这里写目录标题
- 相关背景介绍
- 相关设计思路介绍
- 项目基础
- 文件系统接口
- 扇区
- 文件结构
- 关于inode
- 为什么淘宝不用小文件存储
- 淘宝网为什么不用普通文件存储海量小数据?
- 设计思路
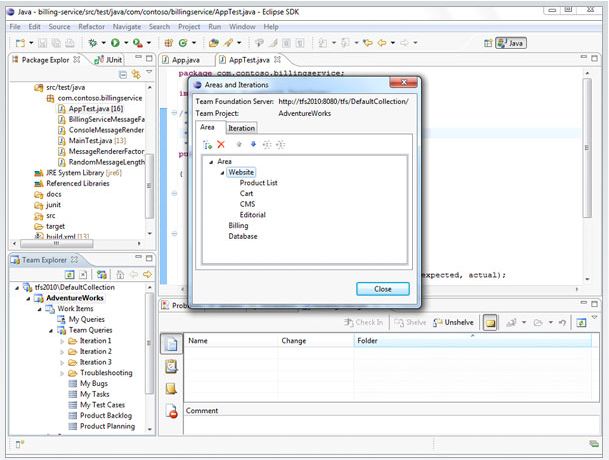
- 关键数据结构哈希表
- 代码日志
- mmp_file.h
- mmap_file.cpp
- file_op.h
- main_mmap_op_file.cpp
- index_handle.cpp
- blockwritetest.cpp
- 总结
相关背景介绍
根据淘宝2016年的数据分析,淘宝卖家已经达到900多万,有上十亿的商品。每一个商品有包括大量的图片和文字(平均:15k),粗略估计下,数据所占的存储空间在1PB 以上,如果使用单块容量为1T容量的磁盘来保存数据,那么也需要1024 x 1024 块磁盘来保存.
思考? 这么大的数据量,应该怎么保存呢?就保存在普通的单个文件中或单台服务器中吗?显然是不可行的。
淘宝针对海量非结构化数据存储设计出了的一款分布式系统,叫TFS,它构筑在普通的Linux机器集群上,可为外部提供高可靠和高并发的存储访问。
相关设计思路介绍
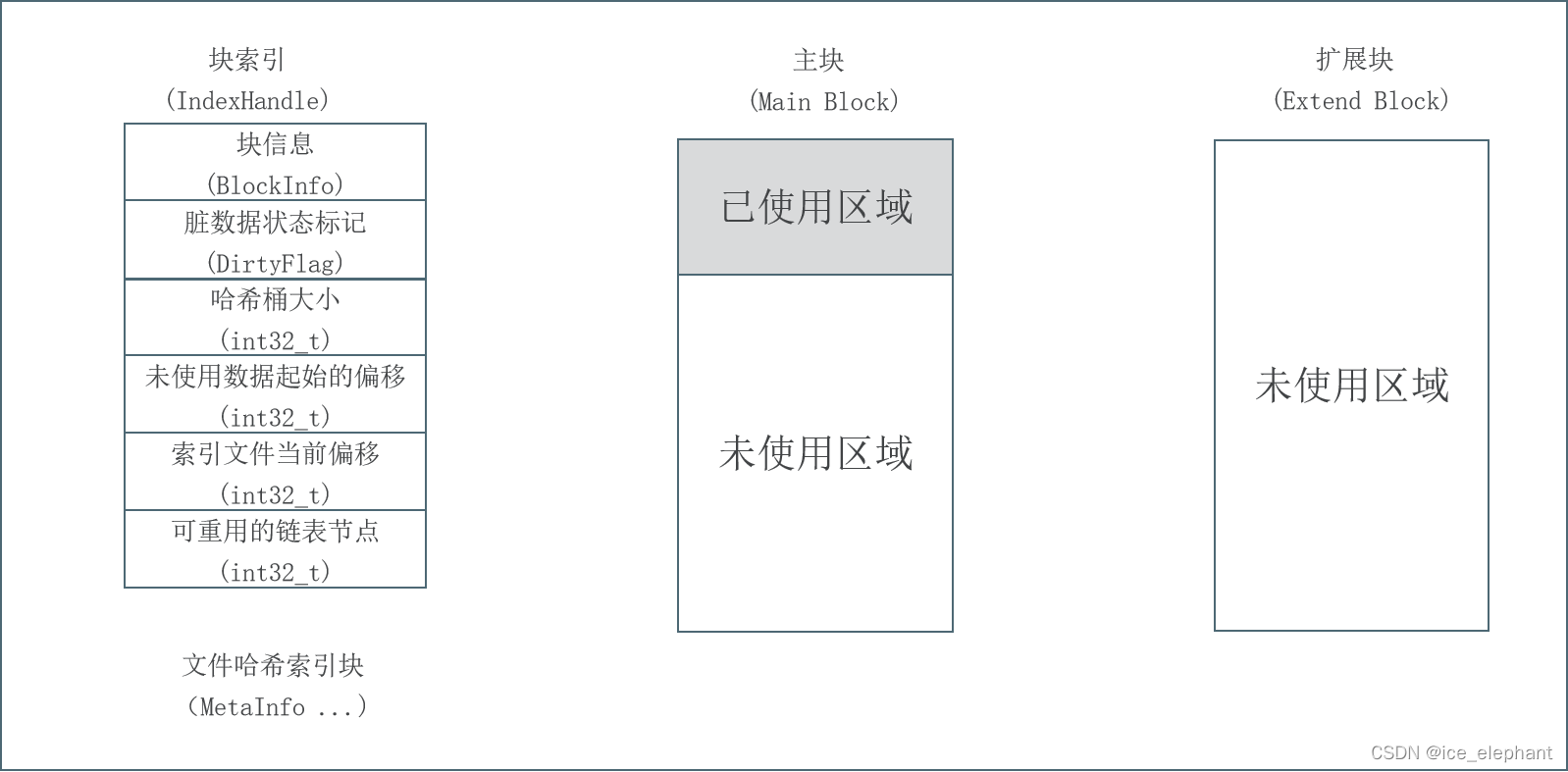
以block文件的形式存放数据文件(一般64M一个block),以下简称为“块”,每个块都有唯一的一个整数编号,块在使用之前所用到的存储空间都会预先分配和初始化。
每一个块由一个索引文件、一个主块文件和若干个扩展块组成,“小文件”主要存放在主块中,扩展块主要用来存放溢出的数据。
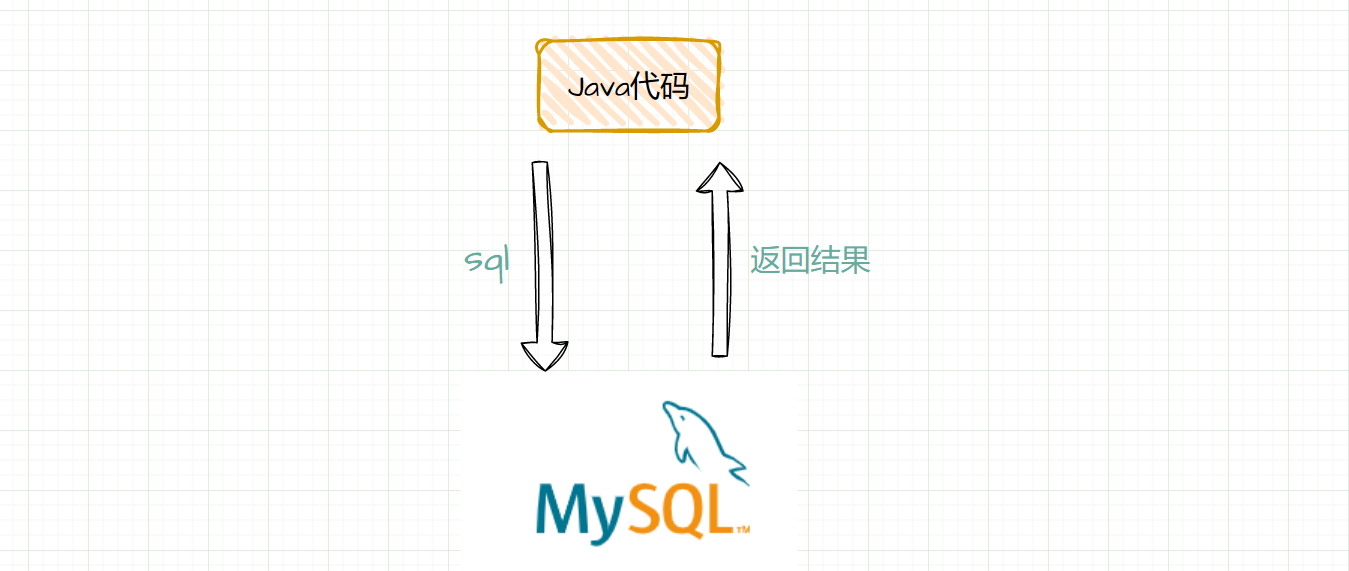
