前言
Spark读写HBase本身来说是没啥可以讲的,最早之前都是基于RDD的,网上的资料就太多了,可以参考:
参考链接1
参考链接2
其实都一样,后来有了Hortonworks公司的研发人员研发了一个Apache Spark - Apache HBase Connector,也就是我们熟悉的shc,通过这个类库,我们可以直接使用 Spark SQL 将 DataFrame 中的数据写入到 HBase 中,具体详细的介绍资料可以参考:
shc的github
国内大佬的总结
再后来,就有了Spark HBase Connector (hbase-spark)
一个国外的哥们总结过这几种方式,他写了一篇博客叫《Which Spark HBase Connector to use in 2019?》
写的比较详细,不过很遗憾的是,我测试了hbase-spark后,发现失败了,因为导入jar包后发现仍然缺少import org.apache.spark.sql.execution.datasources.hbase包,有时间重新测试。
其实国内的博客也有这三种方式的简单介绍,只不过没有那么详细。
我这篇博客主要是针对SHC进行的测试
SHC如何使用
研究一个框架和技术,请毫不犹豫的选择官方给的文档和案例,SHC在github中的README里写的十分详细了,我这里就简单的描述一下流程:
最简单的方式:
./bin/spark-submit --class your.application.class --master yarn-client --packages com.hortonworks:shc-core:1.1.1-2.1-s_2.11 --repositories http://repo.hortonworks.com/content/groups/public/ --files /etc/hbase/conf/hbase-site.xml /To/your/application/jar
不少人也试过这个方式,但是我不推荐,因为每提交一次都要下载无数的依赖包。
我建议是编译源码包然后通过Maven引入
这种方式也有不少人使用,大家可以参考这个,不过这个是本地测试的,我一般是直接在集群上使用,这里简单汇总一下流程
-
下载shc源码包
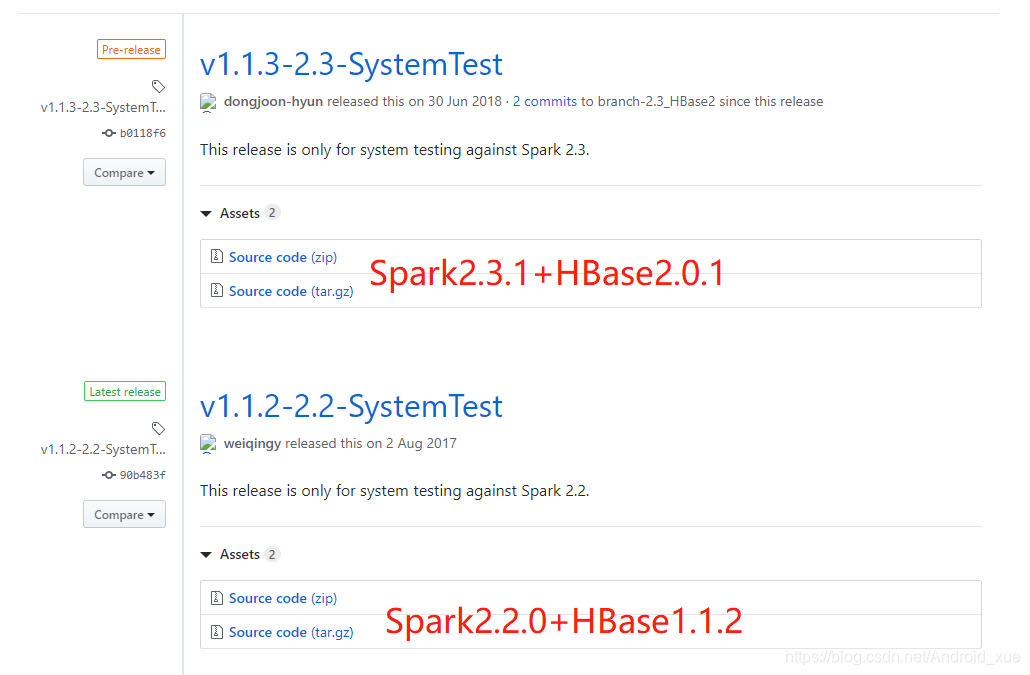
具体下载哪个我个人认为以你集群的HBase版本为准,如果HBase为1.X则下载下面的,2.X则下载上面的即可 -
编译源码包
如果不修改pom文件,那么可以直接在源码包根目录下执行mvn的编译命令:
mvn install -DskipTests
如果要修改,可以参考这个,我个人认为只要大的版本相同,完全可以不用修改,比如我的Spark是2.4.0 HBase是1.2.0,直接编译完全没有问题
- 自己代码的pom文件中引入shc-core依赖
<dependency><groupId>com.hortonworks</groupId><artifactId>shc-core</artifactId><version>1.1.2-2.2-s_2.11</version></dependency>
再导入Scala Spark相关依赖,我pom文件大概是这样的:
<properties><scala.version>2.11.8</scala.version><spark.version>2.4.0</spark.version><java.version>1.8</java.version>
</properties><pluginRepositories><pluginRepository><id>scala-tools.org</id><name>Scala-Tools Maven2 Repository</name><url>http://scala-tools.org/repo-releases</url></pluginRepository>
