专栏简介 :MySql数据库从入门到进阶.
题目来源:leetcode,牛客,剑指offer.
创作目标:记录学习MySql学习历程
希望在提升自己的同时,帮助他人,,与大家一起共同进步,互相成长.
学历代表过去,能力代表现在,学习能力代表未来!
1.什么是索引?
当我们想要在书中查找某个知识点时 , 通常不会一页一页的去遍历 , 而是在目录中锁定具体位置.这样可以节省大量的时间 , 书中的目录就是充当索引的角色 , 方面我们快速查找书中内容 , 典型的空间换时间的设计思想.
那么转换到数据库中 , 索引就是帮助存储引擎快速获取数据的一种数据结构 , 形象的说:"索引就是数据的目录".

2.索引的分类
提到索引大家可能会想到 , 聚簇索引 , 主键索引 , 二级索引 , 普通索引 , 唯一索引 , hash索引 , B+树索引等等. 要想清楚这些索引的使用和实现方式 , 那么需要根据索引之间的相同特点进行分类.
我们可以按照四个角度来分类索引:
- 1.按数据结构分: B+树索引 , Hash索引 , Full-text索引.
- 2.按物理存储分: 聚簇索引(主键索引) , 二级索引(辅助索引).
- 3.按字段特性分: 主键索引 , 唯一索引 , 普通索引 , 前缀索引.
- 4.按字段个数分: 单列索引 , 联合索引.
本文主要谈谈按数据结构来分类索引:
MySql中常见按数据结构来分类的索引有 , B+树索引 , Hash索引 , Full-Test索引 , 数据库中每一种存储引擎支持的索引类型不一定相同 , 常见如下图所示:
| 索引类型 | InnDB 引擎 | MyISAM 引擎 | Memory 引擎 |
| B+树 索引 | ✅ | ✅ | ✅ |
| Hash 索引 | ❌ | ❌ | ✅ |
| Full-Text 索引 | ✅ | ✅ | ❌ |
InnoDB是自MySql 5.5 之后默认存储引擎 , B+树索引也是MySql存储引擎中使用最多的索引类型.
创建表时 , InnoDB存储引擎会根据不同的场景选择不同的列作为索引:
- 如果有主键 , 会默认使用主键作为聚簇索引(主键索引)的索引键.
- 如果没有主键 , 就选择第一个不包含NULL值的唯一列作为聚簇索引的索引键.
- 在以上两者皆无的情况下 , InnoDB将会自动生成一个隐式自增 id 列 , 作为聚簇索引的 索引键.
Tips: 其他索引都属于辅助索引(二级索引). 创建的主键索引和二级索引默认使用的是B+树索引.
3.索引的使用场景
索引的最大好处是提高查询速度 , 但索引也是有缺点的 , 例如:
- 需要占用物理空间 , 数据量越大 , 占用的空间就越多.
- 创建索引和维护索引需要消耗时间 , 这种时间随着数据量的增大而增大.
- 会降低表的增删改的效率 , 因为每次增删改索引 , B+树为了维护索引的有序性 , 都需要进行动态维护.
什么时候适合使用索引?
- 字段有唯一性限制 , 例如学生的 id 号码.
- 经常用于where查询条件的字段 , 这样可以提升整个表的查询效率 , 如果查询条件不是一个字段 , 可以建立联合索引.
- 进程用于 group by 和 order by 的字段 , 这样在查询的时候就不需要再去做一次排序了 , 因为在建立索引之后B+树中的记录都是排序好的.
什么时候不需要创建索引?
- where group by order by 中用不到的字段 , 索引的价值是快速定位 , 如果起不到定位作用的字段 , 通常不需要建立索引 , 因此索引会占用额外空间.
- 字段中存在大量的重复数据 , 不需要创建索引.例如:性别字段 , 只有男女 , 如果数据表中 , 男女的记录分布均匀 , 那么无论搜索那个值都会得到一半的数据.因此MySql中有一个查询优化器 , 当某个值在数据表中出现百分比很高时 , 一般会忽略索引 , 进行全盘扫描.
- 表中数据太少时不需创建索引.
- 经常更新的字段不需要创建索引 , 例如不要对学生的成绩建立索引 , 因为索引字段频繁修改 , 需要维护B+树的有序性 , 那么就需要频繁的重建索引 , 这个过程会影响数据库的性能.
4.索引的使用
创建主键约束(primary key) , 唯一约束(unique) , 外键约束(foreign key)时 , 会自动创建对应列的索引.
- 查看索引
show index from 表名;mysql> show index from student;
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| student | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | | YES | NULL |
+---------+------------+----------+--------------+-------------+-----------+-------------+-- 创建索引
对于非主键 , 非唯一性约束 , 非外键的字段可以创建二级索引.
create index 索引名 on 表名(字段名);mysql> create index name_index on student(name);mysql> show index from student;
+---------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+---------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| student | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | | YES | NULL |
| student | 1 | name_index | 1 | name | A | 0 | NULL | NULL | YES | BTREE | | | YES | NULL |
+---------+------------+------------+--------------+-------------+-----------+-------------Tips:创建索引最好在建表之初 , 如果一个表中已存在很多的数据 , 此时创建索引会占用大量的磁盘盘IO , 花很长的时间 , 在这段时间里数据库无法正常被使用.
- 删除索引
drop index 索引名 on 表名;mysql> drop index name_index on student;mysql> show index from student;
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| student | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | | YES | NULL |
+---------+------------+----------+--------------+-------------+-----------+-------------+-Tips:若数据量较大 , 删除索引也会占用大量磁盘导致数据库无法正常使用.
5.索引的数据结构
B+树 vs 哈希表:
提到数据结构 , 第一时间想到的应该是查询时间复杂度为O(1)的哈希表.但哈希表有个致命的缺陷就是无法比较数据的范围 , 只能查询是否相等 , 因此首先排除哈希表.
B+树 vs 二叉搜索树:
说到查询数据的范围 , 二叉树搜索树绝对是一大利器. 但创建索引的初心是提高查询效率 , 如果数据量过大那么二插搜索树的高度会很高 , 因此也会产生多个节点 , 增加数据库的比较次数 , 导致占用大量磁盘影响数据库的性能.
B+树 vs B树:
在二插搜索树的基础上需要进一步优化. 由此引出了B树也就是N插搜索树 , B树最大的好处就是大大降低了树的高度 , 比较次数虽然没有减少 , 但硬盘I/O的次数减少 , 提升了数据库的性能.

虽然B树相比二插搜索树更适合做索引的数据结构 , 但B+树对B树做了更近一步的改进 , 是为索引量身定制的数据结构.
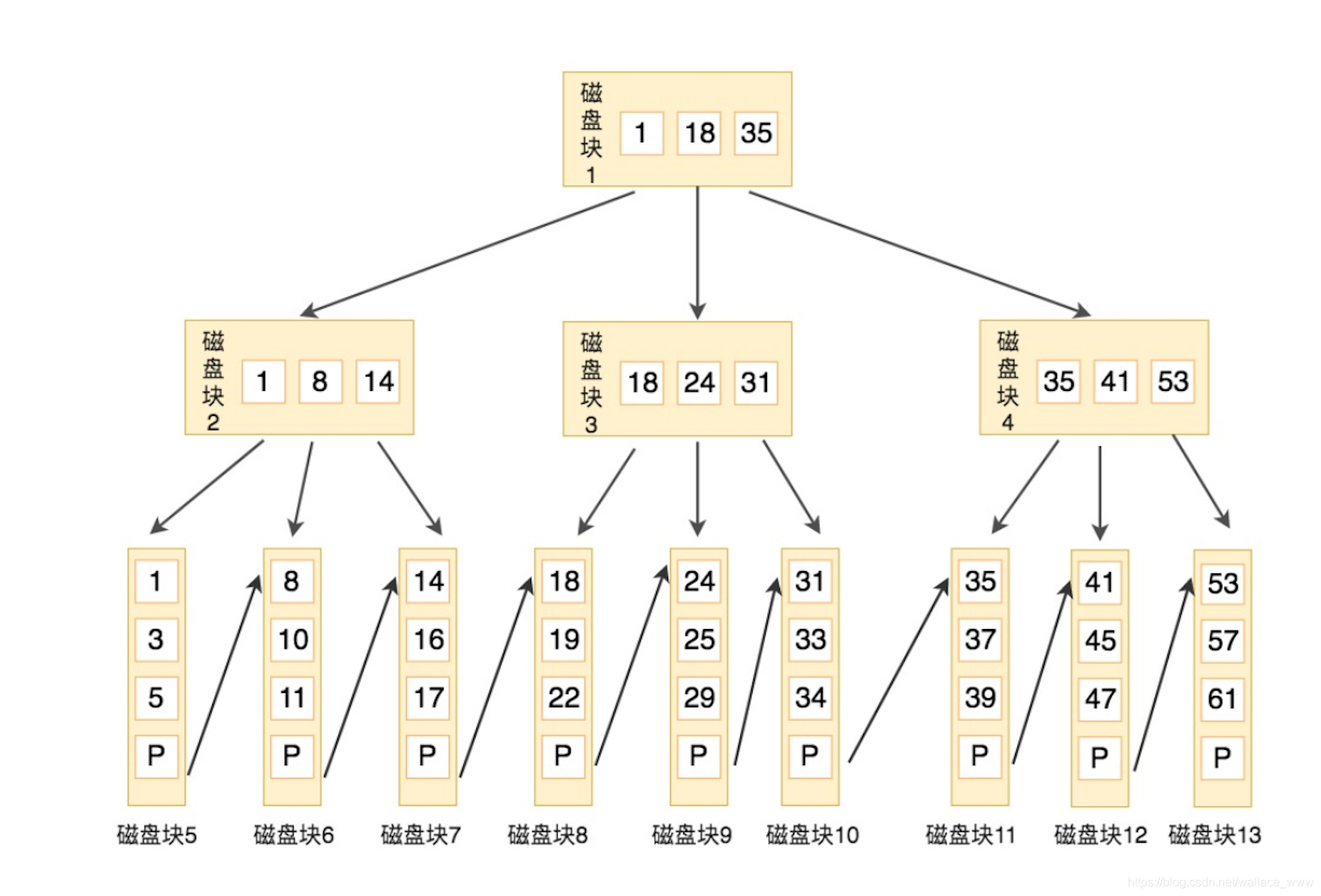
B+树的特点:
- 1.B+树是一个N叉树 , 每个节点上肯包含N个key , N个key划分出N个区间 , 最后一个key相当于最大值.
- 2.父元素的key在子元素中以最大值的形式重复出现.这样可以保证叶子节点包含了所有数据的key.
- 3.B+树会把叶子节点 , 用类似于双向链表的形式 首尾相接.适合MySQL中常见的基于范围的顺序查找.

eg:我们执行下面这条查询语句:
select * from student where id = 6;这条语句使用了主键索引查询 id 号为 6 的学生 , 查询过程中B+树会自顶向下逐层查找
- 将6和根节点的索引数据(8 16)比较 , 在8之前 , 所以根据B+树的搜索逻辑 , 找到第二层的索引数据(2 5 8).
- 在第二层的索引(2 5 8)中比较 , 6 在 5 和 8 之间 , 所以根据B+树的搜索逻辑找到第三层的索引 数据(6 8).
- 在叶子节点的索引数据(6 8)中进行查找 , 然后我们找到索引值为 6 的行数据.
数据库的索引和数据都是存放在硬盘中 , 我们可以把读取一个节点当做一个硬盘的I/O操作 , 那么上述查询过程一共经历了 3 个节点 , 也就是进行了 3 次I/O操作.
B+树存储千万级的数据只需要3-4层的高度就可以满足 , 这意味着从千万级别的表中查询目标数据最多需要3-4次磁盘I/O , 所以B+树相较于二叉搜索树 , 最大的优势在于查询效率很高 , 因为即使在数据量很大的情况下 , 查询一个数据的磁盘I/O依然维持在 3-4 次左右.
B+树的优点:
- 1.作为一个N插搜索树 , 高度降下来 , 比较时硬盘的I/O次数就会减少(同B树).
- 2.B+树更加适合范围查询.
- 3.所有的查询最终都在叶子节点上 , 无论查询哪个元素 , 中间比较的次数大致相等.
- 4.由于所以的key都会在叶子节点中体现 , 因此非叶子节点不必存表的真实记录 , 只需存索引列的值(例如存个id).这样非叶子节点占用的空间大大降低 , 更进一步的降低了硬盘的IO.