每个索引文件存放对应的块信息和“小文件”索引信息,索引文件会在服务启动是映射(mmap)到内存,以便极大的提高文件检索速度。“小文件”索引信息采用在索引文件中的数据结构哈希链表来实现。
每个文件有对应的文件编号,文件编号从1开始编号,依次递增,同时作为哈希查找算法的Key 来定位“小文件”在主块和扩展块中的偏移量。文件编号+块编号按某种算法可得到“小文件”对应的文件名。
项目基础
文件系统接口
文件系统是一种把数据组织成文件和目录方式,提供基于文件的存取接口,并通过权限控制。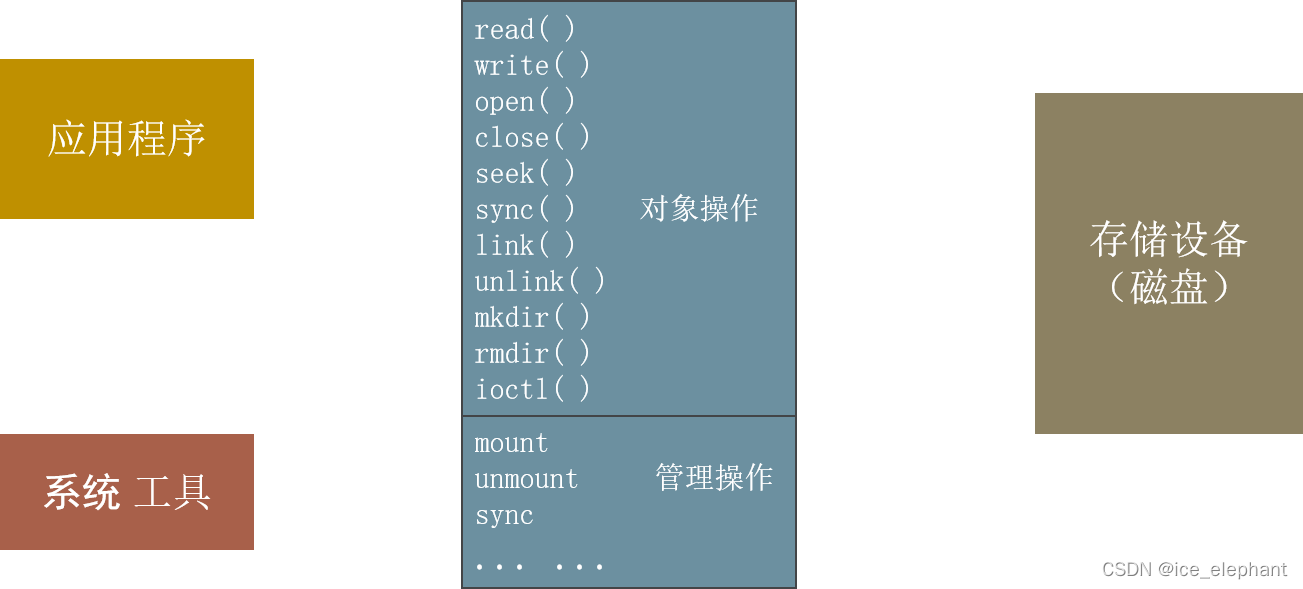
扇区
磁盘读写的最小单位就是扇区,一般每个扇区是 512 字节(相当于0.5KB);
文件的基本单位块 - 文件存取的最小单位。"块"的大小,最常见的是4KB,即连续八个 sector组成一个 block。

在 Linux 系统中可以用 stat 查看文件相关信息
文件结构
目录项区:存放目录下文件的列表信息
文件数据: 存放文件数据
inode区:(inode table) - 存放inode所包含的信息

关于inode
inode - “索引节点”,储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。每个inode都有一个号码,操作系统用inode号码来识别不同的文件。ls -i 查看inode 号
inode节点大小 - 一般是128字节或256字节。inode节点的总数,格式化时就给定,一般是每1KB或每2KB就设置一个inode。一块1GB的硬盘中,每1KB就设置一个inode,那么inode table的大小就会达到128MB,占整块硬盘的12.8%。
为什么淘宝不用小文件存储
- 大规模的小文件存取,磁头需要频繁的寻道和换道,因此在读取上容易带来
较长的延时。

淘宝网为什么不用普通文件存储海量小数据?
