Clion 使用 armadillo 配置方法
jetbrains 全家桶是我的最爱 但是C++的编写网上都是visual studio 的教程,尤其是对于库文件的引用,Clion很少有指导,最近需要将python的程序转为C++,用到了armadillo 矩阵库, 但是网上对于armadillo的使用再Clion中都是胡说八道。下面我来介绍一下正确的做法
第一步 下载 Clion
来这里的应该都下好了,不多赘述
第二步 下载 armadillo
百度搜索 armadillo 选择稳定版下载(这种东西,不是越新越好)
第三步 解压文件 在Clion中创建项目
- 注意我这里创建了一个文件夹 include 放包含的文件

下面是cmake list 编写
cmake_minimum_required(VERSION 3.17)
project({xxx})set(CMAKE_CXX_STANDARD 14)
include_directories(include/armadillo/include) # 引用头文件
link_directories(include/armadillo/examples/lib_win64) #添加依赖
add_executable({xxx} main.cpp)
target_link_libraries({xxx} libopenblas.lib) #添加库文件
第四步 最重要的一步

在lib_win64的文件夹中把 libopenblas.dill 复制到 \cmake-build-debug 的目录下
第五步 运行示例文件
#include <iostream>
#include <armadillo>using namespace std;
using namespace arma;// Armadillo documentation is available at:
// http://arma.sourceforge.net/docs.html// NOTE: the C++11 "auto" keyword is not recommended for use with Armadillo objects and functionsint
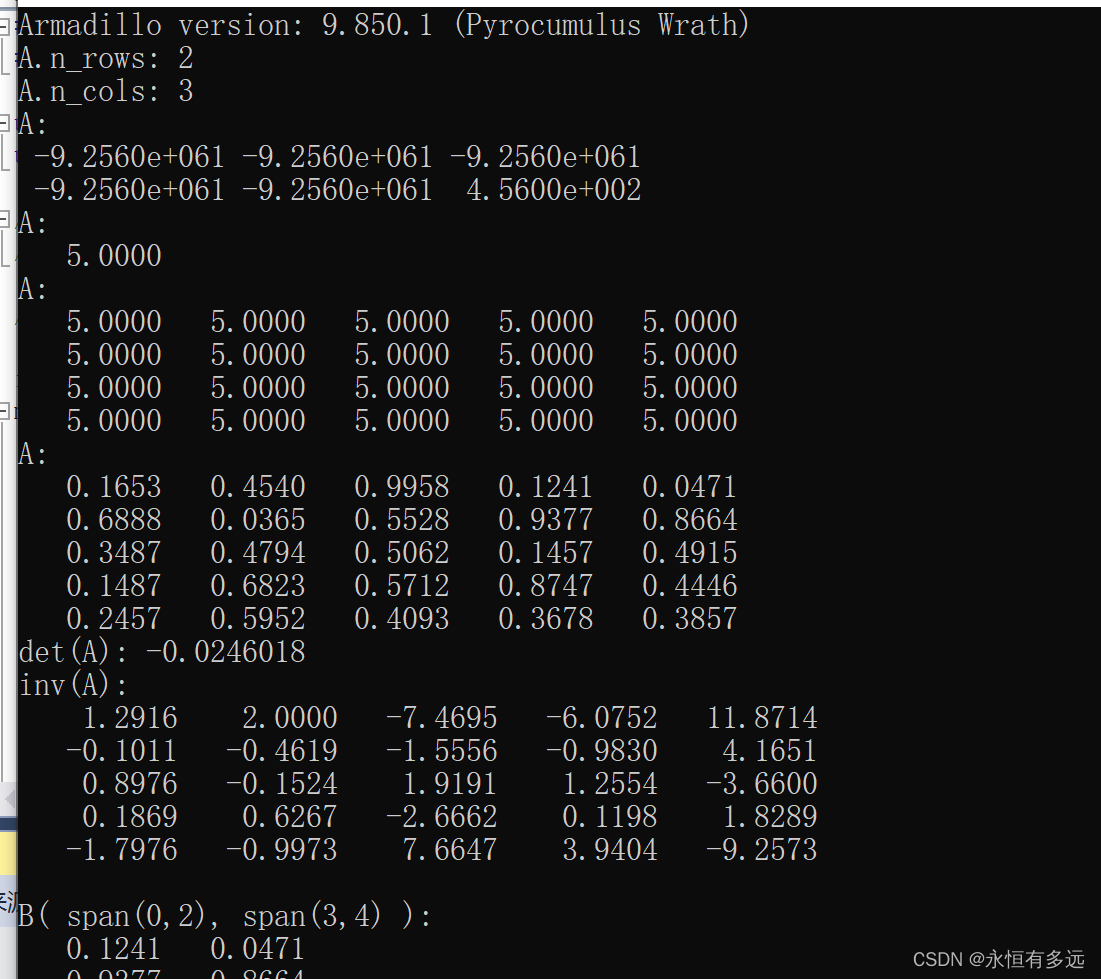
main(int argc, char** argv){cout << "Armadillo version: " << arma_version::as_string() << endl;mat A(2,3); // directly specify the matrix size (elements are uninitialised)cout << "A.n_rows: " << A.n_rows << endl; // .n_rows and .n_cols are read onlycout << "A.n_cols: " << A.n_cols << endl;A(1,2) = 456.0; // directly access an element (indexing starts at 0)A.print("A:");A = 5.0; // scalars are treated as a 1x1 matrixA.print("A:");A.set_size(4,5); // change the size (data is not preserved)A.fill(5.0); // set all elements to a particular valueA.print("A:");A = { { 0.165300, 0.454037, 0.995795, 0.124098, 0.047084 },{ 0.688782, 0.036549, 0.552848, 0.937664, 0.866401 },{ 0.348740, 0.479388, 0.506228, 0.145673, 0.491547 },{ 0.148678, 0.682258, 0.571154, 0.874724, 0.444632 },{ 0.245726, 0.595218, 0.409327, 0.367827, 0.385736 } };A.print("A:");// determinantcout << "det(A): " << det(A) << endl;// inversecout << "inv(A): " << endl << inv(A) << endl;// save matrix as a text fileA.save("A.txt", raw_ascii);// load from filemat B;B.load("A.txt");// submatricescout << "B( span(0,2), span(3,4) ):" << endl << B( span(0,2), span(3,4) ) << endl;cout << "B( 0,3, size(3,2) ):" << endl << B( 