集群模式(Linux)
注意:检测服务器是否有jdk
1)准备三台服务器
| HOST映射 | IP | CUP | 内存 | 端口 | |
|---|---|---|---|---|---|
| Mster | node01 | 192.168.xx.xx | 16 | 32G | 8080 |
| SlaveFrist | node02 | 192.168.xx.xx | 16 | 32G | 8081 |
| SlaveSecond | node03 | 192.168.xx.xx | 32 | 32G | 8082 |
查看服务器上各个端口是否被占用
netstat -anp |grep 8080
netstat -anp |grep 8081
netstat -anp |grep 8082
2)上传解压kettle的安装包
[root@node01 kettle]# ll
-rw-r--r-- 1 root root 1309895085 8月 7 09:50 data-integration.tar.gz
[root@node01 /]# tar -zxvf data-integration.tar.gz
3)进到data-integration/pwd目录,修改配置文件
修改主服务器配置文件carte-config-master-8080.xml
[root@node01 /]# cd /data/kettle/data-integration/
[root@node01 data-integration]# vim pwd/carte-config-master-8080.xml<slave_config><slaveserver><name>master</name><hostname>node01</hostname><port>8080</port><master>Y</master></slaveserver>
</slave_config>
修改从服务器配置文件carte-config-8081.xml
[root@node01 data-integration]# vim pwd/carte-config-8081.xml<slave_config><masters><slaveserver><name>master</name><hostname>node01</hostname><port>8080</port><username>cluster</username><password>cluster</password><master>Y</master></slaveserver></masters><report_to_masters>Y</report_to_masters><slaveserver><name>SlaveFrist</name><hostname>node02</hostname><port>8081</port><username>cluster</username><password>cluster</password><master>N</master></slaveserver>
</slave_config>
修改从服务器配置文件carte-config-8082.xml
[root@node01 data-integration]# vim pwd/carte-config-8082.xml<slave_config><masters><slaveserver><name>master</name><hostname>node01</hostname><port>8080</port><username>cluster</username><password>cluster</password><master>Y</master></slaveserver></masters><report_to_masters>Y</report_to_masters><slaveserver><name>SlaveFrist</name><hostname>node03</hostname><port>8082</port><username>cluster</username><password>cluster</password><master>N</master></slaveserver>
</slave_config>
分发整个kettle的安装目录
[root@node01 kettle]# ll
总用量 1279208
drwxrwxrwx 17 root root 4096 9月 8 2020 data-integration
-rw-r--r-- 1 root root 1309895085 8月 7 09:50 data-integration.tar.gz
[root@node01 kettle]# scp -r pwd/ node02:$PWD
[root@node01 kettle]# scp -r pwd/ node03:$PWD
4)启动相关进程
[root@node01 /]# cd /data/kettle/data-integration/
