码字不易,转载请附原链,搬砖繁忙回复不及时见谅,技术交流请加QQ群:909211071
目的
在一些业务逻辑场景中, 我们要针对同一批数据依次进行不同的处理,并且它们之间是有先后顺序的。比如我们制造一个手机要经历三个阶段:buy(采购配件) - build(组装) - pack(打包),最终得到可以出售的手机。在这个需求场景中,就可以通过goroutine+无缓冲channel实现。
处理逻辑
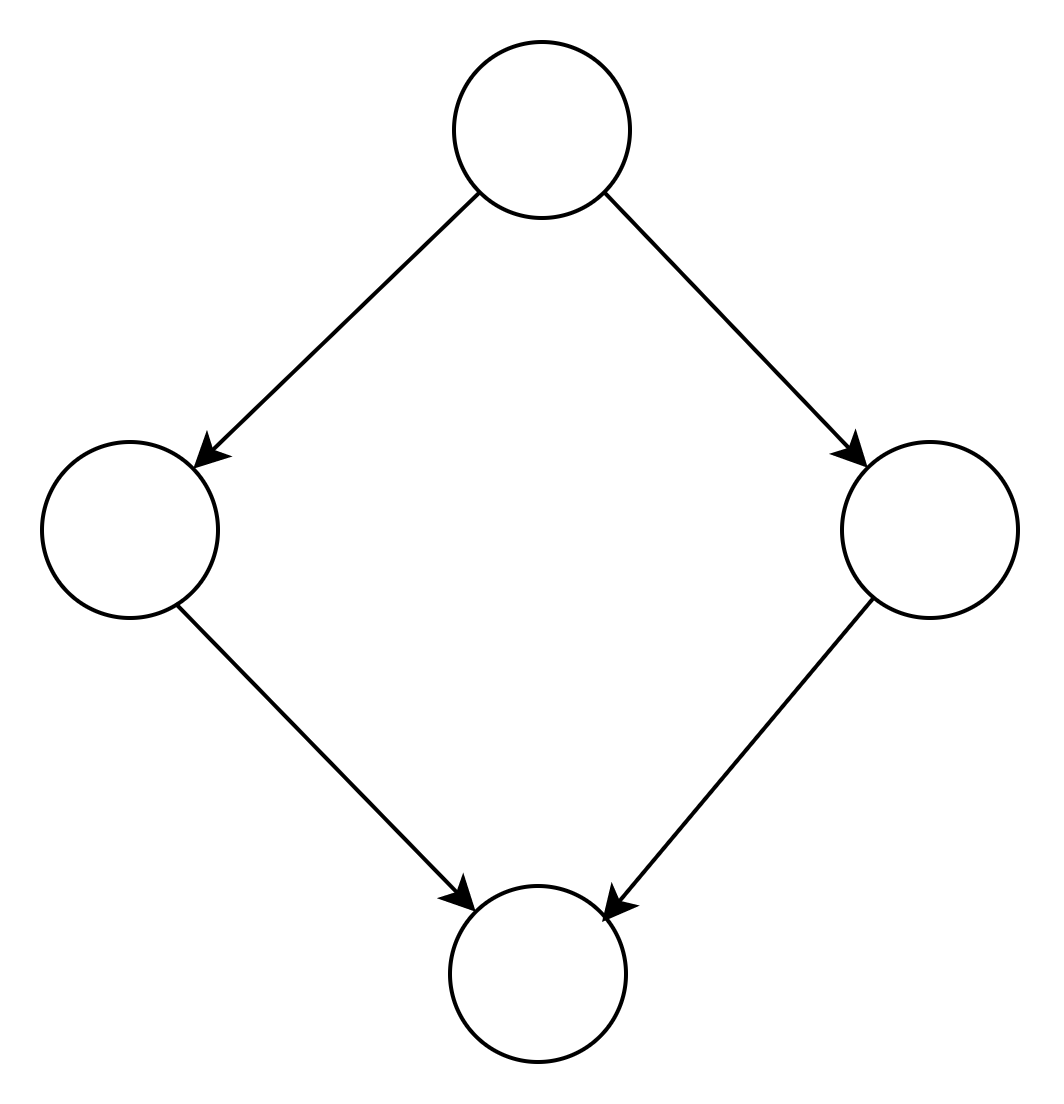
我们把整个处理路程想象成消息队列,生产者buy生产,buy的下游build进行消费并生产,pack下游进行消费。逻辑图如下:

代码实现:
package mainimport ("fmt""sync""time"
)func buy(n int) <-chan string {out := make(chan string)go func() {defer close(out)for i := 1; i <= n; i++ {fmt.Println("proc:buy", i)out <- fmt.Sprintf("配件%d", i)}}()return out
}
func build(in <-chan string) <-chan string {out := make(chan string)go func() {defer close(out)for v := range in {fmt.Println("proc:build", v)out <- fmt.Sprintf("组装(%s)", v)}}()return out
}
func pack(in <-chan string) <-chan string {out := make(chan string)go func() {defer close(out)for v := range in {fmt.Println("proc:pack", v)out <- fmt.Sprintf("打包(%s)", v)}}()return out
}func main() {coms := buy(10)phones := build(coms)packs := pack(phones)for v := range packs {fmt.Println("result:", v)}
}
打印结果:
[why@whydeMacBook-Pro] ~/Desktop/go/test$go run main.go
proc:buy 1
proc:buy 2
proc:build 配件1
proc:build 配件2
proc:buy 3
proc:pack 组装(配件1)
proc:pack 组装(配件2)
proc:build 配件3
result: 打包(组装(配件1))
result: 打包(组装(配件2))
proc:pack 组装(配件3)
result: 打包(组装(配件3))
proc:buy 4
proc:buy 5
proc:build 配件4
proc:build 配件5
proc:buy 6
proc:pack 组装(配件4)
proc:pack 组装(配件5)
proc:build 配件6
proc:buy 7
result: 打包(组装(配件4))
result: 打包(组装(配件5))
proc:pack 组装(配件6)
result: 打包(组装(配件6))
proc:build 配件7
proc:pack 组装(配件7)
result: 打包(组装(配件7))
proc:buy 8
proc:buy 9
proc:build 配件8
proc:build 配件9
proc:buy 10
proc:pack 组装(配件8)
proc:pack 组装(配件9)
proc:build 配件10
result: 打包(组装(配件8))
result: 打包(组装(配件9))
proc:pack 组装(配件10)
result: 打包(组装(配件10))可以看到不同的处理流程是并行处理的,单个处理流程是顺序处理的。
供需不平衡
当三个流程处理效率相同时,上面当实现没有什么问题,但是假设运行了一段时间只会,build 处理能力下降,就会由于中间一个环节阻塞,托满整个执行效率,此时该如何处理呢?
可能大部分人都会想到,增加 build 流水线的工人啊!没错,就是这个思路,所以演变后的逻辑变成下面这样:

我们用 sleep 模拟 build 处理能力下降,演变后的代码如下:
package mainimport ("fmt""sync""time"
