今天,分布式计算引擎是许多分析、批处理和流应用程序的支柱。Spark提供了许多开箱即用的高级功能(pivot、分析窗口函数等)来转换数据。有时需要处理分层数据或执行分层计算。许多数据库供应商提供诸如“递归 CTE(公用表达式)”或“join” SQL 子句之类的功能来查询/转换分层数据。CTE 也称为递归查询或父子查询。在这篇文章中,我们将看看如何使用 Spark 解决这个问题。
分层数据概述 –
存在分层关系,其中一项数据是另一项的父项。分层数据可以使用图形属性对象模型表示,其中每一行都是一个顶点(节点),连接是连接顶点的边(关系),列是顶点的属性。

一些用例
- 财务计算 - 子账户一直累积到父账户直至最高账户
- 创建组织层次结构 - 经理与路径的员工关系
- 使用路径生成网页之间的链接图
- 任何类型的涉及链接数据的迭代计算
挑战
在分布式系统中查询分层数据有一些挑战
数据是连接的,但它分布在分区和节点之间。解决这个问题的实现应该针对执行迭代和根据需要移动数据(shuffle)进行优化。
图的深度会随着时间的推移而变化——解决方案应该处理不同的深度,并且不应该强制用户在处理之前定义它。
解决方案
在 spark 中实现 CTE 的方法之一是使用Graphx Pregel API。
什么是 Graphx Pregel API?
Graphx 是用于图形和图形并行计算的 Spark API。图算法本质上是迭代的,顶点的属性取决于它们直接或间接(通过其他顶点连接)连接顶点的属性。Pregel 是由 Google 和 spark graphX 开发的以顶点为中心的图处理模型,它提供了 pregel api 的优化变体。
Pregel API 如何工作?
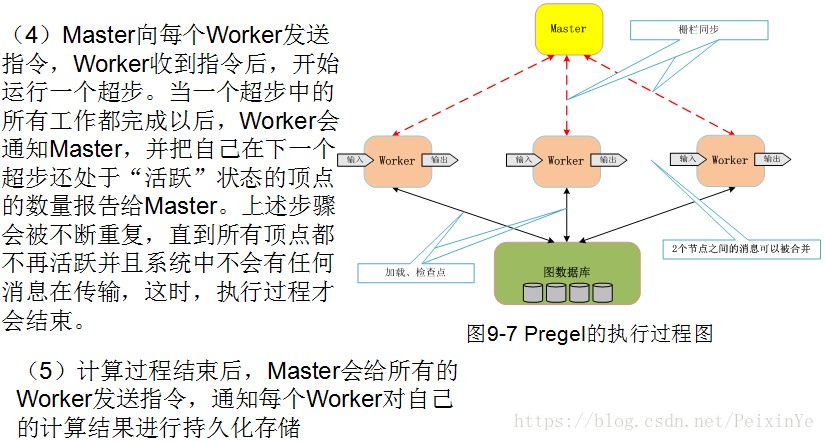
Pregel API 处理包括执行超级步骤
步骤 0:
将初始消息传递给所有顶点
将值作为消息发送到其直接连接的顶点
步骤 1:
接收来自前面步骤的消息
改变值
将值作为消息发送到其直接连接的顶点
重复 步骤 1 直到有消息传递,当没有更多消息传递时停止。
用例的分层数据
下表显示了我们将用于生成自上而下的层次结构的示例员工数据。这里员工的经理由具有 emp_id 值的 mgr_id 字段表示。

添加以下列作为处理的一部分
| Level (Depth) | 顶点在层次结构中所处的级别 |
|---|---|
| Path | 层次结构中从最顶层顶点到当前顶点的路径 |
| Root | 层次结构中最顶层的顶点,当数据集中存在多个层次结构时很有用 |
| Iscyclic | 如果有坏数据,存在循环关系,然后标记它 |
| Isleaf | 如果顶点没有父节点,则标记它 |
代码
import org.apache.log4j.{Level, Logger}
import org.apache.spark.graphx._
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}import scala.util.hashing.MurmurHash3/*** Pregel API* @author zyh*/
object PregelTest {// The code below demonstrates use of Graphx Pregel API - Scala 2.11+// functions to build the top down hierarchy//setup & call the pregel api//设置并调用pregel apidef calcTopLevelHierarcy(vertexDF: DataFrame, edgeDF: DataFrame): RDD[(Any,(Int,Any,String,Int,Int))] = {// create the vertex RDD// primary key, root, pathval verticesRDD: RDD[(VertexId, (Any, Any, String))] = vertexDF.rdd.map{x=> (x.get(0),x.get(1) , x.get(2))}.map{ x => (MurmurHash3.stringHash(x._1.toString).toLong, ( x._1.asInstanceOf[Any], x._2.asInstanceOf[Any] , x._3.asInstanceOf[String]) ) }// create the edge RDD// top down relationshipval EdgesRDD = edgeDF.rdd.map{x=> (x.get(0),x.get(1))}.map{ x => Edge(MurmurHash3.stringHash(x._1.toString).toLong, MurmurHash3.stringHash(x._2.toString).toLong,"topdown" )}// create graphval graph = Graph(verticesRDD, EdgesRDD).cache()val pathSeperator = """/"""// 初始化消息// initialize id,level,root,path,iscyclic, isleafval initialMsg = (0L,0,0.asInstanceOf[Any], List("dummy"),0,1)// add more dummy attributes to the vertices - id, level, root, path, isCyclic, existing value of current vertex to build path, isleaf, pkval initialGraph = graph.mapVertices((id, v) => (id, 0, v._2, List(v._3), 0, v._3, 1, v._1) )val hrchyRDD = initialGraph.pregel(initialMsg,Int.MaxValue, // 迭代次数, 设置成当前表示无限迭代下去EdgeDirection.Out)(setMsg,sendMsg,mergeMsg)// build the path from the listval hrchyOutRDD = hrchyRDD.vertices.map{case(id,v) => (v._8,(v._2,v._3,pathSeperator + v._4.reverse.mkString(pathSeperator),v._5, v._7 )) }hrchyOutRDD}//改变顶点的值def setMsg(vertexId: VertexId, value: (Long,Int,Any,List[String], Int,String,Int,Any), message: (Long,Int, Any,List[String],Int,Int)): (Long,Int, Any,List[String],Int,String,Int,Any) = {// 第一次收到的消息是初始化的消息 initialMsgprintln(s"设置值: $value 收到消息: $message")if (message._2 < 1) { //superstep 0 - initialize(value._1,value._2+1,value._3,value._4,value._5,value._6,value._7,value._8)}else if ( message._5 == 1) { // set isCyclic (判断是不是一个环)(value._1, value._2, value._3, value._4, message._5, value._6, value._7,value._8)} else if ( message._6 == 0 ) { // set isleaf(value._1, value._2, value._3, value._4, value._5, value._6, message._6,value._8)}else { // set new values//( message._1,value._2+1, value._3, value._6 :: message._4 , value._5,value._6,value._7,value._8)( message._1,value._2+1, message._3, value._6 :: message._4 , value._5,value._6,value._7,value._8)}}// 将值发送到顶点def sendMsg(triplet: EdgeTriplet[(Long,Int,Any,List[String],Int,String,Int,Any), _]): Iterator[(VertexId, (Long,Int,Any,List[String],Int,Int))] = {val sourceVertex: (VertexId, Int, Any, List[String], Int, String, Int, Any) = triplet.srcAttrval destinationVertex: (VertexId, Int, Any, List[String], Int, String, Int, Any) = triplet.dstAttrprintln(s" 源头: $sourceVertex 目的地: $destinationVertex")// 检查是不是一个死环, 就是 a是b的领导, b是a的领导// check for icyclicif (sourceVertex._1 == triplet.dstId || sourceVertex._1 == destinationVertex._1) {println(s"存在死环 源头: ${sourceVertex._1} 目的地: ${triplet.dstId}")if (destinationVertex._5 == 0) { //set iscyclicIterator((triplet.dstId, (sourceVertex._1, sourceVertex._2, sourceVertex._3, sourceVertex._4, 1, sourceVertex._7)))} else {Iterator.empty}}else {// 判断是不是叶子节点,就是没有子节点的节点,属于叶子节点,根节点不算 ,所以样例数据中的叶子节点是 3,8,10if (sourceVertex._7==1) //is NOT leaf{Iterator((triplet.srcId, (sourceVertex._1,sourceVertex._2,sourceVertex._3, sourceVertex._4 ,0, 0 )))}else { // set new valuesIterator((triplet.dstId, (sourceVertex._1, sourceVertex._2, sourceVertex._3, sourceVertex._4, 0, 1)))}}}// 从所有连接的顶点接收值def mergeMsg(msg1: (Long,Int,Any,List[String],Int,Int), msg2: (Long,Int, Any,List[String],Int,Int)): (Long,Int,Any,List[String],Int,Int) = {println(s"合并值: $msg1 $msg2")// dummy logic not applicable to the data in this usecasemsg2}// Test with some sample datadef main(args: Array[String]): Unit = {// 屏蔽日志Logger.getLogger("org.apache.spark").setLevel(Level.WARN)val spark: SparkSession = SparkSession.builder.appName(s"${this.getClass.getSimpleName}").master("local[1]").getOrCreate()val sc = spark.sparkContext// RDD 转 DF, 隐式转换import spark.implicits._val empData = Array(// 测试没有顶级的父节点,会出现空指针异常,构建图的时候,会根据边生成一个为null的顶点("EMP001", "Bob", "Baker", "CEO", null.asInstanceOf[String]), ("EMP002", "Jim", "Lake", "CIO", "EMP001"), ("EMP003", "Tim", "Gorab", "MGR", "EMP002"), ("EMP004", "Rick", "Summer", "MGR", "EMP002"), ("EMP005", "Sam", "Cap", "Lead", "EMP004"), ("EMP006", "Ron", "Hubb", "Sr.Dev", "EMP005"), ("EMP007", "Cathy", "Watson", "Dev", "EMP006"), ("EMP008", "Samantha", "Lion", "Dev", "EMP007"), ("EMP009", "Jimmy", "Copper", "Dev", "EMP007"), ("EMP010", "Shon", "Taylor", "Intern", "EMP009")// 空指针和顶点数据重复没有关系// 空指针和父节点在顶点中找不到有关系 (父顶点为null没有关系,需要父顶点能够在顶点列表中能找到), ("EMP011", "zhang", "xiaoming", "CTO", null))// create dataframe with some partitionsval empDF = sc.parallelize(empData, 3).toDF("emp_id","first_name","last_name","title","mgr_id").cache()// primary key , root, path - dataframe to graphx for verticesval empVertexDF = empDF.selectExpr("emp_id","concat(first_name,' ',last_name)","concat(last_name,' ',first_name)")// parent to child - dataframe to graphx for edgesval empEdgeDF = empDF.selectExpr("mgr_id","emp_id").filter("mgr_id is not null")// call the functionval empHirearchyExtDF: DataFrame = calcTopLevelHierarcy(empVertexDF,empEdgeDF).map{ case(pk,(level,root,path,iscyclic,isleaf)) => (pk.asInstanceOf[String],level,root.asInstanceOf[String],path,iscyclic,isleaf)}.toDF("emp_id_pk","level","root","path","iscyclic","isleaf").cache()// extend original table with new columnsval empHirearchyDF = empHirearchyExtDF.join(empDF , empDF.col("emp_id") === empHirearchyExtDF.col("emp_id_pk")).selectExpr("emp_id","first_name","last_name","title","mgr_id","level","root","path","iscyclic","isleaf")// printempHirearchyDF.show()}
}
输出

任务执行
Spark 作业分解为作业、阶段和任务。由于其迭代性质,Pregel API 在内部生成多个作业。每次将消息传递到顶点时都会生成一个作业。由于数据可能位于不同的节点上,因此每个作业可能会以多次 shuffle 结束。
需要注意的是在处理大型数据集时创建的长 RDD 谱系。

概括
Graphx Pregel API 非常强大,可用于解决迭代问题或任何图形计算。