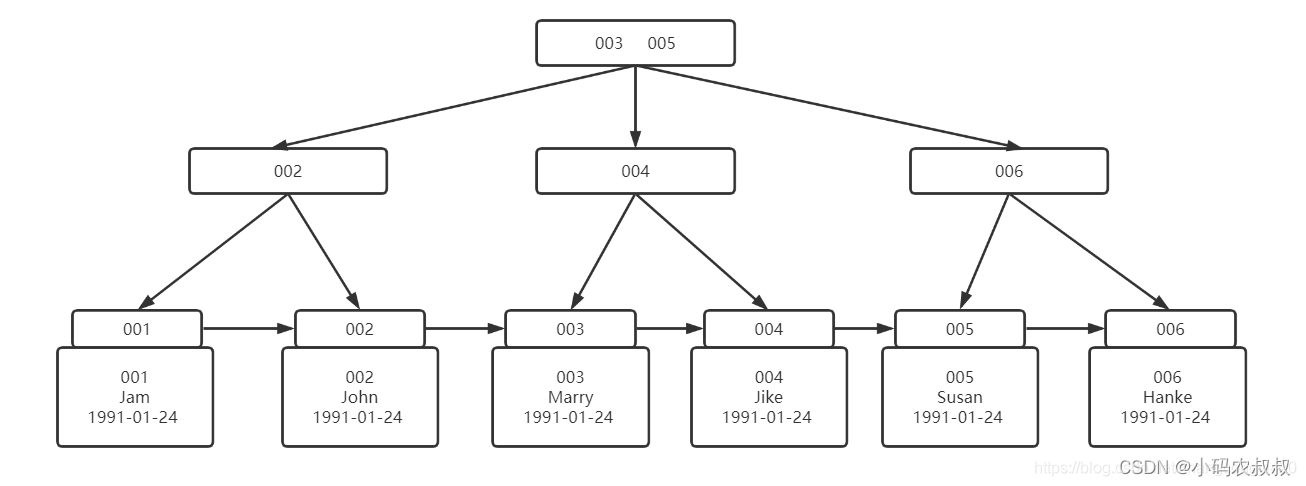
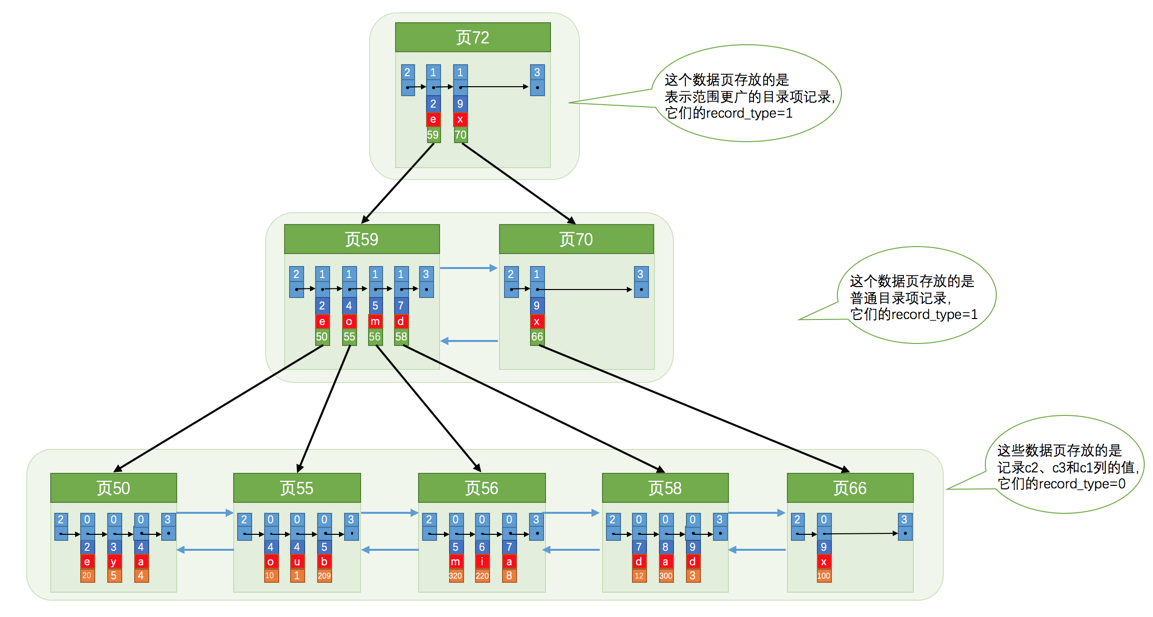
通过二级索引查询数据的过程:
主键索引和二级索引的B+树的区别如下:
- 主键索引的B+树的叶子节点中存放的是实际数据 , 所有完整的数据记录都存放在主键索引的B+树的叶子节点里.
- 二级索引的B+树叶子节点中存放的是主键值 , 而不是实际数据.
如果我们使用二级索引查询 , 会先检验二级索引中B+树的索引值 , 找到对应的叶子节点 , 获取主键值 , 然后再通过主键索引中的B+树查询到对应的叶子节点 , 然后获取整行数据.这个过程叫做回表 , 也就是需要查两次B+树才能查到数据.但如果查询的数据能在二级索引的B+树中查询到 , 这时就不用再查询主键索引了 , 这种在二级索引的B+树中就能查询到结果的过程就叫覆盖索引 , 也就是只要查询一个B+树就能查询到结果.