[root@node01 data-integration]# nohup ./carte.sh pwd/carte-config-master-8080.xml > ../log/master_8080.log 2>&1 &
[root@node02 data-integration]# nohup ./carte.sh pwd/carte-config-8081.xml > ../log/SlaveFrist_8081.log 2>&1 &
[root@node03 data-integration]# nohup ./carte.sh pwd/carte-config-8082.xml > ../log/SlaveSecond_8082.log 2>&1 &
资源库配置
1)数据库资源库
优点:跨平台易使用
(1)打开kettle图像化界面,点击右上角connect,选择Other Resporitory

(2)选择Database Repository

(3)建立新连接


填好之后,点击finish,会在指定的库中创建很多表,至此数据库资源库创建完成
(4)连接资源库
默认账号密码为admin

2)文件资源库
不需要用户密码就可以访问,跨平台使用比较麻烦
(1)选择connect
(2)点击add后点击Other Repositories
(3)选择File Repository
(4)填写信息

Kettle优化
1)启动参数优化
查看carte.sh 本质还是调用spoon.sh
[root@node01 data-integration]# vim carte.sh
darwin=false;
case "$(uname -s)" inDarwin*)darwin=true;;
esac
BASEDIR="`dirname $0`"
cd "$BASEDIR"
DIR="`pwd`"
cd - > /dev/null
OPT="$OPT -Dorg.mortbay.util.URI.charset=UTF-8"
if [ ! "x$JAAS_LOGIN_MODULE_CONFIG" = "x" -a ! "x$JAAS_LOGIN_MODULE_NAME" = "x" ]; thenOPT=$OPT" -Djava.security.auth.login.config=$JAAS_LOGIN_MODULE_CONFIG"OPT=$OPT" -Dloginmodulename=$JAAS_LOGIN_MODULE_NAME"
fi
if [ "${darwin}" = "true" ]; thenOPT="$OPT -Djava.awt.headless=true"
fi
export OPT
"$DIR/spoon.sh" -main org.pentaho.di.www.Carte "$@"
本机内存较大,为了防止OOM,所以调大内存参数,设置变量(推荐使用系统内存的一半)
PENTAHO_DI_JAVA_OPTIONS="-Xms15000m -Xmx30000m -XX:MaxPermSize=1024m"
(1)创建环境变量(spoon.sh 会判断PENTAHO_DI_JAVA_OPTIONS是否为空)
vim /etc/profile
export PENTAHO_DI_JAVA_OPTIONS="-Xms15000m -Xmx30000m -XX:MaxPermSize=1024m"
# 修改后记得source
source /etc/profile
参数参考:
-Xmx2048m:设置JVM最大可用内存为2048M。
-Xms1024m:设置JVM促使内存为1024m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
-Xmn2g:设置年轻代大小为2G。整个JVM内存大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-Xss128k:设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。更具应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
(2)直接修改spoon.sh文件

2)表输入和表输出开启多线程
(1)配置子服务器

(2)配置Kettle集群schemas

(3)配置Run configurations
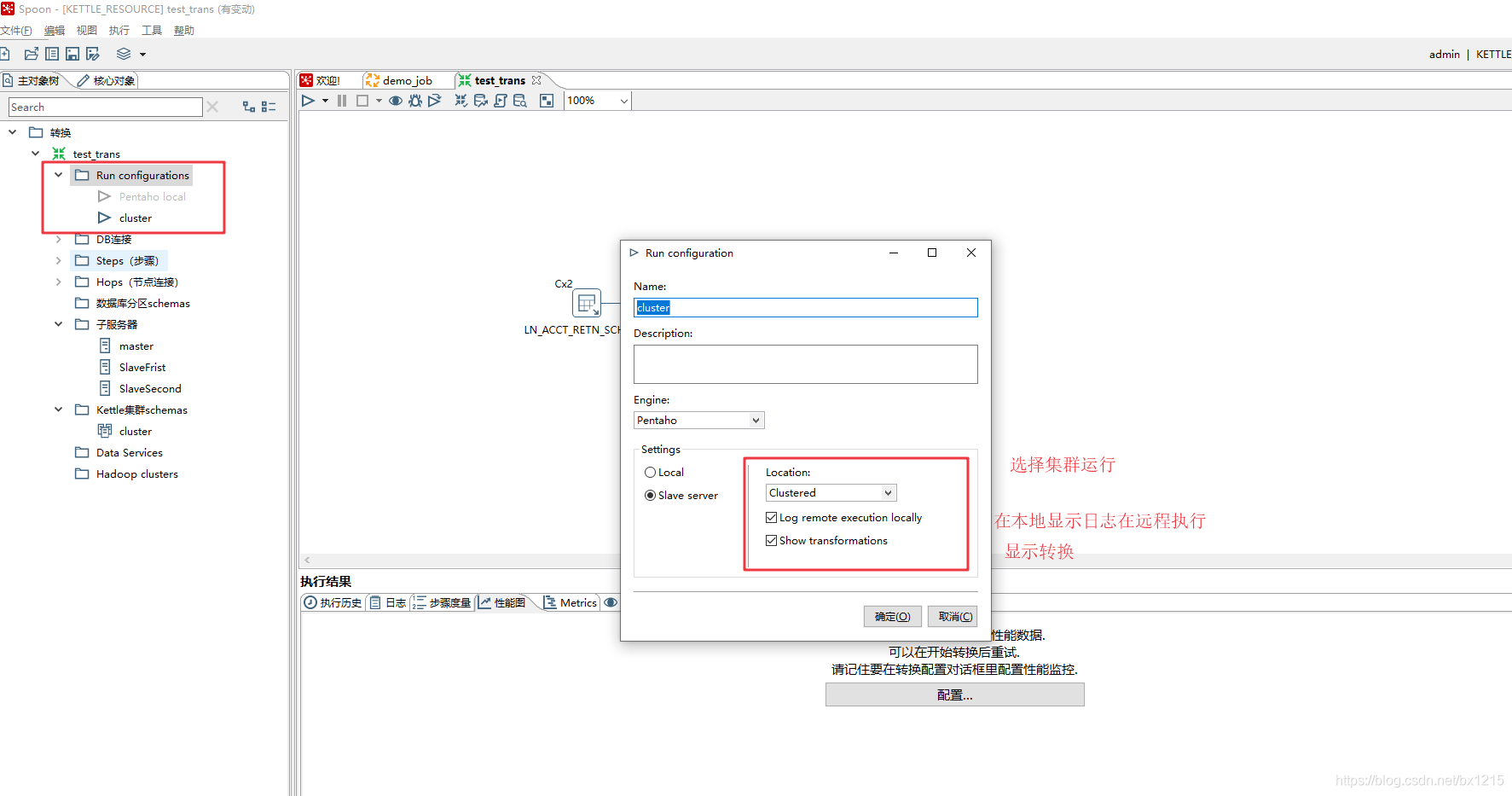
(4)配置转换使用集群执行


注意:表输入如果开启多线程的话,会导致数据重复。比如 select * from test ,起3个线程,就会查3遍,最后的数据就是3份
因为source是oracle,利用oracle的特性: rownum 和函数: mod ,以及kettle的参数: Internal.Step.Unique.Count,Internal.Step.Unique.Number
