HTTP 专栏课-罗剑锋
🐶 趁毕业之前,系统把计算机知识补充一下。从计算机网络开始,后面会扩展到数据结构、算法设计、设计模式、数据库、软件工程、中间件相关内容。这次先根据罗老师课程补一把计算机网络吧!!
- 破冰篇之01、02.(2022年10月7日)
- 破冰篇之03、04.(2022年10月8日)
01 HTTP的前世今生
任职于欧洲核子研究中心(CERN)的蒂姆·伯纳斯 - 李(Tim Berners-Lee)提出了在互联网上构建超链接文档系统的构想。确定三项技术:URI即统一资源标识符,作为互联网上资源的唯一身份;HTML:即超文本标记语言,描述超文本文档;HTTP:即超文本传输协议,用来传输超文本。

HTTP0.9开始,设计成文档都是只允许GET动作从服务器上获取HTML文档,并且在响应请求之后立即关闭连接。
HTTP1.0,增加了HEAD、POST新方法,增加了响应状态码,标记可能的错误原因;引入了协议版本号概念;引入了 HTTP Header(头部)的概念,让 HTTP 处理请求和响应更加灵活;传输的数据不再仅限于文本。
HTTP1.1 ,增加了 PUT、DELETE 等新的方法;增加了缓存管理和控制;明确了连接管理,允许持久连接;允许响应数据分块
(chunked),利于传输大文件;强制要求 Host 头,让互联网主机托管成为可能。
HTTP2.0,2015年的,卖点:二进制协议,不再是纯文本;可发起多个请求,废弃了 1.1 里的管道;使用专用算法压缩头部,减少数据传输量;允许服务器主动向客户端推数据;安全性要求加密通信。
HTTP3.0,Google发明QUIC协议,靠这Chrome推动,2018年获得批准
02 HTTP是什么?HTTP又不是什么?
HTTP:超文本+传输+协议,就是一个协议
协议的特点:两个以上的参与者、对参与者的一种行为约定和规范。
HTTP 是一个用在计算机世界里的协议。它使用计算机能够理解的语言确立了一种计算机之间交流通信的规范,以及相关的各种控制和错误处理方式。
传输的特点:
第一:HTTP是一个双向协议,我们把先发起传输动作的 A 叫做请求方,把后接到传输的 B 叫做应答方或者响应方。
第二:数据虽然是在 A 和 B 之间传输,但并没有限制只有 A 和 B 这两个角色,允许中间有“中转”或者“接力”。
超文本的特点:
所谓“文本”(Text),就表示 HTTP 传输的不是 TCP/UDP 这些底层协议里被切分的杂乱无章的二进制包(datagram),而是完整的、有意义的数据,可以被浏览器、服务器这样的上层应用程序处理。超文本的特点就是包含文字、图片、音、视、超链接等。
总结:“HTTP 是一个在计算机世界里专门在两点之间传输文字、图片、音频、视频等超文本数据的约定和规范”。
在互联网世界里,HTTP 通常跑在 TCP/IP 协议栈之上,依靠 IP 协议实现寻址和路由、TCP协议实现可靠数据传输、DNS 协议实现域名查找、SSL/TLS 协议实现安全通信。
03 HTTP 相关概念
在 HTTP 协议里,浏览器的角色被称为“User Agent”即“用户代理”,意思是作为访问者的“代理”来发起 HTTP 请求。
Web Server, HTTP 协议里响应请求的主体,两个层面:硬件和软件
硬件含义就是物理形式或“云”形式的机器,在大多数情况下它可能不是一台服务器,而是利用反向代理、负载均衡等技术组成的庞大集群。
软件:是提供 Web 服务的应用程序,通常会运行在硬件含义的服务器上,
CDN:“内容分发网络”,应用了 HTTP 协议里的缓存和代理技术,代替源站响应客户端的请求
优点:简单来说,它可以缓存源站的数据,让浏览器的请求不用“千里迢迢”地到达源站服务器,直接在“半路”就可以获取响应。如果 CDN 的调度算法很优秀,更可以找到离用户最近的节点,大幅度缩短响应时间。
爬虫:
- 你觉得 CDN 在对待浏览器和爬虫时会有差异吗?为什么?
