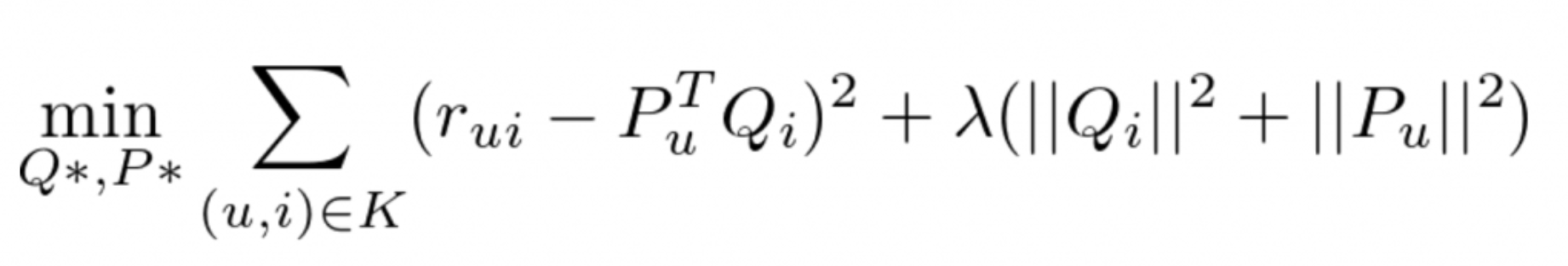1.推荐系统含义、目标
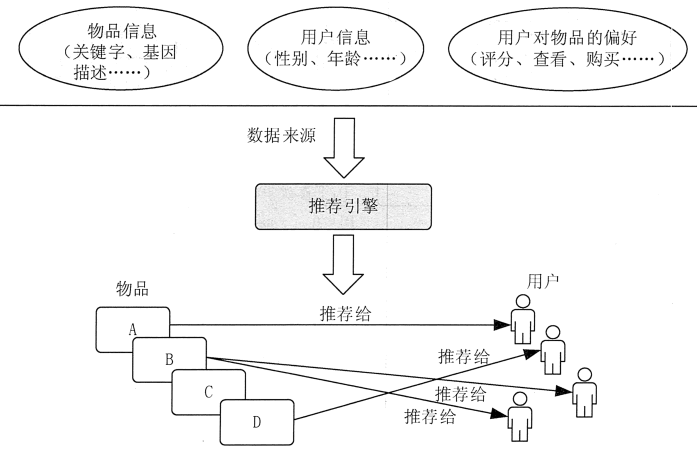
推荐系统根据用户的历史、社交、上下文环境等信息去判断用户当前感兴趣的内容。
推荐系统的业务:
- 物料组装:生产广告,实现文案、图片等内容的个性化
- 物料召回:在大量内容中召回一个子集作为推荐的内容
- 物料排序:将召回的子集的内容按照某种标准进行精细排序
- 运营策略:加入一些运营策略进行一部分的重新排序,再下发内容
算法:
召回、排序。
召回的算法多种多样:itemCF、userCF、关联规则、embedding、序列匹配、同类型收集等等。
排序的算法可以从多个角度来描述。排序算法可以分成五个部分:
构造样本、设计模型、确定目标函数、选择优化方法、评估。

2. 召回模型
-
基于商品内容:比如食物A和食物B,对于它们价格、味道、保质期、品牌等维度,可以计算它们的相似程度,可以想象,我买了包子,很有可能顺路带一盒水饺回家。
优点:冷启动,其实只要你有商品的数据,在业务初期用户数据不多的情况下,也可以做推荐
缺点:预处理复杂,任何一件商品,维度可以说至少可以上百,如何选取合适的维度进行计算,设计到工程经验,这些也是花钱买不到的
典型:亚马逊早期的推荐系统 -
基于关联规则:最常见的就是通过用户购买的习惯,经典的就是“啤酒尿布”的案例,但是实际运营中这种方法运用的也是最少的,首先要做关联规则,数据量一定要充足,否则置信度太低,当数据量上升了,我们有更多优秀的方法,可以说没有什么亮点,业内的算法有apriori、ftgrowth之类的
优点:简单易操作,上手速度快,部署起来也非常方便
缺点:需要有较多的数据,精度效果一般
典型:早期运营商的套餐推荐 -
基于物品的协同推荐:假设物品A被小张、小明、小董买过,物品B被小红、小丽、小晨买过,物品C被小张、小明、小李买过;直观的看来,物品A和物品C的购买人群相似度更高(相对于物品B),现在我们可以对小董推荐物品C,小李推荐物品A,这个推荐算法比较成熟,运用的公司也比较多
优点:相对精准,结果可解释性强,副产物可以得出商品热门排序
缺点:计算复杂,数据存储瓶颈,冷门物品推荐效果差
典型:早期一号店商品推荐 -
基于用户的协同推荐:假设用户A买过可乐、雪碧、火锅底料,用户B买过卫生纸、衣服、鞋,用户C买过火锅、果汁、七喜;直观上来看,用户A和用户C相似度更高(相对于用户B),现在我们可以对用户A推荐用户C买过的其他东西,对用户C推荐用户A买过买过的其他东西,优缺点与基于物品的协同推荐类似,不重复了。
-
基于模型的推荐:svd++、特征值分解、概率图、聚分类等等。比如潜在因子分解模型,将用户的购买行为的矩阵拆分成两组权重矩阵的乘积,一组矩阵代表用户的行为特征,一组矩阵代表商品的重要性,在用户推荐过程中,计算该用户在历史训练矩阵下的各商品的可能性进行推荐。
优点:精准,对于冷门的商品也有很不错的推荐效果
缺点:计算量非常大,矩阵拆分的效能及能力瓶颈一直是受约束的
典型:惠普的电脑推荐 -
基于时序的推荐:这个比较特别,在电商运用的少,在Twitter,Facebook,豆瓣运用的比较多,就是只有赞同和反对的情况下,怎么进行评论排序,详细的可以参见我之前写的一篇文章:应用:推荐系统-威尔逊区间法
-
基于深度学习的推荐:现在比较火的CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)都有运用在推荐上面的例子,但是都还是试验阶段,但是有个基于word2vec的方法已经相对比较成熟,也是我们今天介绍的重点。
优点:推荐效果非常精准,所需要的基础存储资源较少
缺点:工程运用不成熟,模型训练调参技巧难
典型:当前电商的会员商品推荐
基于主题模型的推荐
一篇文章拿到标题后,基于主题模型,基于LDA或者LSI可以把它生成一个向量。
基于这个向量得到关于主题的分布,计算它的相似度,基于这个相似度我们取topN可以得到一个推荐结果。
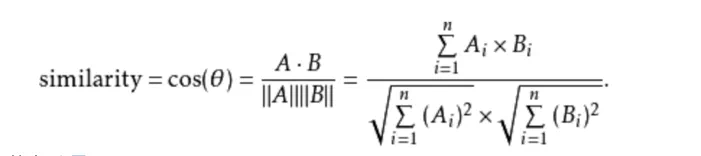
参考:
- 作者:Jachin;
- 阿里技术;
- 个性化推荐系统;
- 应用:深度学习下的电商商品推荐1.常见算法套路2.item2vec的工程引入3.python代码实现;


![[推荐系统]基于个性化推荐系统研究与实现(1)](https://img-blog.csdnimg.cn/af76d8d41cdf4ee8af910a0e86458f87.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5by6aGVhdmVu,size_13,color_FFFFFF,t_70,g_se,x_16)