select * from (SELECT test.*,rownum rn FROM test ) where mod(rn,${Internal.Step.Unique.Count}) = ${Internal.Step.Unique.Number}
解释一下
- rownum 是oracle系统顺序分配为从查询返回的行的编号,返回的第一行分配的是1,第二行是2,意味着,如果排序字段或者数据有变化的话,rownum也会变(也就是跟物理数据没有对应关系,如果要对应关系的话,应该用rowid,但是rowid不是数字,而是类似 AAAR3sAAEAAAACXAAA 的编码),所以需要对rownum进行固化,所以将
SELECT test.*,rownum rn FROM test作为子查询 - mod 是oracle的取模运算函数,比如,
mod(5,3)意即5%3=2,就是5/3=1...2中的2,也就是如果能获取到总线程数,以及当前线程数,取模,就可以对结果集进行拆分了。mod(行号,总线程数)=当前线程序号 - kettle 内置函数
${Internal.Step.Unique.Count}和${Internal.Step.Unique.Number}分别代表线程总数和当前线程序号
而表输出就影响了,开多少线程,kettle都会求总数然后平摊的
表输入时,注意勾选替换变量 表输出!!!不要!!!勾选裁剪表

1.调整提交(Commit)记录数大小进行优化,Kettle默认Commit数量为:1000,可以根据数据量大小来设置Commitsize:1000~50000(尽量提高批处理的commit size)
命令行执行job和trans
1)集群模式
通过界面化配置好JOB集群执行后使用 curl 请求 Web 服务器 发送请求

curl -u "cluster:cluster" "http://node01:8080/kettle/executeJob/?rep=KETTLE_RESOURCE&user=admin&pass=admin&job=/demo_job"参数说明:
executeJob 执行job
rep 资源库设置
user 用户
pass 密码
job job所在路径
2)job
数据库资源库
./kitchen.sh -rep=KETTLE_RESOURCE -user=admin -pass=admin -job=demo_job -logfile=../log/log.txt -dir=/文件资源库
./kitchen.sh -rep=KETTLE_DW -job=demo_job01 -logfile=../log/demo_job01.log -dir=/job/norep 注:需要修改trans指向的路径
./kitchen.sh -norep -file=../job.kjb参数说明:
-rep - 资源库名
-user - 资源库用户名
-pass – 资源库密码
-job – job名
-dir – job路径
-logfile – 日志目录
3)trans
数据库资源库
./pan.sh -rep=KETTLE_RESOURCE -user=admin -pass=admin -trans=demo01 -dir=/文件资源库
./pan.sh -rep=KETTLE_DW -trans=demo_trans01 -dir=/trans/norep
./pan.sh -norep -file=../test01.ktr 参数说明:
-rep 资源库名称
-user 资源库用户名
-pass 资源库密码
-trans 要启动的转换名称
-dir 目录(不要忘了前缀 /)
日志表配置
create table TRANS_LOG
(ID_BATCH NUMBER,CHANNEL_ID VARCHAR2(255),TRANSNAME VARCHAR2(255),STATUS VARCHAR2(15),LINES_READ NUMBER,LINES_WRITTEN NUMBER,LINES_UPDATED NUMBER,LINES_INPUT NUMBER,LINES_OUTPUT NUMBER,LINES_REJECTED NUMBER,ERRORS NUMBER,STARTDATE DATE,ENDDATE DATE,LOGDATE DATE,DEPDATE DATE,REPLAYDATE DATE,LOG_FIELD CLOB
);
comment on table TRANS_LOG is '转换日志表';
comment on column TRANS_LOG.ID_BATCH is 'ID主键,每次转换都会创建';
comment on column TRANS_LOG.CHANNEL_ID is '日志通道 ID (GUID),可以与日志沿袭信息匹配';
comment on column TRANS_LOG.TRANSNAME is '转换名';
comment on column TRANS_LOG.STATUS is '转换的状态:start, end, stopped';
