基于C++11的线程池(threadpool),简洁且可以带任意多的参数 - _Ong - 博客园
C++11多线程编程(六)——线程池的实现
1.
① thread
#include <iostream>
#include <thread>class A
{
public:void operator()() {std::cout << "11111\n";}
};int main()
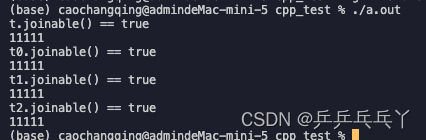
{A a;std::thread t(a);if(t.joinable()){std::cout << "t.joinable() == true\n";t.join();}else{std::cout << "t.joinable() == false\n";}std::thread t0((A())); // 多组括号if(t0.joinable()){std::cout << "t0.joinable() == true\n";t0.join();}else{std::cout << "t0.joinable() == false\n";}std::thread t1{(A())}; // 统一的初始化语法if(t1.joinable()){std::cout << "t1.joinable() == true\n";t1.join();}else{std::cout << "t1.joinable() == false\n";}std::thread t2([]{std::cout << "11111\n";}); // Lamda表达式if(t2.joinable()){std::cout << "t2.joinable() == true\n";t2.join();}else{std::cout << "t2.joinable() == false\n";}return 0;
}
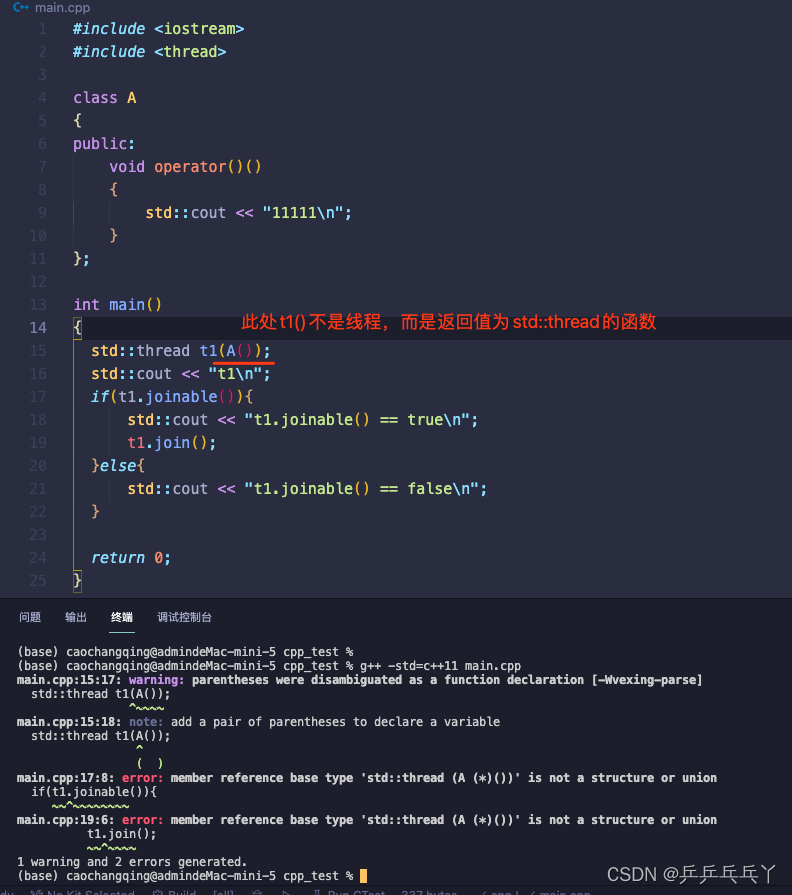
下面这个相当于声明了一个名为t1的函数,这个函数带有一个参数(函数指针指向没有参数并返回A对象的函数),返回一个std::thread对象的函数:
2.竞争冒险(竞态条件)
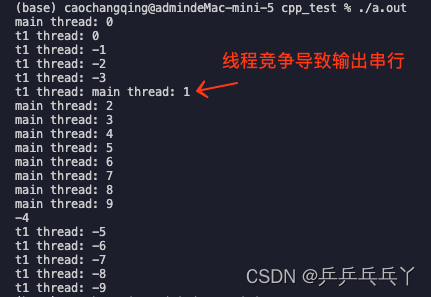
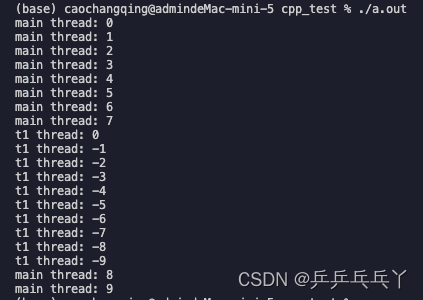
程序的输出依赖于一个或多个线程的执行顺序,最常见的例子是多个线程同时向同一个cout输出。就像下面这样,竞态条件会使得两个线程交替打印,打出来的信息会混到一起:
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;void func1() {for (int i = 0; i > -10; i--)cout << "t1 thread: "<< i << endl;
}int main() {thread t1(func1);for (int i = 0; i < 10; i++)cout << "main thread: " << i << endl;t1.join();return 0;
}
① 使用mutex(互斥锁)解决
解决竞态条件,可以理解为进(线)程同步的方法。
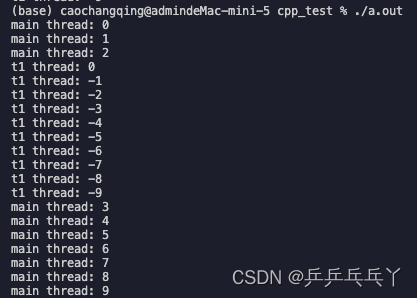
每次调用cout时都使用mutex mu,就能使得每个时间点都只有一个线程在使用mutex,就能防止每行打印混乱。
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
mutex mu;void shared_print(string msg, int id){mu.lock();cout << msg << id << endl;mu.unlock();
}void func1() {for (int i = 0; i > -10; i--)shared_print("t1 thread: ", i);// cout << "t1 thread: "<< i << endl;
}int main() {thread t1(func1);for (int i = 0; i < 10; i++)shared_print("main thread: ", i);// cout << "main thread: " << i << endl;t1.join();return 0;
}
② 使用lock_guard解决
直接使用mutex是有缺陷的。如果mutex.lock()和mutex.unlock()之间的代码出现异常的话,那么mutex就不会被unlock,就会死锁了。因此,不推荐直接使用mutex。因此,推荐使用std::lock_guard<std::mutex> guard(mu)
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