</pluginRepositories><dependencies><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-compiler</artifactId><version>${scala.version}</version></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-reflect</artifactId><version>${scala.version}</version></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scalap</artifactId><version>${scala.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><version>${spark.version}</version></dependency><dependency><groupId>com.hortonworks</groupId><artifactId>shc-core</artifactId><version>1.1.2-2.2-s_2.11</version></dependency>
</dependencies><build><plugins><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><classifier>dist</classifier><appendAssemblyId>true</appendAssemblyId><descriptorRefs><descriptor>jar-with-dependencies</descriptor></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin><plugin><artifactId>maven-compiler-plugin</artifactId><configuration><source>1.7</source><target>1.7</target></configuration></plugin><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.2.2</version><executions><execution><id>scala-compile-first</id><phase>process-resources</phase><goals><goal>compile</goal></goals></execution></executions><configuration><scalaVersion>${scala.version}</scalaVersion><recompileMode>incremental</recompileMode><useZincServer>true</useZincServer><args><arg>-unchecked</arg><arg>-deprecation</arg><arg>-feature</arg></args><jvmArgs><jvmArg>-Xms1024m</jvmArg><jvmArg>-Xmx1024m</jvmArg></jvmArgs><javacArgs><javacArg>-source</javacArg><javacArg>${java.version}</javacArg><javacArg>-target</javacArg><javacArg>${java.version}</javacArg><javacArg>-Xlint:all,-serial,-path</javacArg></javacArgs></configuration></plugin><plugin><groupId>org.antlr</groupId><artifactId>antlr4-maven-plugin</artifactId><version>4.3</version><executions><execution><id>antlr</id><goals><goal>antlr4</goal></goals><phase>none</phase></execution></executions><configuration><outputDirectory>src/test/java</outputDirectory><listener>true</listener><treatWarningsAsErrors>true</treatWarningsAsErrors></configuration></plugin></plugins>
</build>
代码编写
我这里实现了一个简单的场景,就是Spark从Hive表读取数据然后写入HBase,以及Spark从HBase中读取数据然后写入到Hive