comment on column TRANS_LOG.LINES_READ is '读行数';
comment on column TRANS_LOG.LINES_WRITTEN is '写行数';
comment on column TRANS_LOG.LINES_UPDATED is '更新行数';
comment on column TRANS_LOG.LINES_INPUT is '输入行数';
comment on column TRANS_LOG.LINES_OUTPUT is '输出行数';
comment on column TRANS_LOG.LINES_REJECTED is '指定步骤执行错误行数';
comment on column TRANS_LOG.ERRORS is '错误行数';
comment on column TRANS_LOG.STARTDATE is '开始时间';
comment on column TRANS_LOG.ENDDATE is '结束时间';
comment on column TRANS_LOG.LOGDATE is '日志记录更新时间';
comment on column TRANS_LOG.DEPDATE is '依赖时间';
comment on column TRANS_LOG.REPLAYDATE is '-';
comment on column TRANS_LOG.LOG_FIELD is '将包含运行的完整文本日志的字段';create table TRANS_STEP_LOG
(ID_BATCH NUMBER,CHANNEL_ID VARCHAR2(255),LOG_DATE DATE,TRANSNAME VARCHAR2(255),STEPNAME VARCHAR2(255),STEP_COPY NUMBER,LINES_READ NUMBER,LINES_WRITTEN NUMBER,LINES_UPDATED NUMBER,LINES_INPUT NUMBER,LINES_OUTPUT NUMBER,LINES_REJECTED NUMBER,ERRORS NUMBER
);
comment on table TRANS_STEP_LOG is '步骤日志表';
comment on column TRANS_STEP_LOG.ID_BATCH is '批处理ID';
comment on column TRANS_STEP_LOG.CHANNEL_ID is '日志通道ID';
comment on column TRANS_STEP_LOG.LOG_DATE is '记录日期';
comment on column TRANS_STEP_LOG.TRANSNAME is '转换的名称';
comment on column TRANS_STEP_LOG.STEPNAME is '步骤的名称';
comment on column TRANS_STEP_LOG.STEP_COPY is '步骤复制号';
comment on column TRANS_STEP_LOG.LINES_READ is '从前面步骤中读取的行数';
comment on column TRANS_STEP_LOG.LINES_WRITTEN is '写入以下步骤的行数';
comment on column TRANS_STEP_LOG.LINES_UPDATED is '执行的更新语句的数量';
comment on column TRANS_STEP_LOG.LINES_INPUT is '从输入(文件,数据库,网络,…)读取的行数';
comment on column TRANS_STEP_LOG.LINES_OUTPUT is '此步骤写入输出(文件、数据库、网络、)的行数';
comment on column TRANS_STEP_LOG.LINES_REJECTED is '步骤错误处理拒绝的行数';
comment on column TRANS_STEP_LOG.ERRORS is '在此步骤中遇到的错误数量';create table TRANS_PERFORM_LOG
(ID_BATCH NUMBER,SEQ_NR NUMBER,LOGDATE DATE,TRANSNAME VARCHAR2(255),STEPNAME VARCHAR2(255),STEP_COPY NUMBER,LINES_READ NUMBER,LINES_WRITTEN NUMBER,LINES_UPDATED NUMBER,LINES_INPUT NUMBER,LINES_OUTPUT NUMBER,LINES_REJECTED NUMBER,ERRORS NUMBER,INPUT_BUFFER_ROWS NUMBER,OUTPUT_BUFFER_ROWS NUMBER
);
comment on table TRANS_PERFORM_LOG is '运行(性能)日志表';
comment on column TRANS_PERFORM_LOG.ID_BATCH is '批次ID';