CDN 应当是不区分的,因为爬虫本身也是对 Web 资源的访问,且对于爬虫识别并不是 100% 准确的,因此 CDN 只会去计算实际使用了多少资源而不管其中多少来自爬虫; - 你怎么理解 WebService 与 Web Server 这两个非常相似的词?
Web Service 是网络服务实体,而 Web Server 是网络服务器,后者的存在是为了承载前者。
04 HTTP 相关的各种协议
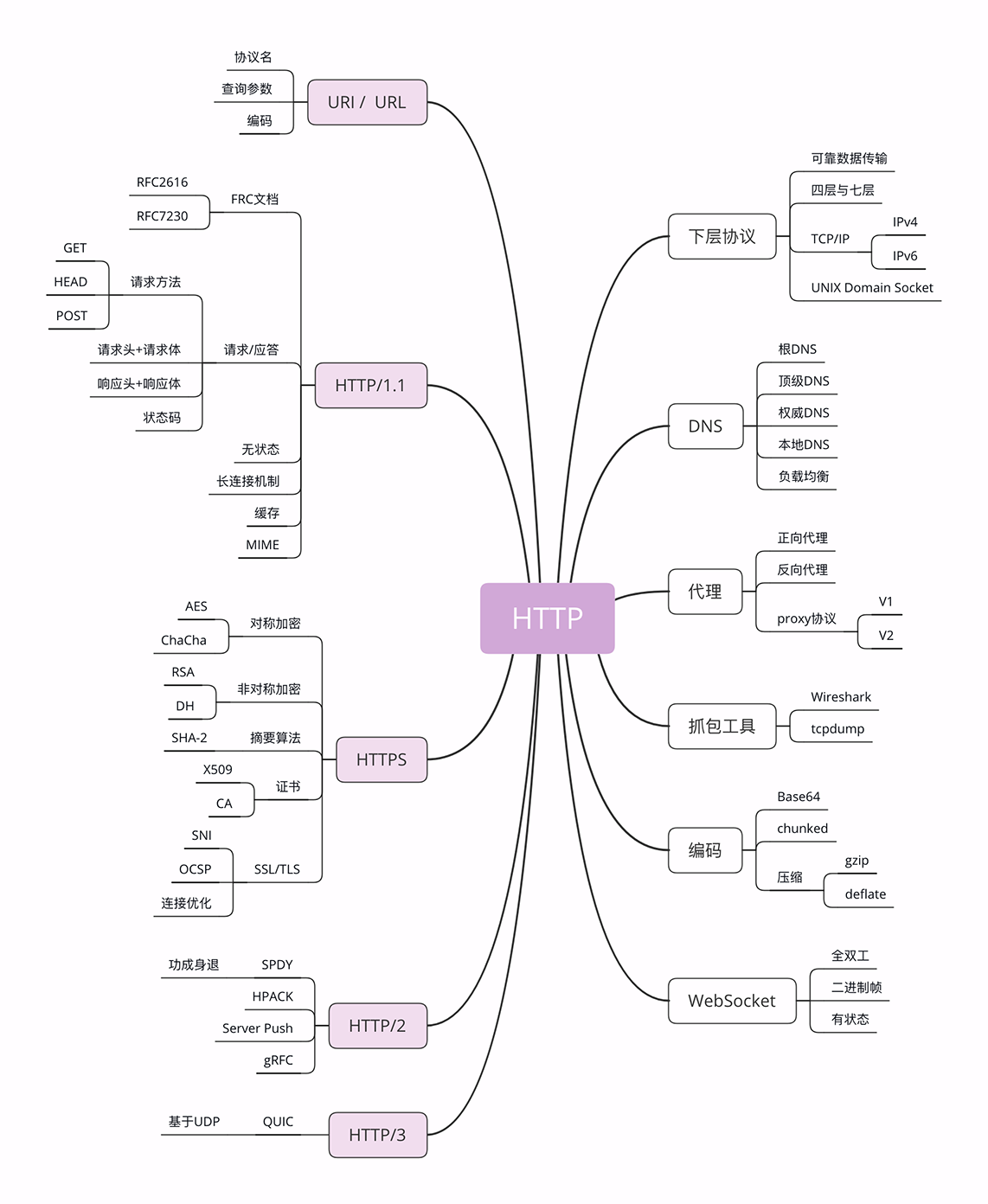
TCP/IP
IP 协议是“Internet Protocol”的缩写,主要目的是解决寻址和路由问题,以及如何在两点间传送数据包。
DNS:
HTTPS:HTTP over SSL/TLS,SSL 使用了许多密码学最先进的研究成果,综合了对称加密、非对称加密、摘要算法、数字签名、数字证书等技术
代理:代理(Proxy)是 HTTP 协议中请求方和应答方中间的一个环节,作为“中转站”,既可以转发客户端的请求,也可以转发服务器的应答。
- 匿名代理:完全“隐匿”了被代理的机器,外界看到的只是代理服务器;
- 透明代理:顾名思义,它在传输过程中是“透明开放”的,外界既知道代理,也知道客户端;
- 正向代理:靠近客户端,代表客户端向服务器发送请求;
- 反向代理:靠近服务器端,代表服务器响应客户端的请求;
代理在传输过程中插入了一个“中间层”
5. 负载均衡:把访问请求均匀分散到多台机器,实现访问集群化;
6. 内容缓存:暂存上下行的数据,减轻后端的压力;
7. 安全防护:隐匿 IP, 使用 WAF 等工具抵御网络攻击,保护被代理的机器;
8. 数据处理:提供压缩、加密等额外的功能。
05丨常说的“四层”和“七层”到底是什么?
TCP/IP protocol
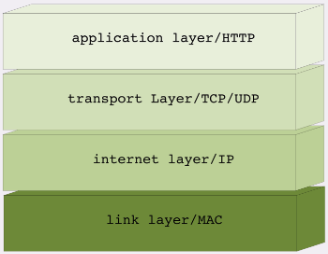
- 链路层,负责在以太网、WiFi 这样的底层网络上发送原始数据包,工作在网卡这个层次,使用 MAC 地址来标记网络上的设备,所以有时候也叫 MAC 层
