式规则理解什么样式适用于哪些东西。从JavaScript角度来看,这个层次结构确实增加了一点复杂性。你会花相当多的时间去弄清楚你现在所有的DOM和你需要去的地方。当我们考虑创建新的元素或移动元素时,这将变得更加明显。这种复杂性是你需要适应的。
找到你的方式
在你找到元素并与它们做一些事情之前,你首先需要了解元素的位置。我解决这个问题,最简单的方法就是从头开始,然后一路向下。这就是我们要做的。
为了更易于帮助在大家理解,先回到上一节中的示例中:
<!DOCTYPE html>
<html> <head> <meta content="DOM, JavaScript, W3cplus" name="keywords" /> <meta content="DOM系列,浏览器和DOM!" name="description" /> <title>LOL! Sea Otter! Little Kid!</title> <link href="style.css" rel="stylesheet"/> </head> <body> <div id="container"> <img src="w3cplus_logo.png"/> <h1>DOM系列学习!</h1> <p class="bodyText">开始学习DOM,这是一个有关于DOM学习的系列教程...<p> <div class="submitButton">next</div> </div> <script src="main.js"></script> </body>
</html>
来自DOM顶部的视图由window、document和html元素组成:
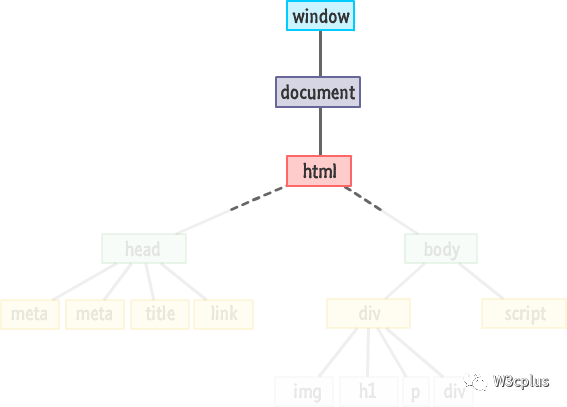
由于这三样东西的重要性,DOM为你提供了通过window、document和document.documentElement访问它们的方法。
var windowObject = window; var documentObject = document; var htmlElement = document.documentElement;
需要注意的一点是,window和document都是全局属性。不必要明确的声明它们,可以直接从容器里拿出来用就行了。
往往,最顶层的树节点可以直接作为document属性使用,比如:
<html> = document.documentElement
顶部文档节点document.documentElement,其对应的就是<html>的DOM节点。另外一个广泛使用的DOM节点是<body>元素,其对应的是document.body:
<body> = document.body
同样的,<head>标签可以用document.head。
不过有一点需要注意:
document.body有可能为null。当脚本在访问不存在的元素时,返回的值将会为null。
比如,当你的脚本在</head>中运行,比如document.body是将返回的值将是null,因为浏览器还没有读取它。但在</body>中的<script>中返回的则是<body>元素:
<html> <head> <script> console.log('From head:', document.body) // => null </script> </head> <body> <script> console.log('From body:', document.body) // => HTMLBodyElement </script> </body>
</html>
上面我们所看到的是html、head和body元素的获取。但事实上,一旦你进入HTML元素级别,你的DOM将开始分支并变得更有趣。在这一点上,你有几种获取DOM的方式。通过使用querySelector()和querySelectorAll()可以帮助你精确地获取你想要获取的DOM元素。或许你已经在项目中大量使用这两种方法了。但事实上,对于许多实际案例来说,这两种方法太过局限。