comment on column TRANS_PERFORM_LOG.SEQ_NR is '保持快照记录分离的简单序列号(1..N)';
comment on column TRANS_PERFORM_LOG.LOGDATE is '快照日期和时间';
comment on column TRANS_PERFORM_LOG.TRANSNAME is '为其拍摄性能快照的转换的名称';
comment on column TRANS_PERFORM_LOG.STEPNAME is '为其拍摄性能快照的步骤的名称';
comment on column TRANS_PERFORM_LOG.STEP_COPY is '步数:0..(copies-1)';
comment on column TRANS_PERFORM_LOG.LINES_READ is '间隔期间从先前步骤读取的行数';
comment on column TRANS_PERFORM_LOG.LINES_WRITTEN is '间隔期间写入以下步骤的行数';
comment on column TRANS_PERFORM_LOG.LINES_UPDATED is '间隔内执行的更新语句数';
comment on column TRANS_PERFORM_LOG.LINES_INPUT is '间隔期间从输入(文件、数据库、网络等)读取的行数';
comment on column TRANS_PERFORM_LOG.LINES_OUTPUT is '间隔期间写入输出(文件、数据库、网络等)的行数';
comment on column TRANS_PERFORM_LOG.LINES_REJECTED is '间隔期间步骤错误处理拒绝的行数';
comment on column TRANS_PERFORM_LOG.ERRORS is '错误';
comment on column TRANS_PERFORM_LOG.INPUT_BUFFER_ROWS is '快照时步数输入缓冲区的大小(以行为单位)';
comment on column TRANS_PERFORM_LOG.OUTPUT_BUFFER_ROWS is '快照时输出缓冲区的大小(以行为单位)';create table TRANS_CHANNEL_LOG
(ID_BATCH NUMBER,CHANNEL_ID VARCHAR2(255),LOG_DATE DATE,LOGGING_OBJECT_TYPE VARCHAR2(255),OBJECT_NAME VARCHAR2(255),OBJECT_COPY VARCHAR2(255),REPOSITORY_DIRECTORY VARCHAR2(255),FILENAME VARCHAR2(255),OBJECT_ID VARCHAR2(255),OBJECT_REVISION VARCHAR2(255),PARENT_CHANNEL_ID VARCHAR2(255),ROOT_CHANNEL_ID VARCHAR2(255)
);
comment on table TRANS_CHANNEL_LOG is '日志通道日志表';
comment on column TRANS_CHANNEL_LOG.ID_BATCH is '批次ID';
comment on column TRANS_CHANNEL_LOG.CHANNEL_ID is '记录通道ID';
comment on column TRANS_CHANNEL_LOG.LOG_DATE is '记录日期';
comment on column TRANS_CHANNEL_LOG.LOGGING_OBJECT_TYPE is '对象类型';
comment on column TRANS_CHANNEL_LOG.OBJECT_NAME is '对象名称';
comment on column TRANS_CHANNEL_LOG.OBJECT_COPY is '对象(通常是步骤)复制';
comment on column TRANS_CHANNEL_LOG.REPOSITORY_DIRECTORY is '对象的存储库目录';
comment on column TRANS_CHANNEL_LOG.FILENAME is '文件名';
comment on column TRANS_CHANNEL_LOG.OBJECT_ID is '存储库对象ID';
comment on column TRANS_CHANNEL_LOG.OBJECT_REVISION is '存储库对象修订';
comment on column TRANS_CHANNEL_LOG.PARENT_CHANNEL_ID is '父对象的记录信道ID';
comment on column TRANS_CHANNEL_LOG.ROOT_CHANNEL_ID is '记录此信息的对象的通道ID';create table JOB_LOG