- “网际层”或者“网络互连层”,
- “传输层”(transport layer)保证数据在 IP 地址标记的两点之间“可靠”地传输
- “应用层”(application layer)
数据包:MAC 层的传输单位是帧(frame),IP 层的传输单位是包(packet),TCP 层的传输单位是段(segment),HTTP 的传输单位则是消息或报文(message)
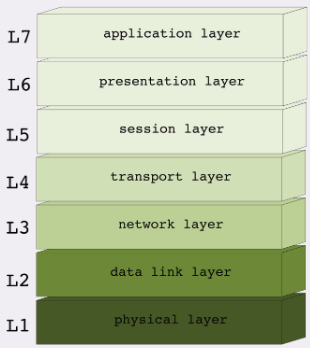
OSI 网络分层模型
TCP/IP 和 OSI 模型的关系
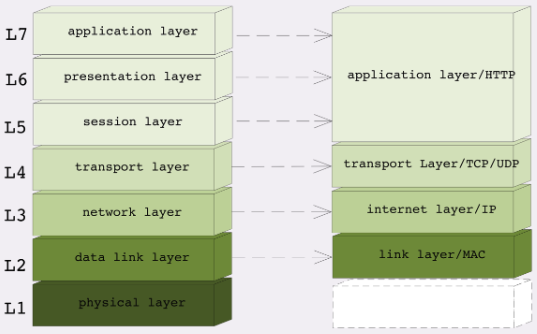
06 | 域名里有哪些门道?
域名是一个有层次的结构,是一串用“.”分隔的多个单词,最右边的被称为“顶级域名”,然后是“二级域名”,层级关系向左依次降低。
DNS 的核心系统是一个三层的树状、分布式服务,基本对应域名的结构
- 根域名服务器(Root DNS Server):管理顶级域名服务器,返回“com”“net”“cn”等顶级域名服务器的 IP 地址;
- 顶级域名服务器(Top-level DNS Server):管理各自域名下的权威域名服务器,比如 com 顶级域名服务器可以返回 apple.com 域名服务器的 IP 地址;
- 权威域名服务器(Authoritative DNS Server):管理自己域名下主机的 IP 地址,比如 apple.com 权威域名服务器可以返回 www.apple.com 的 IP 地址。
“缓存”:(1)网络运行商提供“野生”服务器被称为“非权威域名服务器”,可以缓存之前的查询结果,如果已经有了记录,就无需再向根服务器发起查询,直接返回对应的 IP 地址。(2)操作系统缓存
课下作业
- 在浏览器地址栏里随便输入一个不存在的域名,比如就叫“www. 不存在.com”,试着解释一下它的 DNS 解析过程。
答题方向:浏览器缓存 操作系统缓存 host文件 根域名 顶级域名 返回失败 - 如果因为某些原因,DNS 失效或者出错了,会出现什么后果?
