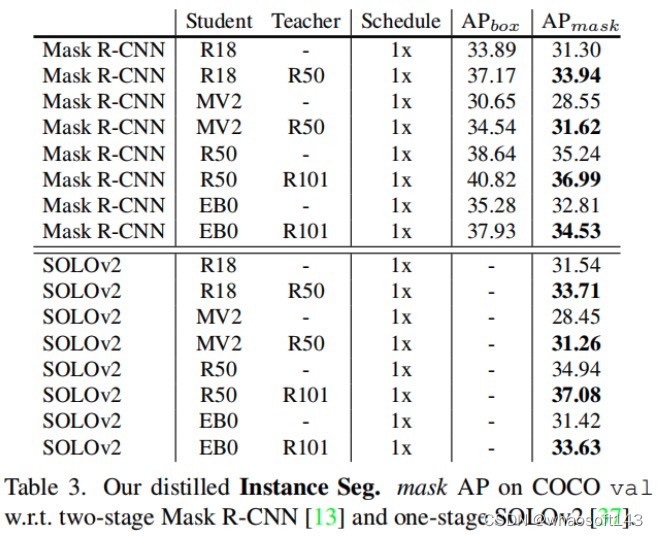
背景:
需求重点:大量小文件,读场景多,磁盘存储有限,要能支持fuse挂载,兼容s3接口
公司最近要进行分布式文件服务的选型,起因是因为公司目前有一些设备上报的文件或者日志性能管理文件需要定时上传到文件系统保存到磁盘中,大多都是一些小文件KB级别不涉及到很大的文件。之前尝试过ceph和juicefs,但是由于我们的需求是需要分布式部署而且文件是存储在磁盘上,ceph方案有些重,但是juicefs文件存储对象为磁盘时只支持单机部署,就想到用juicefs+minio的方案,后来发现一个问题,minio他的分布式场景下会自动启用纠删码模式,而且最少需要四个磁盘。并且EC:N最小情况也是EC:2,为了保证它的高可用,会有一定程度的存储浪费(ps:没想到更好的办法,如果有请评论区指教一下)。
后来查看了seaweedfs,发现它会启用master节点,分布式部署情况下,会选举一个leader而且能实现文件存储的存储调度,而且支持fuse本地挂载和S3接口,话不多说,直接实战一下看看!
官方仓库文档:Wiki - Gitee.com
开始实战
个人理解其实就是分了master和volume,大家在别的帖子稍微看一下就能明白它的一个存储逻辑,这里不再进行赘述。
准备工作:
seaweedfs安装包:Releases · seaweedfs/seaweedfs · GitHub
我对应的机器环境是linux,所以选择linux_amd64.tar进行下载
三台服务器:
xxx.xxx.xxx.1
xxx.xxx.xxx.2
xxx.xxx.xxx.3(实际情况用你自己的机器ip地址就可以)
1.下载压缩包之后分别在三台机器上创建相应的seaweedfs文件目录然后上传压缩包
解压:tar zxvf linux_amd64.tar
解压之后的文件目录:

(注意后续我们的weed命令执行都在这个文件目录下面)
2.创建master和volume文件夹:mkdir -p ./seaweedfs/data ./seaweedfs/volume

3.编写脚本master.sh启动master服务器(记得赋予执行权限chmod +x master.sh)
脚本内容如下:
nohup ./weed master -ip=xxx.xxx.xxx.1 -port=9333 -mdir=./seaweedfs/data -peers=xxx.xxx.xxx.1:9333,xxx.xxx.xxx.2:9333,xxx.xxx.xxx.3:9333 > ./seaweedfs/data/master.log &
nohup ./weed master -ip=xxx.xxx.xxx.2 -port=9333 -mdir=./seaweedfs/data -peers=xxx.xxx.xxx.1:9333,xxx.xxx.xxx.2:9333,xxx.xxx.xxx.3:9333 > ./seaweedfs/data/master.log &
nohup ./weed master -ip=xxx.xxx.xxx.3 -port=9333 -mdir=./seaweedfs/data -peers=xxx.xxx.xxx.1:9333,xxx.xxx.xxx.2:9333,xxx.xxx.xxx.3:9333 > ./seaweedfs/data/master.log &
运行脚本当前目录下输入:./master.sh
查看运行日志 cat master.log 有start Seaweed master 日志就说明master服务器启动成功
(ps: 三台机器分别都要执行上述脚本)
4.配置运行的volume,编写脚本volume.sh启动volume
脚本内容:
nohup ./weed volume -dataCenter dc1 -rack rack1 -dir ./seaweedfs/volume -ip xxx.xxx.xxx.1 -port 9222 -ip.bind xxx.xxx.xxx.1 -max 20 -mserver xxx.xxx.xxx.1:9333,xxx.xxx.xxx.2:9333,xxx.xxx.xxx.3:9333 -publicUrl xxx.xxx.xxx.1:9222 > ./seaweedfs/volume/volume.log &
nohup ./weed volume -dataCenter dc1 -rack rack1 -dir ./seaweedfs/volume -ip xxx.xxx.xxx.2 -port 9222 -ip.bind xxx.xxx.xxx.2 -max 20 -mserver xxx.xxx.xxx.1:9333,xxx.xxx.xxx.2:9333,xxx.xxx.xxx.3:9333 -publicUrl xxx.xxx.xxx.2:9222 > ./seaweedfs/volume/volume.log &
nohup ./weed volume -dataCenter dc1 -rack rack1 -dir ./seaweedfs/volume -ip xxx.xxx.xxx.3 -port 9222 -ip.bind xxx.xxx.xxx.3 -max 20 -mserver xxx.xxx.xxx.1:9333,xxx.xxx.xxx.2:9333,xxx.xxx.xxx.3:9333 -publicUrl xxx.xxx.xxx.3:9222 > ./seaweedfs/volume/volume.log &
三台机器分别运行脚本./volume.sh,查看volume.log,start成功就表示启用成功