)func buy(n int) <-chan string {out := make(chan string)go func() {defer close(out)for i := 1; i <= n; i++ {fmt.Println("proc:buy", i)out <- fmt.Sprintf("配件%d", i)}}()return out
}
func build(in <-chan string) <-chan string {out := make(chan string)go func() {defer close(out)for v := range in {fmt.Println("proc:build", v)time.Sleep(time.Duration(time.Second))out <- fmt.Sprintf("组装(%s)", v)}}()return out
}
func pack(in <-chan string) <-chan string {out := make(chan string)go func() {defer close(out)for v := range in {fmt.Println("proc:pack", v)out <- fmt.Sprintf("打包(%s)", v)}}()return out
}//扇入,汇聚3个channel成一个
func merge(ins ...<-chan string) <-chan string {wg := sync.WaitGroup{}wg.Add(len(ins))out := make(chan string)//定义channel数据传递函数f := func(in <-chan string) {defer wg.Done()for v := range in {out <- v}}//按照传入channel个数并行处理for _, v := range ins {go f(v)}go func() {wg.Wait()close(out)}()return out
}func main() {coms := buy(10)//phones := build(coms)//扇入增加build效率phones1 := build(coms)phones2 := build(coms)phones3 := build(coms)phones := merge(phones1, phones2, phones3)packs := pack(phones)for v := range packs {fmt.Println("result:", v)}
}
打印结果:
[why@whydeMacBook-Pro] ~/Desktop/go/test$go run main.go
proc:buy 1
proc:build 配件1
proc:buy 2
proc:buy 3
proc:buy 4
proc:build 配件3
proc:build 配件2
proc:build 配件4
proc:pack 组装(配件3)
proc:buy 5
proc:buy 6
proc:pack 组装(配件2)
proc:build 配件5
proc:build 配件6
result: 打包(组装(配件3))
result: 打包(组装(配件2))
proc:pack 组装(配件1)
result: 打包(组装(配件1))
proc:buy 7
proc:build 配件7
proc:pack 组装(配件6)
proc:buy 8
result: 打包(组装(配件6))
proc:build 配件8
proc:buy 9
proc:buy 10
proc:build 配件9
proc:pack 组装(配件5)
proc:pack 组装(配件4)
result: 打包(组装(配件5))
result: 打包(组装(配件4))
proc:build 配件10
proc:pack 组装(配件9)
proc:pack 组装(配件8)
result: 打包(组装(配件9))
result: 打包(组装(配件8))
proc:pack 组装(配件7)
result: 打包(组装(配件7))
proc:pack 组装(配件10)
result: 打包(组装(配件10))
[why@whydeMacBook-Pro] ~/Desktop/go/test$通过结果我们可以看到,buy 和 pack 的处理仍是顺序的,而 build 变成了并行处理,解决了我们供需不平衡的问题。
ps:为了减少代码量,提高阅读体验,这里没有贴前后对比图,你可以自己运行对比一下二者的效率,可以很直观地感受到。