先转一篇大佬的博客论文阅读笔记:图像分割方法deeplab以及Hole算法解析
下面是caffe-ssd的vgg16输出后的变化,减少了一个pooling,stride=1,然后下一层采用了 dilation方法,作用按上面博客说是
既想利用已经训练好的模型进行fine-tuning,又想改变网络结构得到更加dense的score map.
即想让输出的feature map更加的稠密,于是用了hole算法,
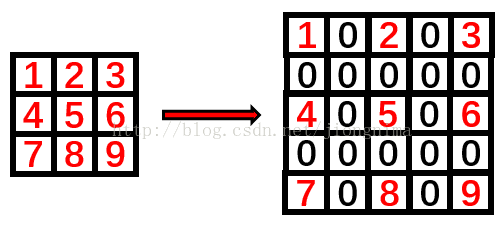
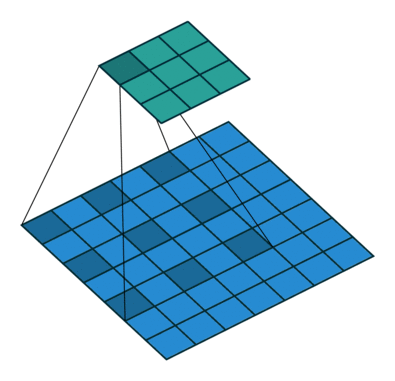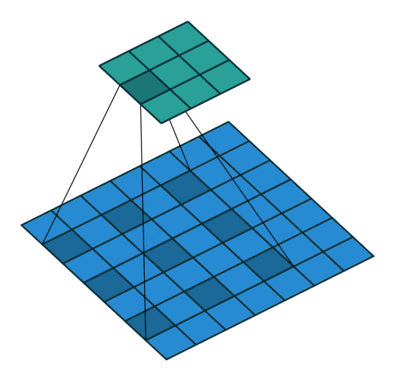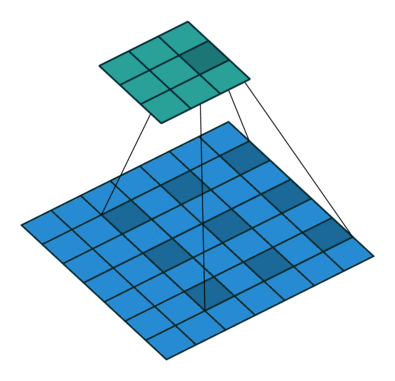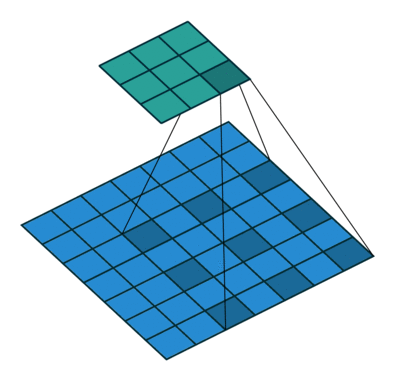
下面一个图能说明作用
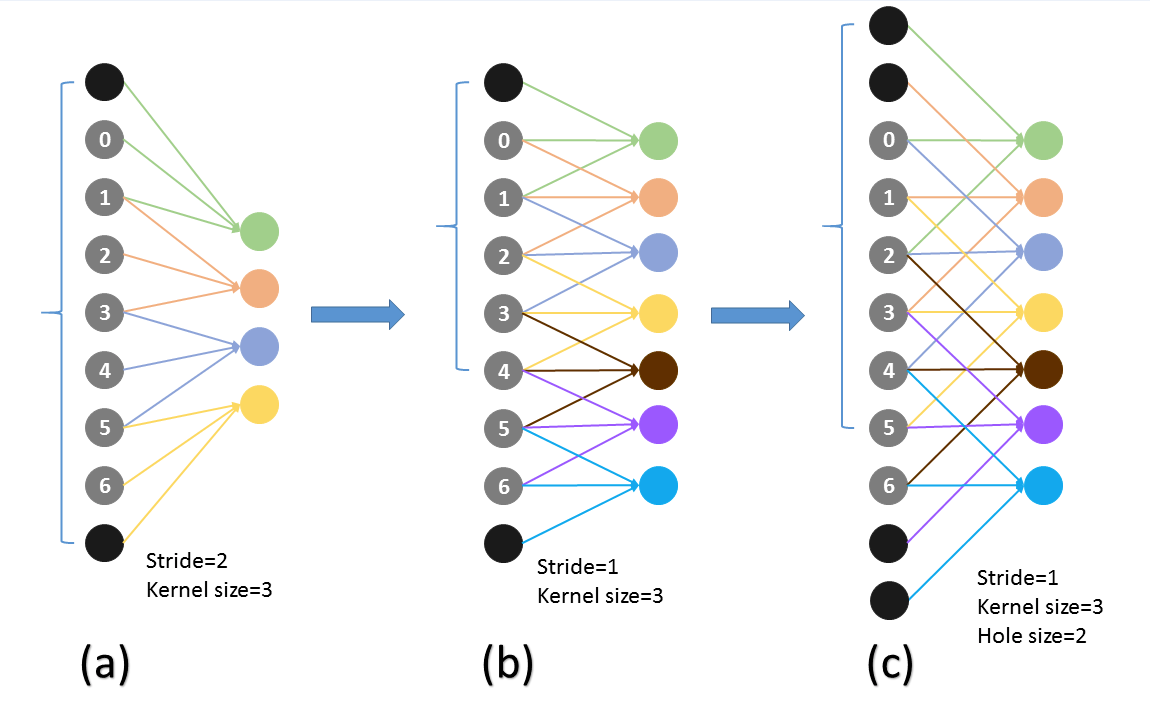