有时候,你不知道你想去哪里。querySelector()和querySelectorAll()主法在这里无法帮助您。你只想上车然后开车,并想找到你想要去的地方。回到DOM的世界当中时,你会发现自己一直处理这个位置。这就是DOM提供的各种内置属性,所有的Motorcycle Diaries将会帮助你,接下来我们将看看这些属性。
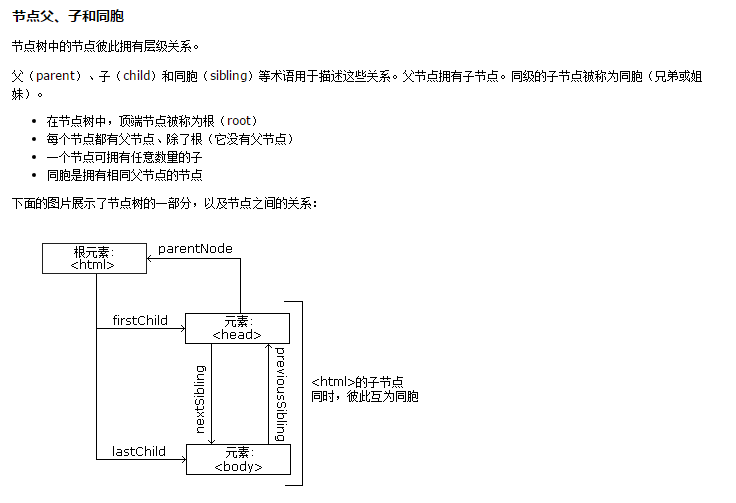
能够帮助你的是知道所有的DOM元素都至少有一个组合,包括父母(Parents)、兄弟姐妹(Siblings)和子元素(Children)。为了更直观的帮助大家理解,来看下图,下图中包含div的script的一个树形图:

div和script是兄弟元素。他们是兄弟元素的原因是他们共有一个相同的父元素body。script元素没有子元素,但是div元素有四个子元素,img、h1、p和div。这四个元素也相互被称为兄弟元素,同样的是因为他们有相同的父元素。这其实很好理解,如果你阅读了文章前面的DOM树相关的内容,你会发现它们就像现实的生活中一样,父母、孩子 和兄弟姐妹的关系基于你所关注的树的位置(对应的就是家族族谱)。几乎每个元素,取决于你看它们的角度,可以扮演多个家庭角色。
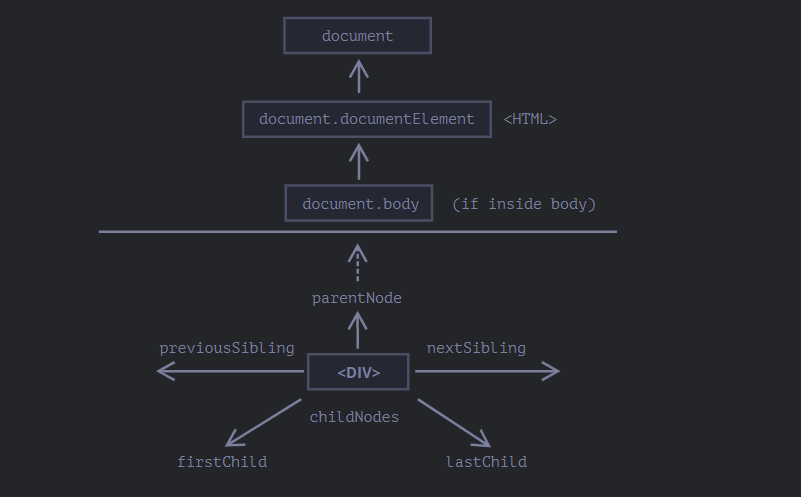
为了更好的理解,DOM中提供了一些对应的属性(这些属性具有一定的依赖关系)。包括:firstChild、lastChild、parentNode、children、previousSibling和nextSibling。从他们的名称上来看,就可以推出这些属性的作用。这几个属性结合在一起将构建一个DOM遍历链接图,允许在DOM节点间找到你想要找到的DOM:
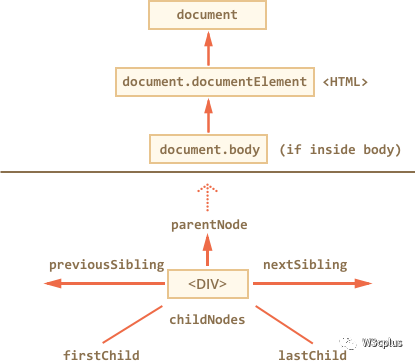
为了更好的理解DOM遍历相关的知识点,咱们接下来将围绕这几个属性来展开。
兄弟姐妹和父母打交道
在这些DOM属性中,最容易处理的是父母和兄弟姐妹。对应的属性有parentNode、previousSibling和nextSibling。下面这张图将帮助你了解这三个属性是如何工作的:

这张图虽然有点零乱,但是你仔细看的话,你可以理清楚它们之间的关系,以及他们之间发生了什么。parentNode属性指向元素的父元素。previousSibling和nextSibling属性允许元素元素它的前一个或下一个兄弟元素。你可以在图中看到箭头的方向指向。最后一行,img的nextSibling是div,相应的div的previousSibling是img元素。不管是通过img或div的parentNode属性都将把我们带入到第二行中的div(事实上就是img和div的元素)。通过上图,大家理解起来是不是很简单。
子元素打交道
上面咱们看到的是如何通过DOM的属性来访问兄弟元素和父元素,事实上,除此之外,DOM还提供一些属性可以访问元素的子元素,比如firstChild、lastChild和children。同样用一图来向大家展示:
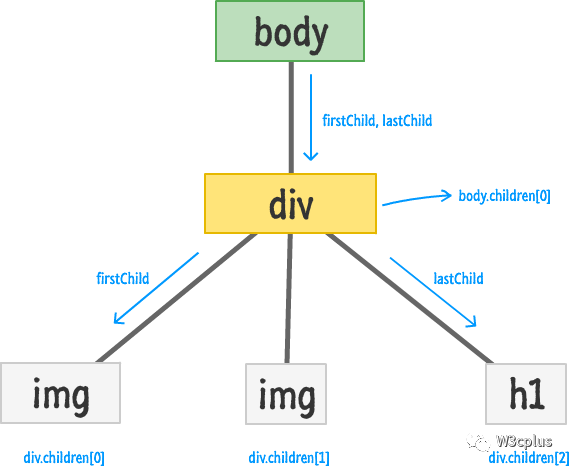
firstChild和lastChild属性是指父元素的第一个和最后一个子元素。如果父类只有一个子元素,就像例子中的body元素一样,firstChild和lastChild都指向相同的元素div。如果一个元素没有子元素,那么firstChild和lastChild属性将返回一个null。
与其他属性相比,其中children属性相对而方要更为复杂一些。当你在父类上访问children属性时,基本上会得到父元素的子元素集合。这个集合并不是数组,但它确实有一些类似数组的能力,就是大家所说的类数组,其具有length属性,可以通过[]或item()来索引集合中具体的元素。比如上图中的div.children[0]访问到的是第一个img元素。
