Linux设备之非阻塞I/O操作
文章目录
- Linux设备之非阻塞I/O操作
- 前言
- 一、接口简介
- 1、select
- 2、poll
- 3、epoll
- 4、总结
- 二、接口介绍
- 三、代码样例
前言
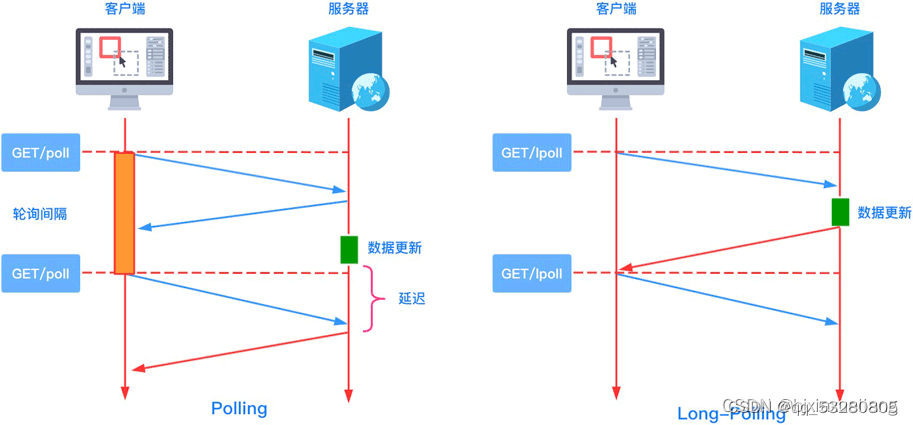
上一篇讲解了Linux设备的阻塞I/O操作,其原理是利用了把进程挂到等待队列中,等条件满足时再唤醒此进程。本片所讲解的是轮询操作,也就是非阻塞的I/O操作。弄清轮询操作主要要弄清select、poll、epoll这三个接口的作用与差别,下面就是对它们的介绍一、接口简介
1、select
select==>时间复杂度O(n)
它仅仅知道了,有I/O事件发生了,却并不知道是哪那几个流(可能有一个,多个,甚至全部),我们只能无差别轮询所有流,找出能读出数据,或者写入数据的流,对他们进行操作。所以select具有O(n)的无差别轮询复杂度,同时处理的流越多,无差别轮询时间就越长。
select本质上是通过设置或者检查存放fd标志位的数据结构来进行下一步处理。这样所带来的缺点是:
1、 单个进程可监视的fd数量被限制,即能监听端口的大小有限。一般来说这个数目和系统内存关系很大,具体数目可以cat /proc/sys/fs/file-max察看。32位机默认是1024个。64位机默认是2048.
2、 对socket进行扫描时是线性扫描,即采用轮询的方法,效率较低。当套接字比较多的时候,每次select()都要通过遍历FD_SETSIZE个Socket来完成调度,不管哪个Socket是活跃的,都遍历一遍。这会浪费很多CPU时间。
3、需要维护一个用来存放大量fd的数据结构,这样会使得用户空间和内核空间在传递该结构时复制开销大。
2、poll
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,如果设备就绪则在设备等待队列中加入一项并继续遍历,如果遍历完所有fd后没有发现就绪设备,则挂起当前进程,直到设备就绪或者主动超时,被唤醒后它又要再次遍历fd。这个过程经历了多次无谓的遍历。
它没有最大连接数的限制,原因是它是基于链表来存储的,但是同样有一个缺点:
1、大量的fd的数组被整体复制于用户态和内核地址空间之间,而不管这样的复制是不是有意义。
2、poll还有一个特点是“水平触发”,如果报告了fd后,没有被处理,那么下次poll时会再次报告该fd。
3、epoll
epoll有EPOLLLT和EPOLLET两种触发模式,LT是默认的模式,ET是“高速”模式。LT模式下,只要这个fd还有数据可读,每次 epoll_wait都会返回它的事件,提醒用户程序去操作,而在ET(边缘触发)模式中,它只会提示一次,直到下次再有数据流入之前都不会再提示了,无 论fd中是否还有数据可读。所以在ET模式下,read一个fd的时候一定要把它的buffer读光,也就是说一直读到read的返回值小于请求值,或者 遇到EAGAIN错误。还有一个特点是,epoll使用“事件”的就绪通知方式,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd,epoll_wait便可以收到通知。
epoll为什么要有EPOLLET触发模式?