上图的颜色其实有问题,应该这么看,图a的输出0123对于图b输出的0246,然后再下一层(c)采用hole算法,c的第三个输出来自0,2,4这对应a中输出的123,所以c层有a的下一层的所有内容,同时又增加到7个输出(相比与原始a的下一层的2个输出),所以输出变得dense了
layer {name: "pool5" //和vgg16的差别,修改了输出type: "Pooling"bottom: "conv5_3"top: "pool5"pooling_param { //注意这个pooling层,步长为1,pad为1那么pool层保持原fmap不变,所以300*300的图像到这里是19*19(300/16)pool: MAXkernel_size: 3stride: 1pad: 1}
}
layer {name: "fc6" //全连接层type: "Convolution"bottom: "pool5"top: "fc6"param {lr_mult: 1.0decay_mult: 1.0}param {lr_mult: 2.0decay_mult: 0.0}convolution_param {num_output: 1024pad: 6kernel_size: 3 //6×(3-1)+1=13,所以pad=6weight_filler {type: "xavier"}bias_filler {type: "constant"value: 0.0}dilation: 6 //膨胀系数 http://blog.csdn.net/jiongnima/article/details/69487519 这篇博客讲的很清楚,理解为放大,没有的地方变成0}
}
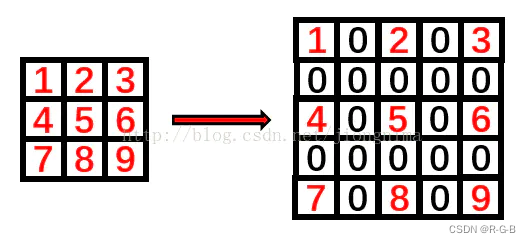




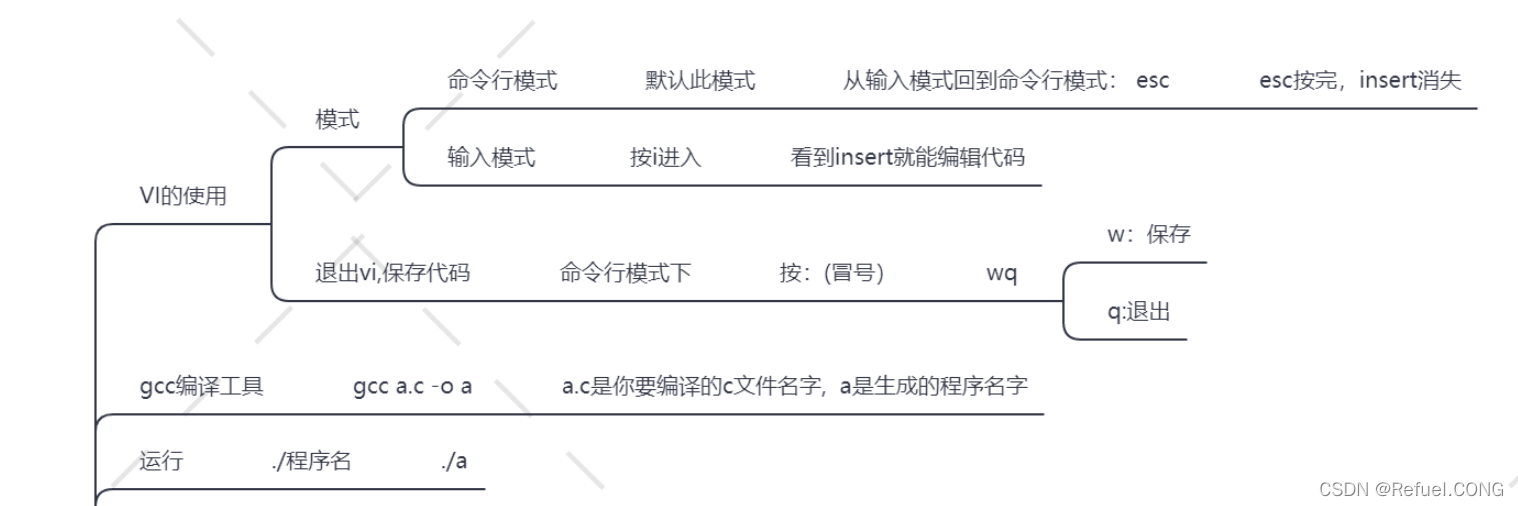
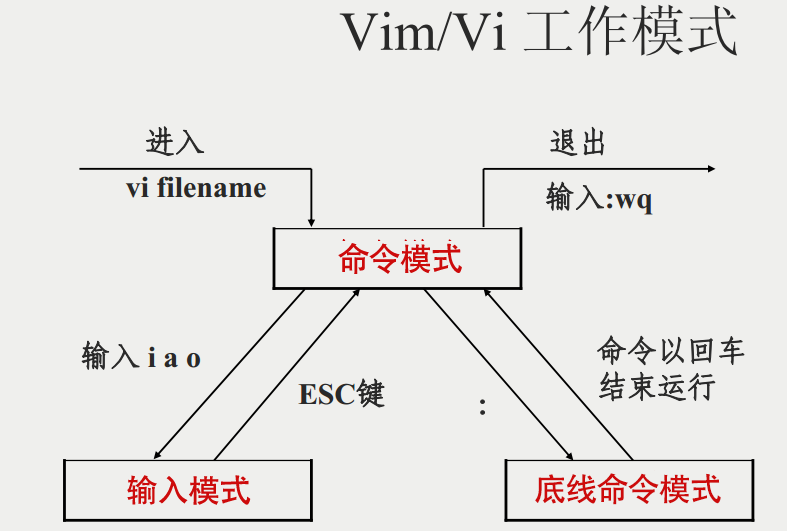



快速入门Linux基础指令](https://img-blog.csdnimg.cn/img_convert/e00dd2f6c79103150c60515a7e1ae9c0.png)

