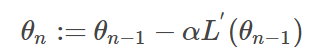在之前所写的KNN算法python实现里,KNN对k的选取很敏感,因为它给所有的近邻分配相同权重,无论距离测试样本有多远。为了降低该敏感性,可以使用加权KNN,给更近的近邻分配更大的权重,给较远的样本权重相应减少。Gaussian函数可以实现这一点,如下图所示。

python实现代码:
def gaussian(dist, sigma = 10.0):""" Input a distance and return it`s weight"""weight = np.exp(-dist**2/(2*sigma**2))return weight### 加权KNN
def weighted_classify(input, dataSet, label, k):dataSize = dataSet.shape[0]diff = np.tile(input, (dataSize, 1)) - dataSetsqdiff = diff**2squareDist = np.array([sum(x) for x in sqdiff])dist = squareDist**0.5#print(input, dist[0], dist[1164])sortedDistIndex = np.argsort(dist)classCount = {}for i in range(k):index = sortedDistIndex[i]voteLabel = label[index]weight = gaussian(dist[index]) #print(index, dist[index],weight)## 这里不再是加一,而是权重*1classCount[voteLabel] = classCount.get(voteLabel, 0) + weight*1maxCount = 0#print(classCount)for key, value in classCount.items():if value > maxCount:maxCount = valueclasses = keyreturn classes下面为分别用KNN和加权KNN运行k=[3,4,5]的准确率。相比于KNN,可以发现加权KNN在k=3和k=4有一样的结果,说明加权KNN能够缓解对k值选取的敏感。

参考链接:https://www.jianshu.com/p/48d391dab189