参考教材:人工智能导论(第4版) 王万良 高等教育出版社
实验环境:Python3.6 + Tensor flow 1.12
人工智能导论实验导航
实验一:斑马问题 https://blog.csdn.net/weixin_46291251/article/details/122246347
实验二:图像恢复 https://blog.csdn.net/weixin_46291251/article/details/122561220
实验三:花卉识别 https://blog.csdn.net/weixin_46291251/article/details/122561505
实验四:手写体生成 https://blog.csdn.net/weixin_46291251/article/details/122576478
实验源码: xxx
3.1实验介绍
3.1.1实验背景
深度学习为人工智能核心技术,本章主要围绕深度学习涉及的全连接神经网络、卷积神经网络和对抗神经网络而开设的实验。
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一 。卷积神经网络具有表征学习(representation learning)能力,能够按其阶层结构对输入信息进行平移不变分类(shift-invariant classification)
3.1.2实验目的
本章实验的主要目的是掌握深度学习相关基础知识点,了解深度学习相关基础知识,经典全连接神经网络、卷积神经网络和对抗神经网络。掌握不同神经网络架构的设计原理,熟悉使用Tensorflow 2.1深度学习框架实现深度学习实验的一般流程。
3.1.3实验简介
随着电子技术的迅速发展,人们使用便携数码设备(如手机、相机等)获取花卉图像越来越方便,如何自动识别花卉种类受到了广泛的关注。由于花卉所处背景的复杂性,以及花卉自身的类间相似性和类内多样性,利用传统的手工提取特征进行图像分类的方法,并不能很好地解决花卉图像分类这一问题。
本实验基于卷积神经网络实现的花卉识别实验与传统图像分类方法不同,卷积神经网络无需人工提取特征,可以根据输入图像,自动学习包含丰富语义信息的特征,得到更为全面的花卉图像特征描述,可以很好地表达图像不同类别的信息。
3.2概要设计
本实验将用户在客户端选取的花卉图像作为输入,运行花卉识别模型,实时返回识别结果作为输出结果并显示给用户。
3.2.1功能结构
花卉识别实验总体设计如下图所示,该实验可以划分为数据处理、模型构建、图像识别三个主要的子实验。
其中数据处理子实验包括数据集划分、图像预处理两个部分;
模型构建子实验主要包括模型定义、模型训练以及模型部署三个部分;
图像识别子实验内容主要包括读取花卉图像、运行推断模型进行图像特征提取,输出模型识别结果三个部分。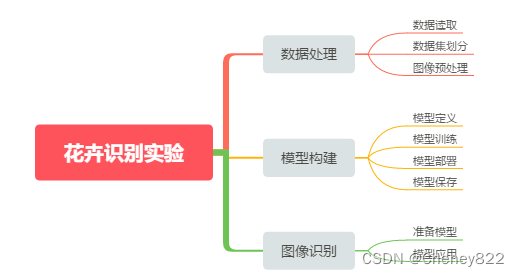
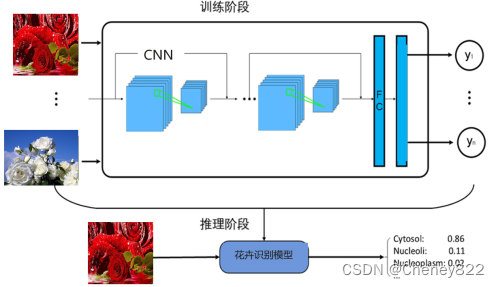
3.2.2体系结构
按照体系结构划分,整个实验的体系结构可以划分为三部分,分别为模型训练、模型保存和模型推理,如图5-3所示。各层侧重点各不相同。
训练层运行在安装有tensorflow框架的服务器,最好配置计算加速卡。
推断层运行于开发环境,能够支持卷积神经网络的加速。
展示层运行于客户端应用程序,能够完成图像选择并实时显示推断层的计算结果。
各层之间存在单向依赖关系。推断层需要的网络模型由训练层提供,并根据需要进行必要的格式转换或加速重构。相应的,展示层要显示的元数据需要由推断层计算得到。
3.3详细设计
3.3.1导入实验环境
步骤 1导入相应的模块
skimage包主要用于图像数据的处理,在该实验当中, io模块主要用于图像数据的读取(imread)和输出(imshow)操作,transform模块主要用于改变图像的大小(resize函数);
glob包主要用于查找符合特定规则的文件路径名,跟使用windows下的文件搜索相似;
os模块主要用于处理文件和目录,比如:获取当前目录下文件,删除制定文件,改变目录,查看文件大小等;
tensorflow是目前业界最流行的深度学习框架之一,在图像,语音,文本,目标检测等领域都有深入的应用,也是该实验的核心,主要用于定义占位符,定义变量,创建卷积神经网络模型;numpy是一个基于python的科学计算包,在该实验中主要用来处理数值运算;
time模块主要用于处理时间系列的数据,在该实验主要用于返回当前时间戳,计算脚本每个epoch运行所需要的时间。
# 导入模块
# -*- coding:uft-8
#from skimage
import glob
import os
import cv2
import tensorflow as tf
from tensorflow.keras import layers, optimizers, datasets, Sequential
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
步骤 2设置初始化环境
# 数据集的地址,改为自己的图片文件地址
path = './flower_photos/'
# 缩放图片大小为100*100,C为通道,彩色图片数值为3
w = 100
h = 100
c = 3types = 0 # 所有花的种类数,也是标签的个数
flower = {0: 'bee', 1: 'blackberry', 2: 'blanket', 3: 'bougainvillea', 4: 'bromelia', 5: 'foxglove'}
3.3.2数据准备
这里通过os.listdir判断给定目录下的是文件还是文件夹,如果是文件夹,那么就进入读取其中的所有文件,这些图像对应的标签就是他们所属的文件夹的编号,遍历完所有子文件夹(这里不限制文件夹数目,可以动态的识别出文件夹)之后便完成了数据集的读取,函数返回读取到的所有图片和图片对应的标签。