- Inode 占用大量磁盘空间,降低了缓存的效果。
设计思路
以block文件的形式存放数据文件(一般64M一个block),以下简称为“块”,每个块都有唯一的一个整数编号,块在使用之前所用到的存储空间都会预先分配和初始化。
每一个块由一个索引文件、一个主块文件和若干个扩展块组成,“小文件”主要存放在主块中,扩展块主要用来存放溢出的数据。
每个索引文件存放对应的块信息和“小文件”索引信息,索引文件会在服务启动是映射(mmap)到内存,以便极大的提高文件检索速度。“小文件”索引信息采用在索引文件中的数据结构哈希链表来实现。
每个文件有对应的文件编号,文件编号从1开始编号,依次递增,同时作为哈希查找算法的Key 来定位“小文件”在主块和扩展块中的偏移量。文件编号+块编号按某种算法可得到“小文件”对应的文件名。
关键数据结构哈希表

代码日志
文件映射类
mmp_file.h
#ifndef MY_LARGE_FILE_H
#define MY_LARGE_FILE_H#include "Common.h"#define DEBUG 1
//代码组织有层次namespace xiaozhu {namespace largefile {struct MMapOption{int32_t max_mmap_size_; //最大内存int32_t first_mmap_size_; //第一次分配的内存int32_t per_mmap_size_; //每次每块分配的内存};class MMapfile {public:MMapfile();explicit MMapfile(const int fd); //必须显示构造MMapfile(const MMapOption & mmap_option, const int fd);~MMapfile();//同步文件,调用这个立即将内存同步到磁盘bool sync_file();//同步bool map_file(const bool write = false);//文件映射到内存同时设置访问权限void* get_data() const; //获取映射到内存的首地址int32_t get_size()const; //映射内容bool munmap_file(); //解除映射bool remap_file(); //重新映射private:bool ensure_file_size(const int32_t size); // 扩容private:int32_t size_;int fd_;void* data_;struct MMapOption mmap_file_option_;};}}#endif
mmap_file.cpp
#include "mmap_file.h"
#include <sys/mman.h>
#include <memory>
#include <errno.h>
#include <string.h>#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>namespace xiaozhu {namespace largefile {MMapfile::MMapfile():size_(0),data_(nullptr),fd_(0){}MMapfile::MMapfile(const int fd) : fd_(fd),data_(nullptr),size_(0) {}MMapfile::MMapfile(const struct MMapOption& mmap_option, const int fd):fd_(fd),data_(nullptr),size_(0) {mmap_file_option_.first_mmap_size_ = mmap_option.first_mmap_size_;mmap_file_option_.max_mmap_size_ = mmap_option.max_mmap_size_;mmap_file_option_.per_mmap_size_ = mmap_option.per_mmap_size_;}MMapfile::~MMapfile() {if (data_) {if (DEBUG) printf("mmap file desruct,fd: %d,mmap_size:%d,data:%p\n", fd_, size_, data_);//同步msync(data_, size_, MS_SYNC); //属性三设置为同步munmap(data_, size_);size_ = 0;data_ = nullptr;fd_ = -1;memset(&mmap_file_option_,'0',sizeof(mmap_file_option_));}}bool MMapfile::sync_file() {if (!data_ && size_ > 0) return msync(data_, size_, MS_ASYNC) == 0; // 使用异步//没有同步直接返回return true;}bool MMapfile::map_file(const bool write) {//执行映射int flags = PROT_READ;if (write) {flags |= PROT_WRITE;}if (fd_ < 0) {return false;}if (0 == mmap_file_option_.max_mmap_size_) {return false;}if (size_ < mmap_file_option_.max_mmap_size_) {size_ = mmap_file_option_.first_mmap_size_;}else {size_ = mmap_file_option_.max_mmap_size_;}if (!ensure_file_size(size_)) {fprintf(stderr, "ensure file size failed in mmap_file,size :%d\n", size_);return false;}data_ = mmap(0, size_, flags, MAP_SHARED, fd_, 0);if (data_ == MAP_FAILED) {fprintf(stderr, "mmap file failed :%s\n",strerror(errno));size_ = 0;fd_ = -1;data_ = nullptr;return false;}if (DEBUG) printf("mmap file successful,fd :%d mmaped size:%d data_:%p\n", fd_, size_, data_);return true;}void* MMapfile::get_data()const {return data_;}int32_t MMapfile::get_size() const{return size_;}bool MMapfile::munmap_file() {if (munmap(data_, size_) == 0) {return true;}else {return false;}}//文件扩容bool MMapfile::ensure_file_size(const int32_t size) {//扩容struct stat s;if (fstat(fd_, &s) < 0) {fprintf(stderr, "fstat error,error desc :%s\n", strerror(errno));return false;}if (s.st_size < size) { //小于 指定的大小if (ftruncate(fd_, size) < 0) { fprintf(stderr, "fruncate error, size:%d,error desc:%s\n",size_,strerror(errno));return false;}}return true;}bool MMapfile::remap_file() {//重新映射//什么时候要重新映射 当改变这个文件装载的大小的时候肯定要重新映射一次 //增加的内存还是 if (fd_ == 0 || !data_) {fprintf(stderr, "mmremap not mapped yet\n");return false;}if (size_ == mmap_file_option_.max_mmap_size_) {fprintf(stderr, "hava been remap max_size :%d\n",size_);return false;}int32_t new_size = mmap_file_option_.per_mmap_size_ + size_;if (new_size > mmap_file_option_.max_mmap_size_) {fprintf(stderr,"new size is so length\n");return false;}if (!ensure_file_size(new_size)) {fprintf(stderr, "mremap failed becase ensure_file_size\n");return false;}if (DEBUG) printf("mremap start fd:%d ,now size_ :%d,new_size:%d data:%p\n", fd_, size_, new_size, data_);//重新映射void* m_remap = mremap(data_, size_, new_size, MREMAP_MAYMOVE);if(m_remap == MAP_FAILED) {fprintf(stderr, "mremap failed\n", strerror(errno));return false;}if (DEBUG) printf("mremap success fd:%d ,now size_ :%d,new_size:%d data:%p\n", fd_, size_, new_size, data_);// mmap_file_option_.per_mmap_size_ = size_;data_ = m_remap;size_ = new_size;return true;} } }
文件操作类
file_op.h
#ifndef FILE_OP_H
#define FILE_OP_H