mutex mu;void shared_print(string msg, int id){lock_guard<mutex> guard(mu); // RAII// mu.lock();cout << msg << id << endl;// mu.unlock();
}void func1() {for (int i = 0; i > -10; i--)shared_print("t1 thread: ", i);// cout << "t1 thread: "<< i << endl;
}int main() {thread t1(func1);for (int i = 0; i < 10; i++)shared_print("main thread: ", i);// cout << "main thread: " << i << endl;t1.join();return 0;
}
注:lock_guard在离开作用域时,会自动释放锁,因此使用大括号包围lock之后,调用完lock_guard语句之后会自动析构,释放锁。

虽然lock_guard挺好用的,但是有个很大的缺陷,在定义lock_guard的地方会调用构造函数加锁,在离开定义域的话lock_guard就会被销毁,调用析构函数解锁。这就产生了一个问题,如果这个定义域范围很大的话,那么锁的粒度就很大,很大程序上会影响效率。所以为了解决lock_guard锁的粒度过大的原因,unique_lock就出现了 unique_lock<mutex> unique(mt);
这个会在构造函数加锁,然后可以利用unique.unlock()来解锁,所以当你觉得锁的粒度太多的时候,可以利用这个来解锁,而析构的时候会判断当前锁的状态来决定是否解锁,如果当前状态已经是解锁状态了,那么就不会再次解锁,而如果当前状态是加锁状态,就会自动调用unique.unlock()来解锁。而lock_guard在析构的时候一定会解锁,也没有中途解锁的功能。当然,方便肯定是有代价的,unique_lock内部会维护一个锁的状态,所以在效率上肯定会比lock_guard慢。
所以,以上两种加锁解锁的方法,加上前面文章介绍的mutex方法,具体该使用哪一个,要依照具体的业务需求来决定,当然mt.lock()和mt.unlock()不管是哪种情况,是肯定都可以使用的。
③ 原子操作
互斥锁可以实现数据的同步,但同时是以牺牲性能为代价的。举个例子:我们把0加一再减一,循环一定的次数,开启20个线程来观察,这个正确的结果应该还是等于0的。
首先是不加任何互斥锁同步:
#include <iostream>
#include <thread>
#include <atomic>
#include <time.h>
#include <mutex>
using namespace std;#define MAX 100000
#define THREAD_COUNT 20
int total = 0;void thread_task()
{for (int i = 0; i < MAX; i++){total += 1;total -= 1;}
}int main()
{clock_t start = clock();thread t[THREAD_COUNT];for (int i = 0; i < THREAD_COUNT; ++i){t[i] = thread(thread_task);}for (int i = 0; i < THREAD_COUNT; ++i){t[i].join();}clock_t finish = clock();cout << "result:" << total << endl;cout << "duration:" << finish - start << "ms" << endl;return 0;
}
可见,以上程序运行很快,但是结果却不正确的。
那么我们将线程加上互斥锁mutex再来看看:
#include <iostream>
#include <thread>
#include <atomic>
#include <time.h>
#include <mutex>
using namespace std;#define MAX 100000
#define THREAD_COUNT 20
int total = 0;
mutex mu;void thread_task()
{for (int i = 0; i < MAX; i++){mu.lock();total += 1;total -= 1;mu.unlock();}
}int main()