# 读取图片
def read_img(path):global typesglobal flowerimgs = []labels = []if not os.path.isdir(path):print("路径不正确")exit(0)for s in os.listdir(path):print("\nfolder ", s)f_label = s.split("_")[-1]flower[types] = s.split("_")[0]# flower[f_label]=s.split("_")[0]s = path + s + "/"if not os.path.isdir(s): # 只读文件夹continuetypes += 1 # 数据集数目加1for im in os.listdir(s):im = s + imprint('\r\tloading :%s' % (im), end="")img = io.imread(im)img = transform.resize(img, (w, h))imgs.append(img)# labels.append(f_label)labels.append(types - 1)return np.asarray(imgs, np.float32), np.asarray(labels, np.int32)
3.3.3构建花卉识别模型
CNN训练模型
模型尺寸分析:卷积层全都采用了补0,所以经过卷积层长和宽不变,只有深度加深。池化层全都没有补0,所以经过池化层长和宽均减小,深度不变。
模型尺寸变化:100×100×3->100×100×32->50×50×32->50×50×64->25×25×64->25×25×128->12×12×128->12×12×128->6×6×128
本文的CNN模型比较简单,后续完全可以通过增大模型复杂度或者改参数调试以及对图像进行预处理来提高准确率。
下面列出网络模型的部分:
这里首先用tf.getvariable创建新的tensorflow变量并用tf.tf.constant_initializer
和tf.constant_initializer初始化为(stddev=0.1)和(0.0)
然后用 tf.nn.conv2d创建2维卷积层步长参数为[1,1,1,1],卷积方式为’SAME’
然后用线性整流函数relu进行处理
with tf.variable_scope('layer1-conv1'):conv1_weights = tf.get_variable("weight",[5,5,3,32],initializer=tf.truncated_normal_initializer(stddev=0.1))conv1_biases = tf.get_variable("bias", [32], initializer=tf.constant_initializer(0.0))conv1 = tf.nn.conv2d(input_tensor, conv1_weights, strides=[1, 1, 1, 1], padding='SAME')relu1 = tf.nn.relu(tf.nn.bias_add(conv1, conv1_biases))
下面类似:
with tf.variable_scope('layer11-fc3'):fc3_weights = tf.get_variable("weight", [512, 5],initializer=tf.truncated_normal_initializer(stddev=0.1))if regularizer != None: tf.add_to_collection('losses', regularizer(fc3_weights))fc3_biases = tf.get_variable("bias", [5], initializer=tf.constant_initializer(0.1))logit = tf.matmul(fc2, fc3_weights) + fc3_biases
下面是池化操作:利用tf.nn.max_pool完成,池化窗口大小为[1,2,2,1],填充方式为VALID表示不填充,窗口在每一个维度上滑动的步长为[1,2,2,1]
with tf.name_scope("layer4-pool2"):pool2 = tf.nn.max_pool(relu2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
3.3.4训练并保存模型
下面给出部分训练模型的代码:
训练过程中输出每一次训练的train loss 、train acc、val loss、val acc用于分析训练的效果。
def train():
......for epoch in range(n_epoch):start_time = time.time()# trainingtrain_loss, train_acc, n_batch = 0, 0, 0for x_train_a, y_train_a in minibatches(x_train, y_train, batch_size, shuffle=True):_, err, ac = sess.run([train_op, loss, acc], feed_dict={x: x_train_a, y_: y_train_a})train_loss += errtrain_acc += acn_batch += 1print("--第"+str(epoch + 1)+"次训练:".ljust(10, " "), end="")print(str((np.sum(train_loss)) / n_batch).ljust(20, " "), (str(np.sum(train_acc) / n_batch)).ljust(20, " "), end="")# validationval_loss, val_acc, n_batch = 0, 0, 0for x_val_a, y_val_a in minibatches(x_val, y_val, batch_size, shuffle=False):err, ac = sess.run([loss, acc], feed_dict={x: x_val_a, y_: y_val_a})val_loss += errval_acc += acn_batch += 1print(str((np.sum(val_loss) / n_batch)).ljust(20, " "), str((np.sum(val_acc) / n_batch)).ljust(20, " "))