先创建Hive表,并导入测试数据:
CREATE TABLE employee(id STRING,name STRING,age INT,city STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';准备数据
1,张三,23,北京
2,李四,24,上海
3,王五,25,重庆
4,赵六,26,天津
5,田七,27,成都
6,Lily,16,纽约
7,Jack,15,洛杉矶
8,Rose,18,迈阿密LOAD DATA LOCAL INPATH '/data/release/employee.txt' INTO TABLE employee;
SparkReadHive2HBase的代码:
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.execution.datasources.hbase.HBaseTableCatalogobject SparkReadHive2HBase {def main(args: Array[String]): Unit = {val catalog =s"""{|"table":{"namespace":"default", "name":"employee"},|"rowkey":"id",|"columns":{|"id":{"cf":"rowkey", "col":"id", "type":"string"},|"name":{"cf":"person", "col":"name", "type":"string"},|"age":{"cf":"person", "col":"age", "type":"int"},|"city":{"cf":"address", "col":"city", "type":"string"}|}|}""".stripMarginval spark = SparkSession.builder().appName(name = s"${this.getClass.getSimpleName}").config("spark.debug.maxToStringFields", "100").config("spark.yarn.executor.memoryOverhead", "2048").enableHiveSupport().getOrCreate()import spark.sqlsql(sqlText = "select * from employee").write.options(Map(HBaseTableCatalog.tableCatalog -> catalog, HBaseTableCatalog.newTable -> "4")).format("org.apache.spark.sql.execution.datasources.hbase").save()}
}
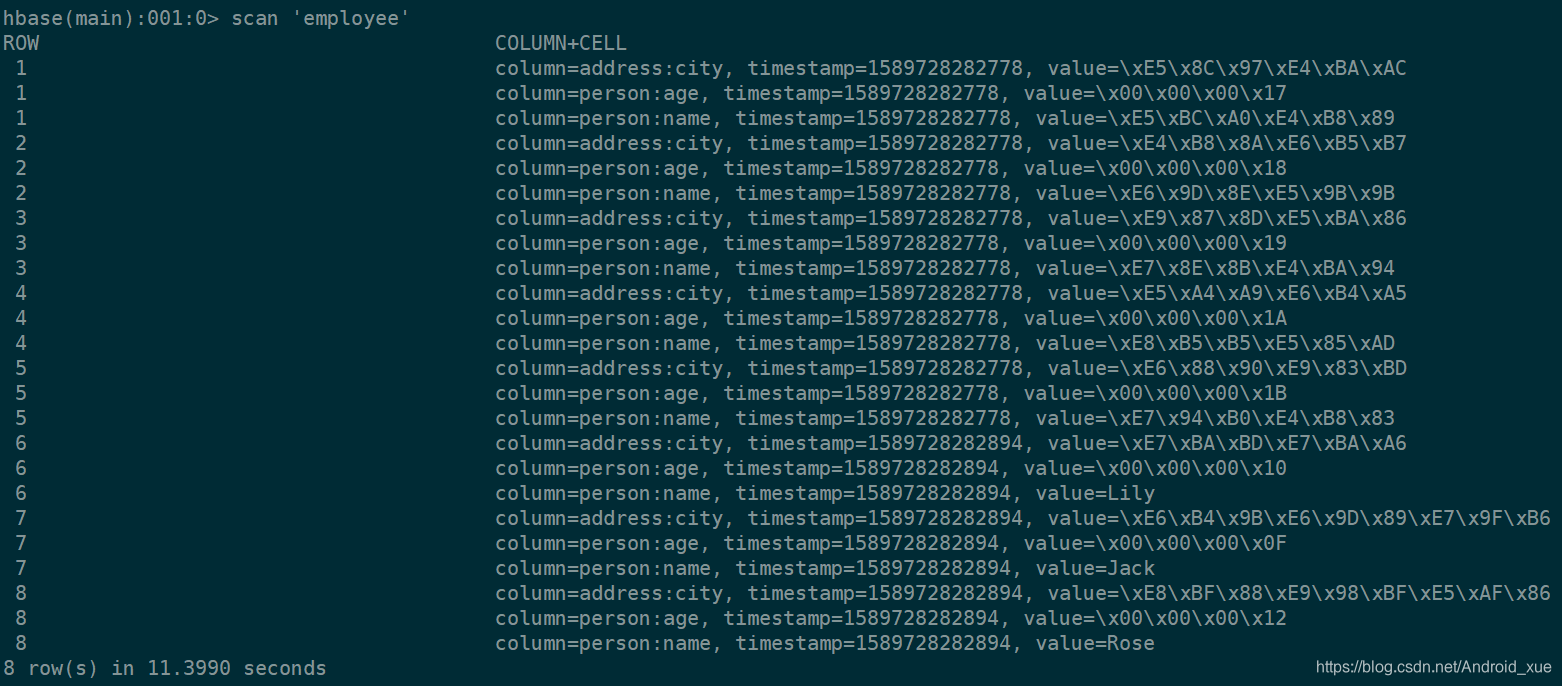
查看数据:
SparkReadHBase2Hive代码:
import org.apache.spark.sql.execution.datasources.hbase.HBaseTableCatalog
import org.apache.spark.sql.{DataFrame, SparkSession}object SparkReadHBase2Hive {def main(args: Array[String]): Unit = {val catalog =s"""{|"table":{"namespace":"default", "name":"employee"},|"rowkey":"id",|"columns":{|"id":{"cf":"rowkey", "col":"id", "type":"string"},|"name":{"cf":"person", "col":"name", "type":"string"},|"age":{"cf":"person", "col":"age", "type":"int"},|"city":{"cf":"address", "col":"city", "type":"string"}|}|}""".stripMarginval spark = SparkSession.builder().appName(name = s"${this.getClass.getSimpleName}").config("spark.debug.maxToStringFields", "100").config("spark.yarn.executor.memoryOverhead", "2048").enableHiveSupport().getOrCreate()import spark.sqlval df: DataFrame = spark.read.options(Map(HBaseTableCatalog.tableCatalog -> catalog)).format("org.apache.spark.sql.execution.datasources.hbase").load()df.createOrReplaceTempView("view1")sql("select * from view1 where age >= 18").write.mode("overwrite").saveAsTable("employee2")spark.stop()}
}
查看Hive中employee2表的数据:

如何提交
首先用Maven打完Jar包会有两个,我们要选择的一定是带依赖的jar包,虽然很大,但是因为我们集群没有相应的Jar包,因此选择大的Jar包
spark2-submit \
--class SparkReadHive2HBase \
--files /etc/hbase/conf/hbase-site.xml \
--master yarn \
--deploy-mode cluster \
--num-executors 70 \
--executor-memory 20G \
--executor-cores 3 \
--driver-memory 4G \
--conf spark.default.parallelism=960 \
/data/release/hbasespark.jar
这里有个重点:
必须得使用cluster模式,否则报错:
ERROR client.ConnectionManager$HConnectionImplementation: Can't get connection to ZooKeeper: KeeperErrorCode = ConnectionLoss for /hbase
这样的顺利的实现的Spark使用DataFrame读写HBase咯
后记
我在定义HBase目录结构的时候,发生了一点小失误,我之前想的时候给employee表rowkey名字起为phone_number,后来不知咋地又想直接用id吧,于是把目录结构写混了:
val catalog =s"""{|"table":{"namespace":"default", "name":"employee"},|"rowkey":"id",|"columns":{|"id":{"cf":"rowkey", "col":"phone_number", "type":"string"},|"name":{"cf":"person", "col":"name", "type":"string"},|"age":{"cf":"person", "col":"age", "type":"int"},|"city":{"cf":"address", "col":"city", "type":"string"}|}|}""".stripMargin
于是报错:
ERROR yarn.ApplicationMaster: User class threw exception: java.lang.UnsupportedOperationException: empty.tail
改为正确的目录结构后就好了:
val catalog =s"""{|"table":{"namespace":"default", "name":"employee"},|"rowkey":"id",|"columns":{|"id":{"cf":"rowkey", "col":"id", "type":"string"},|"name":{"cf":"person", "col":"name", "type":"string"},|"age":{"cf":"person", "col":"age", "type":"int"},|"city":{"cf":"address", "col":"city", "type":"string"}|}|}""".stripMargin