(ID_JOB NUMBER,CHANNEL_ID VARCHAR2(255),JOBNAME VARCHAR2(255),STATUS VARCHAR2(15),LINES_READ NUMBER,LINES_WRITTEN NUMBER,LINES_UPDATED NUMBER,LINES_INPUT NUMBER,LINES_OUTPUT NUMBER,LINES_REJECTED NUMBER,ERRORS NUMBER,STARTDATE DATE,ENDDATE DATE,LOGDATE DATE,DEPDATE DATE,REPLAYDATE DATE,LOG_FIELD CLOB
);
comment on table JOB_LOG is '作业日志表';
comment on column JOB_LOG.ID_JOB is '批次标识,每次作业都会创建';
comment on column JOB_LOG.CHANNEL_ID is '日志通道 ID (GUID),可以与日志沿袭信息匹配';
comment on column JOB_LOG.JOBNAME is '作业的名称';
comment on column JOB_LOG.STATUS is '作业状态:start, end, stopped, running';
comment on column JOB_LOG.LINES_READ is '行数读取的最后一个作业项目(改造)';
comment on column JOB_LOG.LINES_WRITTEN is '最后一个作业条目(转换)写入的行数';
comment on column JOB_LOG.LINES_UPDATED is '最后一个作业条目(转换)执行的更新语句数';
comment on column JOB_LOG.LINES_INPUT is '最后一个作业条目(转换)从磁盘或网络读取的行数这是来自文件、数据库等的输入';
comment on column JOB_LOG.LINES_OUTPUT is '最后一个作业条目(转换)写入磁盘或网络的行数这是文件、数据库等的输入';
comment on column JOB_LOG.LINES_REJECTED is '最后一个作业条目(转换)因错误处理而拒绝的行数';
comment on column JOB_LOG.ERRORS is '发生的错误数';
comment on column JOB_LOG.STARTDATE is '增量 (CDC) 数据处理的日期范围的开始这是最后一次此作业正确运行“日期范围的终结”';
comment on column JOB_LOG.ENDDATE is '增量 (CDC) 数据处理的日期范围结束';
comment on column JOB_LOG.LOGDATE is '此日志记录的更新时间如果作业状态为“结束”,则表示作业结束';
comment on column JOB_LOG.DEPDATE is '依赖日期:作业设置中依赖规则计算的最大日期';
comment on column JOB_LOG.REPLAYDATE is '重播日期是作业开始时间的同义词';
comment on column JOB_LOG.LOG_FIELD is '将包含作业运行的完整文本日志的字段通常这是一个 CLOB 或(长)TEXT 类型的字段';create table JOB_ITEM_LOG
(ID_BATCH NUMBER,CHANNEL_ID VARCHAR2(255),LOG_DATE DATE,TRANSNAME VARCHAR2(255),STEPNAME VARCHAR2(255),LINES_READ NUMBER,LINES_WRITTEN NUMBER,LINES_UPDATED NUMBER,LINES_INPUT NUMBER,LINES_OUTPUT NUMBER,LINES_REJECTED NUMBER,ERRORS NUMBER,RESULT CHAR,NR_RESULT_ROWS NUMBER,NR_RESULT_FILES NUMBER
);
comment on table JOB_ITEM_LOG is '作业项日志表';
comment on column JOB_ITEM_LOG.ID_BATCH is '作业批次ID';
comment on column JOB_ITEM_LOG.CHANNEL_ID is '日志通道ID';
comment on column JOB_ITEM_LOG.LOG_DATE is '记录日期';
comment on column JOB_ITEM_LOG.TRANSNAME is '父作业的名称';
comment on column JOB_ITEM_LOG.STEPNAME is '作业条目名称';
comment on column JOB_ITEM_LOG.LINES_READ is '(转换)作业条目读取的行数';
comment on column JOB_ITEM_LOG.LINES_WRITTEN is '由(转换)作业条目编写的代码行数';
comment on column JOB_ITEM_LOG.LINES_UPDATED is '由(改造)工作进入执行更新语句数';
comment on column JOB_ITEM_LOG.LINES_INPUT is '作业条目从输入(文件、数据库、网络等)读取的行数';
comment on column JOB_ITEM_LOG.LINES_OUTPUT is '作业条目写入输出(文件、数据库、网络等)的行数';
comment on column JOB_ITEM_LOG.LINES_REJECTED is '(转换)作业条目的错误处理拒绝的行数';
comment on column JOB_ITEM_LOG.ERRORS is '错误';
comment on column JOB_ITEM_LOG.RESULT is '结果';
comment on column JOB_ITEM_LOG.NR_RESULT_ROWS is '执行后的结果行数';
comment on column JOB_ITEM_LOG.NR_RESULT_FILES is '执行后的结果文件数';create table JOB_CHANNEL_LOG
(ID_BATCH NUMBER,CHANNEL_ID VARCHAR2(255),LOG_DATE DATE,LOGGING_OBJECT_TYPE VARCHAR2(255),OBJECT_NAME VARCHAR2(255),OBJECT_COPY VARCHAR2(255),REPOSITORY_DIRECTORY VARCHAR2(255),FILENAME VARCHAR2(255),OBJECT_ID VARCHAR2(255),OBJECT_REVISION VARCHAR2(255),PARENT_CHANNEL_ID VARCHAR2(255),ROOT_CHANNEL_ID VARCHAR2(255)
);
comment on table JOB_CHANNEL_LOG is '日志通道日志表';
comment on column JOB_CHANNEL_LOG.ID_BATCH is '批次ID';
comment on column JOB_CHANNEL_LOG.CHANNEL_ID is '记录通道ID';
comment on column JOB_CHANNEL_LOG.LOG_DATE is '记录日期';
comment on column JOB_CHANNEL_LOG.LOGGING_OBJECT_TYPE is '对象类型';
comment on column JOB_CHANNEL_LOG.OBJECT_NAME is '对象名称';
comment on column JOB_CHANNEL_LOG.OBJECT_COPY is '对象(通常是步骤)复制';
comment on column JOB_CHANNEL_LOG.REPOSITORY_DIRECTORY is '对象的存储库目录';
comment on column JOB_CHANNEL_LOG.FILENAME is '文件名';
comment on column JOB_CHANNEL_LOG.OBJECT_ID is '存储库对象ID';
comment on column JOB_CHANNEL_LOG.OBJECT_REVISION is '存储库对象修订';
comment on column JOB_CHANNEL_LOG.PARENT_CHANNEL_ID is '父对象的记录信道ID';
comment on column JOB_CHANNEL_LOG.ROOT_CHANNEL_ID is '记录此信息的对象的通道ID';


每次添加转换和作业都需要配置日志表(有的时候可能会忘记)
解决方案(使用数据库资源库)
-- 添加上面的表 之后添加触发器
-- JOB日志配置
create or replace trigger r_job_logafter inserton r_job_attribute
declare
-- 声明变量v_job integer;v_job_log varchar2(20):='JOB_LOG';v_job_entry_log varchar2(20):='JOB_ITEM_LOG';v_job_channel_log varchar2(20):='JOB_CHANNEL_LOG';-- 数据库连接名v_database_name varchar2(20):='TEST_ODS';
begin-- 查询最新的id_jobselect max(t.id_job) into v_job from R_JOB t;
-- 更新
-- 作业日志表
update r_job_attribute set value_str =v_job_log where
code='JOB_LOG_TABLE_TABLE_NAME' and id_job=v_job;
-- 作业项日志表
update r_job_attribute set value_str =v_job_entry_log where
code='JOB_ENTRY_LOG_TABLE_TABLE_NAME' and id_job=v_job;
-- 日志通道日志表
update r_job_attribute set value_str =v_job_channel_log where
code='CHANNEL_LOG_TABLE_TABLE_NAME' and id_job=v_job;-- 更新数据库连接
update r_job_attribute set value_str =v_database_name where
code='JOB_LOG_TABLE_CONNECTION_NAME' and id_job=v_job;
update r_job_attribute set value_str =v_database_name where
code='JOB_ENTRY_LOG_TABLE_CONNECTION_NAME' and id_job=v_job;
update r_job_attribute set value_str =v_database_name where
code='CHANNEL_LOG_TABLE_CONNECTION_NAME' and id_job=v_job;
end r_job_log;-- TRANSFORMATION日志配置
create or replace trigger r_trans_logafter insert on r_trans_attribute
declare
-- 声明变量v_trans integer;v_trans_log varchar2(20):='TRANS_LOG';v_step_log varchar2(20):='TRANS_STEP_LOG';v_performance_log varchar2(20):='TRANS_PERFORM_LOG';v_channel_log varchar2(20):='TRANS_CHANNEL_LOG';-- 数据库连接名v_database_name varchar2(20):='TEST_ODS';
begin-- 查询最新的id_transformationselect max(t.id_transformation) into v_trans from r_transformation t;
-- 更新
-- 转换日志表
update r_trans_attribute set value_str =v_trans_log where
code='TRANS_LOG_TABLE_TABLE_NAME' and id_transformation =v_trans;
-- 步骤日志表
update r_trans_attribute set value_str =v_step_log where
code='STEP_LOG_TABLE_TABLE_NAME' and id_transformation =v_trans;
-- 运行日志表
update r_trans_attribute set value_str =v_performance_log where
code='PERFORMANCE_LOG_TABLE_TABLE_NAME' and id_transformation =v_trans;
-- 日志通道日志表
update r_trans_attribute set value_str =v_CHANNEL_LOG where
code='CHANNEL_LOG_TABLE_TABLE_NAME' and id_transformation =v_trans;-- 更新数据库连接
update r_trans_attribute set value_str =v_database_name where
code='TRANS_LOG_TABLE_CONNECTION_NAME' and id_transformation
=v_trans;
update r_trans_attribute set value_str =v_database_name where
code='STEP_LOG_TABLE_CONNECTION_NAME' and id_transformation
=v_trans;
update r_trans_attribute set value_str =v_database_name where
code='PERFORMANCE_LOG_TABLE_CONNECTION_NAME' and id_transformation
=v_trans;
update r_trans_attribute set value_str =v_database_name where
code='CHANNEL_LOG_TABLE_CONNECTION_NAME' and id_transformation
=v_trans;
end r_trans_log;