07丨自己动手,搭建HTTP实验环境
软件安装wireshare、openresty(http://openresty.org/en/download.html)、telnet客户端、chorme
基础篇
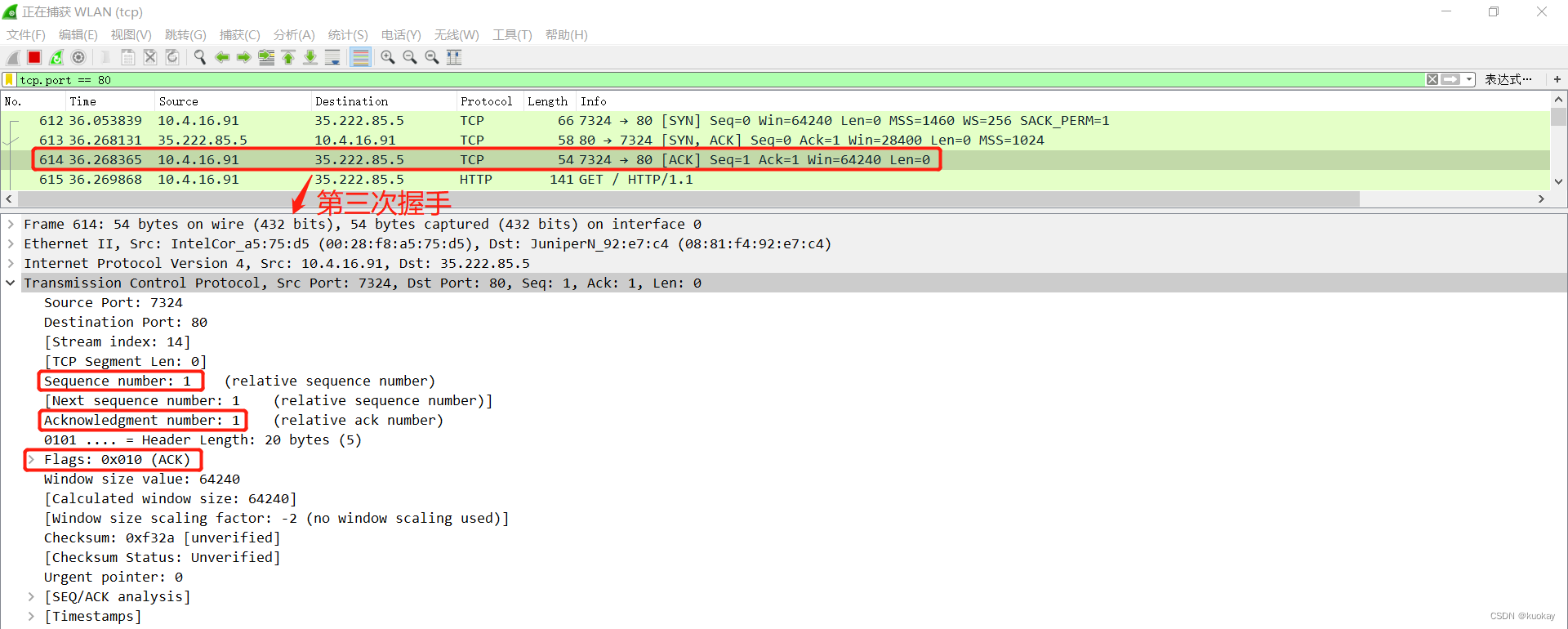
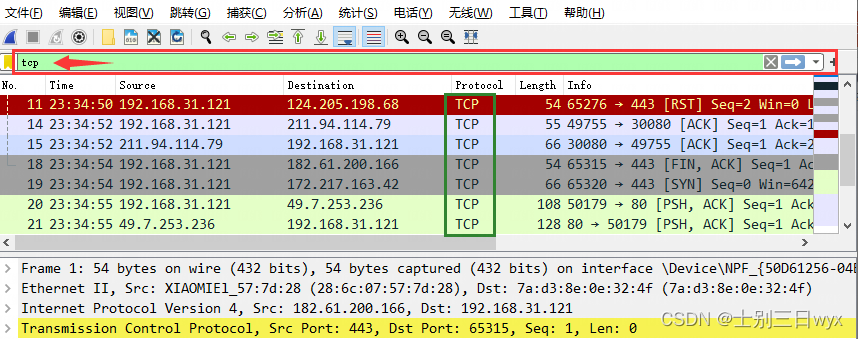
08丨键入网址再按下回车,后面究竟发生了什么?