好了到目前位置我们已经完成了master服务器和卷服务器volume的启动,访问一下ip地址+端口号9333,就可以看到服务器:
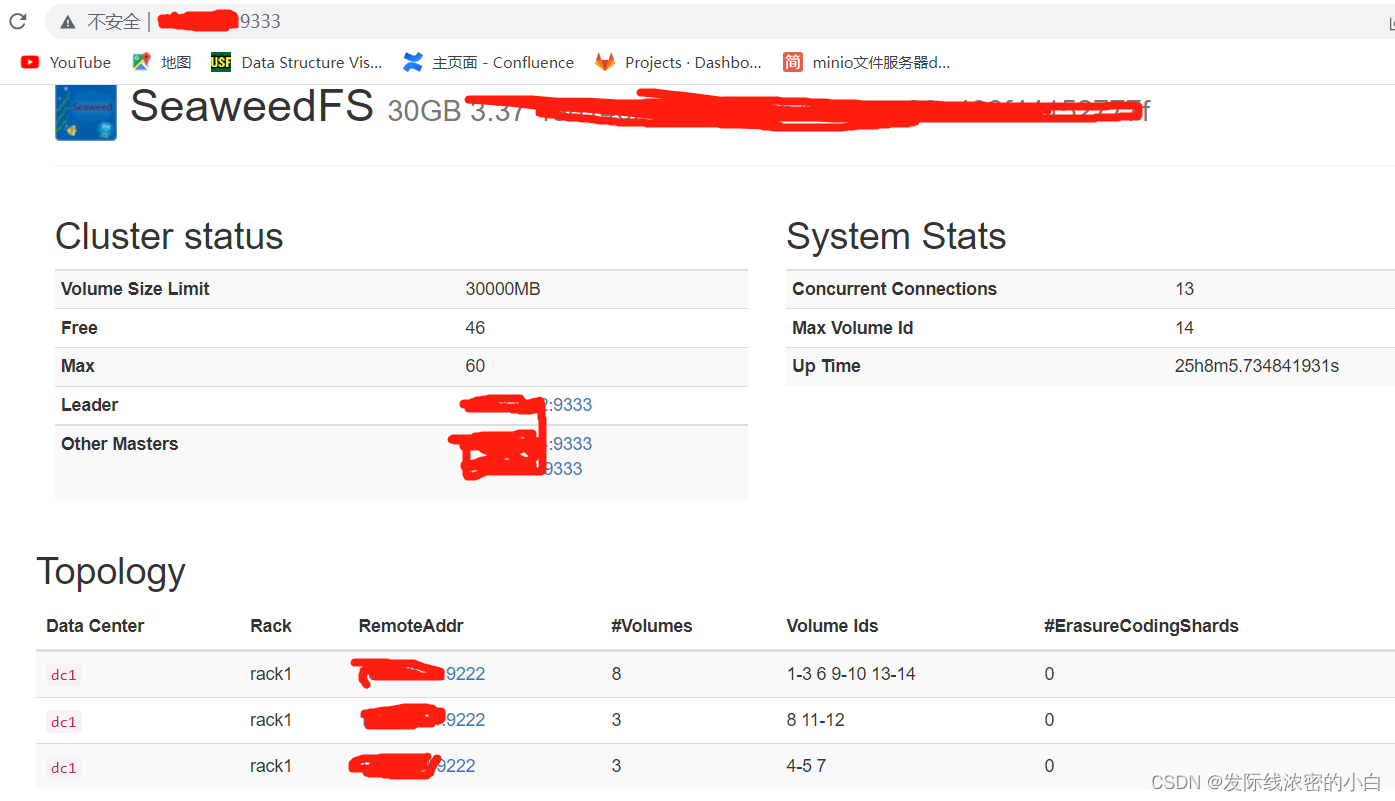
上图中就是我三台机器的ip地址以及volume的大小,刚部署完成,你们的volumes和volume Ids都是0是正常的,因为还没有上传文件,所以master不会分配fid,不要担心。而且,三台服务器,已经有它自己的选举模式,选出了其中一台作为leader
接下来我们尝试进行文件的上传下载删除:
大概原理就是你先请求master服务器,master服务器给你分配fid和url地址,你再根据分配给你的fid和url地址进行文件操作
获取文件上传fid和url地址:
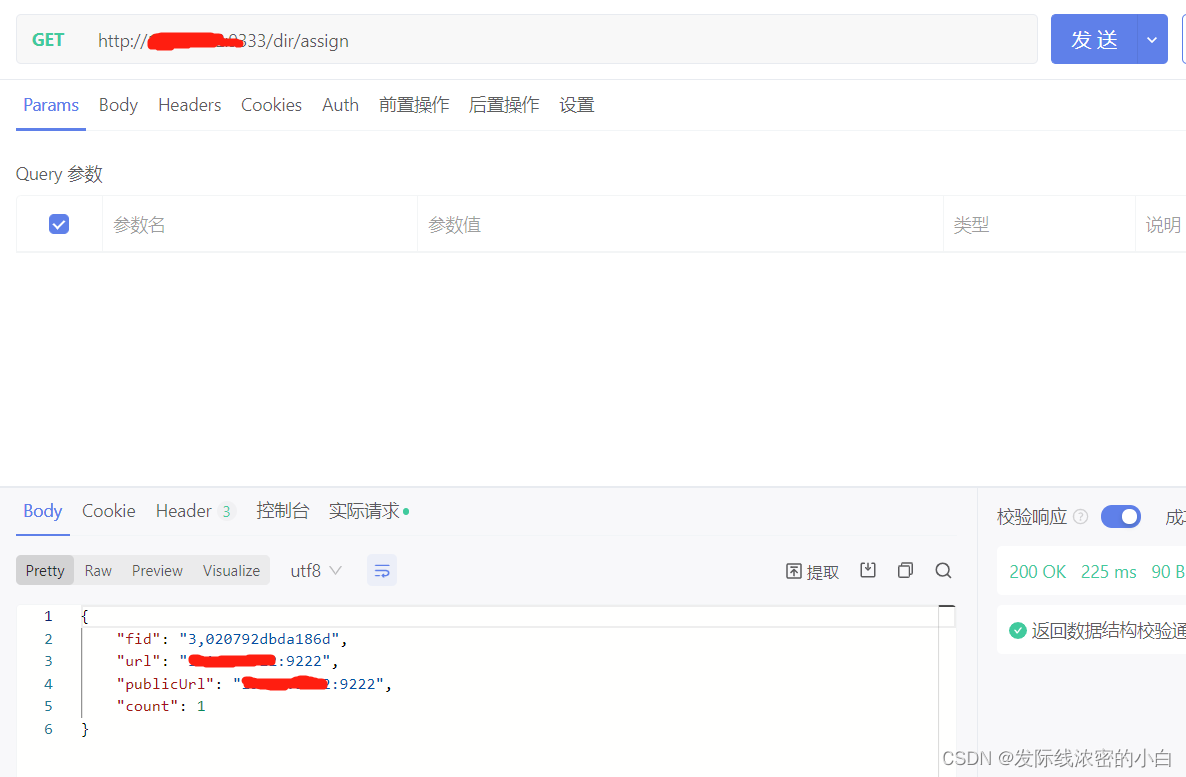
上传文件:(接口地址用上面获取到的fid和url)
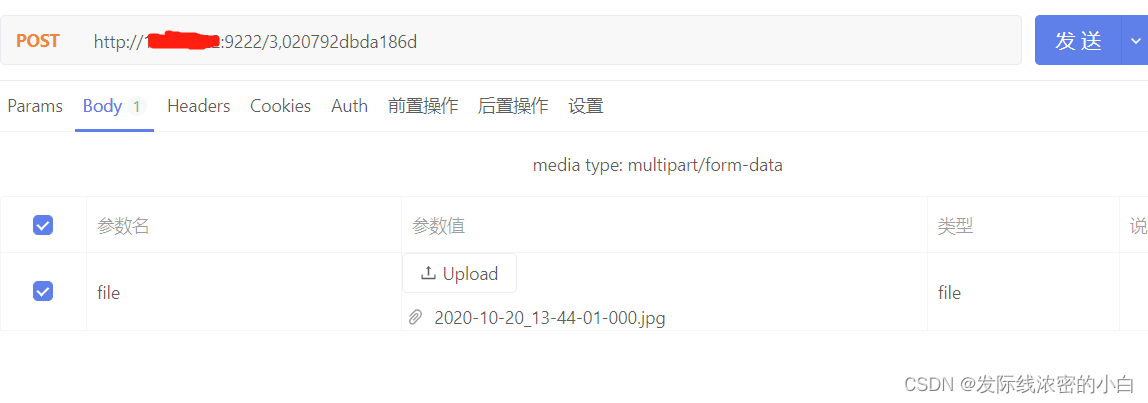
同理下载文件删除文件,上述接口地址不变,只需要把调用方式改为GET/DELETE,因为它提供的是标准的restful接口。
FUSE挂载
正如我前面需求提到的,我们可能需要将文件系统挂载到本地目录,这样的话,我们的文件上传之后就能再挂载目录中查看了,非常方便,话不多说上手操作
seaweedfs挂载需要先启动一个挂载服务器filer,还是在我们的seaweedfs目录下进行:
执行命令:
开启filter服务器
nohup ./weed -v=3 filer -port=8888 -master=xxx.xxx.xxx.1:9333 >> filer.log &
另外两台机器也执行上述命令,seaweedfs默认的文件服务器端口号是8888
然后使用mount命令进行挂载