如果采用EPOLLLT模式的话,系统中一旦有大量你不需要读写的就绪文件描述符,它们每次调用epoll_wait都会返回,这样会大大降低处理程序检索自己关心的就绪文件描述符的效率.。而采用EPOLLET这种边沿触发模式的话,当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据全部读写完(如读写缓冲区太小),那么下次调用epoll_wait()时,它不会通知你,也就是它只会通知你一次,直到该文件描述符上出现第二次可读写事件才会通知你!!!这种模式比水平触发效率高,系统不会充斥大量你不关心的就绪文件描述符
epoll的优点:
1、没有最大并发连接的限制,能打开的FD的上限远大于1024(1G的内存上能监听约10万个端口);
2、效率提升,不是轮询的方式,不会随着FD数目的增加效率下降。只有活跃可用的FD才会调用callback函数;
即Epoll最大的优点就在于它只管你“活跃”的连接,而跟连接总数无关,因此在实际的网络环境中,Epoll的效率就会远远高于select和poll。
3、 内存拷贝,利用mmap()文件映射内存加速与内核空间的消息传递;即epoll使用mmap减少复制开销。
4、总结
综上,在选择select,poll,epoll时要根据具体的使用场合以及这三种方式的自身特点。
1、表面上看epoll的性能最好,但是在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。
2、select低效是因为每次它都需要轮询。但低效也是相对的,视情况而定,也可通过良好的设计改善
二、接口介绍
下面分别介绍select与poll两个函数对应接口:
1、select
int select(int numfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
参数readfds,writefds,exceptfds分别是被select()监视的读,写和异常处理的文件描述符集合,numfds代表的是需要检查的号码最高的文件描述符加1。timeout参数是一个指向struct timeval类型的指针,它可以使select()在等待timeout时间后若没有文件描述符准备好则返回。struct timeval定义如下:
struct timeval{int tv_sec; //秒int tv_usec; //微秒
}
对于一个文件描述符集合有以下几种操作方法
FD_ZERO(fd_set *set) //清除一个文件描述符集合
FD_SET(int fd, fd_set *set) //将一个文件描述符加入文件描述符集合中
FD_CLR(int fd, fd_set *set) //将一个文件描述符从文件描述符集合中取出
FD_ISSET(int fd, fd_set *set) //判断文件描述符是否被值位
2、poll
在设备驱动中,poll()函数的原型是:
unsigned int (*poll)(struct file *filp, struct poll_table_struct *wait);
第一个参数为file结构体指针,第二个参数为轮询表指针。
在poll()函数中主要进行两个操作:
(1)对可能引起设备文件状态变化的等待队列调用poll_wait()函数,将对应等待队列头添加到poll_table中。
(2)返回表示是否能对设备进行无阻塞读、写访问的掩码。
poll_wait()函数的原型如下:
void poll_wait(struct file *filp, wait_queue_heat_t *queue, struct poll_table_struct *wait);
三、代码样例
在驱动中的poll函数里,首先将设备结构体中的r_wait和w_wait等待队列头添加到等待队列表,然后通过判断dev->current_len是否等于0来获得设备的可读状态,通过判断dev->current_len是否等于MEM_SIZE来获得设备的可写状态。我们在应用程序中使用select机制监控globalfifo的可读写状态。
驱动代码如下:
#include <linux/module.h>
#include <linux/types.h>
#include <linux/fs.h>
#include <linux/errno.h>
#include <linux/mm.h>
#include <linux/sched.h>
#include <linux/init.h>
#include <linux/cdev.h>
#include <asm/io.h>
#include <asm/system.h>
#include <asm/uaccess.h>
#include <linux/slab.h>
#include <linux/poll.h>
#include <linux/wait.h>#define MEM_SIZE 0x1000 //全局内存最大4KB
#define MEM_CLEAR 0x1 //清零全局内存
#define GLOBALMEM_MAJOR 250 //预设的globalmem的主设备号static int globalmem_major = GLOBALMEM_MAJOR;/*整体思想:申请一块全局结构体变量,把它当作一个FIFO,只有当FIFO中有数据的时候,读进程才能把数据读出,而且读取后的数据会从FIFO的全局内存中被拿掉;只有当FIFO非满时,写进程才能往这个FIFO中写入数据。
*/
typedef struct gm_cdev{struct cdev cdev; //字符设备结构体unsigned char mem[MEM_SIZE]; //全局内存struct semaphore sem; //并发控制用的信号量unsigned int current_len; //fifo有效数据长度wait_queue_head_t r_wait; //阻塞读用的等待队列头wait_queue_head_t w_wait; //阻塞写用的等待队列头
}GLOBALFILO;GLOBALFILO *globalmem_dev; //设备结构体指针//文件打开参数
int globalmem_open(struct inode *inode, struct file *file)
{//将设备结构体指针赋值给文件私有数据指针file->private_data = globalmem_dev;return 0;
}//文件释放函数
int globalmem_release(struct inode *inode, struct file *file)
{return 0;
}//ioctl设备控制函数
long globalmem_ioctl(struct file *file, unsigned int cmd, unsigned long arg)
