正则通配符的介绍
^ 表示开头 $ 表示结尾 . 表示任意字符 * 表示任意多个
1、元字符匹配
(.) 表示匹配除换行符以外的任意字符。
(\w) 表示匹配字母、下划线、数字 (\W匹配汉字)
(\d) 表示匹配数字
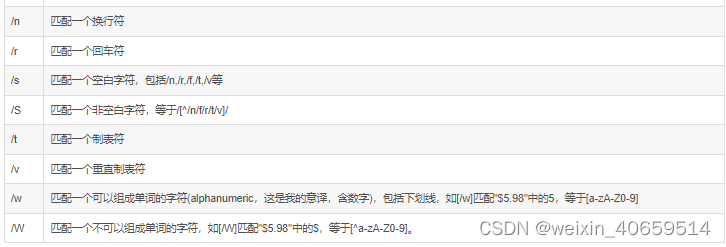
(\s) 表示匹配任意的空白符(tab 换行 空格)
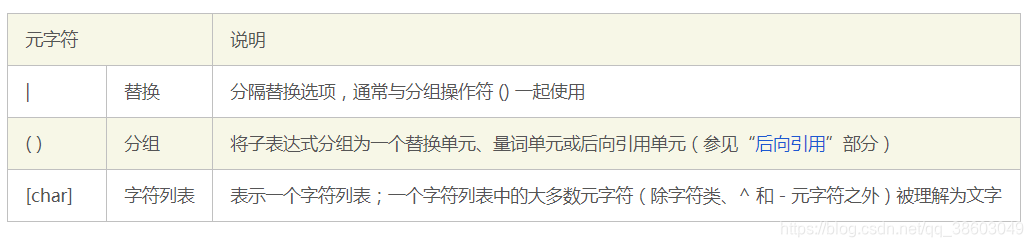
([ ]) 表示匹配方括号中任一字符
([^匹配内容]) 表示不匹配方括号中任一字符
2、位置匹配
(^) 表示匹配字符串的开始,空值:^$
($) 表示匹配字符串的结束
(\b) 表示匹配单词的开始或结束。
(\B) 表示匹配非单词的开始或结束
3、频率匹配
(*) 表示匹配重复0次或多次
(+) 表示匹配重复一次或更多次
(?) 表示匹配重复0次或1次
({n}) 表示匹配重复n次
({n,}) 表示重复n次或更多次
({n,m}) 表示重复n到m次
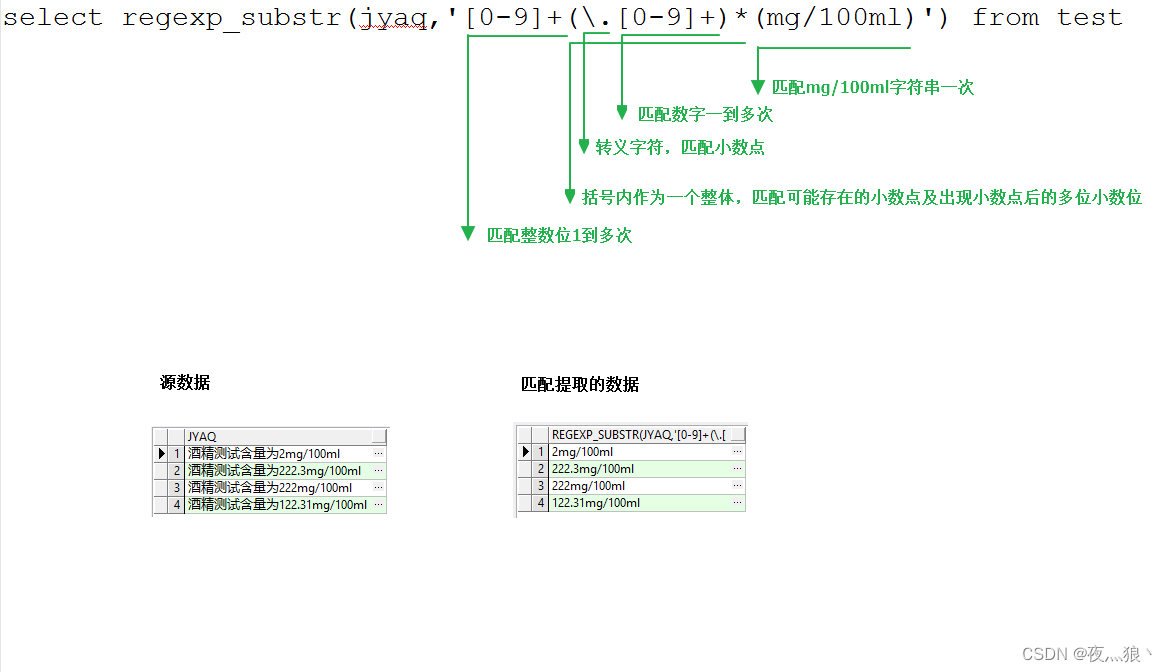
正则匹配函数:regexp_extract函数
用法:
regexp_extract(string subject, string pattern, int index)
返回值: string
功能:将字符串subject按照pattern正则表达式的规则拆分,返回index指定的字符。
regexp_replace(string A, string B, string C)
返回值: string
说明:将字符串A中的符合Java正则表达式B的部分替换为C。注意,在有些情况下要使用转义字符,类似Oracle中的regexp_replace函数。
regexp
语法: A REGEXP B
操作类型: strings
描述: 功能与RLIKE相同 如 xx not regexp '\\d{8}'