#include "Common.h"namespace xiaozhu {namespace largefile {class FileOperation {public:FileOperation(const std::string &file_Name,const int open_flags = O_RDWR |O_LARGEFILE);~FileOperation();int open_file();void close_file();int flush_file();//文件立即写入到磁盘 1行代码引起的血案//带精细化的读写int pread_file(char* buf, const int32_t nbytes,int64_t offset);int pwrite_file(char* buf, const int32_t nbytes, int64_t offset);int write_file(char* buf, const int32_t nbytes);//int read_file(char* buf, const int32_t nbytes);int64_t get_file_size();int unlink_file();//删除文件int ftruncate_file(const int64_t length);int seek_file(const int64_t offset);int get_fd() { return fd_; }protected:int fd_;char* filename_;int open_flags_;protected:static const mode_t OPEN_MODE = 0644;static const int MAX_DISK_TIMES = 5;//磁盘最大读取次数protected:int check_file();};}}#endif
#include "file_op.h"namespace xiaozhu {namespace largefile {FileOperation::FileOperation(const std::string& file_Name, const int open_flags):fd_(-1), open_flags_(open_flags){filename_ = strdup(file_Name.c_str());//字符串复制}FileOperation::~FileOperation(){if (fd_ > 0) {::close(fd_);}if (!filename_) free(filename_); filename_ = nullptr;}int FileOperation::open_file() {if (fd_ > 0) {close(fd_);fd_ = -1;}fd_ = ::open(filename_, open_flags_, OPEN_MODE);return fd_;}void FileOperation::close_file() {if (fd_ < 0) {return;}close(fd_);fd_ = -1;}int FileOperation::check_file(){if (fd_ < 0) {fd_ = open_file();}return fd_;}int64_t FileOperation::get_file_size() {int fd = check_file();struct stat statbuf;if (!fstat(fd,&statbuf) != 0) {return -1;}return statbuf.st_size();}int FileOperation::ftruncate_file(const int64_t length) {int fd = check_file();if (fd < 0) {return fd;}return ftruncate(fd, length);}int FileOperation::seek_file(const int64_t offset) {int fd = check_file();if (fd < 0) {return fd;}return lseek(fd, offset,SEEK_SET);}int FileOperation::flush_file() {if (open_flags_ & O_SYNC) {//如果是同步操作的话直接返回就不用主动映射了 return 0;}int fd = check_file();if (fd < 0) {return fd;}return fsync(fd); //缓冲区写入磁盘}//读数据 int FileOperation::pread_file(char* buf, const int32_t nbytes, int64_t offset){//从 offset 开始读写nbytes个字节 if (nbytes < 0) return 0;//int total_read = 0;int need_read = nbytes;int cur_offset = offset;char* tmp_buf = buf;int i = 0;while (need_read > 0) {if (i >= MAX_DISK_TIMES) {break;}if (check_file() < 0) {return -errno;}int readlen = pread64(fd_, tmp_buf, need_read, cur_offset);if (readlen < 0) {readlen = errno;if (-readlen == EINTR || -readlen == EAGAIN) {continue;}else if (EBADF == -readlen) {fd_ = -1;continue;}else {continue;}}else if (readlen == 0) {break;}else {need_read -= readlen; //还需要读这么多//total_read += readlen; //总共读了这么多tmp_buf += readlen;cur_offset += readlen; //当前读写的情况} //还有什么情况呢 ?}if (need_read != 0 ) {return xiaozhu::largefile::EXIT_DISK_OPER_INCOMPLETE;}return xiaozhu::largefile::TFS_SUCCESS;}int FileOperation::pwrite_file(char *buf,const int32_t nbytes,int64_t offset) {//从 offset 开始读写nbytes个字节 if (nbytes < 0) return 0;//int total_read = 0;int need_write = nbytes; //需要读这么多个字节 friends ok is well none of usint cur_offset = offset;char* tmp_buf = buf;int i = 0;while (need_write > 0) {if (i >= MAX_DISK_TIMES) {break;}if (check_file() < 0) {return -errno;}int writelen = ::pwrite64(fd_, tmp_buf, need_write, cur_offset);if (writelen < 0) {writelen = errno;if (-writelen == EINTR || -writelen == EAGAIN) {continue;}else if (EBADF == -writelen) {fd_ = -1;continue;}else {continue;}}else if (writelen == 0) {break;}else {need_write -= writelen; //还需要读这么多tmp_buf += writelen; //总共读了这么多cur_offset += writelen; //当前读写的情况}//还有什么情况呢 ?}if (need_write != 0) {return xiaozhu::largefile::EXIT_DISK_OPER_INCOMPLETE;}return xiaozhu::largefile::TFS_SUCCESS;}//写文件int FileOperation::write_file(char* buf, const int32_t nbytes){return 0; //不指定偏移来写int needwrite = nbytes;char* tmp_buf = buf;int i = 0;while (needwrite > 0) {if (i >= MAX_DISK_TIMES) {break;}++i;if (check_file() < 0) {return -errno;}int write_len = ::write(fd_, tmp_buf, needwrite);if (write_len < 0) {write_len = -errno;if (-write_len == EINTR || -write_len == EAGAIN) {continue;}else if (EBADF == -write_len) {fd_ = -1;return write_len;}else {continue;}//快速实现 }needwrite -= write_len;tmp_buf += write_len; //bug 指针的移动}if (needwrite != 0) {return xiaozhu::largefile::EXIT_DISK_OPER_INCOMPLETE;}return xiaozhu::largefile::TFS_SUCCESS;}int FileOperation::unlink_file() {close_file();return unlink(filename_);}}
}单元测试
main_mmap_op_file.cpp
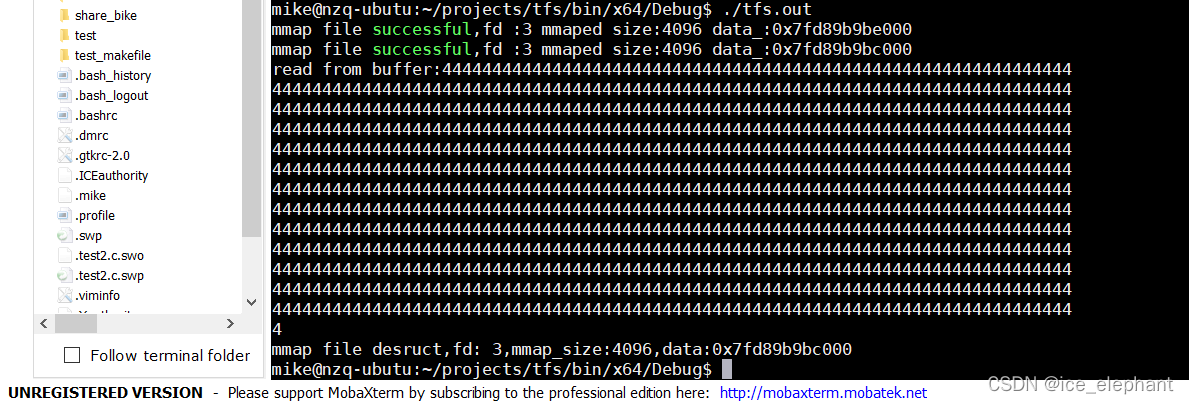
#include "mmap_file_op.h"using namespace xiaozhu;