0,3, size(3,2) ) << endl;cout << "B.row(0): " << endl << B.row(0) << endl;cout << "B.col(1): " << endl << B.col(1) << endl;// transposecout << "B.t(): " << endl << B.t() << endl;// maximum from each column (traverse along rows)cout << "max(B): " << endl << max(B) << endl;// maximum from each row (traverse along columns)cout << "max(B,1): " << endl << max(B,1) << endl;// maximum value in Bcout << "max(max(B)) = " << max(max(B)) << endl;// sum of each column (traverse along rows)cout << "sum(B): " << endl << sum(B) << endl;// sum of each row (traverse along columns)cout << "sum(B,1) =" << endl << sum(B,1) << endl;// sum of all elementscout << "accu(B): " << accu(B) << endl;// trace = sum along diagonalcout << "trace(B): " << trace(B) << endl;// generate the identity matrixmat C = eye<mat>(4,4);// random matrix with values uniformly distributed in the [0,1] intervalmat D = randu<mat>(4,4);D.print("D:");// row vectors are treated like a matrix with one rowrowvec r = { 0.59119, 0.77321, 0.60275, 0.35887, 0.51683 };r.print("r:");// column vectors are treated like a matrix with one columnvec q = { 0.14333, 0.59478, 0.14481, 0.58558, 0.60809 };q.print("q:");// convert matrix to vector; data in matrices is stored column-by-columnvec v = vectorise(A);v.print("v:");// dot or inner productcout << "as_scalar(r*q): " << as_scalar(r*q) << endl;// outer productcout << "q*r: " << endl << q*r << endl;// multiply-and-accumulate operation (no temporary matrices are created)cout << "accu(A % B) = " << accu(A % B) << endl;// example of a compound operationB += 2.0 * A.t();B.print("B:");// imat specifies an integer matriximat AA = { { 1, 2, 3 },{ 4, 5, 6 },{ 7, 8, 9 } };imat BB = { { 3, 2, 1 }, { 6, 5, 4 },{ 9, 8, 7 } };// comparison of matrices (element-wise); output of a relational operator is a umatumat ZZ = (AA >= BB);ZZ.print("ZZ:");// cubes ("3D matrices")cube Q( B.n_rows, B.n_cols, 2 );Q.slice(0) = B;Q.slice(1) = 2.0 * B;Q.print("Q:");// 2D field of matrices; 3D fields are also supportedfield<mat> F(4,3); for(uword col=0; col < F.n_cols; ++col)for(uword row=0; row < F.n_rows; ++row){F(row,col) = randu<mat>(2,3); // each element in field<mat> is a matrix}F.print("F:");return 0;}