文章目录
- 引入
- Innodb B+树
- 联合索引存储以及寻址
- 总结
引入
最近找工作, 去一家三方支付公司面试,前面得过程还挺好,所有的提都回答对了(心里暗自窃喜应该能拿到高工资offer,迎娶白富美,然后走向人生巅峰),面试官说问最后一个问题:“联合索引在B+树如何存储以及如何寻址?”,然后一脸懵逼【我只记得索引前缀匹配原则~~】。然后,,就没有然后了。。直接让回家。
回来看资料博客,以及和同事讨论。稍微有点眉目。
Innodb B+树
先看一下B+树。这里直接拿张洋大神的图 链接:http://blog.codinglabs.org/articles/theory-of-mysql-index.html。
聚簇索引:
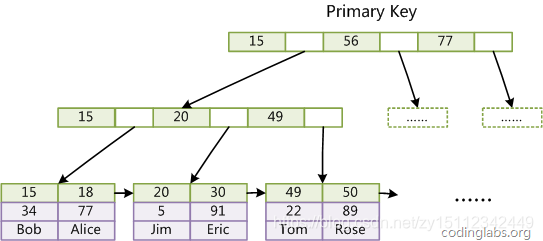
辅助非聚簇索引:

结构:当一个表T(id,name,age,sex,high)建一个普通索引 KEY(name),name的索引结果就和上面辅助非聚簇索引结构一样。
查询:当有一个select id,name,age from T where name = “” 辅助索引会根据name在B+树上进行二叉树查找,找出叶子节点数据后发现没有age这个数据,就会进行回表操作到主键聚簇索引去查找,拿到聚簇索引叶子节点的age数据。
联合索引存储以及寻址
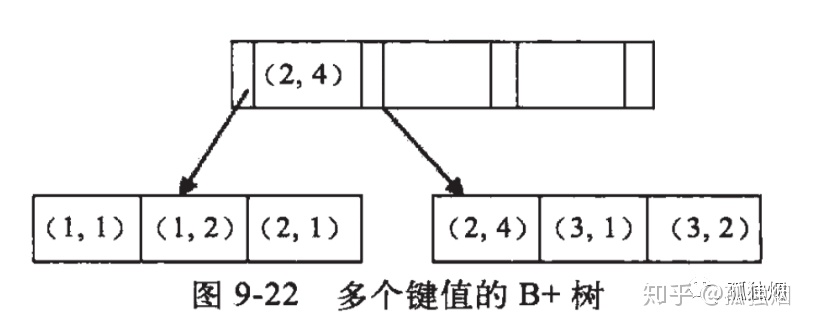
索引结构:因为上述回表操作也会消耗性能,所以系统可以根据业务情况加上一个组合索引(并不是一定得加,毕竟索引也是个珍贵的资源),例如给上述加上一个组合索引 KEY(name,age,sex)【 KEY(col1,col2,col3)】。那么这个组合索引的B+树非叶子节点数据结构和上述辅助非聚簇索引图一样,但是叶子节点是这样的:

叶子节点存储col1,col2,col3这三列数据以及加上ID这一列数据。
寻址过程:
例如语句:select * from T where name = “张三” and age=25,先根据name字段从辅助聚簇索引定位到哪一个叶子节点数据中,然后根据age节点在上述表格的前6行中,寻找age= 25的数据,然后找出所有符合的数据以及其对应的ID,然后根据ID来进行回表操作查询。这里返回了三条数据,就回了三次表。
总结
对一个知识点要深入理解才行,不能光看表面,死记更背。重要还是去自己思索,才会是自己的东西。
上述写的有问题麻烦大佬指正。