{GLOBALFILO *v_dev = file->private_data; //从文件结构体中取出设备结构体switch(cmd){case MEM_CLEAR:/*用信号量方式实现并发控制,不能用自旋锁,因为copy_to_user会引起进程调度,可能导致内核崩溃*///获得信号量if(down_interruptible(&globalmem_dev->sem)){return -ERESTARTSYS; }memset(v_dev->mem, 0, MEM_SIZE);//释放信号量up(&globalmem_dev->sem);printk(KERN_INFO "globalmem is set to zero\n");break;default:return -EINVAL;}return 0;
}//读函数
static ssize_t globalmem_read(struct file *file, char __user *buf, size_t size, loff_t *ppos)
{int ret = 0;GLOBALFILO *v_dev = file->private_data; //从文件结构体中取出设备结构体DECLARE_WAITQUEUE(wait, current); //定义等待队列/*用信号量方式实现并发控制,不能用自旋锁,因为copy_to_user会引起进程调度,可能导致内核崩溃*///获得信号量if(down_interruptible(&v_dev->sem)){return -ERESTARTSYS; }//把wait等待队列挂到等待队列头上add_wait_queue(&v_dev->r_wait, &wait);//等待FIFO非空while(0 == v_dev->current_len){if(file->f_flags & O_NONBLOCK){//如果文件是非阻塞,则直接退出ret = -EAGAIN;goto out;}//改变进程状态为睡眠__set_current_state(TASK_INTERRUPTIBLE);//释放信号量up(&v_dev->sem);printk(KERN_INFO "%d, In globalmem_read, Begin schedule!\n", __LINE__);//调用其他进程执行schedule();printk(KERN_INFO "%d, In globalmem_read, End schedule!\n", __LINE__);//如果信号唤醒此进程if(signal_pending(current)){ret = -ERESTARTSYS;goto out2;}//获得信号量if(down_interruptible(&v_dev->sem)){return -ERESTARTSYS; }}//把数据从内核空间拷贝到用户空间if(size > v_dev->current_len){size = v_dev->current_len;}if(copy_to_user(buf, (void *)v_dev->mem, size)){ret = -EFAULT;goto out;}else{//fifo有效数据前移memcpy(v_dev->mem, v_dev->mem+size, v_dev->current_len-size);//有效数据长度减少v_dev->current_len -= size;printk(KERN_INFO "read %u bytes, current_len is %u\n", size, v_dev->current_len);//唤醒写等待队列wake_up_interruptible(&v_dev->w_wait);ret = size;}out://释放信号量up(&v_dev->sem);out2://移除等待队列remove_wait_queue(&v_dev->r_wait, &wait);set_current_state(TASK_RUNNING);printk(KERN_INFO "%d, It is end!\n", __LINE__);return ret;
}//写函数
static ssize_t globalmem_write(struct file *file, const char __user *buf, size_t size, loff_t *ppos)
{GLOBALFILO *v_dev = file->private_data; //从文件结构体中取出设备结构体int ret = 0;DECLARE_WAITQUEUE(wait, current); //定义等待队列/*用信号量方式实现并发控制,不能用自旋锁,因为copy_to_user会引起进程调度,可能导致内核崩溃*///获得信号量if(down_interruptible(&v_dev->sem)){return -ERESTARTSYS; }//把wait等待队列挂到等待队列头上add_wait_queue(&v_dev->w_wait, &wait); //等待fifo非满while(MEM_SIZE == v_dev->current_len){if(file->f_flags & O_NONBLOCK){//如果文件是非阻塞,则直接退出ret = -EAGAIN;goto out;} //改变进程状态为睡眠__set_current_state(TASK_INTERRUPTIBLE);//释放信号量up(&v_dev->sem);printk(KERN_INFO "%d, In globalmem_write, Begin schedule!\n", __LINE__);//调用其他进程执行schedule();printk(KERN_INFO "%d, globalmem_write, End schedule!\n", __LINE__);//如果信号唤醒此进程if(signal_pending(current)){ret = -ERESTARTSYS;goto out2;}//获得信号量if(down_interruptible(&v_dev->sem)){return -ERESTARTSYS; }}//把数据从用户空间拷贝到内核空间if(size > MEM_SIZE - v_dev->current_len){size = MEM_SIZE - v_dev->current_len;}if(copy_from_user( (void *)v_dev->mem+v_dev->current_len, buf, size)){ret = -EFAULT;goto out;}else{v_dev->current_len += size;printk(KERN_INFO "write %u bytes, current len is %u\n", size, v_dev->current_len);//唤醒读等待队列wake_up_interruptible(&v_dev->r_wait);ret = size;}out: //释放信号量up(&v_dev->sem);out2:remove_wait_queue(&v_dev->w_wait, &wait);set_current_state(TASK_RUNNING);printk(KERN_INFO "%d, It is end!\n", __LINE__);return ret;
}static unsigned int globalfifo_poll(struct file *filp, struct poll_table_struct *wait)