在DOM中获取子节点,除了前面提到的三个属性之外,还有一个childNodes属性,不过它和children有一个很明显的区别:
children只获取子节点(即子元素),而childNodes除了获取的子节点还包括文本节点。
除此之外,还有一个特殊的函数hasChildNodes()可以用来判断某个元素是否包含子节点。
这个时候,你把它们放在一起,你就可以对DOM进行遍历。也可以做一些事情。比如,检查某个元素是否有子元素存在,我们就可以这样做:
let bodyElement = document.body
if (bodyElement.firstChild) {
// 这里做你想做的事情...
}
如果body没有子节点,那么if语奖将返回null。当然,你也可以使用bodyElement.lastChild或bodyElement.children做为if语句的条件。
再来看另一个简单示例,前面提到过了,通过children可以获取某个元素的所有子节点(前提是这个元素有子元素存在)。这个时候得到的是一个类数组,如查你要获取到该元素中的每个子节点,就需要使用for循环来处理:
var bodyElement = document.body;
for (var i = 0; i < bodyElement.children.length; i++) {
var childElement = bodyElement.children[i]; document.writeln(childElement.tagName); }
通过元素遍历DOM
上面咱们看到的是通过DOM节点来遍历DOM。比如childNodes属性,除了可以获取元素节点之外,还可以获取文本节点,甚至是注释节点。但很多时候,对于DOM的操作,咱们只需要获取想要的DOM元素节点,而不需要考虑文本和注释节点。这个时候咱们只需要操作元素节点即可,这对应DOM中操作元素节点的一些属性。同样的使用下图来向大家阐述,易于理解:
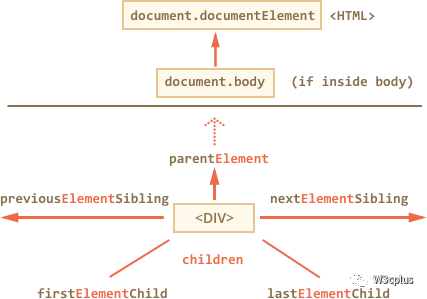
和前面相比,这里的属性多了Element这个词,其对应的含义:
children:元素节点的子元素firstElementChild、lastElementChild:元素的第一个或最后一个子元素previousElementSibling和nextElementSibling:元素的前一个或后一个相邻元素parentElement:元素的父元素
总结
这篇文章是DOM系列的第二篇文章,主要介绍了DOM树和DOM的遍历。前一部分只要介绍了DOM树,简单的理解,任何一个HTML文档都可以类似于家族的族普来绘制对应的DOM树。通过DOM树可以理清楚每个DOM元素(或者说DOM节点)之间的关系。比如,父子关系、兄弟关系等。
另外,在DOM中找到对应的元素是每位JavaScript开发人员都应该需要掌握的技巧之一。这篇文章的后一部分主要向大家介绍了如何对DOM进行遍历,其实就是通过DOM的属性怎么获取DOM的元素或节点。简单的归纳一下,分为:
向上获取,比如
parentNode、parentElement和closest;向下获取,比如
querySelector()、querySelectorAll()、children、firstChildren、lastChildren和childNodes兄弟元素(节点),比如
nextElementSibling、previousElementSibling、nextSibling和previousSibling
如果文中有不对之处,或者你有更好的经验,欢迎在下面的评论中与我们一起分享。最后要说明的是,文章中有些图片来自互联网,如涉及侵权,烦请告之。
文章涉及到图片和代码,如果展示不全给您带来不好的阅读体验,欢迎点击文章底部的 阅读全文。如果您觉得小站的内容对您的工作或学习有所帮助,欢迎关注此公众号。
W3cplus.com
————————————
记述前端那些事,引领web前沿
长按二维码,关注W3cplus
▼