{clock_t start = clock();thread t[THREAD_COUNT];for (int i = 0; i < THREAD_COUNT; ++i){t[i] = thread(thread_task);}for (int i = 0; i < THREAD_COUNT; ++i){t[i].join();}clock_t finish = clock();cout << "result:" << total << endl;cout << "duration:" << finish - start << "ms" << endl;return 0;
}
我们可以看到运行结果是正确的,但是时间比原来慢太多了。虽然很无奈,但这也是没有办法的,因为只有在保证准确的前提才能去追求性能。
那有没有什么办法在保证准确的同时,又能提高性能呢?通过原子操作。
#include <iostream>
#include <thread>
#include <atomic>
#include <time.h>
#include <mutex>
using namespace std;
#include <atomic>#define MAX 100000
#define THREAD_COUNT 20
// int total = 0;
atomic_int total(0); // 原子操作
mutex mu;void thread_task()
{for (int i = 0; i < MAX; i++){// mu.lock();total += 1;total -= 1;// mu.unlock();}
}int main()
{clock_t start = clock();thread t[THREAD_COUNT];for (int i = 0; i < THREAD_COUNT; ++i){t[i] = thread(thread_task);}for (int i = 0; i < THREAD_COUNT; ++i){t[i].join();}clock_t finish = clock();cout << "result:" << total << endl;cout << "duration:" << finish - start << "ms" << endl;return 0;
}
可以看到,我们在这里只需要定义atomic_int total(0)就可以实现原子操作了,就不需要互斥锁了。而性能的提升也是非常明显的,这就是原子操作的魅力所在。
④ 条件变量
当某个线程持有这把锁的时候(就是所谓的加锁),那么这个线程是独占所有的资源,这里的资源指的是执行的权限,其他要抢夺资源的线程都不得不等待。在很多情况下,这都容易适用,但是有些情况下,却会产生一些异常情况。
在生产消费者模型当中,肯定都会用到互斥锁的机制的,当生产者往队列中放数据的瞬间,消费者是不能取数据的,那这时候可能会碰见一个问题,如果生成者因为某些原因,放数据过慢,但是消费者取数据很快,当队列中没有数据了,消费者还去取的话,就会发生异常情况。有些人可能会说,加个条件判断一下队列是否为空不就可以了。
这个肯定是当然可以的,但是在队列依旧没有数据的这一段时间,是要不断的循环判断这个条件,CPU肯定是会飙升的,浪费了很多不必要的资源。这时候我们设想,能否设计这样的一种机制,如果在队列没有数据的时候,消费者线程能一直阻塞在那里,等待着别人给它唤醒,在生产者往队列中放入数据的时候通知一下这个等待线程,唤醒它,告诉它可以来取数据了。
条件变量是多线程数据同步的一种操作,不管是用哪种框架,哪种语言实现多线程的功能,条件变量都是不得不考虑的一种情况。C++中提供了#include <condition_variable>头文件,里面就包含了条件变量的相关类。其中有两个非常重要的接口,wait()和notify_one(),wait()可以让线程陷入休眠状态,意思就是不干活了,notify_one()就是唤醒真正休眠状态的线程,开始干活了。当然还有notify_all()这个接口,顾名思义,就是通知所有正在等待的线程,起来干活了。
#include <iostream>
#include <deque>
#include <thread>
#include <mutex>
#include <condition_variable>
using namespace std;deque<int> q;
mutex mt;
condition_variable cond; // 条件变量void thread_producer()
{int count = 10;while (count > 0){unique_lock<mutex> unique(mt);q.push_front(count);unique.unlock();cout << "producer a value: " << count << endl;cond.notify_one(); // 唤醒this_thread::sleep_for(chrono::seconds(1));count--;}
}void thread_consumer()