nohup ./weed mount -filer=xxx.xxx.xxx.1:8888 -dir=/mount -filer.path=/ >> wefsmount.log &
另外两台机器也执行一样的命令
上述的-dir=/mount 这个mount就是我自己创建的本地目录,当然你自己可以随意指定
启用完成之后查看日志cat wefsmount.log
访问一下filer服务:
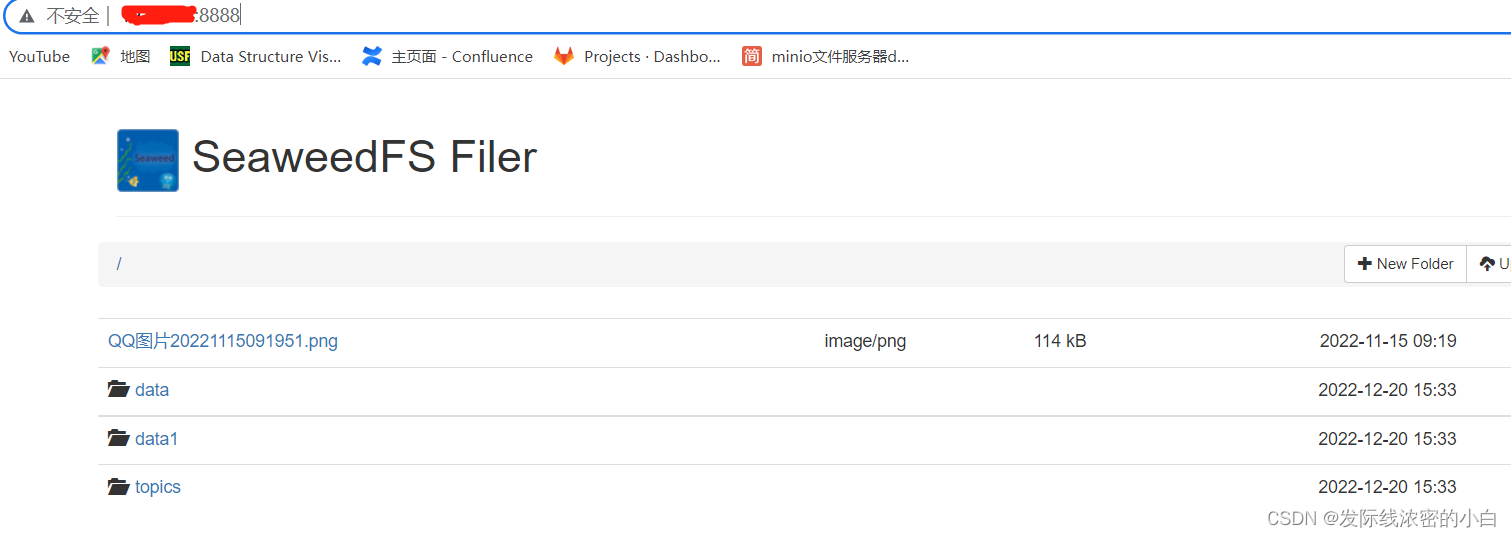
访问成功,我们可以在这上面进行文件的上传下载
S3网关
接下来就该提到S3,之前对这个概念一直很模糊,也不知道文件系统服务支持S3到底讲的是什么,后来发现,其实S3就是一套标准的接口访问协议,具体可以参考一下S3的API文档,那么seaweedfs怎么去启用S3呢?
很简单只需要一条命令:./weed s3
也可以用./weed s3 -h 去查看他的一些s3命令,默认情况下启动,端口号是8333,而且任何的key都是可以访问的。
网关启用之后我们就可以直接用S3接口进行文件操作啦!!!
值得一提的是,如果你是跟我一样的物理机,本地使用代理进行远程访问,开启S3之后,远程物理机默认的转发接口是localhost:8333就会导致你只能物理机本身访问,不支持对外开放,这个也有解决办法,在我们的启动命令上加一个ip.bind 绑定到你的物理机ip,就可以远程访问了。
//开启S3网关
./weed s3 -ip.bind=xxx.xxx.xxx.1
试一下效果:
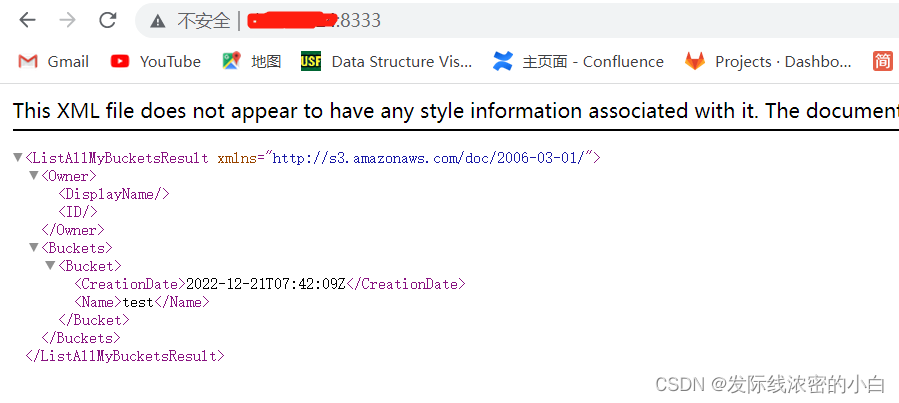
ok,大功告成,可以访问!
上述就是我初学分布式文件系统的一些经验,趟了很多坑,因为很多人实际场景去操作的时候都会遇到不同的问题,官方文档又是全英文,也是废了不少劲,收获不少。
第一次写文章,可能有些写的不清楚的地方,有什么问题,欢迎评论区交流!