using namespace largefile;largefile::MMapOption map_option = { 1024 * 1000,4096,4096 };int main(void) {const char* file_Name = "./test.txt";char write_buffer[1024 + 1];char read_buffer[1024 + 1];MMapFileOperation* mpt = new MMapFileOperation(file_Name);int ret = mpt->mmap_file(map_option);int fd = mpt->open_file();if (fd < 0) {fprintf(stderr, "file is not open !\n");exit(-1);}write_buffer[1024] = '\0';if (ret == largefile::TFS_EEROR) {fprintf(stderr, "largefile::TFS_ERROR mmap_file failed\n");exit(-1);}memset(write_buffer, '4', 1024);//写进去ret = mpt->pwrite_file(write_buffer, 1024, 0);if (ret == largefile::TFS_EEROR) {fprintf(stderr, "largefile::TFS_EEROR pwrite_file failed\n");exit(-1);}ret = mpt->pread_file(read_buffer, 1024, 0);if (ret == largefile::TFS_EEROR) {fprintf(stderr, "largefile::failed pread_file failed\n");exit(-1);}read_buffer[1024] = '\0';printf("read from buffer:%s\n", read_buffer);ret = mpt->flush_file();if (ret == largefile::TFS_EEROR) {fprintf(stderr, "largefile::TFS_ERROR flush_file failed\n");exit(-1);}ret = mpt->mumap_file();mpt->close_file();return 0;
}
测试结果:
第四次单元测试
##main_index_init_test.cpp
#include "indexHandle.h"
#include "Common.h"
#include "file_op.h"#include <string>
#include <sstream>
#include <iostream>static int debug = 1;using namespace std;using namespace xiaozhu;const static largefile::MMapOption map_option = { 1024 * 1000,4096,4096 };//内存映射参数
const static int32_t bucket_size = 1000;
const static int32_t main_blocksize = 1024 * 1024 * 64;
static int32_t block_id = 1;int main(int argc, char** argv) {std::string mainbock_path;std::string index_path;std::cout << "Please input block id:%d\n";cin >> block_id;if (block_id < 0) {cerr << "Invalid blockid. exit" << endl;exit(-1);}std::stringstream tmp_stream;tmp_stream << "." << largefile::MAINBLOCK_DIR_PREFIX << block_id;tmp_stream >> mainbock_path;largefile::FileOperation* mainblock = new largefile::FileOperation(mainbock_path, O_CREAT | O_RDWR | O_LARGEFILE);int ret = mainblock->ftruncate_file(main_blocksize);if (ret != 0) {fprintf(stderr, "create main_block failed. reason :%s\n", mainbock_path.c_str());exit(-2);}//创建索引文件;largefile::IndexHandle* index_handle = new largefile::IndexHandle(".", block_id);if (debug) printf("init index ...\n");//if(index_handle->)ret = index_handle->create(block_id, bucket_size, map_option);if (ret != largefile::TFS_SUCCESS) {fprintf(stderr, "create index %d failed\n", block_id);exit(-3);}//mainblock->flush_file();//index_handle->delete mainblock;delete index_handle;return 0;
}
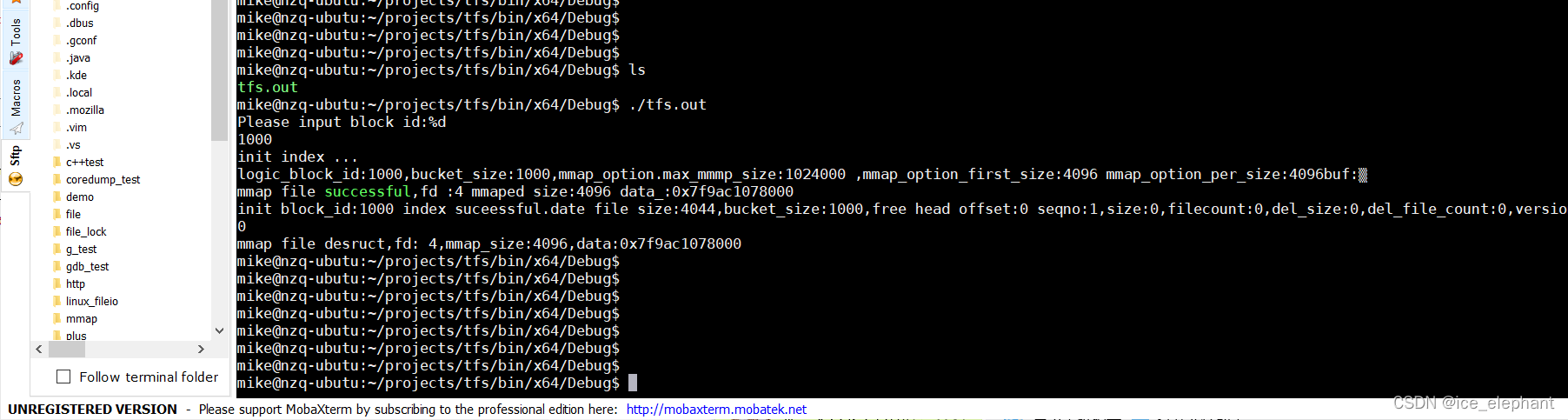
添加 删除、写模块后的头文件 :index_handle.h
在这里插入代码片
index_handle.cpp
写入块,int IndexHandle::write_segment_meta(const uint64_t key, Meltainfo& meta)
#ifndef HANDLE_INDEX_H
#define HANDLE_INDEX_H#include "Common.h"
#include "mmap_file_op.h"namespace xiaozhu {namespace largefile {struct IndexHeader {public:IndexHeader(){memset(this, 0, sizeof(IndexHeader));}BlockInfo block_info_;int32_t bucket_size_;int32_t data_offset_;//指向主块的 也代表数据大小int32_t index_file_size_; //以空间换时间 index_header + all int32_t free_head_offset_;};class IndexHandle {public :IndexHandle(const std::string& base_path, const uint32_t main_block_id);~IndexHandle();int create(const uint32_t logic_block_id,const int32_t bucket_size,const MMapOption map_option);//哈希桶的大小int load(const uint32_t logic_block_id, const int32_t bucket_size, const MMapOption map_option);//remove unlinkint remove(const uint32_t logic_block_id);int flush();void commit_block_offset_data(const int file_size) const{reinterpret_cast<IndexHeader*>(file_op_->get_map_data())->data_offset_ += file_size;}int updata_block_info(const OperType oper_type,const uint32_t modify_size);IndexHeader* index_header() {return reinterpret_cast< IndexHeader* >(file_op_->get_map_data());}BlockInfo* block_info() {return reinterpret_cast<BlockInfo*>(file_op_->get_map_data());}int32_t bucket_sizes()const{return reinterpret_cast<IndexHeader*>(file_op_->get_map_data())->bucket_size_; //等于bucket_size();}int32_t get_block_data_offset()const{return reinterpret_cast<IndexHeader*>(file_op_->get_map_data())->data_offset_;}int32_t free_head_offset() {return reinterpret_cast<IndexHeader*>(file_op_->get_map_data())->free_head_offset_;}int32_t* bucket_slot() {return reinterpret_cast<int32_t*>(reinterpret_cast<char*> (file_op_->get_map_data())+ sizeof(IndexHeader));}int write_segment_meta(const uint64_t key,Meltainfo &meta);int read_sengment_meta(const uint64_t key, Meltainfo& meta);int32_t delete_segment_meta(const uint64_t key);int hash_find(const uint64_t key, int32_t& current_offset, int32_t& previous_offset);int32_t hash_insert(const uint64_t key,int32_t previous,Meltainfo &meta);private:MMapFileOperation* file_op_;bool is_load_;bool hash_compare(int64_t left,int64_t right);};}
}#endif单元测试
blockwritetest.cpp
#include "indexHandle.h"
#include "Common.h"
#include "file_op.h"#include <string>
#include <sstream>