{int data = 0;while (data != 1){unique_lock<mutex> unique(mt);while (q.empty())cond.wait(unique); // 休眠data = q.back();q.pop_back();cout << "consumer a value: " << data << endl;unique.unlock();}
}int main()
{thread t1(thread_consumer);thread t2(thread_producer);t1.join();t2.join();return 0;
}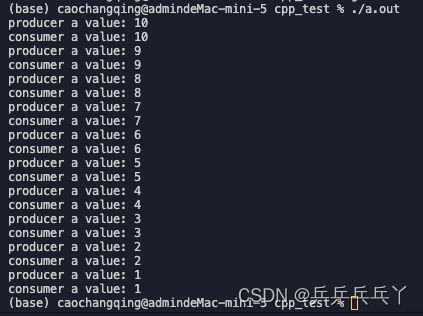
生产者:首先生产者利用unique_lock来加锁,然后将生产的数据放入队列,打印,解锁,一旦解锁之后,消费者获得了执行机会 ——>
消费者:另一方面消费者就会通过unique_lock获得控制权,也就是获得锁,然后判断队列为空的话就一直盗用wait()函数阻塞在那里,等待其他线程来唤醒它。而阻塞该线程时,该函数会自动解锁,允许其他线程执行 ——>
生产者:再次回到生产者这里,生产者线程利用利用条件变量cond.notify_one()来通知阻塞的线程起来干活了 ——>
消费者:阻塞在那里的消费者线程一旦得到notify唤醒,该函数取消阻塞并获取锁,然后取出队列中的数据,并打印,最后解锁 ——>
生产者:再次回到生产者,然后生产者休眠1秒,这里休眠是为了模拟生产者生产慢的情况,实际开发的时候不要去休眠。最后减一,进入下一次生产。
以上就是利用条件变量来实现生产消费者模型,这个会大大降低CPU的占有率,当然代价就是编程稍微有点麻烦,但与这优化程序来比,这肯定是值的。
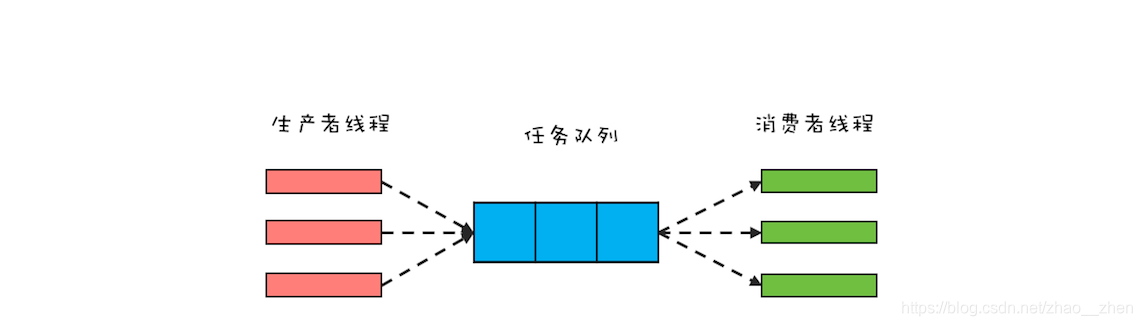
3.线程池
我们可以看到多线程提高了CPU的使用率和程序的工作效率,但是如果有大量的线程,就会影响性能,因为要大量的创建与销毁,因为CPU需要在它们之间切换。线程池可以想象成一个池子,它的作用就是让每一个线程结束后,并不会销毁,而是放回到线程池中成为空闲状态,等待下一个对象来使用。
但是让人遗憾的是,C++并没有在语言级别上支持线程池技术,虽然无法从语言级别上支持,但是我们可以利用条件变量和互斥锁自己实现一个线程池。这里就不得不啰嗦几句,条件变量和互斥锁就像两把利剑,几乎可以实现多线程技术中的大部分问题,不管是生产消费者模型,还是线程池,亦或是信号量,所以我们必须好好掌握好这两个工具。
思路:
-
对于线程池ThreadPool,必须要有构造和析构函数,构造函数中,创建N个线程(这个自己指定),插入到工作线程当中,工作线程可以是vector结构。工作线程中的线程具体要做什么呢?进入线程的时候必要用unique_lock进程加锁处理,不能让其他线程以及主线程影响到要处理的这个线程。判断任务队列是否为空,如果为空,则利用条件变量中的wait函数来阻塞该线程,等待任务队列不为空之后唤醒它。然后取出任务队列中的任务,执行任务中的具体操作。
-
接着将任务放入任务队列taskQueue,这里的任务是外部根据自己的业务自己定义的,可以是对象,可以是函数,结构体等等,而任务队列这里定义为queue结构,一定要记得将任务放入任务队列的时候,要在之前加锁,放入之后在解锁,这里的加锁解锁可以用unique_lock结构,当然也可以用mutex结构,而放入任务队列之后就可以用条件变量的notify_one函数通知阻塞的线程来取任务处理了。
-
线程池的实现就有点像是生产消费者模型,append()就像是生产者,不断的将任务放入队列,run()函数就像消费者,不断的从任务队列中取出任务来处理,生产消费的两头分别用notify_one()和wait()来唤醒和阻塞。更加详细的介绍可以去看我的上一篇文章。
-
最后写一个main文件来调用线程池的相关接口,main文件里定义一个任务对象,然后是main函数。
实现:
threadPool.h
/** @Author: error: error: git config user.name & please set dead value or install git && error: git config user.email & please set dead value or install git & please set dead value or install git* @Date: 2023-02-08 15:25:55* @LastEditors: error: error: git config user.name & please set dead value or install git && error: git config user.email & please set dead value or install git & please set dead value or install git* @LastEditTime: 2023-02-08 15:29:36* @FilePath: /cpp_test/threadPool.h* @Description: 这是默认设置,请设置`customMade`, 打开koroFileHeader查看配置 进行设置: https://github.com/OBKoro1/koro1FileHeader/wiki/%E9%85%8D%E7%BD%AE*/