{unsigned int mask = 0;GLOBALFILO *v_dev = filp->private_data; //获取设备结构体//获得信号量if(down_interruptible(&v_dev->sem)){return -ERESTARTSYS; }//设备结构体中的r_wait和w_wait等待队列头添加到等待队列表poll_wait(filp, &v_dev->r_wait, wait);poll_wait(filp, &v_dev->w_wait, wait);//fifo非空if(0 != v_dev->current_len){mask |= POLLIN | POLLRDNORM; //数据可读取}//fifo非满if(MEM_SIZE != v_dev->current_len){mask |= POLLOUT | POLLWRNORM; //数据可写入}//释放信号量up(&v_dev->sem);return mask;
}
//文件操作结构体
static const struct file_operations global_fops = {.owner = THIS_MODULE, //固定格式.llseek = NULL,.poll = globalfifo_poll,.read = globalmem_read,.write = globalmem_write,.unlocked_ioctl = globalmem_ioctl,.compat_ioctl = NULL,.open = globalmem_open,.release = globalmem_release,
};//初始化并注册cdev设备
static void globalmem_setup_cdev(GLOBALFILO *cdev, int index)
{int errno;int devno = MKDEV(globalmem_major, index); //将主设备号和次设备号换成dev_t类型cdev_init(&cdev->cdev, &global_fops); //静态内存定义初始化cdev->cdev.owner = THIS_MODULE;//把cdev设备加入到内核中去,devno为设备号,1为设备数量errno = cdev_add(&cdev->cdev, devno, 1);if(errno)printk(KERN_NOTICE "Add %d dev is error %d", index, errno);
}//设备驱动加载
int globalmem_init(void)
{int result;dev_t devno = MKDEV(globalmem_major, 0);//申请设备号if(globalmem_major){//静态申请设备号result = register_chrdev_region(devno, 1, "globalmem");}else{//动态申请设备号result = alloc_chrdev_region(&devno, 0 , 1, "globalmem");globalmem_major = MAJOR(devno);}if(result < 0){return result;}//申请设备结构体内存globalmem_dev = kmalloc(sizeof(GLOBALFILO), GFP_KERNEL);if(!globalmem_dev){//申请内存失败result = -ENOMEM;goto err;}memset(globalmem_dev, 0, sizeof(GLOBALFILO));globalmem_setup_cdev(globalmem_dev, 0);//初始化信号量//init_MUTEX(&globalmem_dev->sem); //已被废除sema_init(&globalmem_dev->sem, 1);//初始化读等待队列头init_waitqueue_head(&globalmem_dev->r_wait);//初始化写等待队列头init_waitqueue_head(&globalmem_dev->w_wait);return 0;err:unregister_chrdev_region(devno, 1);return result;
}//设备驱动卸载
void globalmem_exit(void)
{cdev_del(&globalmem_dev->cdev); //内核注销设备kfree(globalmem_dev); //释放设备结构体内存unregister_chrdev_region(MKDEV(globalmem_major, 0), 1); //释放设备号
}MODULE_LICENSE("Dual BSD/GPL");
module_param(globalmem_major, int, S_IRUGO);module_init(globalmem_init);
module_exit(globalmem_exit);应用层测试程序如下
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>#define FIFO_CLEAR 0x1
#define BUFFER_LEN 20
#define GLOBALFIFO "/dev/globalfifo"
int main()
{int fd, num;char rd_ch[BUFFER_LEN] = {0};fd_set rfds, wfds; //读写文件描述符集合//以非阻塞的方式打开/dev/globalfifo设备文件fd = open(GLOBALFIFO, O_RDONLY|O_NONBLOCK);if(-1 != fd){//FIFO清0if(ioctl(fd, FIFO_CLEAR, 0) < 0){printf("Can not clear FIFO!\n");}while(1){//清除文件描述符集合FD_ZERO(&rfds);FD_ZERO(&wfds);//将一个文件描述符加入文件描述符集合中FD_SET(fd, &rfds);FD_SET(fd, &wfds);select(fd+1, &rfds, &wfds, NULL, NULL);//如果数据可读出if(FD_ISSET(fd, &rfds)){printf("We can read msg now!\n");}//如果数据可写入if(FD_ISSET(fd, &wfds)){printf("We can write msg now!\n");}}}else{printf("Can not open device!\n");}}现象是当/dev/globalfifo中为空时,执行应用层测试程序编译出的可执行文件,会发现一直打印“We can write msg now!”如下图所示:

当/dev/globalfifo中有数据但是没有占满全部空间时,执行应用层测试程序编译出的可执行文件,会发现交替打印“We can write msg now!”和“”We can read msg now!如下图所示:

当/dev/globalfifo被占满时,执行应用层测试程序编译出的可执行文件,会发现一直打印“We can read msg now!”如下图所示: