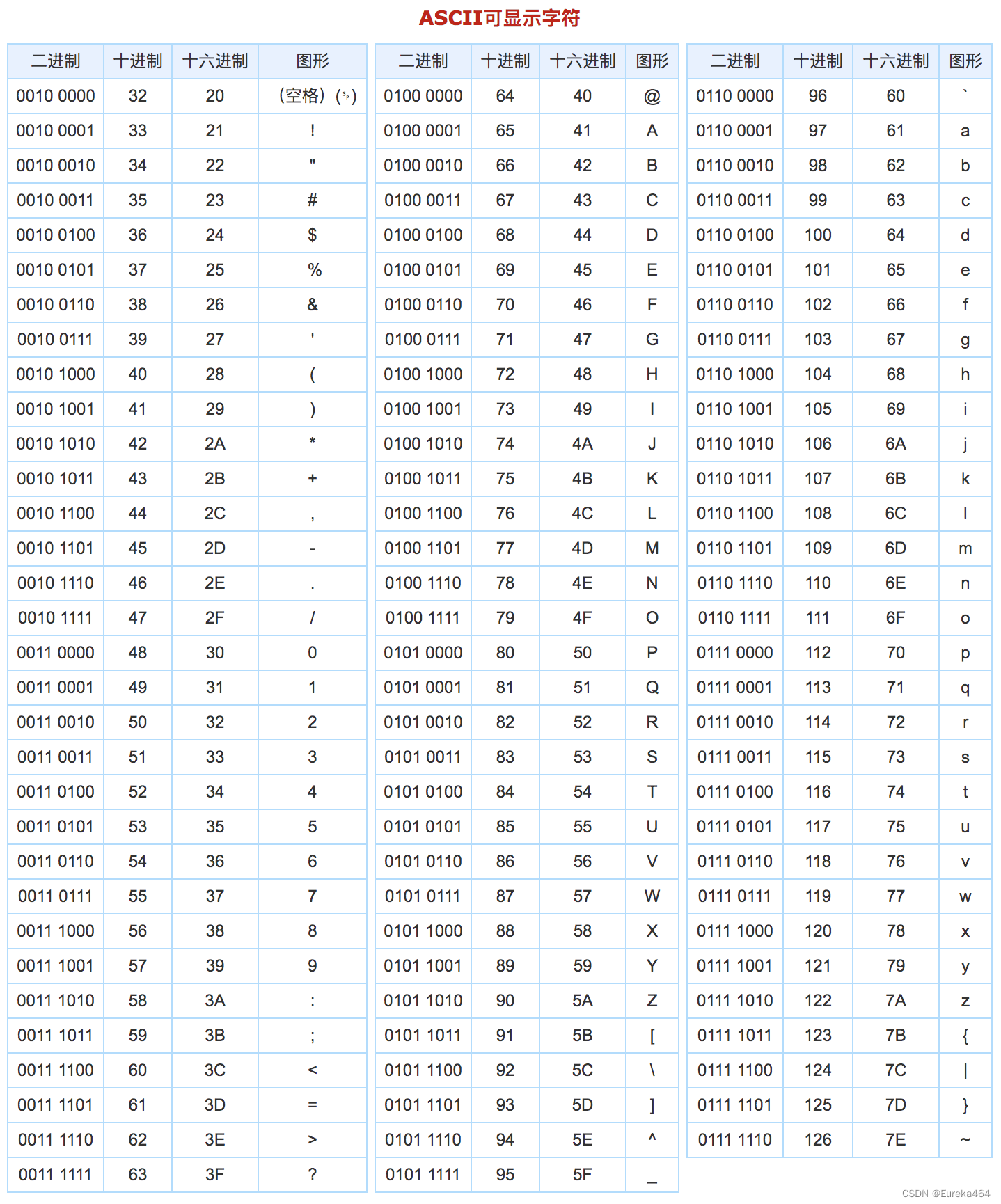
python入门学习笔记目录
- 1.编程概论
- 1.1 注释
- 1.2 打印与标记符
- 1.2.1 打印 print
- 1.2.2标记符
- 1.3 代码行
- 1.3.1 单行语句
- 1.3.2 多行语句
- 1.3.3 缩进
- 1.3.4 复合语句
- 1.4 关键字
- 1.5 基本对象数据类型
- 1.5.1type() 函数
- 1.5.2 isinstance() 判断函数
- 1.5.3 type 与 isinstance
- 1.6 常量与变量
- 1.7 语法
- 1.7.1 错误与异常
- 1.8 python操作符
- 1.8.1 算术操作符
- 1.8.2 比较操作符
- 1.8.3 逻辑操作符
- 1.8.4 赋值操作符
- 1.9 条件语句
- 1.9.1 if 条件语句
- 1.9.2 if...else 语句
- 1.9.3 if...elif...else 语句
- 1.9.4 三元操作符
- 1.10 挑战练习
- 2. 基本对象类型
- 2.1 数字类型
- 2.1.1 数字类型转换
- 2.1.2 数字类型可以进行运算
- 2.1.3 数字函数
- 2.1.4 随机数函数
- 2.1.5 三角函数
- 2.1.6 数字常量
- 2.1.7 math
- 2.2 字符串(str)
- 2.2.1 转义符 \
- 2.2.2 字符串的运算
- 2.2.2.1 字符串的拼接
- 2.2.2.2 字符串的乘法 *
- 2.2.2.3 原始字符串
- 2.2.2.4 索引和切片
- 2.2.2.5 成员运算符 in / not in
- 2.2.2.6 字符串的最值和比较
- 2.2.3 字符串的格式化输出(format 函数)
- 2.2.4 常用的字符串方法
- 2.2.4.1 字符大小写的转换
- 2.2.4.2 字符串的判断方法
- 2.2.4.3 字符串的分割 split() 方法
- 2.2.4.4 去除空格
- 2.2.4.5 拼接字符串 join() 方法
- 2.2.4.6 替换 replace()
- 2.2.5 字符串挑战练习
- 2.3 列表 list
- 2.3.1 定义
- 2.3.2 索引和切片
- 2.3.3 反转
- 2.3.4 列表的基本方法
- 2.3.4.1 reverse()
- 2.3.4.2 append 和 extend
- 2.3.4.3 count
- 2.3.4.4 index
- 2.3.4.4 insert
- 2.3.4.5 remove 和 pop
- 2.3.4.6 sort
- 2.3.4.7 列表的修改
- 2.3.4.8 多维列表
- 2.3.4.9 总结(列表与字符串)
- 2.4 元祖
- 2.4.1 创建元祖
- 2.4.2 索引和切片
- 2.4.3 列表与元祖的转化
- 2.5 字典
- 2.5.1 创建字典
- 2.5.2 访问字典中的值
- 2.5.3 字典的基本操作
- 2.5.4 字符串格式化输出补充
- 2.5.5 字典的方法
- 2.5.5.1 clear
- 2.5.5.2 copy
- 2.5.5.3 get 和 setdefault
- 2.5.5.4 items,keys,values
- 2.5.5.5 pop,popitem
- 2.5.5.6 update
- 2.6 集合 set
- 2.6.1 创建集合
- 2.6.2 set 的方法
- 2.6.3 不变的集合
- 2.6.4 集合的运算
- 2.6.4.1 元素与集合的关系
- 2.6.4.1 集合与集合的关系
- 3. 循环
- 3.1 for 循环
- 3.1.1 range(start,stop[,step])
- 3.1.2 zip() 函数
- 3.1.3 enumerate()
- 3.1.4 列表解析(列表推导)
- 3.1.5 字典解析
1.编程概论
1.1 注释
- 注释是使用特殊的符号告诉编程语言忽略这行代码,简单来说注释是给人看的,让人能更容易读懂代码,而编程系统会自动忽略注释的内容。
单行注释 #
- 单行注释可以使用 符号 # 创建注释
# 开始学习python啦,第一行代码是学会打印hello world,print('hello world!')
print('hello world!')

多行注释
- 使用3对单引号或者3对双引号来创建多行注释
'''
今天是周二
开始学习python啦
坚持就是胜利
'''
# 或者
"""
这是多行注释
编程机器不会运行的模块
但是程序员可以通过这来了解我们为什么这样写代码
"""
1.2 打印与标记符
1.2.1 打印 print
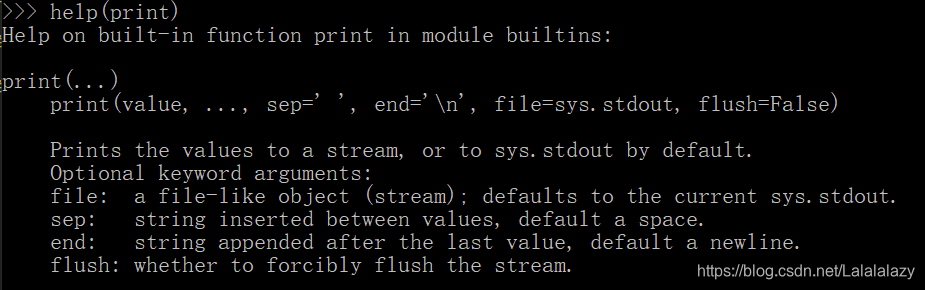
- 程序打印内容使用关键字 print ,它可以打印任何内容,记得要带上圆括号引号,英文状态
print('好好学习,天天向上')
print('good good study,day day up!')

- 我们可以使用内置函数 help() 来查看 print 的用法与功能
- 同样的,以后碰到不懂的函数都可以使用内置函数 help() 来查看相关用法与功能。
1.2.2标记符
- 标记符的第一个字符必须是字母表中的字母或者下划线_
- 标记符的其他部分由字母数字和下划线组成
- 标记符区分大小写
1.3 代码行
1.3.1 单行语句
- 我们写程序的时候,都是由一行一行的代码组成的,代码的最左边一般都有行数以区别代码。
- 单行语句也称简单语句:一般是由一行代码组成
1.3.2 多行语句
- 有时候代码比较长,可能不止一行,这时候可以使用反斜杠、三引号、圆括号、方括号或者大括号扩
展至新一行,实现多行语句
print('''This is a really really
really really long line ofcode.''')
- 另外,还可以使用反斜杠 \ 对代码进行换行
print\
("""his is a really really
really really long line ofcode.""")
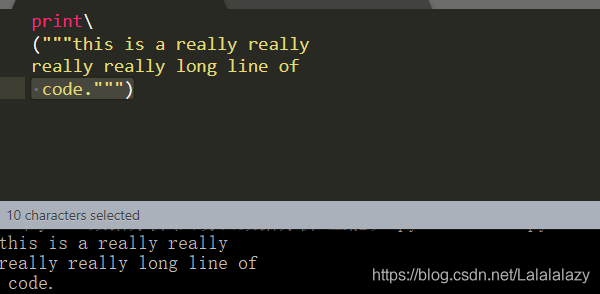
- 这里主要体现了:反斜杠可以将(""“This is a really really really long line of code.”"")和 print 放在不同的行,实现多行语句
total = item_one + \item_two + \item_three
- 另外圆括号()、方括号[]、大括号{}也可以实现多行语句,可自行了解
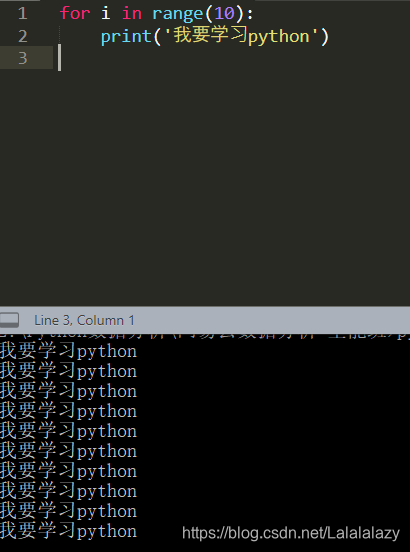
1.3.3 缩进
- 缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数。
- 缩进表示代码块的开始和结束
for i in range(10):print('我要学习python')
if 1>2:print('true')
else:print('false')
-
也许这里会更好理解,print(‘true’)与print(‘false’)这两行有相同的缩进,缩进了4个空格,代表的是同一个代码块。缩进的空格数可以变,但是同一个代码块缩进数应该一样,否则代码无法正常运行,会提示异常。
-
缩进不一致时,执行后会出现错误:缩进错误
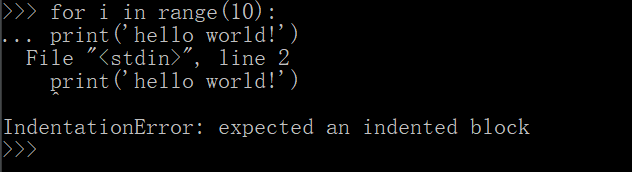
1.3.4 复合语句
- 复合语句由一个或多个从句(clause)组成。
- 从句包括两行或多行代码
- 代码头(header)及紧随其后的配套代码(suite)。代码头指的是从句中包含关键字的那行代码,之后是一个冒号和一行或多行带缩进的代码。缩进之后,是一个或多个配套代码。配套代码就是从句中一行普通的代码。代码头控制配套代码的执行。
- 下面将介绍的条件语句就是复合语句组成的,现在我们先看一个简单的例子:打印10次 hello world !
for i in range(10):print('hello world!')
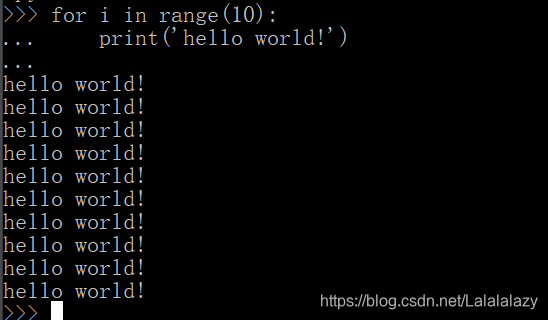
1.4 关键字
- 关键字也称保留字,是编程语言中具有特殊意义的字,我们在编程命名的时候要避免以关键字来命名,不能把关键字用作任何标记符的名称。
- 可以使用python标准库提供的 keyword 模块输出当前版本的所有关键字,以下所示。
import keyword
tmp = keyword.kwlist
print(tmp)