#ifndef _THREADPOOL_H
#define _THREADPOOL_H
#include <vector>
#include <queue>
#include <thread>
#include <iostream>
#include <condition_variable>
using namespace std;const int MAX_THREADS = 1000; //最大线程数目template <typename T>
class threadPool
{
public:threadPool(int number = 1);~threadPool();bool append(T *task);//工作线程需要运行的函数,不断的从任务队列中取出并执行static void *worker(void *arg);void run();private://工作线程vector<thread> workThread;//任务队列queue<T *> taskQueue;mutex mt;condition_variable condition;bool stop;
};template <typename T>
threadPool<T>::threadPool(int number) : stop(false)
{if (number <= 0 || number > MAX_THREADS)throw exception();for (int i = 0; i < number; i++){cout << "create thread:" << i << endl;workThread.emplace_back(worker, this);}
}template <typename T>
inline threadPool<T>::~threadPool()
{{unique_lock<mutex> unique(mt);stop = true;}condition.notify_all();for (auto &wt : workThread)wt.join();
}template <typename T>
bool threadPool<T>::append(T *task)
{//往任务队列添加任务的时候,要加锁,因为这是线程池,肯定有很多线程unique_lock<mutex> unique(mt);taskQueue.push(task);unique.unlock();//任务添加完之后,通知阻塞线程过来消费任务,有点像生产消费者模型condition.notify_one();return true;
}template <typename T>
void *threadPool<T>::worker(void *arg)
{threadPool *pool = (threadPool *)arg;pool->run();return pool;
}template <typename T>
void threadPool<T>::run()
{while (!stop){unique_lock<mutex> unique(this->mt);//如果任务队列为空,就停下来等待唤醒,等待另一个线程发来的唤醒请求while (this->taskQueue.empty())this->condition.wait(unique); T *task = this->taskQueue.front();this->taskQueue.pop();if (task)task->process();}
}
#endifmain.cpp
#include "threadPool.h"
#include <string>
using namespace std;class Task
{
private:int total = 0;public:void process();
};//任务具体实现什么功能,由这个函数实现
void Task::process()
{//这里就输出一个字符串cout << "task successful!" << endl;this_thread::sleep_for(chrono::seconds(1));
}template class std::queue<Task>;
int main(void)
{threadPool<Task> pool(1);std::string str;while (1){Task *task = new Task();pool.append(task);delete task;}
}