#include <iostream>static int debug = 1;using namespace std;using namespace xiaozhu;const static largefile::MMapOption map_option = { 1024 * 1000,4096,4096 };//内存映射参数
const static int32_t bucket_size = 1000;
const static int32_t main_blocksize = 1024 * 1024 * 64;
static int32_t block_id = 1;int mains(int argc, char** argv) {std::string mainbock_path;std::string index_path;std::cout << "Please input block id:%d\n";cin >> block_id;if (block_id < 0) {cerr << "Invalid blockid. exit" << endl;exit(-1);}int ret;//创建索引文件;//if(index_handle->)largefile::IndexHandle* index_handle = new largefile::IndexHandle(".", block_id);//if (debug) printf("create index...\n");//ret = index_handle->create(block_id, bucket_size, map_option);//if (ret != largefile::TFS_SUCCESS) {// fprintf(stderr, "create index %d failed\n", block_id);// exit(-3);//}if (debug) printf("load index ...\n");//if(index_handle->)ret = index_handle->load(block_id, bucket_size, map_option);if (ret != largefile::TFS_SUCCESS) {fprintf(stderr, "load index %d failed\n", block_id);exit(-2);}//把文件写入主块文件std::stringstream tmp_stream;tmp_stream << "." << largefile::MAINBLOCK_DIR_PREFIX << block_id;tmp_stream >> mainbock_path;//cout << "mainblock_path:" << mainbock_path << endl;largefile::FileOperation* mainblock = new largefile::FileOperation(mainbock_path, O_CREAT | O_RDWR | O_LARGEFILE);mainblock->ftruncate_file(main_blocksize);char buffer[4096];memset(buffer, '3', sizeof(buffer));buffer[4095] = '\0';int32_t data_offset = index_handle->get_block_data_offset();uint32_t file_no = index_handle->block_info()->seq_no_;ret = mainblock->pwrite_file(buffer, sizeof(buffer), data_offset);if (ret != largefile::TFS_SUCCESS) {fprintf(stderr, "wrtite to main blcok faield. reason:%s\n", strerror(errno));delete mainblock;delete index_handle;return ret;}//写入 metainfolargefile::Meltainfo meta;meta.set_filed(file_no);meta.set_offset(data_offset);meta.set_size(sizeof(buffer));//meta.set_key(block_id);ret = index_handle->write_segment_meta(meta.get_key(), meta);//index_handle->index_header()->data_offset_;if (ret == largefile::TFS_SUCCESS) {index_handle->commit_block_offset_data(sizeof(buffer));//跟新索引信息index_handle->updata_block_info(largefile::C_OPER_INSERT, sizeof(buffer));ret = index_handle->flush();if (ret != largefile::TFS_SUCCESS) {fprintf(stderr, "flush mainblock %d.file no :%u", block_id, file_no);}}else {fprintf(stderr, "write_segment_meta mainblock %d.file no :%u", block_id, file_no);}if (ret != largefile::TFS_SUCCESS){//写失败了fprintf(stderr, "write to mainblock:%d fail.file no:%\n", block_id, file_no);}else {printf("write successfully.file no:%u block id:%d\n", file_no, block_id);}//index_handle->flush();mainblock->close_file();delete mainblock;delete index_handle;return 0;
}
添加后的 indexhandle.cpp
#include "indexHandle.h"#include <sstream>namespace xiaozhu {namespace largefile {IndexHandle::IndexHandle(const std::string& base_path, const uint32_t main_block_id) {//创建 file_op_std::stringstream tmp_stream;tmp_stream << base_path << INDEX_DIR_PREFIX << main_block_id;std::string index_path;tmp_stream >> index_path;file_op_ = new MMapFileOperation(index_path, O_CREAT | O_RDWR | O_LARGEFILE);is_load_ = false;}IndexHandle::~IndexHandle(){if (file_op_) {delete file_op_;file_op_ = nullptr;}}int IndexHandle::create(const uint32_t logic_block_id, const int32_t bucket_size, const MMapOption map_option){int ret;if (DEBUG) {printf("logic_block_id:%u,bucket_size:%d,mmap_option.max_mmmp_size:%d ,mmap_option_first_size:%d mmap_option_per_size:%d", logic_block_id, bucket_size, map_option.max_mmap_size_, map_option.per_mmap_size_, map_option.per_mmap_size_);}if (is_load_) {return xiaozhu::largefile::EXIT_INDEX_ALREADY_LOAD;}//printf("43\n");int64_t file_size = file_op_->get_file_size();//printf("46\n");if (file_size < 0) {return TFS_EEROR;}else if (file_size == 0) {//索引头部IndexHeader i_header;i_header.block_info_.block_id_ = logic_block_id;i_header.block_info_.seq_no_ = 1;i_header.bucket_size_ = bucket_size; //桶子的个数i_header.index_file_size_ = sizeof(IndexHeader) + bucket_size * sizeof(int32_t);char* init_data = new char[i_header.index_file_size_];memcpy(init_data, &i_header, sizeof(IndexHeader));memset(init_data + sizeof(IndexHeader), 0, i_header.index_file_size_ - sizeof(IndexHeader));ret = file_op_->pwrite_file(init_data, i_header.index_file_size_, 0);delete [] init_data;init_data = nullptr;if (ret != largefile::TFS_SUCCESS) {return ret;}ret = file_op_->flush_file();if (ret != largefile::TFS_SUCCESS) {return ret;}}else {return largefile::EXIT_META_UNEXPECT_FOUND_ERROR;}ret = file_op_->mmap_file(map_option);printf("87\n");printf("bucket_size():%u,index_headr bucket_size():%u\n",bucket_sizes(),index_header()->bucket_size_);printf("91\n");if (ret != largefile::TFS_SUCCESS) {return ret;}is_load_ = true;if (DEBUG) {printf("init block_id:%d index suceessful.date file size:%d,bucket_size:%d,free head offset:%d seqno:%d,size:%d,filecount:%d,del_size:%d,del_file_count:%d,version:%d\n",logic_block_id, index_header()->index_file_size_,index_header()->bucket_size_, index_header()->free_head_offset_, block_info()->seq_no_, block_info()->size_,block_info()->file_count_, block_info()->del_size_, block_info()->del_file_count_, block_info()->version_);}return ret;}int IndexHandle::load(const uint32_t logic_block_id, const int32_t bucket_size, const MMapOption map_option){int ret = largefile::TFS_SUCCESS;if (is_load_) {printf("EXIT_INDEX_ALREADY_LOAD \n");return EXIT_INDEX_ALREADY_LOAD;}int64_t file_size = file_op_->get_file_size();if (file_size < 0){return file_size;}else if (file_size == 0) {printf("file_size equal zero\n");return EXIT_INDEX_CORRUPT_EEROR;}MMapOption tmp_option = map_option;// if this conditional how to solve it ?if (tmp_option.first_mmap_size_ < file_op_->get_file_size() && file_op_->get_file_size() <= map_option.max_mmap_size_){tmp_option.first_mmap_size_ = file_size;}ret = file_op_->mmap_file(tmp_option);if (ret != TFS_SUCCESS) {return ret;}//printf("bucket_size():%u,index_headr bucket_size():%u\n", bucket_sizes(), index_header()->bucket_size_);if (0 == block_info()->block_id_ || 0 == (bucket_sizes())) {fprintf(stderr, "index corrupt. blockid:%u,bucket_size:%d\n", block_info()->block_id_, index_header()->bucket_size_);return EXIT_INDEX_CORRUPT_EEROR;}int index_file_size = sizeof(IndexHeader) + bucket_sizes() * sizeof(int32_t);if (file_size < index_file_size) {fprintf(stderr, "index size is smaller than file_size_\n");return EXIT_INDEX_CORRUPT_EEROR;}if (logic_block_id != block_info()->block_id_) {// if (logic_block_id != block_info()->block_id_) {fprintf(stderr, "block id confilit logic_block_id:%u block_info()->block_id_:%d\n", logic_block_id, block_info()->block_id_);// }}if (bucket_sizes() != bucket_size) {fprintf(stderr, "bucket_size is not equel bucket_sizes()\n", bucket_sizes(), bucket_size);}is_load_ = true;if (DEBUG) {printf("init block_id:%d index suceessful.date file size:%d,bucket_size:%d,free head offset:%d seqno:%d,size:%d,filecount:%d,del_size:%d,del_file_count:%d,version:%d\n",logic_block_id, index_header()->index_file_size_,index_header()->bucket_size_, index_header()->free_head_offset_, block_info()->seq_no_, block_info()->size_,block_info()->file_count_, block_info()->del_size_, block_info()->del_file_count_, block_info()->version_);}return TFS_SUCCESS;}int IndexHandle::remove(const uint32_t logic_block_id){if (logic_block_id != block_info()->block_id_) {fprintf(stderr, "logic_block_id:%u is not equel file savaed block_id_:%u",logic_block_id, block_info()->block_id_);}//int ret = file_op_->mumap_file();if (ret != TFS_SUCCESS) {return ret;}ret = file_op_->unlink_file();return ret;}int IndexHandle::flush(){int ret = file_op_->flush_file();if (ret != largefile::TFS_SUCCESS) {fprintf(stderr, "index flush fail,ret :%d ,error desc:%s\n", ret, strerror(errno));}return ret;}int IndexHandle::updata_block_info(const OperType oper_type, const uint32_t modify_size){if (block_info()->block_id_ == 0) {return EXIT_BLOCK_ID_ZERO_ERROR;}else if (oper_type == OperType::C_OPER_INSERT) {++block_info()->file_count_;++block_info()->version_;++block_info()->seq_no_;block_info()->size_ += modify_size;}else if (oper_type == OperType::C_OPER_DELET) {--block_info()->file_count_;++block_info()->version_;block_info()->seq_no_;block_info()->size_ -= modify_size;++block_info()->del_file_count_;block_info()->del_size_ += modify_size;}if (DEBUG) {printf("update blockinfo()\n");printf("init block_id:%d index suceessful.data_offset_:%d,bucket_size:%d,free head offset:%d seqno:%d,size:%d,filecount:%d,del_size:%d,del_file_count:%d,version:%d oper_type:%d\n",block_info()->block_id_, index_header()->data_offset_, index_header()->bucket_size_, index_header()->free_head_offset_, block_info()->seq_no_, block_info()->size_,block_info()->file_count_, block_info()->del_size_, block_info()->del_file_count_, block_info()->version_, oper_type);}return TFS_SUCCESS;}//怎么写 how to write friends ok yes me knowint IndexHandle::write_segment_meta(const uint64_t key, Meltainfo& meta){int32_t current_offset = 0, previous_offset = 0;int ret = hash_find(key, current_offset, previous_offset);//key 存在就不插入了if (ret == TFS_SUCCESS) {fprintf(stderr, "TFS_SUCCESS\n");return EXIT_META_UNEXPECT_FOUND_ERROR;}else if (ret != EXIT_META_INFO_IS_NOT_EXIT) {fprintf(stderr, "EXIT_META_INFO_IS_NOT_EXIT\n");return ret;}ret = hash_insert(key, previous_offset, meta);return ret;}int IndexHandle::read_sengment_meta(const uint64_t key, Meltainfo& meta){int32_t current_offset, previous_offset;int ret = hash_find(key, current_offset, previous_offset);if (ret!= TFS_SUCCESS) { fprintf(stderr,"key is not exit\n");return largefile::EXIT_META_INFO_IS_NOT_EXIT;}else {file_op_->pread_file(reinterpret_cast<char*>(&meta), sizeof(meta), current_offset);return ret;}}int32_t IndexHandle::delete_segment_meta(const uint64_t key){int32_t current_offset, previous_offset = 0;int ret = hash_find(key, current_offset, previous_offset);if (ret != TFS_SUCCESS) {return ret;}Meltainfo meta_info;ret = file_op_->pread_file(reinterpret_cast<char*>(&meta_info), sizeof(meta_info), current_offset);if (ret != TFS_SUCCESS) {return ret;}int next_pos = meta_info.get_next_meta_info(); //拿到当前位置的下一个节点if (previous_offset == 0) {int32_t slot = static_cast<int32_t>(key) % bucket_sizes();bucket_slot()[slot] = next_pos; //直接进行一波覆盖}else {Meltainfo pre_meta_info;ret = file_op_->pread_file(reinterpret_cast<char*>(&pre_meta_info), sizeof(pre_meta_info),previous_offset);if (TFS_SUCCESS != ret) {return ret;}pre_meta_info.set_next_meta_offset(next_pos);ret = file_op_->pwrite_file(reinterpret_cast<char*>(&pre_meta_info), sizeof(Meltainfo), previous_offset);if (TFS_SUCCESS != ret) {return ret;}}meta_info.set_next_meta_offset(free_head_offset());ret = file_op_->pwrite_file(reinterpret_cast<char*>(&meta_info), sizeof(Meltainfo),current_offset);index_header()->free_head_offset_ = current_offset;updata_block_info(C_OPER_DELET, meta_info.get_size());if (DEBUG) printf("delete_segment_meta-reuse metalnfo,current_offset:%d\n", current_offset);return TFS_SUCCESS;}int IndexHandle::hash_find(const uint64_t key, int32_t& current_offset, int32_t& previous_offset){current_offset = 0;previous_offset = 0;Meltainfo meta;int ret = TFS_SUCCESS;//查找int32_t slot = key % bucket_sizes();int32_t pos = (int32_t)bucket_slot()[slot]; //得到//根据偏移量读取存储的 metainfofor (; pos != 0;) {ret = file_op_->pread_file(reinterpret_cast<char*>(&meta), sizeof(Meltainfo), pos);if (ret != TFS_SUCCESS) {return ret;}if (hash_compare(meta.get_key(), key)) {current_offset = pos;return TFS_SUCCESS;}previous_offset = pos;pos = meta.get_next_meta_info();}return EXIT_META_INFO_IS_NOT_EXIT;}int32_t IndexHandle::hash_insert(const uint64_t key, int32_t previous_offset, Meltainfo& meta){int32_t slot = static_cast<uint32_t> (key) % bucket_sizes();//const 类型强转//printf("slot:%d\n", slot);int ret;int current_offset;Meltainfo tmp_meta;//确定 metainfo 存储在文件中的偏移量if (free_head_offset() != 0) {ret = file_op_->pread_file(reinterpret_cast<char*>(&tmp_meta), sizeof(Meltainfo), free_head_offset());if (ret != TFS_SUCCESS) {printf("free_head_offset failed\n");return ret;}current_offset = index_header()->free_head_offset_;if (DEBUG) printf("reuse metainfo,current_offset:%d \n", current_offset);index_header()->free_head_offset_ = tmp_meta.get_next_meta_info(); }else {current_offset = index_header()->index_file_size_;index_header()->index_file_size_ += sizeof(Meltainfo);}printf("------------------------hash_insert index_header()->index_file_size_:%d--------------------\n", index_header()->index_file_size_);//第三步将 matainfo 写入索引文件meta.set_next_meta_offset(0);ret = file_op_->pwrite_file(reinterpret_cast<char*> (&meta), sizeof(Meltainfo), current_offset);//拿到上一个mateif (ret != TFS_SUCCESS) {index_header()->index_file_size_ -= sizeof(Meltainfo);return ret;}//将 map 节点插入到哈希链表中if (0 != previous_offset) {ret = file_op_->pread_file(reinterpret_cast<char*>(&tmp_meta), sizeof(Meltainfo), previous_offset);if (ret != TFS_SUCCESS) {index_header()->index_file_size_ -= sizeof(Meltainfo);return ret;}meta.set_next_meta_offset(current_offset);file_op_->pwrite_file(reinterpret_cast<char*>(&tmp_meta), sizeof(meta), previous_offset);if (ret != TFS_SUCCESS) {index_header()->index_file_size_ -= sizeof(Meltainfo);return ret;}}else {printf(" index_headr()->index_file_size:%d\n", index_header()->index_file_size_);printf(",bucket_slot():%d slot:%d\n",bucket_slot()[slot],slot);bucket_slot()[slot] = current_offset;}return TFS_SUCCESS;}bool IndexHandle::hash_compare(int64_t left, int64_t right){return left == right ? true : false;}}
}
测试读、可重复利用节点的删除 mainblockwrite.cpp
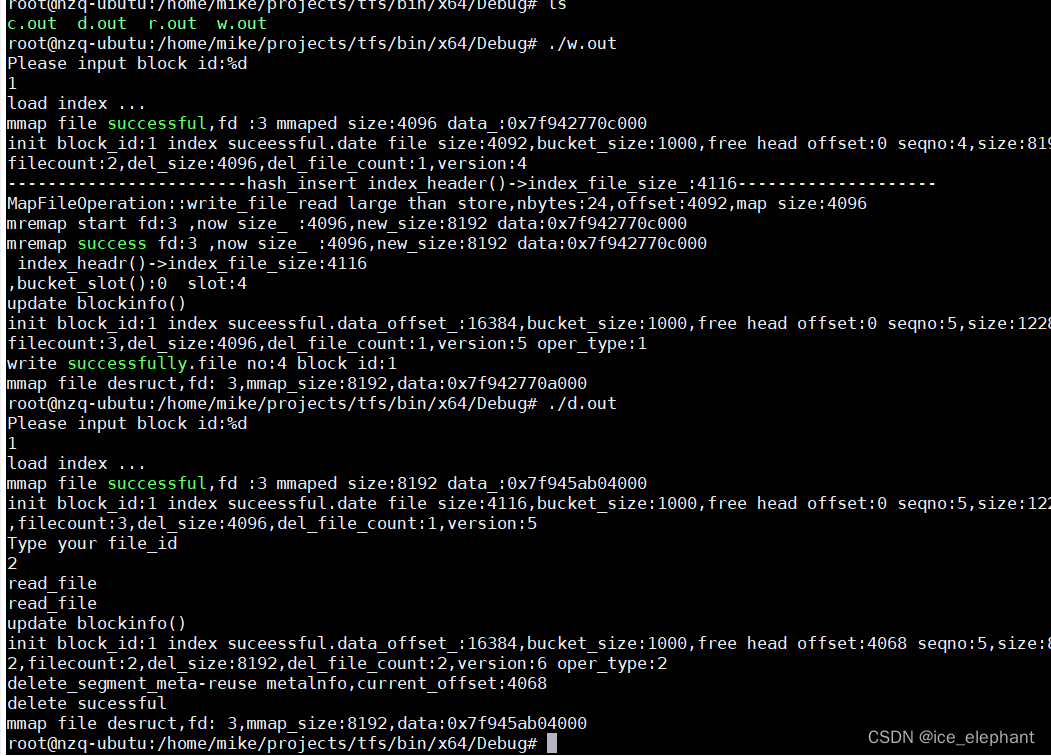
总结
这个淘宝分布式文件系统核心存储引擎项目,从宏观层面理解:就是通过文件来管理文件。这么直接说有点抽象,刚开始我有疑问,为什么要用文件管理文件?操作系统直接来帮我们管理了不好吗?为什么还要自己写一个程序?这是我做这个项目之初的疑问。后来我了解到,因为淘宝的数据量非常的大,如果这些数据都存在磁盘中,cpu 直接访问磁盘的速度是非常慢的,大概是 cpu 访问内存的速度的万分之1 ,然后这么多数据并不能都放在内存中,因为内存的 大小是十分有限的价格昂贵.而造成访问磁盘速度这么慢的原因是,系统在访问文件的时候需要移动这个 “磁头” 这个涉及到一些底层的物理知识,磁头的移动是十分耗时的,但是磁头得帮我们定位到文件,迫不得寻找消耗时间,阿里的大牛们,设计的这个淘宝分布式文件系统,就是不让系统来帮我们找磁盘,我们自己写一个 index 文件专门帮我们来管理文件岂不美哉 ? 这样就可以避免系统帮我们找文件磁盘移动. 这个思想的本质是,以空间来换时间,用价格相对不太昂贵的硬盘的储存空间,来换取文件的访问效率。 淘宝的这种大文件的分布式文件系统在业界堪称是最牛的设计,它的设计十分精巧.