3.3.5识别花卉
首先创建用于读取测试的花卉图片的函数,该函数读取测试文件夹中的所有图片并以np.array的形式返回。
def get_test_img(path):imgs = []cv_data = []for im in os.listdir(path):im = path + imprint('\rrecognizing :%s' % (im), end="")img = io.imread(im)img = transform.resize(img, (w, h))imgs.append(img)cv_data.append(cv2.imread(im))return np.asarray(imgs), cv_data
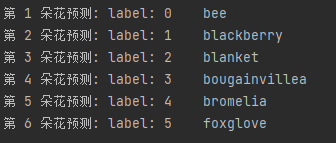
然后就可以利用上述训练得到的判别器来判断所给的图像的标签。然后就可以根据得到的标签输出花的名字
def recog():path = './data/TestImages/'model_path = "./model/"data, cv_datas = get_test_img(path)with tf.Session() as sess:saver = tf.train.import_meta_graph(model_path + 'model.ckpt.meta')saver.restore(sess, tf.train.latest_checkpoint(model_path))graph = tf.get_default_graph()x = graph.get_tensor_by_name("x:0")feed_dict = {x: data}logits = graph.get_tensor_by_name("logits_eval:0")classification_result = sess.run(logits, feed_dict)# 打印出预测矩阵print(classification_result)# 打印出预测矩阵每一行最大值的索引print(tf.argmax(classification_result, 1).eval())# 根据索引通过字典对应花的分类output = tf.argmax(classification_result, 1).eval()for i in range(len(output)):print("第", i + 1, "朵花预测: label:", output[i], "\t", flower[output[i]])font = cv2.FONT_HERSHEY_SIMPLEXimg = cv_datas[i]cv2.putText(img, flower[output[i]], (20, 20), font, 1, (0, 0, 0), 1)# cv2.imshow(flower[output[i]],img)# cv2.waitKey(0) # # 使图片停留用于观察,没有这一行代码,图片会在展示瞬间后消失
由于待识别的图片一共有六张,所以将其排列在一个两行三列的图片之中。
使用pyplot的subplot即可实现,遍历所有图片并分别将图片放第i个位置处。
# 下面改用pyplot绘图以让结果显示在一张图片中pyplot.subplot(2, 3, 1 + i) # 使用subplot()构建子图,第一个参数5表示每列有5张图,第二个参数表示每行有6张图,1+i表示第(1+i张图)pyplot.axis('off') # 关闭坐标轴("on"为显示坐标轴)pyplot.title(flower[output[i]])pyplot.imshow(img, cmap='gray_r') # 使用imshow()函数画出训练集相应图片原始像素数据,参数cmap = gray表示黑底白字图像,这边使用"gray_r"表示白底黑字图
pyplot.savefig('res.png') # 保存图片
pyplot.show()
3.4运行测试
首先读取数据集,由下图可见,程序依次读取了六个文件夹,并从每个文件夹中读取了多张图片。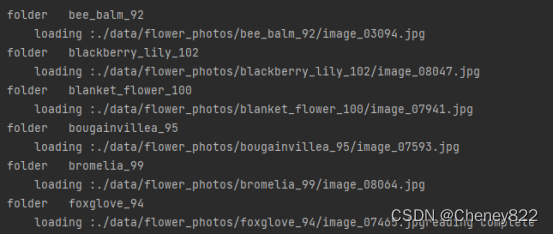
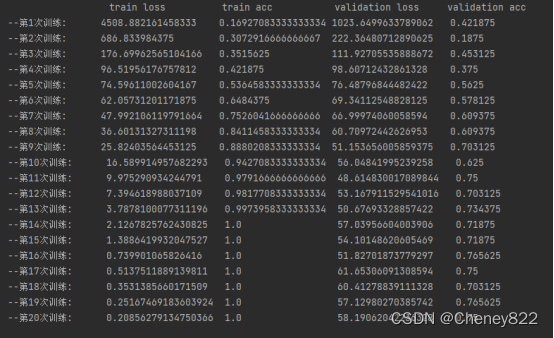
然后开始训练,这里输出了:训练集损失值、:训练集准确率、测试集损失值、测试集准确率这几个指标,通过观察数值变化可以发现:
train loss不断减小
Train acc不断增大直至为1并稳定为1
Val loss 大体上不断减小,但后半部分稍有波动
Val acc 大体上不断增大,但后半部分稍有波动
以上说明网络正在学习,状态良好。
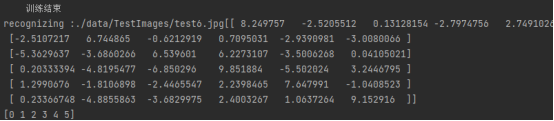
然后输出识别出的花卉对应的标签以及名称:
第1朵花预测: Label: 0 bee
第2朵花预测: Label: 1 bLackberry
第3朵花预测: Label: 2 bLanket
第4朵花预测: Label: 3 bougainvillea
第5朵花预测: Label: 4 bromelia
第6朵花预测: Label: 5 foxgLove
然后将图片和名称显示在一张图片内方便观察。