- HTTP 协议基于底层的 TCP/IP 协议,所以必须要用 IP 地址建立连接;
- 如果不知道 IP 地址,就要用 DNS 协议去解析得到 IP 地址,否则就会连接失败;
- 建立 TCP 连接后会顺序收发数据,请求方和应答方都必须依据 HTTP 规范构建和解析报文;
- 为了减少响应时间,整个过程中的每一个环节都会有缓存(包括本地浏览器缓存、系统host缓存、cdn缓存),能够实现“短路”操作;
- 虽然现实中的 HTTP 传输过程非常复杂,但理论上仍然可以简化成实验里的“两点”模型。
课下作业
你能试着解释一下在浏览器里点击页面链接后发生了哪些事情吗?
这一节课里讲的都是正常的请求处理流程,如果是一个不存在的域名,那么浏览器的工作流程会是怎么样的呢?
09 | HTTP报文是什么样子的?
HTTP协议的请求报文和响应报文的结构基本相同,由三大部分组成:
- 起始行:描述请求或响应的基本信息;
- 头部信息:key-value 形式
- 消息正文:实际传输的数据,它不一定是纯文本,可以是图片、视频等二进制数据。
有的 http 包,只有包头,消息正文是空的,这种情况如果包头很大会占用占用大量的服务器资源,影响运行效率
- 请求行(起始行):简要地描述了客户端想要如何操作服务器端的资源。有三个部分
请求方法、请求目标(URI,标记请求方法要操作的资源)、版本号
GET / HTTP/1.1
状态行
响应报文里的起始行,在这里它不叫“响应行”,而是叫“状态行”(status line),意思是服务器响应的状态。
由三个部分组成。版本号、状态码、原因
状态行:Version | SP | Status Code | SP| Reason|CRLF
HTTP/1.1 200 OK
- 头部字段
头部字段是 key-value 的形式,用“:”分隔,不区分大小写,顺序任意,除了规定的标准头,也可以任意添加自定义字段,实现功能扩展;
HTTP/1.1 里唯一要求必须提供的头字段是 Host,它必须出现在请求头里,标记虚拟主机名。
头部字段需要注意
- 字段名不区分大小写,例如“Host”也可以写成“host”,但首字母大写的可读性更好;
- 字段名里不允许出现空格,可以使用连字符“-”,但不能使用下划线“_”。例如,“test-name”是合法的字段名,而“test name”“test_name”是不正确的字段名;
- 字段名后面必须紧接着“:”,不能有空格,而“:”后的字段值前可以有多个空格;
- 字段的顺序是没有意义的,可以任意排列不影响语义;
- 字段原则上不能重复,除非这个字段本身的语义允许,例如 Set-Cookie。
课下作业
如果拼 HTTP 报文的时候,在头字段后多加了一个 CRLF,导致出现了一个空行,会发生什么?(当作body处理)
讲头字段时说“:”后的空格可以有多个,那为什么绝大多数情况下都只使用一个空格呢?(节省资源)
10 | 应该如何理解请求方法?
目前 HTTP/1.1 规定了八种方法,单词都必须是大写的形式,我先简单地列把它们列出来,后面再详细讲解。
GET:获取资源,可以理解为读取或者下载数据;
HEAD:获取资源的元信息;
POST:向资源提交数据,相当于写入或上传数据;
PUT:类似 POST;
DELETE:删除资源;
CONNECT:建立特殊的连接隧道;
OPTIONS:列出可对资源实行的方法;
TRACE:追踪请求 - 响应的传输路径。