- import keyword 只是导入这个模块,想要把关键字都显示出来,我们需要把关键字的列表赋给一个变量,再把变量打印出来。所以这里令 tmp = keyword.kwlist ,再 print(tmp)
1.5 基本对象数据类型
- 在python中,万物皆对象,对象有类型。
- 对象有3个属性的数据值:唯一标识(其在计算机中的内存地址,不变)、数据类型(对象所属的数据类别,决定了对象的属性,不变)、值(对象表示的数据)
- 基本的数据类型有6种: Number(数字)、String(字符串)、List(列表)、Tuple(元组)、Set(集合)、Dictionary(字典)
- 数据类型为 NoneType 的对象,其值永远为 None,用来表示数据缺失。
其中
- 不可变数据类型:Number(数字)、String(字符串)、Tuple(元组);
- 可变数据类型:List(列表)、Dictionary(字典)、Set(集合)。
1.5.1type() 函数
- python内置的 type() 函数可以用来查询变量所指的对象类型。
type(2)type(2.1)type(None)type('hello world')
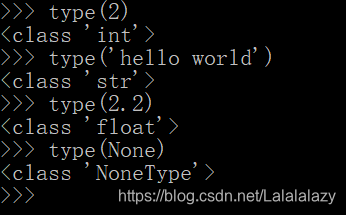
1.5.2 isinstance() 判断函数
- isinstance 存在
- isinstance(object, classinfo) ——object 是变量,classinfo 是类型
- 若参数 object 是 classinfo 类的实例,或者 object 是 classinfo 类的子类的一个实例, 返回 True。
- 若 object 不是一个给定类型的的对象, 则返回结果总是False。
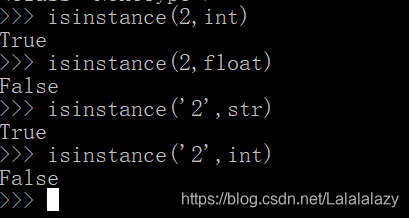
1.5.3 type 与 isinstance
-共同点:两者都可以判断对象类型
-不同点:type()不会认为子类是一种父类类型,isinstance()会认为子类是一种父类类型。
1.6 常量与变量
- 顾名思义,常量是不会变的值;而变量是会改变的值
- 变量可以由一个或多个字符组成的名称构成,并可以使用赋值符 等号(=)赋予这个名称一个值
1.7 语法
- 语法(syntax)指的是规范一门语言中句子结构,尤其是字词顺序的一整套规则及流程。
- 在 Python 中,字符串永远被包括在引号内,这就是 Python 的一个语法示例。
1.7.1 错误与异常
-
Python 有两种错误:语法错误和异常。
-
在编写 python 程序时如果不注意语法的正确使用,在程序运行时就会出现错误,这种错误属于语法错误。
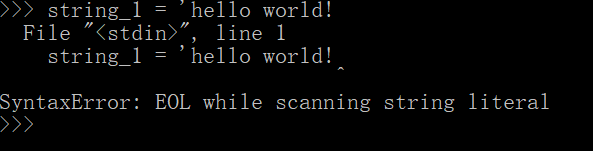
-
如上,字符串的右侧少了个引号,程序便无法执行了,并给出相关的错误信息:语法错误。
-
错误信息会告诉你错误位于哪个文件,出现在哪一行,以及属于什么类型。
-
针对这种语法错误,我们可以找到出错的地方,相应地去修改,就可以正常运行了
-
而 python 中不属于语法错误的错误,就是异常(exception)。
-
出现异常时,Python 程序会说“Python(或程序)报了一个异常”
-
比如不小心把0用作分母,就会出现“ZeroDivisionError”异常
-
比如代码缩进不正确,程序会报“IdentationError”
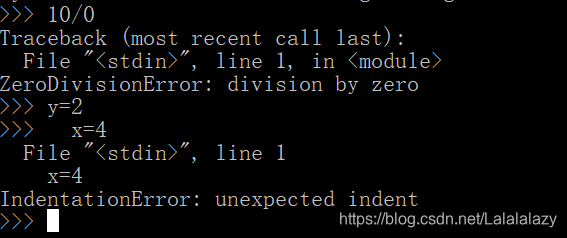
1.8 python操作符
- Python 有多个类型的操作符,下面先了解算术操作符、比较操作符、逻辑操作符
1.8.1 算术操作符
| 操作符 | 含义 | 示例 | 结果 |
|---|---|---|---|
| ** | 指数运算 | 2**3 | 8 |
| % | 取模运算,即取余数 | 14%4 | 2 |
| // | 整除运算,即取整数 | 14//4 | 3 |
| / | 除法运算,返回浮点数 | 13/8 | 1.625 |
| * | 乘法运算 | 8*2 | 16 |
| - | 减法运算 | 7-1 | 6 |
| + | 加法运算 | 2+3 | 5 |

- 操作数:操作符两侧的值
- 表达式:两个操作数和一个操作符共同构成一个表达式
- 程序运行时,Python 会对每个表达式求值,并返回一个值作为结果。
- 运算顺序:括号(parentheses)、指数(exponents)、乘法(multiplication)、除法(division)、加法(addition)和减法(subtraction)
1.8.2 比较操作符
| 操作符 | 含义 | 示例 | 结果 |
|---|---|---|---|
| > | 大于 | 100>10 | True |
| < | 小于 | 100<10 | False |
| >= | 大于等于 | 2>=2 | True |
| <= | 小于等于 | 1<=4 | True |
| == | 等于 | 6==9 | False |
| != | 不等于 | 3!=2 | True |

- 这里可以区分一下 = 与 == ,= 在 python 中是用来给变量赋值的,而 == 是用来比较两边是否相等。
1.8.3 逻辑操作符
| 操作符 | 含义 | 示例 | 结果 |
|---|---|---|---|
| and | 与(都真才真) | True and True | True |
| or | 或(一真则真) | True or False | True |
| not | 非 | not True | False |
- 关键字 and 可以连接两个表达式,如果二者求值均为 True,则返回 True。
- 在一个语句中可以多次使用 and 关键字
- 关键字 or 可连接两个或多个表达式,如果任意一个表达式的值为 True,即返回True
- 在一个语句中可以多次使用 and 、or
- 如果表达式原本的求值结果为 True,加上 not 之后结果会变为False
- 所以,将关键字 not 放置在表达式的前面,将改变表达式的求值结果,逆转为原本结果的对立值。
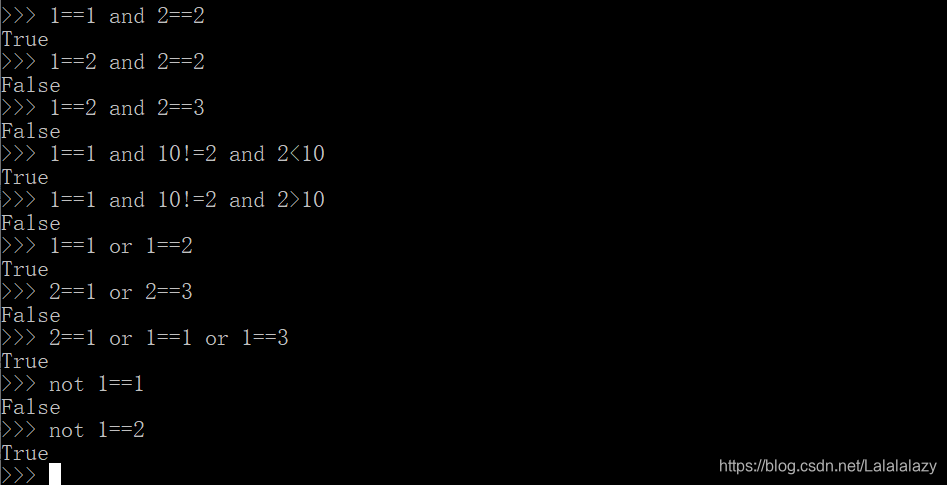
- 在 and、or、not 三种运算中,非运算 not 级别最高,and 次之,or 运算级别最低
- not(a and b) 等价于 not a or not b;
- not(a or b) 等价于 not a and not b;
- not(not a) 等价于 a;
1.8.4 赋值操作符
| 操作符 | 说明 | 示例 | 结果 |
|---|---|---|---|
| = | 简单的赋值操作符 | a=3 | 把3赋值给a |
| += | 加法赋值操作符 | a+=3 | 把a+3的值赋给a,即a=a+3 |
| -= | 减法赋值操作符 | a-=1 | 把a-1的值赋给a,即 a=a-1 |
| *= | 乘法赋值操作符 | a*=2 | 把a2的值赋给a,即 a=a2 |
| /= | 除法赋值操作符 | a/=2 | 把a/2的值赋给a,即a=a/2 |
| %= | 取模赋值操作符 | a%=2 | 把a%2的值赋给a,即 a=a%2 |
| //= | 取商赋值操作符 | a//2 | 把a//2的值赋给a,即 a=a//2 |
| **= | 幂赋值操作符 | a**=2 | 把a**2的值赋给a,即 a=a%2 |
| := | 海象运算符 | 可在表达式内部为变量赋值。` |

1.9 条件语句
- 条件语句是一种控制结构:通过分析变量的值从而做出相应的决定的代码块
- 条件语句的关键字:if、elif、else
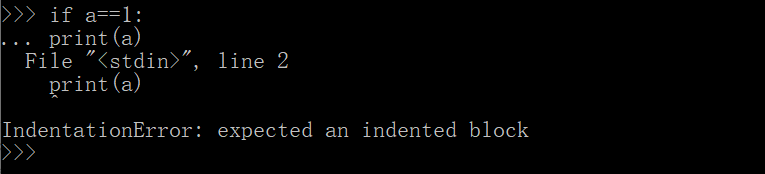
1.9.1 if 条件语句
- 如果满足条件就这样
if bool(conj):do something
-
以上伪代码(伪代码是用于解释说明示例代码的标记方法)中 bool(conj) 是一个判断条件,结果是 True 或者 False ,如果是 True ,就会执行 do something 这条语句,否则不返回任何值。

-
值得注意的是,if 语句之后的冒号 :必须要有,执行语句(do something 那行)前面需要缩进4个空格,一个Tab键,很多编译器会自动缩进,没有的话需要自己特别注意,否则会提示缩进错误
-
python中必须通过缩进的方法来表示语句块的开始和结束
1.9.2 if…else 语句
- 如果满足条件就这样,否则就那样
if 1>2 :print('True')
else:print('False')
- 注意冒号的使用,其实这里有两个判断语句 if 判断语句:如果条件是真的;else 判断语句:如果条件是假的
- 可以理解为有判断就有冒号
- print(‘True’) 和 print(‘False’) 都是需要执行的语块,所以需要缩进
1.9.3 if…elif…else 语句
- if…elif…else 基本样式结构如下
if 条件1:语块1
elif 条件2:语块2
elif 条件3:语块3
...
else:语块4
- if…elif…else 中间可跟多个elif
- 如果一个 if-else 语句中包含有 elif 语句,则首先判断 if 语句。如果该语句中的表达式为 True,则只执行其中的代码。但是,如果其值为 False,每个之后的 elif 语句都将进行求值。只要有一个 elif 语句中的表达式结果为 True,则执行其中的代码并退出。如果没有任何一个 elif 语句的结果为 True,则执行 else 语句中的代码。
- 要记得每个条件语句都需要冒号 :即,if、else、elif 后都需要冒号 :(英文冒号)
number=input('please enter a number:')
# input函数用于用户输入内容
number=int(number)
# input返回的结果都是字符串,需要用int函数把用户输入的内容转为数字类型
if number == 10 :print('this number is {}'.format(number))
elif number > 50 :print('this number is {}'.format(number))print('this number is more than 50')
elif number > 10 :print('this number is {}'.format(number))print('this number is more than 10')
else:print('this number is {}'.format(number))print('this number is less than 50')

1.9.4 三元操作符
- 三元操作是条件语句中比较简单的一种赋值方式,什么情况下变量等于这个值,否则变量就等于那个值。
A=Y if X else Z
- 如果 X是真的,执行 A=Y
- 如果 X是假的,执行 A=Z
x=2
y=4
a='python' if x>y else 'hello'
print(a)
b='python' if x<y else 'hello'
print(b)
1.10 挑战练习
- 请打印 3 个不同的字符串。
- 编写程序:如果变量的值小于 10,打印一条消息;如果大于或等于 10,则打印不同的消息。
- 编写程序:如果变量的值小于或等于 10,打印一条消息;如果大于 10 且小于或等于 25,则打印一条不同的消息;如果大于 25,则打印另一条不同的消息。
- 编写一个将两个变量相除,并打印余数的程序。
- 编写一个将两个变量相除,并打印商的程序。
- 编写程序:为变量 age 赋予一个整数值,根据不同的数值打印不同的字符串说明。
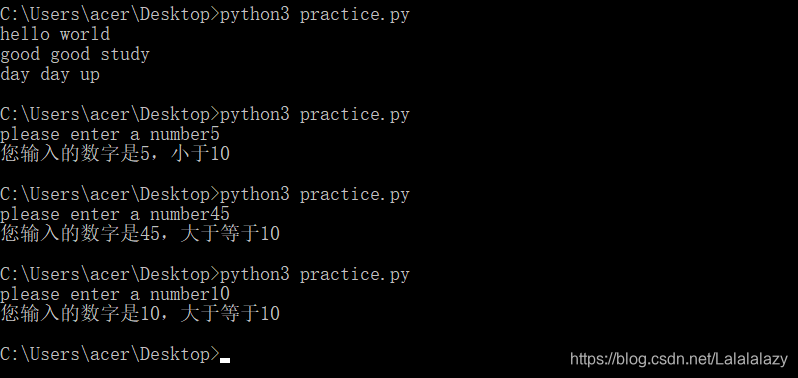
# 第一题
print('hello world')
print('good good study')
print('day day up')
# 第二题
num_1=int(input('please enter a number'))if num_1 < 10 :print('您输入的数字是{},小于10'.format(num_1))
else:print('您输入的数字是{},大于等于10'.format(num_1))
# 第三题
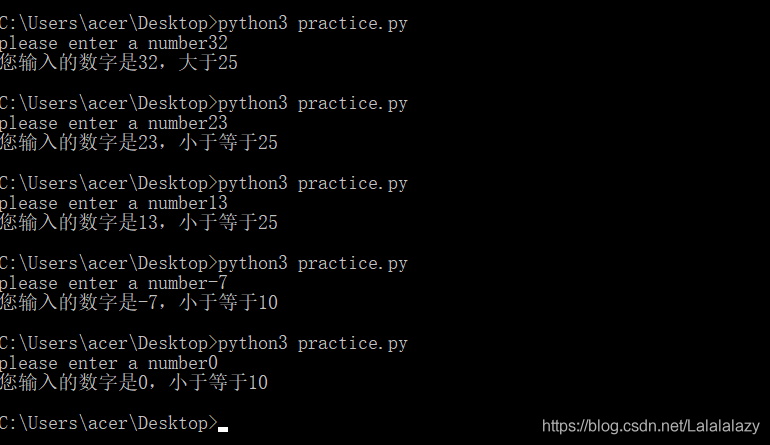
num_1=int(input('please enter a number'))if num_1 <= 10 :print('您输入的数字是{},小于等于10'.format(num_1))
elif num_1 <=25 :print('您输入的数字是{},小于等于25'.format(num_1))
else:print('您输入的数字是{},大于25'.format(num_1))
# 第四题,第五题
num_1=20
num_2=7
num_3=num_1%num_2
print(num_3)
num_4=num_1//num_2
print(num_4)
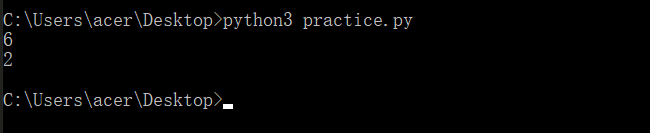
age=int(input("请输入你的年龄:"))if age<=0:print("请输入正确的年龄:")
elif age<=18:print("你的年龄是{},未成年".format(age))
elif age<=40:print("你的年龄是{},还年轻,继续拼搏".format(age))
elif age<=60:print("你的年龄是{},注意养生了吗".format(age))
else:print("你的年龄是{},祝您身体健康哦".format(age))
2. 基本对象类型
- 第1章中讲到,基本的数据类型有6种: Number(数字)、String(字符串)、List(列表)、Tuple(元组)、Set(集合)、Dictionary(字典),现在将详细对其进行讲解。
2.1 数字类型
- Python 数字数据类型用于存储数值。
- python的数字类型有四种:整数(int)、浮点数(float)、布尔型(bool)和复数(complex)。
- **注意:**在 Python2 中是没有布尔型的,它用数字 0 表示 False,用 1 表示 True。到 Python3 中,把 True 和 False 定义成关键字了,但它们的值还是 1 和 0,它们可以和数字相加。
- 通过变量赋值可直接创建数字类型
num_1=2
num_1=2.1
整型(Int)
- 通常被称为是整型或整数,是正或负整数,不带小数点。Python3 整型是没有限制大小的,可以当作 Long 类型使用,所以 Python3 没有 Python2 的 Long 类型。
浮点型(float) - 浮点型由整数部分与小数部分组成,浮点型也可以使用科学计数法表示(2.5e2 = 2.5 x 102 = 250)
复数( (complex)) - 复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型。
2.1.1 数字类型转换
- int(x) 将x转换为一个整数。
- float(x) 将x转换到一个浮点数。
- complex(x) 将x转换到一个复数,实数部分为 x,虚数部分为 0。
- complex(x, y) 将 x 和 y 转换到一个复数,实数部分为 x,虚数部分为 y。x 和 y 是数字表达式。
a=input('请输入一个数字:')
a=int(a)
b=float(a)

2.1.2 数字类型可以进行运算
- 其中,第1章中讲到的算法操作符,赋值操作符都可用在数字的运算上,这里就不重复了。
2.1.3 数字函数
| 函数 | 返回值 |
|---|---|
| abs(x) | 返回数字的绝对值,如abs(-10) 返回 10 |
| ceil(x) | 返回数字的上入整数,如math.ceil(4.1) 返回 5 |
| floor(x) | 返回数字的下舍整数,如math.floor(4.9)返回 4 |
| exp(x) | 返回e的x次幂(ex),如math.exp(1) 返回2.718281828459045 |
| fabs(x) | 返回数字的绝对值,如math.fabs(-10) 返回10.0 |
| log(x) | 如math.log(math.e)返回1.0,math.log(100,10)返回2.0 |
| log10(x) | 返回以10为基数的x的对数,如math.log10(100)返回 2.0 |
| max(x1, x2,…) | 返回给定参数的最大值,参数可以为序列。 |
| min(x1, x2,…) | 返回给定参数的最小值,参数可以为序列。 |
| pow(x, y) | x**y 运算后的值。 |
| round(x [,n]) | 返回浮点数 x 的四舍五入值,如给出 n 值,则代表舍入到小数 |
| sqrt(x) | 返回数字x的平方根。 |
2.1.4 随机数函数
- 随机数可以用于数学,游戏,安全等领域中,还经常被嵌入到算法中,用以提高算法效率,并提高程序的安全性。
| 函数 | 说明 |
|---|---|
| choice(seq) | 从序列的元素中随机挑选一个元素,比如random.choice(range(10)),从0到9中随机挑选一个整数。 |
| randrange ([start,] stop [,step]) | 从指定范围内,按指定基数递增的集合中获取一个随机数,基数默认值为 1 |
| random() | 随机生成下一个实数,它在[0,1)范围内。 |
| seed([x]) | 改变随机数生成器的种子seed。如果你不了解其原理,你不必特别去设定seed,Python会帮你选择seed。 |
| shuffle(lst) | 将序列的所有元素随机排序 |
| uniform(x, y) | 随机生成下一个实数,它在[x,y]范围内。 |
2.1.5 三角函数
| 函数 | 说明 |
|---|---|
| acos(x) | 返回x的反余弦弧度值。 |
| asin(x) | 返回x的反正弦弧度值。 |
| atan(x) | 返回x的反正切弧度值。 |
| atan2(y, x) | 返回给定的 X 及 Y 坐标值的反正切值。 |
| cos(x) | 返回x的弧度的余弦值。 |
| hypot(x, y) | 返回欧几里德范数 sqrt(xx + yy)。 |
| sin(x) | 返回的x弧度的正弦值。 |
| tan(x) | 返回x弧度的正切值。 |
| degrees(x) | 将弧度转换为角度,如degrees(math.pi/2) , 返回90.0 |
| radians(x) | 将角度转换为弧度 |
2.1.6 数字常量
| 常量 | 说明 |
|---|---|
| pi | 数学常量 pi(圆周率,一般以π来表示) |
| e | 数学常量 e,e即自然常数(自然常数)。 |
2.1.7 math
- 以上的某些函数介绍(如:math.ceil(4.1))使用了math
- math 是python的一个模块,模块相关内容后面章节会详细讲解,现在只是简单了解一下math模块
- math 模块可以直接使用,但需要用关键字 import 来将 math 引入当前环境。
# 以求圆周率为例子
import math
math.pi

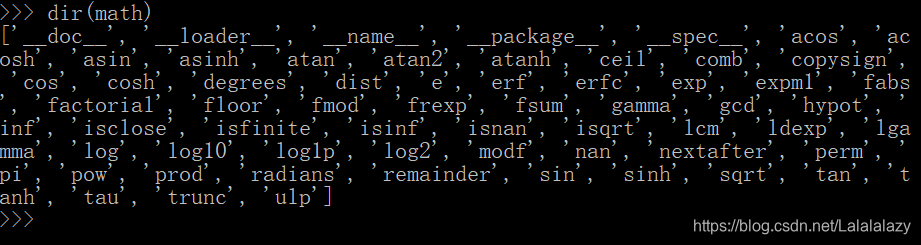
- 如果你想继续深入了解这个库还有哪些函数功能,可以使用内置函数 dir() 来查看
dir(math)
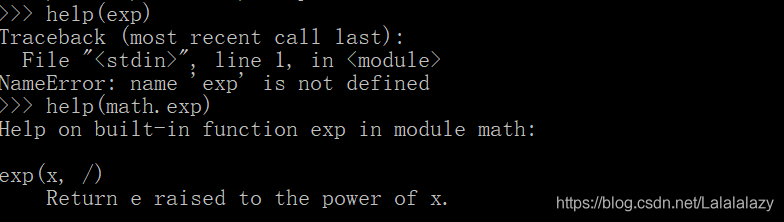
- 如果你想知道某个功能怎么用,可以使用内置函数 help()
- 使用help函数查询库的功能,不能直接把功能的名字放进括号里,还需把库的名字带上,比如 math.exp
help(math.exp)
2.2 字符串(str)
- 字符串是由0个或多个字符组成的有限的串行
- 字符串是 Python 中最常用的数据类型。我们可以使用引号( ’ 或 " )来创建字符串。
- 一个中文、一个英文、一个空格都属于字符串里的一个字符
- 可以使用 len() 函数来测量字符串的长度(字符的个数)
- 使用内置函数 type() 查看对象类型
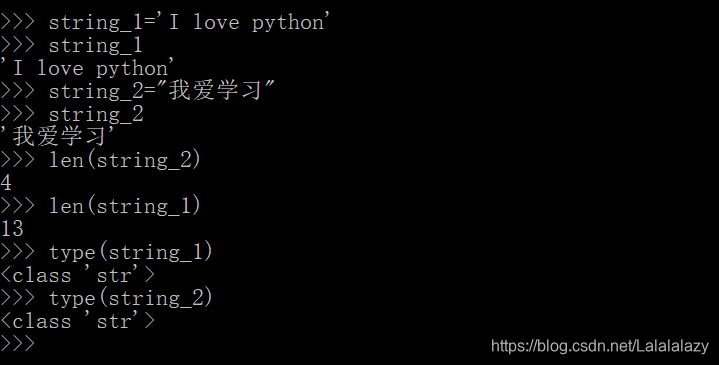
string_1='I love python'
string_2="我爱学习"
len(string_1)
len(string_2)
type(string_1)
- 字符串是不可变的,我们无法修改字符串中的字符,如果想要修改,只能创建一个新的字符串。
2.2.1 转义符 \
- 现在我想打印一句话:what’s your name?,你会怎么去执行呢?
- 是如下吗?这么简单,肯定有坑吧,先运行看看!
print('what's your name?')

-
果然呀!出现了语法错误,SyntaxError: invalid syntax
-
编写这段程序时,我们涉及三个单引号(一对半),python解析器是看不懂的,它会以为前面两个单引号才是一对,而后面单个单引号则会让python解析器的迷惑,因为语法上是不能出现单个引号的,于是python解析器报了个语法错误。
-
那么我们应该怎么解决这个问题呢?方法有二
方法一:双引号包裹单引号
print("what's your name?")

- 这样就能让python解析器好好地理解啦,先识别一对双引号,再把双引号的内容打印出来,对python解析器来说双引号里面的一切都是字符串
- 同样的,单引号里面也可以包裹双引号。

方法二:使用转义符
- 哈哈,终于讲到转义符了
- 所谓转义符,顾名思义,就是让某个具有特别意义的符号不再表示某个含义。
- python中,使用符号反斜杠 \ 作为转义符(其实很多语言都使用这个符号作为转义符,学习MySQL的时候也碰到了)
print("what\'s your name?")

以下介绍比较常用的转义类型
| 转义字符 | 说明 |
|---|---|
| \(在行尾时) | 续行符 |
| \\ | 转义反斜杠符号 |
| \’ | 转义单引号 |
| \" | 转义双引号 |
| \a | 响铃,执行后电脑会有提示音 |
| \b | 退格(Backspace) |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车,将 \r 后面的内容移到字符串开头,并逐一替换开头部分的字符,直至将 \r 后面的内容完全替换完成。 |
| \f | 换页 |
| \oyy | 八进制数,y 代表 0~7 的字符,例如:\012 代表换行。 |
| \xyy | 十六进制数,以 \x 开头,y 代表的字符,例如:\x0a 代表换行 |
| \other | 其它的字符以普通格式输出 |
例子
# 续行,第1章所提到的实现多行语句
print("line1 \
line2 \
line3")
line1 line2 line3
# 反斜杠print("\\")# 单引号print('\'')# 双引号print("\"")# 铃声,执行后电脑有响声。print("\a")# 退格print("Hello \b World!")#结果:Hello World!# 空,输出结果什么也没有print("\000")# 换行print("\n")# 纵向制表符print("Hello \v World!")# 横向制表符print("Hello \t World!")# 回车print("Hello\rWorld!")print("Hello who are you\rWorld!")# 换页print("Hello \f World!")
2.2.2 字符串的运算
- 数字类型有运算,字符串也有
- 先看看字符串的运算操作符吧,注意区别于数字的算术操作符。
| 操作符 | 说明 |
|---|---|
| + | 字符串连接 |
| * | 重复输出字符串 |
| [] | 通过索引获取字符串中的字符 |
| [:] | 截取字符串中的一部分,遵循左闭右开原则,str[0:2] 是不包含第 3 个字符的。 |
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True |
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True |
| r/R | 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母 r(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 |
a = "Hello"
b = "Python"
print("a + b 输出结果:", a + b)
print("a * 2 输出结果:", a * 2)
2.2.2.1 字符串的拼接
- 使用 + 操作符,把两个字符串拼接起来成为一个新的字符串
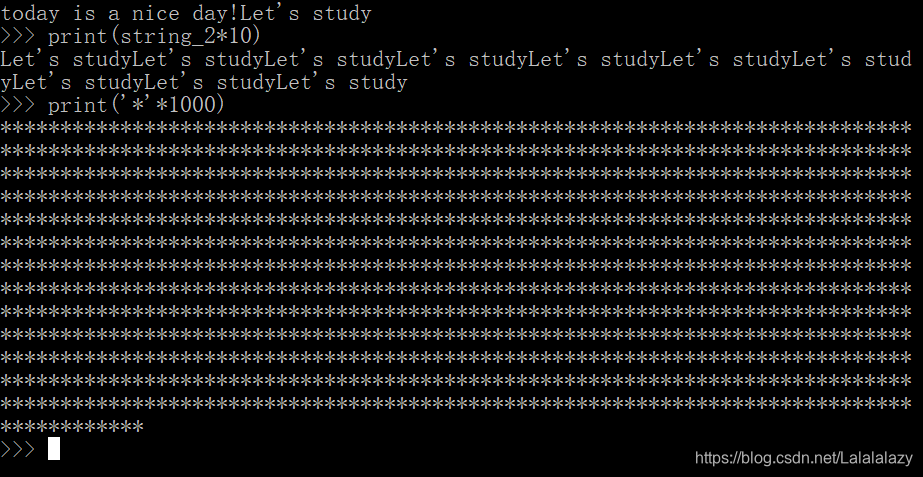
string_1='today is a nice day!'
string_2='Let\'s study'
print(string_1+string_2)

2.2.2.2 字符串的乘法 *
- 在字符串中使用乘法符号 * 代表的是重复
- 可使用乘法操作符,将字符串与数字相乘,表示重复多少次
print(string_2*10)
print('*'*1000)
2.2.2.3 原始字符串
- 字符串操作符 r 或者 R 使输出的字符串为原始字符串
- 那么什么是原始字符串呢?
- 字符串的每个字符都有本身的含义(原始含义),如果使用了转义符 \ ,其原始的含义就会发生转变,而 r 或者 R 的使用就是保证不发生转义,以原始字符串输出。

- 例子中 反斜杠 \ 和 n 的字面意思就是反斜杠 \ 和 n ,但当他们结合使用时,就发生了转义(转为换行的意思,python解析器把他们理解为换行),而使用了就让python解析器把他们理解为字符 \ 和 n ,原样输出。
- 会不会有些人觉得奇怪,我本来就是要换行,不需要原始字符串,那么 r 或者 R 存在的意义在哪呢?请看下例
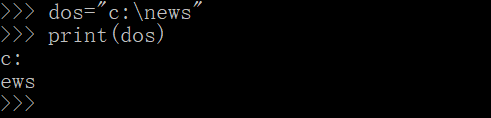

- 大哥,我想要个路径而已,你给我整成啥样啦!
- 别慌!

- 使用转义符不就好了吗

- 可是如果是下面这种路径呢?
dos="c:\new\study\python"
- 一个一个地去转,太烦了吧
- 咳咳,终于到 r / R上场了

- 由 r/R 开头引起的字符串,输出的就是原始字符串。
2.2.2.4 索引和切片
- 前面提到字符串是序列,所谓序列就是:有顺序的排列。
- 拿字符串
string = 'python'做例子 - string 就是由字符 p、y、t、h、o、n 有序地排列起来而组合成的字符串,当字符的顺序发生变化,就会成为一个新的字符串,这就是为啥字符串类型的对象不可变。
- python中把字符串有序排列的字符做了编号,叫做索引
- 那么python是怎么给字符串编号的呢?请看下例:
string='study python'
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| s | t | u | d | y | p | y | t | h | o | n | |
| -12 | -11 | -10 | -9 | -8 | -7 | -6 | -5 | -4 | -3 | -2 | -1 |
-
正索引: 从第1个字符开始到最后一个字符结束(从左到右编号),编号从0开始,以此类推,如上字符串“s”编号0,"t"编号1,……
-
负索引: 从倒数第一个字符开始到第一个字符结束(从右到左编号),编号从-1开始,以此类推,如上字符串“n“编号为-1,”o“编号为-2,……
-
值得注意的是: 空格也属于一个字符
-
那么索引有什么用呢?
-
通过索引我们可以找到该索引所对应的字符
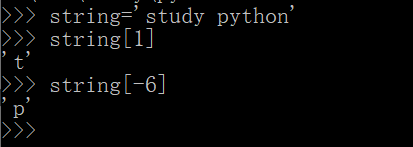
string='study python'
string[1]
string[-6]
# 上面介绍过,我们可以利用符号 [] 通过索引获取字符串中的字符
- 同样的,我们也可以根据字符知道索引,使用字符串的方法——index()
string.index('t')
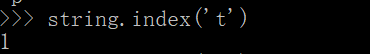
-
示例中有两个“t”,但结果只返回了正索引的第一个,找到就结束了程序。
-
了解了索引,是时候了解切片了
-
所谓切片是指通过索引对字符串进行全部或部分的截取,得到新的字符串,但不改变原来的字符串,这就是字符串切片。
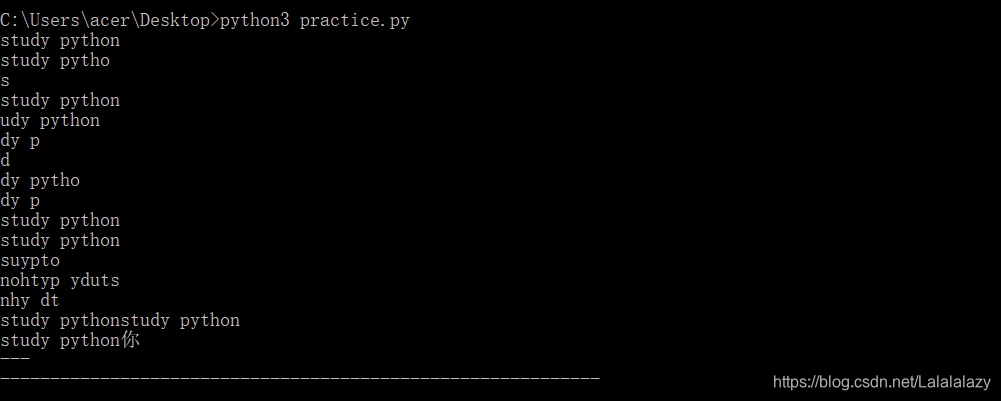
string='study python'
#输出字符串
print(string)
#输出第一个到倒数第二个的所有字符
print(string[0:-1])
#输出字符串第一个字符(左边开始数)
print(string[0])
#输出从第一个开始后的所有字符
print(string[0:])
#输出从第三个开始后的所有字符
print(string[2:])
#输出从第四个开始到第七个的字符,步长为1
print(string[3:7:1])
#输出从第四个开始到第七个的字符,步长为2
print(string[3:7:2])
#输出从第四个开始到倒数第一个的字符,默认步长为1
print(string[3:-1])
#输出从第四个开始到第七个的字符
print(string[3:7])
#截取字符串的全部范围
print(string[::])
#截取字符串的范围,步长为1
print(string[::1])
#截取字符串的范围,步长为2
print(string[::2])
#字符串翻转,步长为1
print(string[::-1])
#字符串翻转,步长为2
print(string[::-2])
#输出字符串两次
print(string*2)
#连接字符串
print(string+'你')
print('---')
print('---'*20)
2.2.2.5 成员运算符 in / not in
- 判断元素是否存在序列中
string='study python'
'p' in string
'study' in string
' ' in string
'u' not in string

2.2.2.6 字符串的最值和比较
- 字符串中的字符其实也有大小之分
- 在计算机中每个字符都通过编码对应着一个数字,它们都会有一个顺序
- 我们可以使用内置函数 ord() 得到一个字符所对应的数字编码
- 通过 min() 和 max() 函数获得字符串的最小值和最大值。

- 另外,我们还可以使用 chr() 函数得到一个字符所对应的数字编码
- 所以,两个字符串是可以进行大小比较的,你没有听错
- 两个字符串的比较,python解析器会先将字符串的字符转成对应编码的数字,然后再进行比较
# 单个字符比较
"a">"b"
"a"<"b"
"a"=="b"
# 字符串比较
"abc">"aaa"
"abc">"zc"
- 单个字符的比较可以理解,但是字符串又是怎么比较的呢?
- 以"abc">“aaa"为例,首先看两个字符串的第一个字符,比较谁大,大的则大,一样大就看第二个字符,所以"abc”>"aaa"返回结果为True
2.2.3 字符串的格式化输出(format 函数)
- python2.6 以前使用占位符 % 进行格式化输出,python2.6 以后引入了 format 方法并被提倡使用
- 那什么是格式化输出呢?
- 格式化输出是用于指定输出参数的格式与相对位置的字符串参数,通俗点来讲就是我需要输出的这个字符串的某个位置要指定是我想要输出的参数。
使用占位符 %
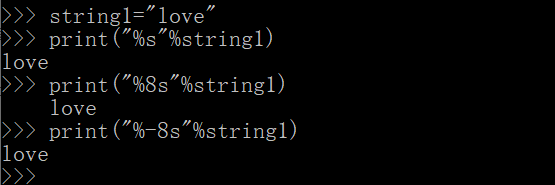
- %s 输出一个字符串
- %ws 输出一个字符串,w指格式化输出的字符串宽度,如w>0输出字符串右对齐,w<0输出字符串左对齐,如果w宽度小于实际字符串的占位数,则会按实际的宽度输出。
string1="love"
print("%s"%string1)
print("%8s"%string1)
print("%-8s"%string1)
使用 format() 方法
- format是字符串中的一个方法,表达式为 str.format()
- 如果你对 format() 方法很陌生,还是建议使用内置函数 help() 查看一下其用法用途


-
英文不好还可以找翻译
-
S.format(*args, **kwargs) 括号里是方法的参数,参数的形式有 *args 和 **kwargs 两种
-
*args 表示传入的参数形如(“python”,“Java”),这个很好理解,就是传入两个普通的对象——字符串,当然也可以是数字类型等,后面再讲。
-
**kwargs 表示出入的参数形如 (hot=“python”,normal=“java”),这个对我们小白来说可能有点难理解,都不知道是什么来的,其实这是一种“字典“类型的格式化输出,先把它记住,后面学习字典再来

-
下面进入示例
"I'am a {0} and I like {1}".format("green hand","python")

- {}是占位符,在这里 {0} 和 {1} 占了两个位置
- S.format(*args, **kwargs) 其中S 是对象(双引号里面的内容),S 后面的圆点 . 是引出对象的属性或方法的工具,必须要有
- format(“green hand”,“python”) 传入了需要格式化输出的两个参数,分别用双引号括了起来,分别对应着 “I’am a {0} and I like {1}” 中的那两个占位符,第一个占位符 {0} 会传入 format 的第一个参数 “green hand” ,第二个占位符 {1} 会传入 format 的第二个参数 “python”。
"I'am a {1} and I like {0}".format("python","green hand")

- 花括号{} 里面的数字是位置参数,与 format 括号后面的参数位置是对应的, format 括号后面的第一个参数对应着花括号 {} 的位置参数是0 (即:{0}),format 括号后面的第二个参数对应着花括号 {} 的位置参数是1 (即:{1}),以此类推。
- 另外,花括号还可以指定一些格式,让输出的结果符合指定的样式。
- 下面以例子说话。
"I'am a {0:15} and I like {1:>15}".format("green hand","python")

- 这里我们可以把注意力集中在花括号上 {0:15} 和 {1:>15} 较 {0} 和 {1} 多了 冒号(:)、数字(15)和(>)它们的作用分别是什么呢?
- 冒号(:)的作用主要是把位置参数与格式化要求隔离起来, 冒号(:)前是位置参数,位置参数作用前面已讲过, 冒号(:)后面是格式化要求。
- 数字(15)是指我需要输出的参数的格式是15个字符,如果 format 后面提供的对应参数的字符串长度比格式化要求的字符长度长,则会按照 format 后面提供的对应参数的字符串长度输出。
- 符号(>)是指右对齐,与此字符有类似功能的还有(<,左对齐)、(^,居中),当然字符的输出本来就默认是左对齐,所以左对齐的符号没必要使用。
- 所以上例中,{0:15} 传入 format 括号后面的第一个参数,字符长度为15,左对齐
- {1:>15} 传入 format 括号后面的第二个参数,字符长度为15,右对齐

- 此例说明如果 format 后面提供的对应参数的字符串长度比格式化要求的字符长度长,则会按照 format 后面提供的对应参数的字符串长度输出。以及说明了居中对齐。
- {0:5} 要求输出的字符长度是5,可 “green hand” 的字符长度大于5,所以原样输出。
- {1:^15} 要求居中对齐,所以 “python” 的输出占用了15个字符长度,并实现了居中对齐。
- 另外,如果冒号(:)后面没有字符长度的要求,格式化参数也会原样输出。
- 请继续看例子:
"I'am a {0:.2} and I like {1:^10.4}".format("green hand","python")

-
这里又多了点东西——小圆点(.)
-
{0:.2} 中冒号与小圆点之间没有数字,即没有字符的长度要求;{1:^10.4} 中冒号与小圆点之间有(^10),意思是字符串长度为10,对应的参数输出应该是居中对齐,查看结果确实是居中
-
好,那么小圆点是啥意思呢?
-
对字符串的格式化输出来说,小圆点表示字符串的截取,小圆点后面的数字表示字符串截取的长度。
-
(.2)是指对字符串进行2个字符的截取,所以格式化输出的结果是(gr)
-
(.4)是对字符串截取4个字符,所以输出内容是(pyth),居中对齐
-
它们都是从第一个字符进行截取的。
-
format 方法不仅可以传入字符串,也可以传入数字(包括整型和浮点型),而且都可以有一定的格式花样。请看例子!
"She is {0:4d} years old and she is {1:f}m tall".format(14,1.632415)

- 这里,d 代表的是整数, f 代表 浮点数,当花括号填了 d 或 f 后面的 format 参数必须输入相应的数据类型,否则有可能出错,之所以是有可能,是因为某些情况可以强制性转化为整数或浮点数。
- 这里的数字4依然表示字符长度,只是默认的输出格式不再是字符串的左对齐,而是格式化数字类型时默认为右对齐,此点必须注意区分。
"She is {0:4d} years old and she is {1:6.2f}m tall".format(14,1.632415)

- 以上对浮点数进行了某些格式化要求。
- {1:6.2f} 冒号前数字是位置参数1,对应格式化内容是 format 传入的第二个参数;冒号后面的6是指格式化输出字符长度要求为6,默认右对齐;这个小圆点跟字符串的小圆点不一样,浮点数的格式化要求——小圆点是指保留的小数是几位,这里是指保留两位小数(四舍五入)。
- 继续看例!
"She is {0:04d} years old and she is {1:06.2f}m tall".format(14,1.632415)

-
设置长度要求前多了个0,意思是在数字前面,如果位数不够,用0填充。
-
讲了这么多,还是有点疲惫呀!总结一下format这一块,参数的形式 args 和 **kwargs 只是了解了args部分,还有 **kwargs 部分没了解,未来有期!
2.2.4 常用的字符串方法
- 说到字符串的方法,我们可以使用 dir() 内置函数,看看字符串都有哪些方法
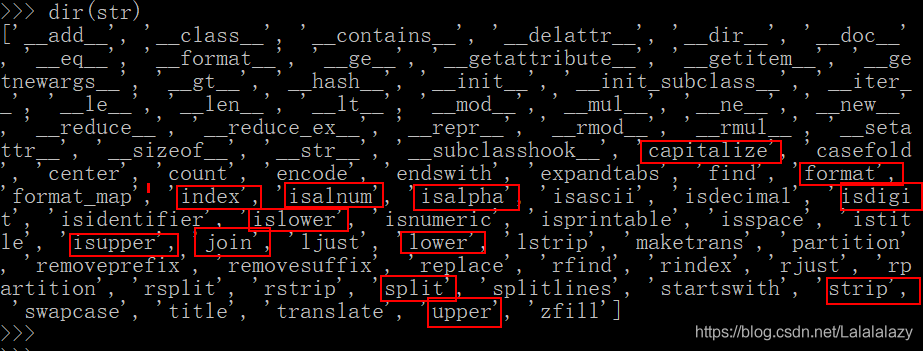
- 如果不了解对应的方法的用途用法,老样子,使用 help() 内置函数,但要记得查找某个对象类型的方法,要使用对象类型导出方法的形式,比如:
help(str.capitalize)

2.2.4.1 字符大小写的转换
- 上面查找的字符串的方法,有些是用来实现各种类型的大小写转换。如下:
| 方法 | 用途 |
|---|---|
| str.upper | 将字符串的字母全转成大写 |
| str.lower | 将字符串的字母全转成小写 |
| str.capitalize | 将首字母转换为大写 |
| str.title | 将字符串中所有单词的首字母大写,而其他字母小写 |
| str.isupper | 判断字符串的字母是否全部是大写 |
| str.islower | 判断字符串字母是否全部都是小写 |
| str.istitle | 判断字符串是否标题模式,即字符串中所有单词的首字母是大写,而其他字母是小写 |
- 字符串的方法中 is-开头的方法几乎都是判断类型的方法,返回结果是布尔型
- 以上对字符串的大小写转换的方法会生成一个新的字符串,不会改变原来的字符串。
- 在你想要得到某个字符串的大写或小写时,可以创建新的变量来赋值,比如:
string0=string.upper()
- 之前的例子我们已经给变量 string 赋值了
string="study python" - 要注意方法的使用,需要转换的对象(string)接个小圆点(.)然后使用方法名,方法名后带括号
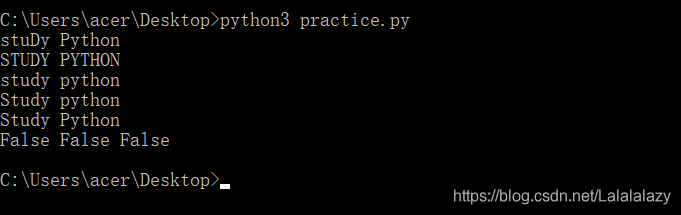
string="stuDy Python"
string0=string.upper()
string1=string.lower()
string2=string.capitalize()
string3=string.title()
print(string,\n,string0,\n,string1,\n,string2,\n,string3)a=string.isupper()
b=string0.islower()
c=string2.istitle()
print(a,b,c)
2.2.4.2 字符串的判断方法
- 上面接触了字符串的几个判断方法,接着再介绍几个常用的判断方法,其他的有兴趣可使用内置函数 help() 自行了解
- 判断方法返回结果皆为布尔型
| 判断方法 | 用途 |
|---|---|
| str.isalnum | 判断字符串是否全部由字母和数字组成 |
| str.isalpha | 判断字符串是否全部由字母组成 |
| str.isdigit | 判断字符串是否全部由数字组成 |
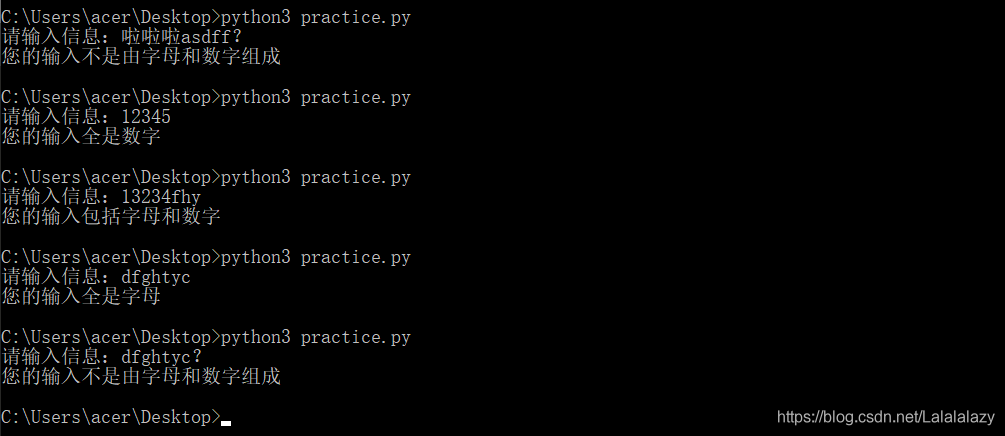
- 例子,判断用户输入的信息属于什么类型
user_input=input("请输入信息:")if user_input.isalpha():print("您的输入全是字母")
elif user_input.isdigit():print("您的输入全是数字")
elif user_input.isalnum():print("您的输入包括字母和数字")
else:print("您的输入不是由字母和数字组成")
2.2.4.3 字符串的分割 split() 方法
- 总的来说,字符串的 split() 方法是通过指定分隔符sep对字符串进行分割,并返回分割后的字符串列表。
- split() 方法返回的是一个列表!
- 先对 split(self, /, sep=None, maxsplit=-1) 进行个语法解释:
- self, / 是可以输入你想分割的字符串,也可以不用输入你想分割的字符串,这是 split 方法的两种不同的使用方式,下面会用例子解释。
- sep=None 分隔符默认为 None ,即当你不设置分隔符时会默认以 None 来对字符串进行分割,而 None 的意思是:以空格分割,这是默认的。
- maxsplit=-1 最大分割参数,默认参数为-1
- 所谓最大分割参数,就是你想把字符串分割多少次的意思,默认为-1,还记得讲到索引时,-1是指字符串的最后一个字符,同比,这里的-1是指分割到最后,只要能分割的就分割。这是默认的,当然你可以自己设置你想分割几次,下面用例子说话。
string="I love python and I will study python with my heart."
a=str.split(string)

- 以上例子就是把需要分割的字符串放在 split 的括号里面,以默认的分割方式(分隔符为字符串的空格符,分割到最后)进行分割,返回一个列表,这里列表还未总结,可以先有个概念,列表就是用 [] 来盛放元素,元素之间用逗号隔离。
- 其实我们也没必要把字符串放在括号里面,请看下面的用法:
string="I love python and I will study python with my heart."
a=string.split()

- 直接使用需要分割的字符串导出 split 方法
- 这里也是默认的分割方式
- 下面看看怎么去设置我想要的分割方式
string="I love python and I will study python with my heart."
a=string.split()
b=string.split(" ") # 直接设置空格为分隔符,默认分割到最后
c=string.split("and") # 以 and 进行分割字符串,默认分割到最后
d=string.split(" ",4) # 以空格分割字符串,分割4次,得到5个元素
- split 方法的使用技巧远不及此,有兴趣的可自行探索
2.2.4.4 去除空格
| 去除空格方法 | 用途 |
|---|---|
| str.strip() | 去除字符串左右两边空格 |
| str.lstrip() | 去除字符串左边空格 |
| str.rstrip() | 去除字符串右边空格 |
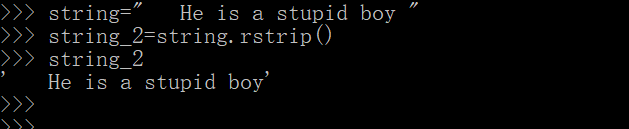
string=" He is a stupid boy "
string_0=string.strip()
string_1=string.lstrip()
string_2=string.rstrip()
print(string)
print(string_0)
print(string_1)
print(string_2)
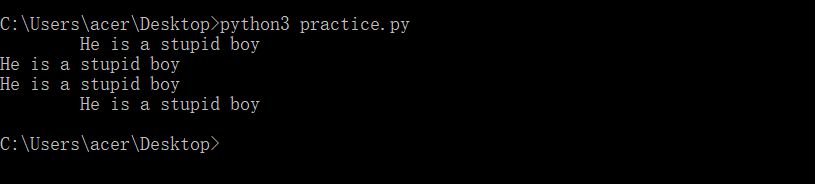
- 这里去除右边空格并不是很明显,看下例吧
2.2.4.5 拼接字符串 join() 方法

- join(self, iterable, /) 的意思是,join 方法的参数要求是一个可迭代的对象
- iterable 可迭代的
- 可迭代的对象有:字符串、元祖、列表(元祖、列表后面都会讲到)
- join() 会将可迭代对象的元素以指定的字符(分隔符)拼接起来并生成一个新的字符串,不改变原来的对象。
- 语法: ‘sep’.join(self, iterable, /) , sep 是你想设置的拼接的分隔符,用引号括起来;self, iterable, / 指的是可迭代的对象,千万不要误以为这里可以输入两个参数,它只是告诉你:参数,可迭代的。
- str.join() 只接受一个参数
拼接字符串
string="I love python"
"".join(string) # 不设置分隔符,默认不用分割,直接拼接各个元素并输出
" ".join(string) # 设置分隔符为一个空格,可迭代对象的每个元素会以空格连接起来组成一个新的字符串输出
".".join(string) # 设置分隔符为一个小圆点 . ,可迭代对象的每个元素会以小圆点 . 连接起来组成一个新的字符串输出
"!".join(string) # 设置分隔符为 !

拼接元祖
- 元祖的相关内容这里还未讲到,大家可以先有个概念,元祖是使用圆括号 () 把元素装起来的一个可迭代的对象,元素之间用逗号分隔,比如:
tu=(1,2,3,4,"haha","la",9);如果元祖只有一个元素,后面也要跟个逗号:tu_1=("haha",).
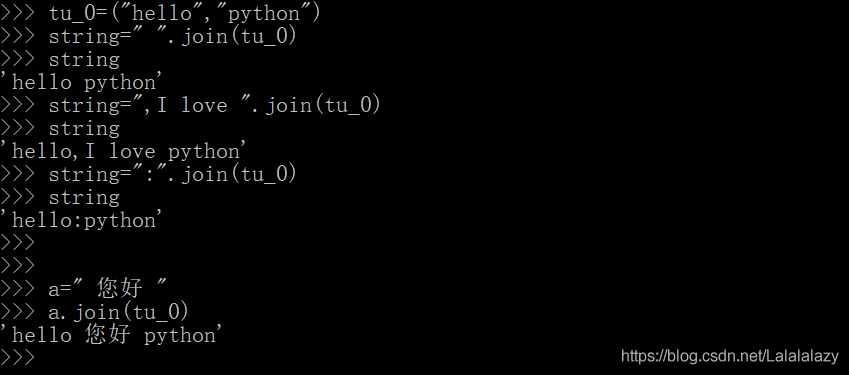
tu_0=("hello","python") # 创建元祖
string=" ".join(tu_0) # 以空格将元祖的元素拼接起来组成一个新的字符串,并赋给变量 string
string=",I love ".join(tu_0) # 把分隔符设置成一个字符串(其实分隔符本身就是字符串)将元祖的元素拼接输出
string=":".join(tu_0) # 分隔符为 :a=" 您好 "
a.join(tu_0)
拼接列表
- 上面讲到分割字符串的时候使用 split() 可以把字符串的元素以一定的方式分割,并返回一个列表
- 列表是使用 [] 把元素盛装起来,元素之间使用逗号分隔的一个可迭代的对象,其对象类型是列表
- 下面看看我们可以怎样对列表进行拼接。
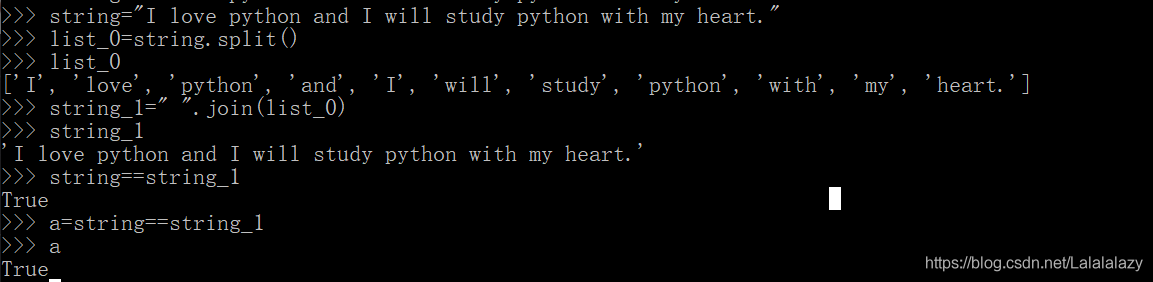
string="I love python and I will study python with my heart." # 创建字符串
list_0=string.split() # 分割字符串
print(list_0)
string_1=" ".join(list_0) # 拼接字符串
print(string_1)
a=string==string_1 # 判断原字符串与新建的字符串是否一样
2.2.4.6 替换 replace()

- 语法:str.replace(self, old, new, count=-1, /)
- self 是传入对象,即需要进行替换的字符串;
- old 是指需要被替换的部分,可以是某个字符,也可以是某几个字符;
- new 是指需要换进来的东西,可以是某个或某几个字符组成的字符串。
- count=-1 如果字符串需要被替换的部分出现多次,我们可以使用这个参数设置我替换几次,顺序从左到右。默认为全部替换。注意,这里并没有说是第几次被替换。
# 按照语法 str.replace(self, old, new, count=-1, /)
string="I love python and I will study python with my heart."
new_string=str.replace(string,"I","小七黛")
new_string_1=str.replace(string,"I","小七黛",1)#替换1次
- 返回结果为

- 其实我们可以使用另一种语法
self.replace(old, new, count=-1, /)
string="I love python and I will study python with my heart."
new_string=string.replace("I","小七黛")
new_string_1=string.replace("I","小七黛",2)
new_string=string.replace("my"," ")
new_string=string.replace(" "," ")
- 字符串的方法还有很多,可自行探索
2.2.5 字符串挑战练习
- 打印字符串"Camus"中的所有字符
- 编写程序,从用户处获取两个字符串,将其插入字符串"Yesterday I wrote a [用户输入 1]. I sent it to [用户输入 2]!"中,并打印新字符串。
- 想办法将字符串"aldous Huxley was born in 1894."的第一个字符大写,从而使语法正确。
- 对字符串"Where now? Who now? When now?"调用一个方法,返回如下述的列表[“Where now?”, “Who now?”, “When now?”]。
- 对列表[“The”, “fox”, “jumped”, “over”, “the”, “fence”, “.”] 进行处理,将其变成一个语法正确的字符串。每个单词间以空格符分隔,但是单词fence 和句号之间不能有空格符。(别忘了,我们之前已经学过将字符串列表连接为单个字符串的方法。)
- 将字符串"A screaming comes across the sky."中所有的"s"字符替换为美元符号。
- 找到字符串"Hemingway"中字符"m"所在的第一个索引。
- 在你最喜欢的书中找一段对话,将其变成一个字符串。
- 先后使用字符串拼接和字符串乘法,创建字符串"three three three"。
- 对字符串"It was bright cold day in April, and the clocks were striking thirteen."进行切片,只保留逗号之前的字符。
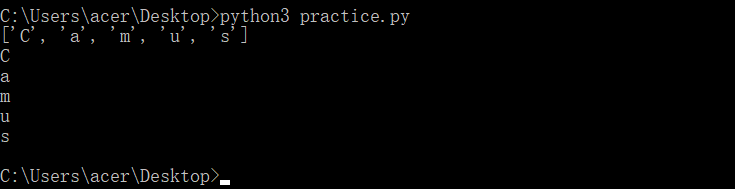
# 第一题
string_1="Camus"
string_2=" ".join(string_1) #添加分隔符
list_1=string_2.split() # 进行分割字符串
print(list_1) # 得到的列表就是字符串的所有字母
# 如果想把字符串的字符一个一个的打印,可使用遍历
for i in string_1:print(i)
# 第二题
user_enter_1=input("Please enter what you wrote yesterday:")
user_enter_2=input("Please enter the person you contated yesterday:")
print("Yesterday I wrote a {0}. I sent it to {1}"\.format(user_enter_1,user_enter_2))

# 第三题
string_3="aldous Huxley was born in 1894."
string_3=string_3.capitalize()
print(string_3)
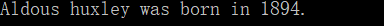
# 第四题
string_4="Where now? Who now? When now?"
string_4=string_4.replace("?","??",2)
string_4=string_4.split("? ")
print(string_4)

# 第五题
list_5=["The", "fox", "jumped", "over", "the", "fence", "."]
string_5=" ".join(list_5)
string_5=string_5.replace(" .",".")
print(string_5)

# 第六题
string_6="A screaming comes across the sky."
string_6=string_6.replace("s","$")
print(string_6)

'''
第七题
找到字符串"Hemingway"中字符"m"所在的第一个索引。
以上的字符串方法中,我并没有提过寻找索引的方法,
但既然题目都说了这是字符串的方法,那可以先调用字符串的库查看一下有关索引的方法
然后根据内置函数 help() 查看用途用法
'''
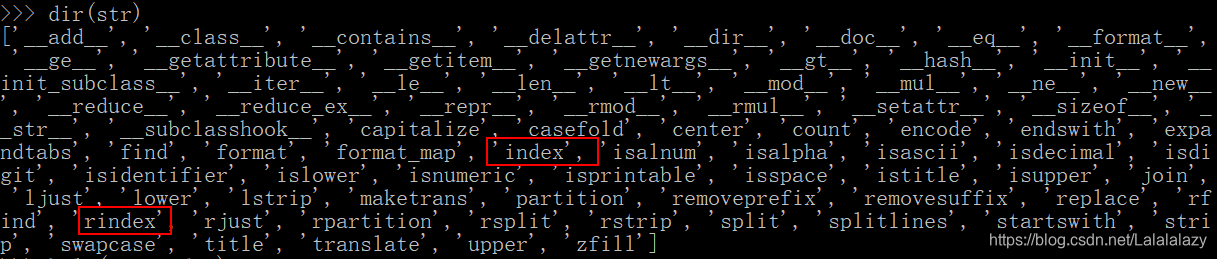
- 通过字符串的方法库,我们可以看到有关索引的两个方法 index 、rindex
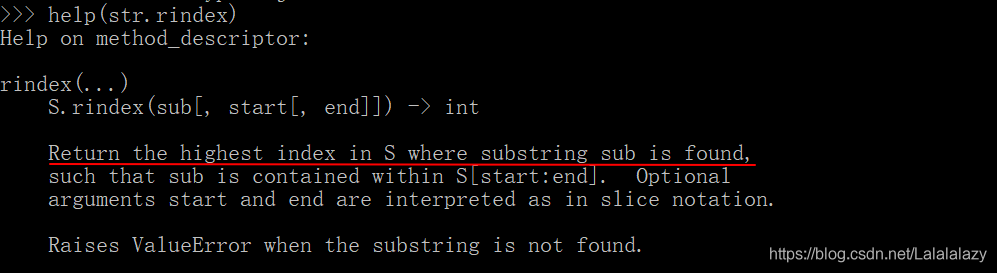
- 至于怎么用,还是使用 help() 吧

| 索引 | 说明 |
|---|---|
| S.index(sub[, start[, end]]) -> | 查找的是最低的那个索引 |
| S.rindex(sub[, start[, end]]) -> int | 查找的是最高的那个索引 |
- S是方法的对象,sub是指你想要找索引的字符,int 指返回整数;
# 第七题
"Hemingway".index("m")

# 第八题
print\
('''
a说:“如果你不违背我,你要什么我就能给你什么,你要什么都可以,把你的心给我吧”
b说:“我甚至连他的一张照片都没有,他只活在我的记忆里”
经典:一个人一生可以爱上很多人,等你获得真正属于你的幸福以后,
你就会明白以前的伤痛其实是一种财富,它让你更好的把握和珍惜你爱的人''')

# 第八题
string_8="three"
string_8=(string_8+" ")*2+string_8
print(string_8)

# 第九题
string_9="It was bright cold day in April, \
and the clocks were striking thirteen."
a=string_9.index(",")
string_9=string_9[:a]
print(string_9)

2.3 列表 list
- 写在前面:列表在python中具有非常强大的功能
2.3.1 定义
- 列表是使用方括号 [] 把元素盛装起来,元素之间使用逗号分隔的一个可迭代的对象。
- 列表是以固定的顺序保存对象的容器。
- 一会说列表是对象,一会说列表是容器,会不会很懵?
- 就好比如说书桌与电脑,都是物品,但物品的类型不同,而电脑可以放在书桌上,书桌就相当于一个容器了,而这个容器不仅仅可以盛放电脑,还可以放书本,水杯,手机等等各种物品。相同的,列表是python的对象,类型是列表,对象还有很多类型,包括数字、字符串、元祖、字典、集合等等,而之所以说列表是容器,是因为在列表里可以存放各种类型的对象,放在列表里的对象相对列表来说是组成列表的元素,元素可以是各种类型的对象:数字、字符串、元祖、甚至是列表本身都可以。
- 元素以固定的顺序保存在列表中,元素之间用逗号分隔。
- 创建列表可以有两种方法:方法一,使用 list() 函数创建空列表;方法二,直接使用方括号创建列表,这种方法可以创建空列表,也可以直接创建一个包含一定对象的列表,即把你希望放在列表的对象填入方括号中,用逗号分隔。
lst_1=list()
lst_2=[]
lst_3=[2021,"小七黛","女","Amethyst bead",[1,2,3,4],True,False,60] #列表存放了数字、字符串、布尔型、列表
type(lst_1)
type(lst_2)
type(lst_3)
# 使用type() 查看对象类型

- 我们还可以使用布尔函数 bool() 来判断列表是不是含有元素的列表,当列表为空返回 False ,非空列表则返回 True
bool(lst_1)
bool(lst_2)
bool(lst_3)

2.3.2 索引和切片
- 字符串、列表和元组都是可迭代的对象,它们是序列,序列中的每个值都有对应的位置值,称之为索引。
- 回顾一下字符串的索引,正索引从左到右,从0开始;负索引从右到左,从-1开始。这套规则放在列表中同样适用
- 列表中的索引和切片,与字符串都是一样的,可以把字符串那块理论直接搬过来使用。
string_0="python" # 创建字符串
lst_0=["python",20,"study",9.9] # 创建列表
string_0[0] # 取字符串索引为0的元素
lst_0[0] # 取列表索引为0的元素
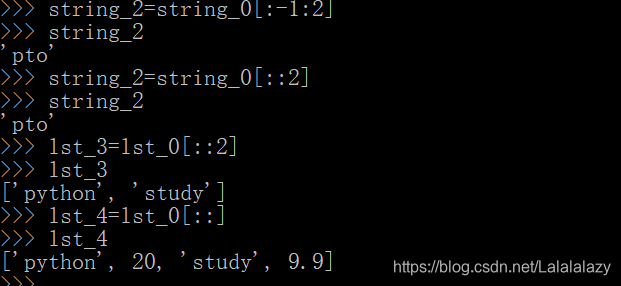
- 切片语法:sep[start🔚step] start 是开始的索引,如果为空,默认从第一个元素开始,end 是结束的索引,如果为空,默认到结尾结束,step 是步长,如果为空,默认步长为 1
string_0="python" # 创建字符串
lst_0=["python",20,"study",9.9] # 创建列表
string_1=string_0[:]
lst_1=lst_0[2:4]
lst_2=lst_0[2:3]
lst_3=lst_0[::2]
lst_4=lst_0[::]
2.3.3 反转
- 切片还有一个特殊的功能,就是把序列反转,返回跟原来完全相反的顺序结果
string_0="python" # 创建字符串
lst_0=["python",20,"study",9.9] # 创建列表
string_1=string_0[::-1]
lst_1=lst_0[::-1]
- 依然是切片的套路,步长-1,告诉 python 解析器,需要从右向左看这个对象,按照步长1取列表中的元素。
- 切片生成的对象都是新的对象,不会改变原来的对象。
补充:reversed() 反转函数
- reversed() 函数从指定的sequence参数(序列对象)中返回反向迭代器。返回的对象是reversed类型,它是一个迭代器。
- reversed类型的对象,目前为止第一次碰到,先保留个印象,有个概念。
- 在经过reversed()的作用之后,返回的是一个把序列值经过反转之后的迭代器,所以,需要通过遍历,使用 List()函数,或者 next() 等方法,获取作用后的值;
string_0="python" # 创建字符串
lst_0=["python",20,"study",9.9] # 创建列表
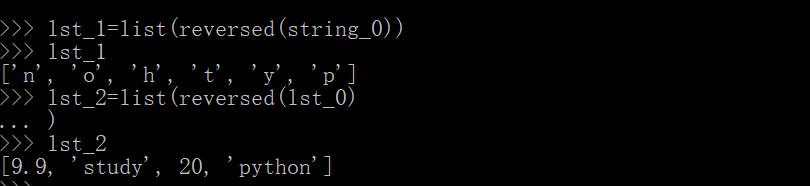
lst_1=list(reversed(string_0)) # 反转字符串,并把逐个元素存放在lst_1列表中
lst_2=list(reversed(lst_0)) # 反转列表
2.3.4 列表的基本方法

2.3.4.1 reverse()
- 先看不带双横线的,几乎都是常用的。
- 先看 reverse ,因为这跟刚刚介绍的反转函数很像。
- 使用 help(list.reverse)
- reverse(self, /)
- Reverse IN PLACE.
- 此函数没有返回值,而是原地将列表反序
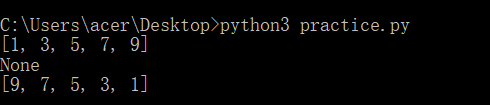
lst_1=[1,3,5,7,9]
print(lst_1)
a=lst_1.reverse()
print(a)
print(lst_1)
- 注意区别于 reversed() 函数, reversed() 函数属于python的内置函数,而 reverse() 只是列表的一个方法。
lst_1=[1,3,5,7,9]
b=reversed(lst_1)
print(lst_1)
print(b)
print(list(b))

| 函数 | 共同点 | 区别 |
|---|---|---|
| reversed() | 反序 | 内置函数,返回迭代器类型的对象,需要使用list()函数转换输出,不改变原列表 |
| list.reverse() | 反序 | 列表的一个方法,返回值为None,改变原列表 |
2.3.4.2 append 和 extend
| 方法 | 说明 |
|---|---|
| L.append() | 在列表最后追加一个元素,每次一个!改变原列表 |
| L.extend() | 在列表的最后扩容,extend传入可迭代对象,并把可迭代对象的元素逐个追加到列表中,改变原列表,不改变传入对象 |
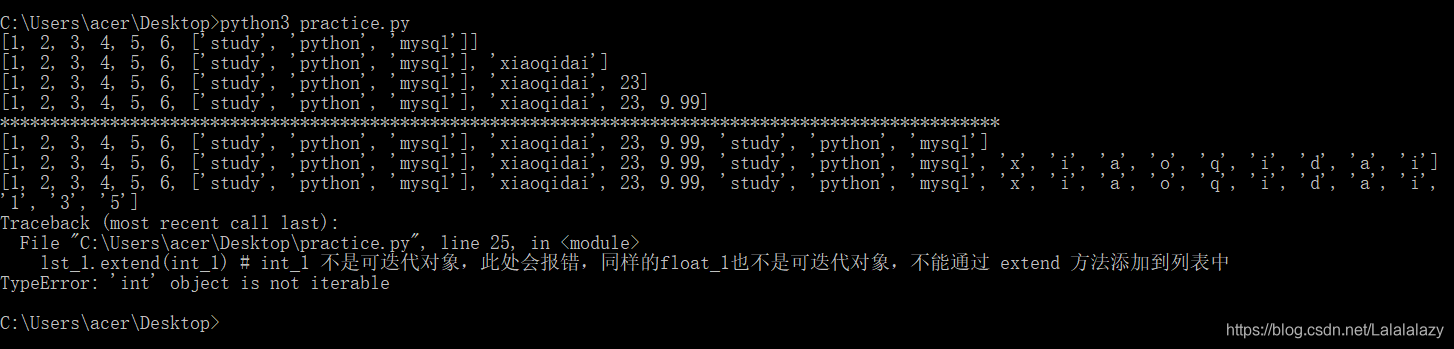
lst_1=[1,2,3,4,5,6]
lst_2=["study","python","mysql"]
string_1="xiaoqidai"
string_2="135"
int_1=23
float_1=9.99# 使用 append
lst_1.append(lst_2) # 把对象 lst_2 追加到列表 lst_1 中
print(lst_1)
lst_1.append(string_1) # 把对象 string_1 追加到列表 lst_1 中
print(lst_1)
lst_1.append(int_1) # 把对象 int_1 追加到列表 lst_1 中
print(lst_1)
lst_1.append(float_1) # 把对象 float_1 追加到列表 lst_1 中
print(lst_1)
print("*"*100)
# 使用 extend
lst_1.extend(lst_2) # 把列表 lst_2 中的元素全都添加到列表 lst_1 中
print(lst_1)
lst_1.extend(string_1) # 把列表 string_1 中的元素全都添加到列表 lst_1 中
print(lst_1)
lst_1.extend(string_2) # 把列表 string_2 中的元素全都添加到列表 lst_1
print(lst_1)
lst_1.extend(int_1) # int_1 不是可迭代对象,此处会报错,同样的float_1也不是可迭代对象,不能通过 extend 方法添加到列表中
print(lst_1)
2.3.4.3 count
字符串方法 count
- 想起字符串也有这个方法 count ,按字面意思就是计数,那是统计什么数,怎样计数的呢?
- 先看看字符串的 count ,
help(str.count) - S.count(sub[, start[, end]]) -> int
- Return the number of non-overlapping occurrences of substring sub in string S[start:end]. Optional arguments start and end are interpreted as in slice notation.
- 大概意思就是:返回子字符串sub在字符串S中不重叠的出现次数,也就是统计对象sub在字符串中出现了多少次,返回次数(整型),[start:end] 是可选参数,就是可以通过[start:end] 截取某个片段统计某个元素出现了多少次,如果不设置[start:end] ,则默认在整个字符串中统计某个元素出现的次数。
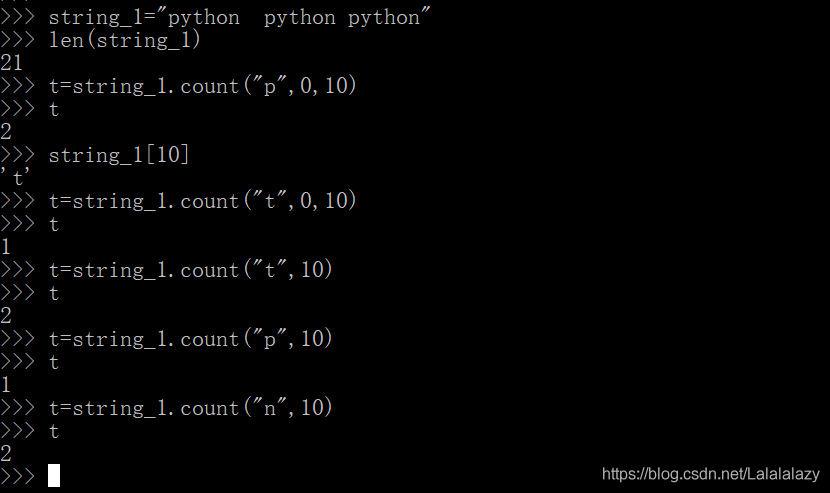
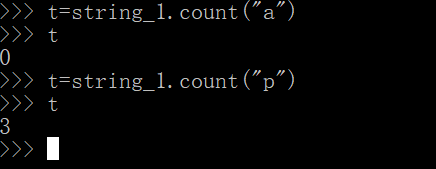
string_1="python python python"
len(string_1) # 计算字符串的字符长度,以估算截取片段的位置
t=string_1.count("p",0,10) #从字符串的索引为0的位置开始,到索引为10的位置结束,统计p 出现的次数
string_1[10] # 查看 索引为10的位置是哪个字符,大概就知道索引为10是中间python的那个 t 了
t=string_1.count("t",0,10) #从字符串的索引为0的位置开始,到索引为10的位置结束,统计 t 出现的次数,如果是1次,那就是左开右闭原则,即,截取的片段开始位置包括 0 ,结束位置不包括10
t=string_1.count("t",10) # 当后面只给出一个参数的时候,默认为这是截取字符串开始的位置,一直到最后才结束
t=string_1.count("p",10)
t=string_1.count("n",10)
列表方法 count
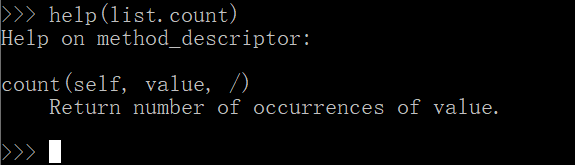
- count(self, value, /)
- Return number of occurrences of value.
- 跟字符串的方法有点不同,后面并没有可选的截取片段的统计了,这里的意思是统计传入对象在列表中出现的次数(值)
lst_1=string_1.split() # 利用字符串的分割函数,创建一个列表
print(lst_1)
lst_1.extend(["study",1,3,5,"hard"]) # 给列表再添点数据
lst_1.append("study") # 再追加一个
print(lst_1)lst_1.count("python") # 统计列表中的元素 python 出现了几次
lst_1.count("study") # 统计列表中的元素 study 出现了几次
lst_1.count("1") #这里统计的是字符串 “1“ 出现的次数,并不是数字1,而列表中没有出现字符串”1”,所以这里结果是0
lst_1.count(1) #统计整型 1 在列表中出现的次数
lst_1.count("python",1) # 检验一下,是否可以截取片段,结果报错,列表的count函数只能接受一个参数
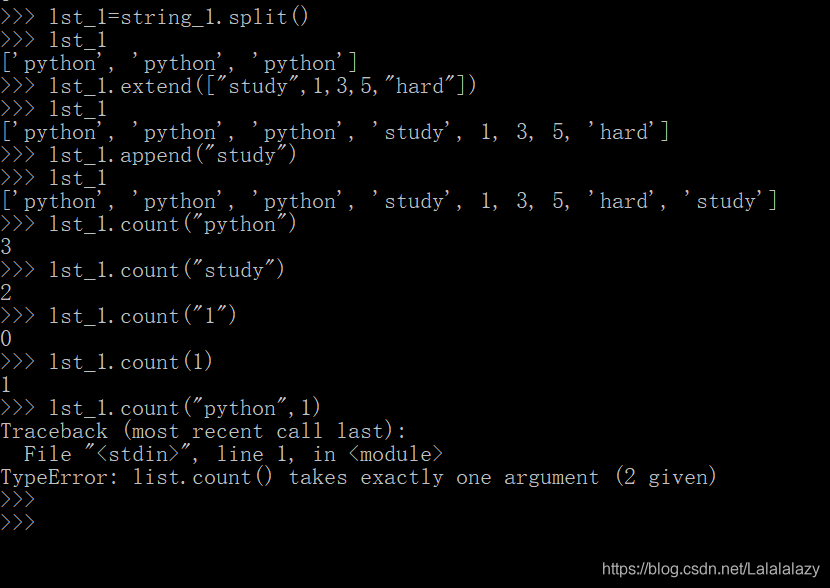
- 列表以及字符串的 count 函数对不存在的元素返回结果是0而不是报错。
- 列表只是简单地统计元素出现的次数,而字符串可以统计某个片段的某个元素的出现次数。
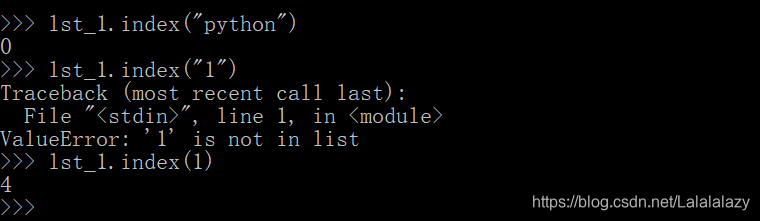
2.3.4.4 index
- 前面的知识点都有穿插过这个函数,字符串也有这个方法。字符串的index 这里就不重复了。
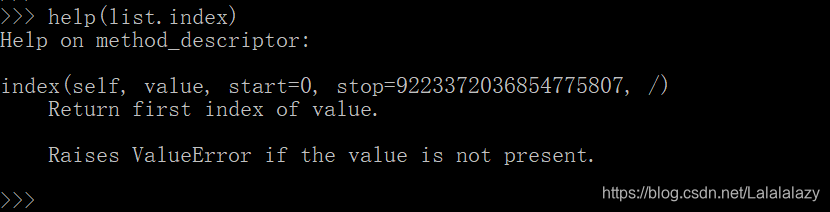
- 返回传入对象在列表中第一次出现的索引,并给出了可以找到的索引范围,先不用管,因为作为小白的我暂时不会碰到这么大数据的列表。
- 这里还说了,如果找不到传入对象在列表中的位置会报错。
lst_1=['python', 'python', 'python', 'study', 1, 3, 5, 'hard', 'study']
lst_1.index("python")
lst_1.index("1")
lst_1.index(1)
2.3.4.4 insert
help(list.insert)

- 在给出的索引前插入对象
lst_1=['python', 'python', 'python', 'study', 1, 3, 5, 'hard', 'study']
list.insert(lst_1,len(lst_1)-1,"done") # 在列表的最后一个元素前插入对象“done“
# 以上写法 insert传入了3个参数,第一个是操作的列表,第二个是索引,第三个是插入对象。#另一种写法
lst_1.insert(len(lst_1),"done") # 这种情况只能传入两个参数,一个索引,一个插入对象。

- lst_1.insert(len(lst_1),“done”) 等同于 lst_1.apppend(“done”)
2.3.4.5 remove 和 pop
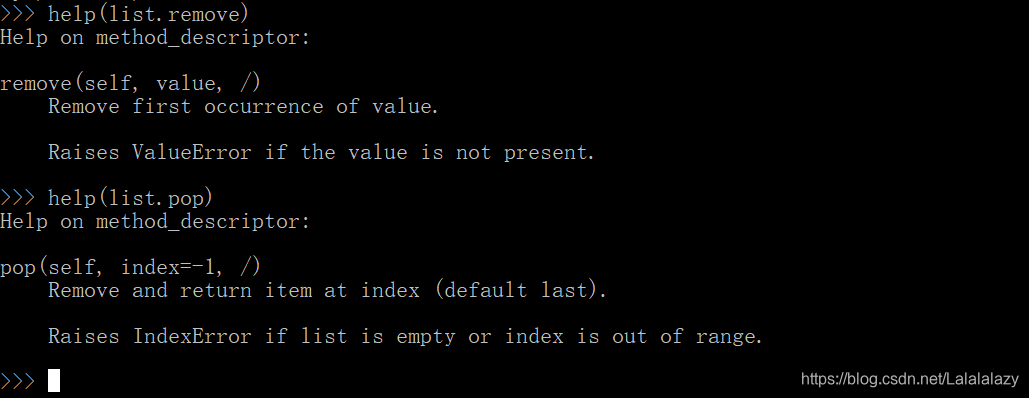
help(list.remove)
help(list.pop)
- 通过阅读文档,可大致知道两种方法的异同
- 他们共同之处是对列表进行删除操作。
- 不同的是:
- remove 参数:一个,为需要删除的对象(一次删除一个,删除在列表的第一次出现的参数),没有返回值,参数不在列表中会报错 ValueError
- pop 参数:可以传入一个可选参数,为索引的位置参数,直接定位索引位置进行删除,如果不提供索引位置则默认在列表最后的位置进行删除操作;同时,会返回被删除的对象。
- pop 的删除操作中索引如果超出列表索引范围会报错:IndexError
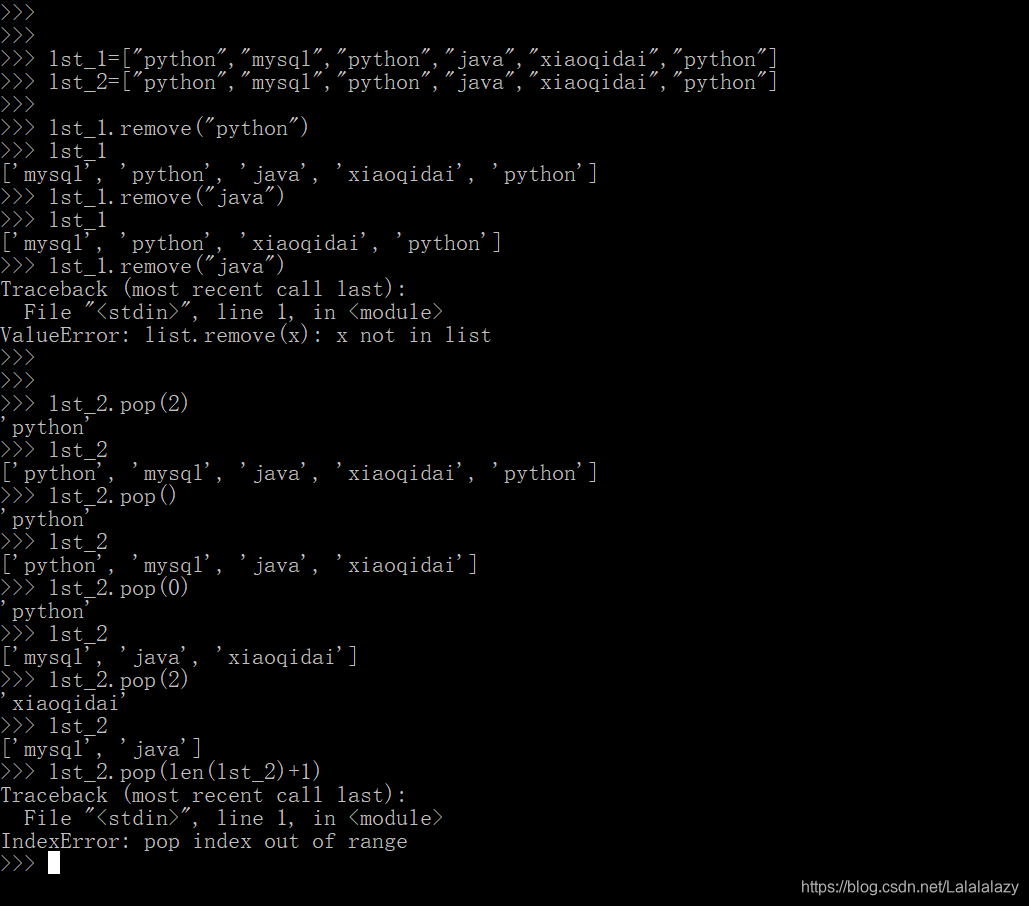
lst_1=["python","mysql","python","java","xiaoqidai","python"]
lst_2=["python","mysql","python","java","xiaoqidai","python"]
lst_1.remove("python")
lst_1.remove("java")
lst_1.remove("java")lst_2.pop(2)
lst_2.pop()
lst_2.pop(0)
lst_2.pop(1)
lst_2.pop(len(lst_2)+1)
2.3.4.6 sort
- sort() 是对列表进行排序的方法
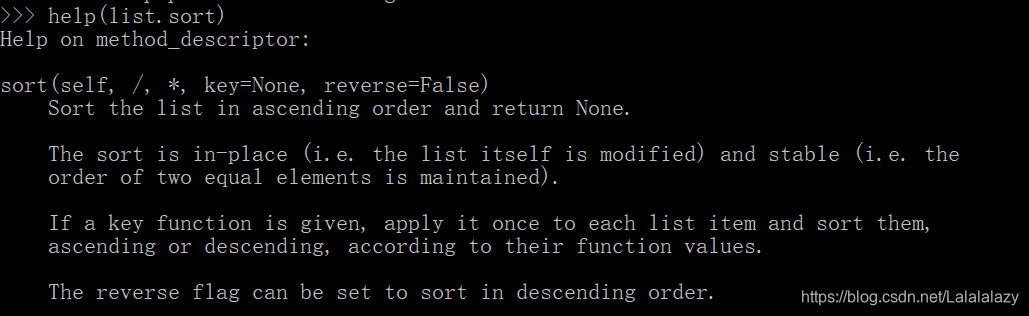
- sort(self, /, *, key=None, reverse=False)
- key 前面部分都可以忽略
- key=None:排序的条件,默认没有,你可以设置你想通过什么条件来排序;
- reverse=False:默认reverse=False 即正序,从小到大;reverse=True 则是反序,从大到小排序。
lst_1=[1,6,7,4,5,6,2,9]
lst_2=["python","java","C+","mysql"]
lst_3=["python","java","C+","mysql",80,85,90,100,96]lst_1.sort()
lst_2.sort()
lst_3.sort()
lst_2=["python","java","C+","mysql","p","pp","pz"]
lst_2.sort()
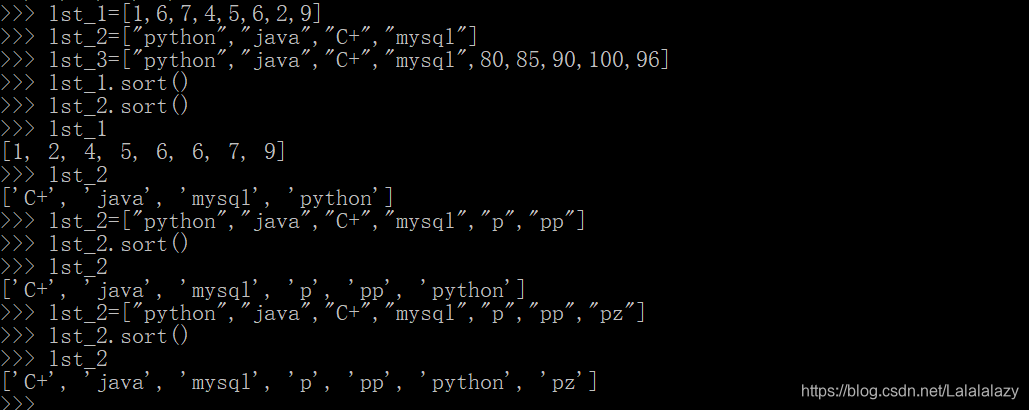
- 通过实验可以知道,默认情况下对数字的排序是正序:从小到大排序;
- 对纯字母字符串的排序也是正序,从小到大排序,这个大小的比较跟之前我在字符串的大小比较时讲的一样,统一先比较第一个字母,确定第一轮的大小,对于第一个字母相等的,就比较第二个字母,以此类推。
- 以上是默认的情况

- 这个实验表明,列表不能在字符串与数字之间进行排序。
设置条件排序
lst_2=["python","java","C+","mysql","p","pp","pz"]
lst_2.sort(key=len)

lst_2=["python","java","C+","mysql","p","pp","pz"]
lst_2.sort(key=len,reverse=True)
lst_1.sort(key=len,reverse=True)

- 排序的花样这里先介绍这些,还有未知的可自行探索或交流一下也可,谢谢支持。
2.3.4.7 列表的修改
- 可利用索引直接对列表进行修改
lst_2=['python', 'mysql', 'java', 'C+', 'pp', 'pz', 'p']
lst_2[0]="change"
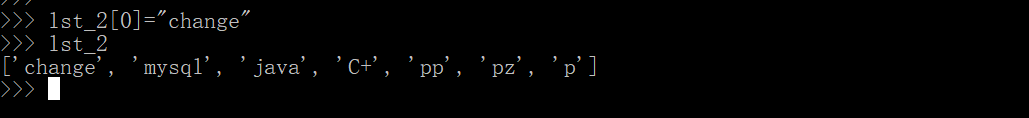
2.3.4.8 多维列表
- 之前说列表中也可以放列表,如下:
duowei_1=[[1,2,3],[3,5,9],[0,6,4]]
- 像以上这种称为多维列表,列表的元素有三个列表组成,学过线性代数的会不会觉得很行列式很像,哈哈,先保留个印象吧!
- 查找某个元素的子元素可如下操作:
duowei_1[1][0]

2.3.4.9 总结(列表与字符串)
- 列表的很多操作都是原地修改的,即直接对列表进行增删改,列表是可变的
- 而字符串是不能修改的,各种操作只能生成一个新的字符串,原来的字符串依然是原来的字符串,字符串是不可变的。
列表与字符串的转换
str.split()
"[sep]".join(list)
2.4 元祖
- 之前讲过元祖是用圆括号() 把元素装起来,且元素之间用逗号隔离,当元祖只有一个元素时,元素后也需要逗号,否则无法确认这是元祖。
- 元祖、字符串和列表都是序列,都是可迭代对象。
- 元祖什么类型的元素都可以装进括号里面,这方面与列表一样。
- 元祖不可修改,这与字符串一样。
2.4.1 创建元祖
t=12,'hello',9.9,True,[1,3,"python"]
print(t)
type(t)
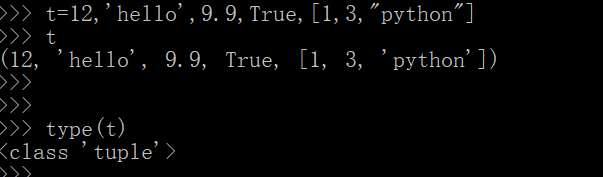
- 以上通过简单的赋值语句创建了元祖
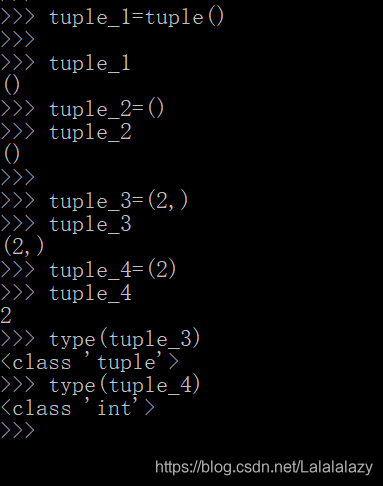
- 也可以通过 tuple() 函数直接创建空元祖
- 还可以直接使用圆括号创建包含元素或不包含元素的元祖
tuple_1=tuple()
tuple_2=()
tuple_3=(2,)
tuple_4=(2)type(tuple_3)
type(tuple_4)
2.4.2 索引和切片
- 元祖跟字符串、列表一样是序列,它的每个元素都有对应的索引,可以进行切片,基本操作和列表、字符串相仿,故不赘述。
2.4.3 列表与元祖的转化
- 使用 list() 和 tuple() 函数可以实现列表和元祖之间的转化
tuple_1=(1,3,'python','hello')
tuple_1=list(tuple_1)tuple_1=[1, 3, 'python', 'hello']
tuple_1=tuple(tuple_1)
- 因此,若想修改元祖就有了途径啦!
2.5 字典
- 想想我们平时用的字典是怎样的?
- 拿英文字典做例子:想要查找某个单词的解释,首先找到单词,然后就可以查看解释了。
- python 中的字典也差不多,它是用来存储一一对应的键值对,我们可以通过字典的键(key)来查看其所对应的值(value)。
- 键与值之间使用冒号连接,键值对之间使用逗号间隔。
- 字典可变
- 字典没有顺序,所以没有索引和前片切片
2.5.1 创建字典
- 直接使用花括号 {} 创建空字典或包含元素的字典
- 使用函数 dict() 创建空字典或非空字典

- 在字典中,键是唯一的,不能重复,不能修改,因此列表不可作为键(列表可自改);值对应于键,可重复。
- 还可以利用元祖建构字典,如下:
name=([1,"python"],[2,"java"])
course=dict(name) # 使用函数 dict() 强制把元祖转换为字典,需注意元祖的结构dt=dict(name="John",age=23) # 使用函数 dict() 创建非空字典

2.5.2 访问字典中的值
- 上面讲过,通过键可以查看值,那么是怎样查看呢?
person={"name":"Mike","age":18,"phone":"123-999"}
person["name"]
2.5.3 字典的基本操作
| 操作 | 说明 |
|---|---|
| len(d) | 返回字典(d)中的键值对的数量 |
| d[key] | 返回字典(d)中的键(key)所对应的值(value) |
| d[key]=value | 将值(value)赋给字典中的键(key),创建或修改的键值对 |
| del d[key] | 删除字典(d)的键(key)所对应的键值对 |
| key in d | 检查字典是否含有键为key的项 |
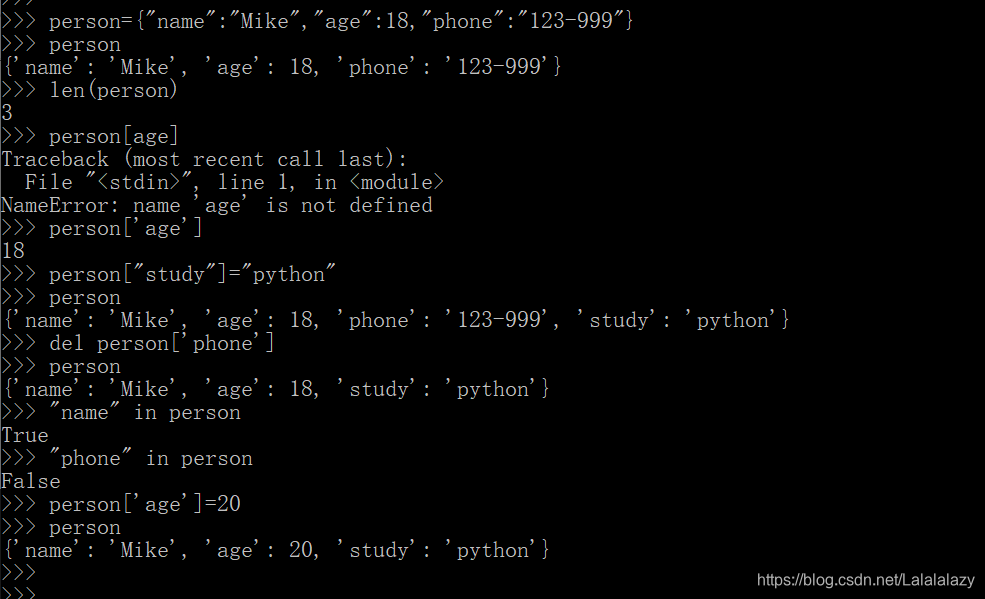
person={"name":"Mike","age":18,"phone":"123-999"}
len(person)
person['age']
person["study"]="python"
del person['phone']
"name" in person
"phone" in person
person['age']=20
2.5.4 字符串格式化输出补充
- 还记得讲到字符串的 format 函数时,有点东西没讲完。
- format 的传入参数有两种: *args 和 **kwargs ,其中 *args 传入字符串、整数、浮点数,而 **kwargs是传入字典类型
- 占位符填上键,format 函数传入相应的字典,输出简洁明了,如下示例:
my_information={'name':'Mery','time':'moroning','age':'19','phone':'222-888-999','country':'China','sex':'girl'}
introduce='''Good {time},everybody!My name is {name}.I'am {age} years old,a sunshine {sex},come from {country}.That's all,thank you!
'''
print(introduce.format(**my_information))

2.5.5 字典的方法
- 老方法查看字典的方法

2.5.5.1 clear
- 清空字典的所有元素,得到一个空字典,没有返回值
a={1:'string',2:'list',3:'tuple'}
print(a)
a.clear()
print(a)

- 注意区别 del
- del 是删除字典,彻底删除字典这个对象
del a
print(a)

2.5.5.2 copy
- 顾名思义,这是复制字典的方法
a={1:'string',2:'list',3:'tuple'}
print(a)
print(id(a))
b=a.copy()
print(b)
print(id(b))
b['title']='python'
print(b)
print(a)

- 通过 id 函数可以看到经过了 copy 得到了两个内容一样的对象,修改复制过来的对象b不影响a.
2.5.5.3 get 和 setdefault
get
- get 是通过键获取字典中的值,如果字典中没有相应的键,返回值为默认值None,不会报错
- get 可以设置默认值:如果键不存在,则返回所设置的默认值;不设置默认值则为None。
a={1:'string',2:'list',3:'tuple','total':['python','mysql']}
print(a.get('total'))
print(a.get('python'))
print(a.get(3,'无'))
print(a.get(4,'无'))
print(a['total'])
print(a['python'])

- 之前说过字典中可以通过中括号 [] 来获取值,可对比一下区别!
setdefault
- setdefault 与 get 的一个共同点是:获取键的值,返回值,设置特定的值;不同之处是:当键不存在时,setdefault 函数会直接为该字典添加相应的键值对,还可以为该键值对设置值,默认为None.
a={1:'string',2:'list',3:'tuple','total':['python','mysql']}
print(a)
print(a.setdefault(2))
print(a)
print(a.setdefault(4))
print(a)
print(a.setdefault('title','python'))
print(a)

2.5.5.4 items,keys,values

- 字典的三个方法,分别返回字典的每条内容(键值对)、每个键、每个值
- 它们返回的是一个称为集合的对象
dd={'major':'python','web':'www.runoob.com','name':'xiaoqi'}
dd_items=dd.items()
dd_values=dd.values()
dd_keys=dd.keys()
print(dd_items)
print(dd_values)
print(dd_keys)

2.5.5.5 pop,popitem
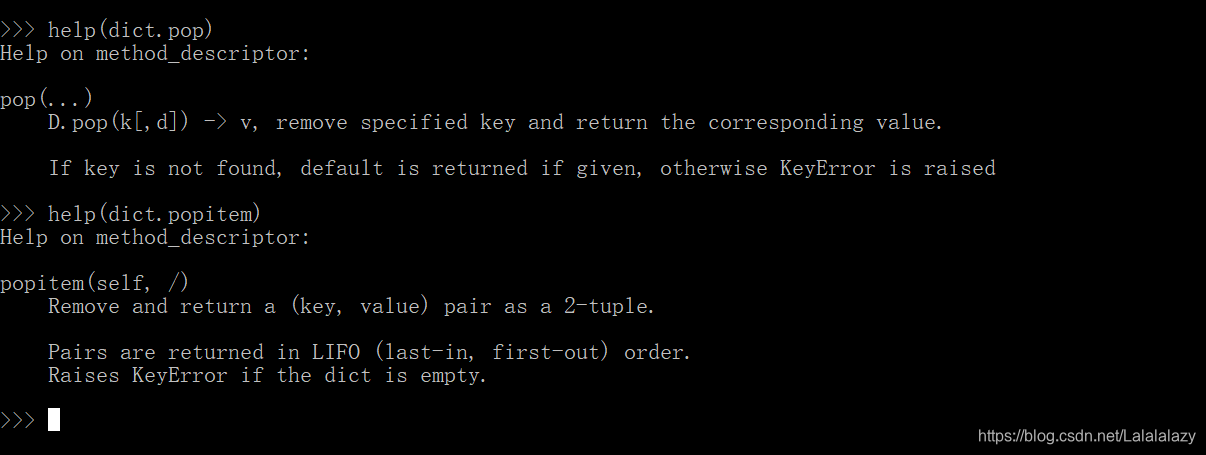
- dict.pop() 移除指定的键并返回,如果找不到键,则返回默认值;如果给定,则返回默认值,否则引发KeyError
dd={'major':'python','web':'www.runoob.com','name':'xiaoqi'}
print(dd)
a=dd.pop('name')
print(dd)
print(a)
b=dd.pop('age','none')
print(dd)
print(b)

- dict.popitem() 随机移除键值对并把键值对以元祖的形式返回。
dd={'major':'python','web':'www.runoob.com','name':'xiaoqi'}
print(dd)
dd_delete=dd.popitem()
print(dd)
print(dd_delete)

2.5.5.6 update
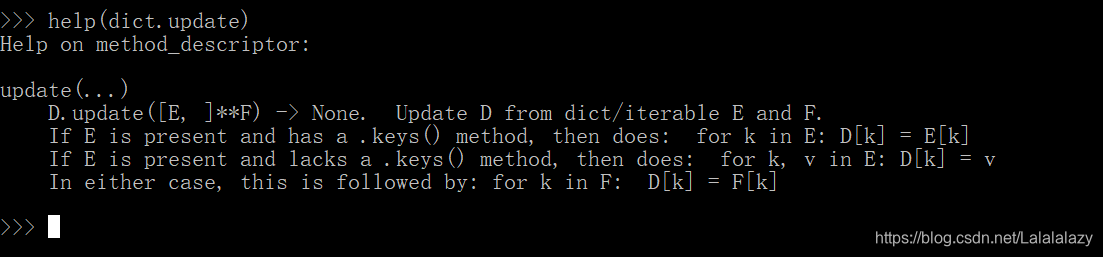
- dict.update() 更新字典,没有返回值,其参数是字典或者某种可迭代的对象。
dd={'major':'python','web':'www.runoob.com','name':'xiaoqi'}
print(dd)
dd_update=dd.update([('age','12')])
print(dd)
dd_update=dd.update({1:'nihao',2:'hello'})
print(dd)

2.6 集合 set
- set 是一个集合,使用大括号 {} 把元素装起来,跟我们高中学的集合差不多,具有互异性、无序性、确定性(元素不可变)。
2.6.1 创建集合
- 使用关键字 set ;使用大括号 {}
- 但是,不能使用大括号 {} 创建空集合,因为python会认为你创建的是字典。
- 集合具有确定性的特征,即元素的确定性,因此集合的元素是不可变的。
- 但集合本身是可变的,换句话说,集合可以被原地修改。
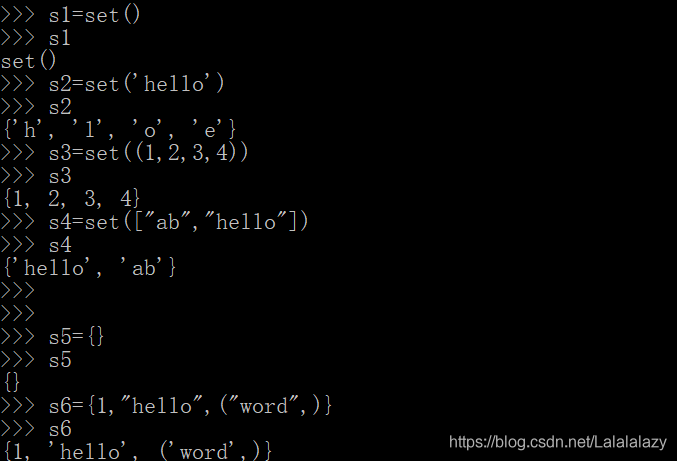
s1=set()
s2=set('hello')
s3=set((1,2,3,4))
s4=set(["ab","hello"])
s5={}
s6={1,"hello",("word",)}
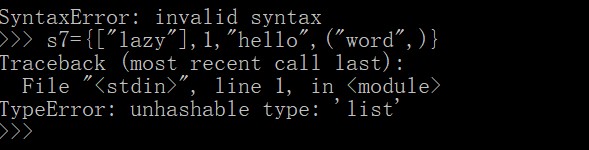
s7={["lazy"],1,"hello",("word",)}
2.6.2 set 的方法

2.6.3 不变的集合
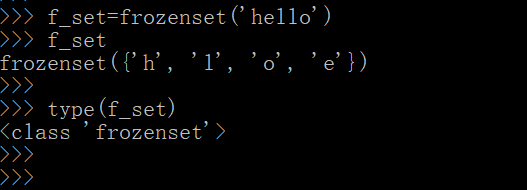
- 集合本身是可变的,但是我们可以使用关键字 frozenset() 创建不可变的集合
f_set=frozenset('hello')
2.6.4 集合的运算
2.6.4.1 元素与集合的关系
- 元素与集合的关系只有属于或不属于,使用成员运算符 in \ not in
a_set=set('hello')
"h" in a_set
"H" in a_set
"H" not in a_set

2.6.4.1 集合与集合的关系
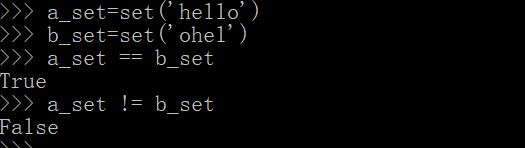
(1)等于:A是否等于B
- 使用比较运算符 == 或者 !=
a_set=set('hello')
b_set=set('ohel')
a_set == b_set
a_set != b_set
(2)子集:A 是否含于 B
- 使用比较运算符小于号 < ;或者使用集合的方法 issubset()
a_set=set('hello')
b_set=set('hol')
b_set < a_set
a_set < b_set
b_set.issubset(a_set)
c_set=set("hole")
a_set<c_set

(3)并集:A 、B 的所有元素
- 使用符号 “|”(半角竖线);表达式为 A|B
- 使用函数A.union(B)
- 并集是它们产生的一个新的对象,并不是某个集合的原地更新
a_set=set('hello')
b_set=set('python')
new_set=a_set|b_set
new_set_2=a_set.union(b_set)
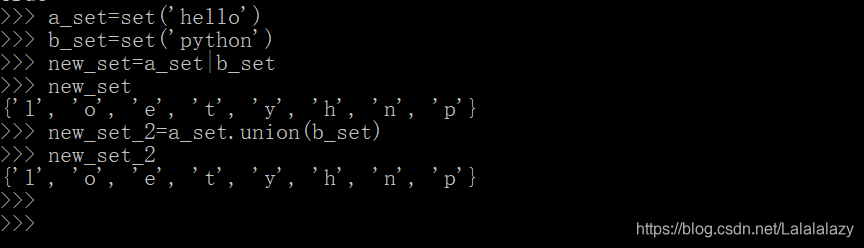
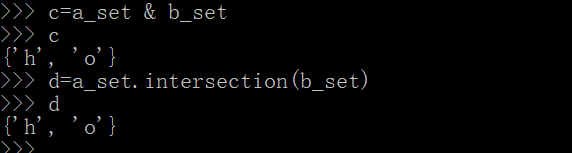
(4) 交集:A、B 共有的元素
- 使用符号 &
- 使用 intersection()
a_set=set('hello')
b_set=set('python')
c=a_set & b_set
d=a_set.intersection(b_set)
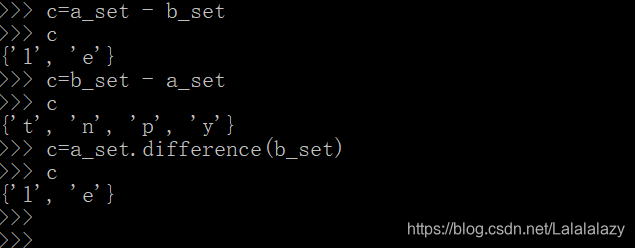
(5) A 相对于 B 的差(补),即 A 有的 B 没有
- 使用减号 “-”
- 使用 difference()
a_set=set('hello')
b_set=set('python')
c=a_set - b_set
c=b_set - a_set
c=a_set.difference(b_set)
(5) A 、 B 的对称差集,即 A 有的 B 没有与 B 有的 A 没有的并集
a_set=set('hello')
b_set=set('python')
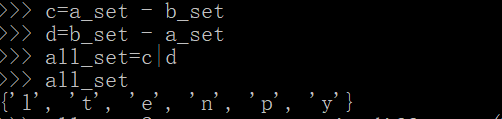
c=a_set - b_set
d=b_set - a_set
all_set=c|d
3. 循环
3.1 for 循环
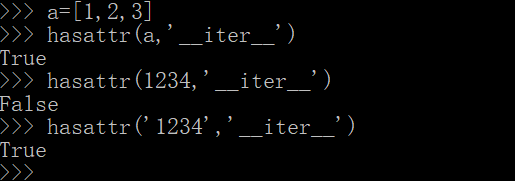
- for循环是用来遍历可迭代对象的循环语句。
- 可迭代对象可使用函数 hasattr(self,‘iter’) 来判断,返回 True 是可迭代对象,否则为 False。
a=[1,2,3]
hasattr(a,'__iter__')
- 可迭代对象还可以引用 collections 库的 isinstance 函数来判断对象是否可迭代
import collections
isinstance('hello',collections.Iterable)
# python3.8 以上版本可使用如下表达,因为以上表达即将被停用。
isinstance('hello',collections.abc.Iterable)

- 遍历字符串
string_1='zhutou'
for i in string_1:print(i)
- 遍历列表
lst_1=['he','is','a','nice','boy']
for i in lst_1:print(i)
- 遍历元祖
tup_1=(10,15,12,9)
for i in tup_1:print(i)
- 遍历字典
# 返回键一
dic_1={'who':'zhutou','what':'love','how':'well'}
for i in dic_1:print(i)
# 返回键二
for i in dic_1.keys():print(i)
# 返回值一
for i in dic_1:print(dic_1[i])
# 返回值二
for i in dic_1.values():print(i)
# 返回键与值
for k,v in dic_1.items():print(k,v)
3.1.1 range(start,stop[,step])
- start 开始的数值,默认为0
- stop 结束的数值,必须写
- step 步长,默认为1
- range函数返回的是Range类型的对象(Range类型的对象就是类似等差数列的东西),可通过 list 函数转化为列表。
a=range(10)
lst_1=list(a)
lst_2=list(range(0,10,2))
range(1,10,3)
- 练习:取100以内的偶数
# 方法一
lst=[]
for i in range(100):if i % 2 == 0:lst.append(i)
print(lst)
# 方法二
lst_2=list(range(0,100,2))
print('lst_2=',lst_2)

3.1.2 zip() 函数
- zip() 函数返回的是一个zip对象,其中的参数是可迭代对象
a=['age','name','job']
b=['18','Mary','student']
t=zip(a,b)
print(t,'/n',type(t))

a=['age','name','job']
b=['18','Mary','student']
# 把a,b成组以列表形式显示
lst=list(zip(a,b))
# 把a,b以字典的键值对形式显示
d=dict(zip(a,b))
print(lst)
print(d)
- 练习:把两列表的值相加
a=[1,3,5,7,9]
b=[2,4,6,8,10]
# 方法1
lst=[]
for i in range(len(a)):lst.append(a[i]+b[i])
print(lst)
# 方法2
lst=[]
for x,y in zip(a,b):lst.append(x+y)
print(lst)
3.1.3 enumerate()
- enumerate() 函数可得到索引以及索引对应的元素
- 其参数必须是序列
a=[('age', '18'), ('name', 'Mary'), ('job', 'student')]
for i,s in enumerate(a):# i 对应可迭代对象的索引,s 对应可迭代对象的元素print(i,s)
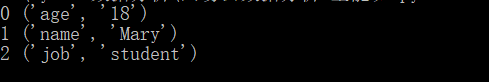
3.1.4 列表解析(列表推导)
- 写在列表中的for 语句,并把满足语句的元素提取到列表中
[i for i in range(100) if i % 2 ==0]

- 优点:简化代码,提高运行速度
- 其他解析:字典解析、集合解析
3.1.5 字典解析
- 把字典中值为None的键值对移除,采用字典解析如下:
data={"id":1,"f_name":"Jonathan","m_name":None,"l_name":"Hsu"}
data_1={k:v for k,v in data.items() if v != None }
print(data_1)

- 把字典dd={‘python’:89,‘java’:58,‘physics’:65,‘math’:49,‘chinese’:78} 中大于平均分的科目找出来。
dd={'python':89,'java':58,'physics':65,'math':49,'chinese':78}
scores=dd.values() # 获取所有值
mean=sum(scores)/len(scores) # 计算平均分
print(mean)
dd_mean={k:v for k,v in dd.items() if v>mean} # 字典解析
print(dd_mean)