Hello,world!
🐒本篇博客使用到的工具有:VMware16 ,Xftp7
若不熟悉操作命令,推荐使用带GUI页面的CentOS7虚拟机
我将使用带GUI页面的虚拟机演示
虚拟机(Virtual Machine)
指通过软件模拟的具有完整硬件系统功能的、运行在一个完全隔离环境中的完整计算机系统。在实体计算机中能够完成的工作在虚拟机中都能够实现。在计算机中创建虚拟机时,需要将实体机的部分硬盘和内存容量作为虚拟机的硬盘和内存容量。每个虚拟机都有独立的CMOS、硬盘和操作系统,可以像使用实体机一样对虚拟机进行操作。
【确保服务器集群安装和配置已经完成!】可参考我的上篇博客:
VMware创建Linux虚拟机之(一)实现免密登录_Vim_飞鱼的博客-CSDN博客
VMware创建Linux虚拟机之(二)下载安装JDK与配置Java环境变量_Vim_飞鱼的博客-CSDN博客
前言
请根据读者的自身情况,进行相应随机应变。
我的三台CentOS7服务器:
主机:master(192.168.149.101)
从机:slave1(192.168.149.102)
从机:slave2(192.168.149.103)
每一个节点的安装与配置是相同的,在实际工作中,通常在master节点上完成安装和配置后,然后将安装目录通过 scp 命令复制到其他节点即可。
注意:所有操作都是root用户权限,需要我们登陆时选择root用户登录。
下载Hadoop安装包
Hadoop官网:Apache Hadoophttp://hadoop.apache.org/
我这里用的Hadoop版本下载地址:Apache Hadoop![]() https://hadoop.apache.org/release/3.3.4.html
https://hadoop.apache.org/release/3.3.4.html
在下一篇博客中,我将下载安装 jdk-8u261-linux-x64.tar 推荐大家使用,目前 jdk17 与 hadoop 3并不兼容,别问我怎么是知道的🙂
解压Hadoop安装包(只在master做)
首先,需要确保 network 网络已经配置好,使用 Xftp 等类似工具进行上传,把 hadoop-3.3.4.tar.gz 上传到 /opt/hadoop 目录内。
上传完成后,在 master 主机上执行以下代码:
cd /opt/hadoop进入/opt/hadoop目录后,执行解压缩命令:
tar -zxvf hadoop-3.3.4.tar.gz回车后系统开始进行解压,屏幕会不断滚动解压过程,执行成功后,系统在 hadoop 目录自动创建 hadoop-3.3.4 子目录。
然后修改文件夹名称为“hadoop”,即hadoop安装目录,执行修改文件夹名称命令:
mv hadoop-3.3.4 hadoop注意:也可用Xftp查看相应目录是否存在,确保正确完成。
我们进入安装目录,查看一下安装文件,如果显示如图文件列表,说明压缩成功
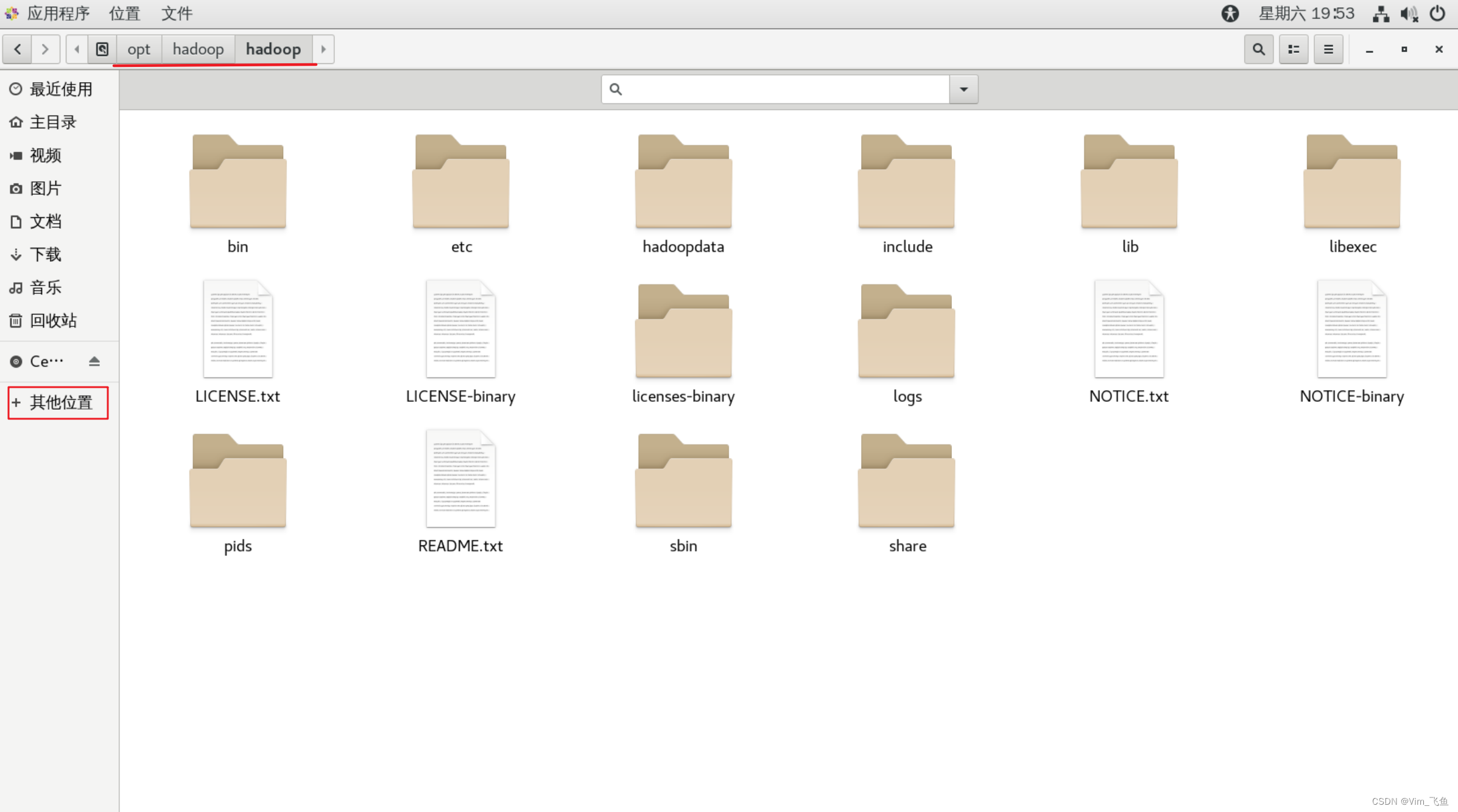
配置env文件(只在master做)
请先看如下命令(希望可以记住它们,后续操作会经常使用)
A. 进入编辑状态:insert
B. 删除:delete
C. 退出编辑状态:ctrl+[
D. 进入保存状态:ctrl+]
E. 保存并退出:" :wq " 注意先输入英文状态下冒号
F. 不保存退出:" :q! " 同上
大概执行顺序:A→B→C→D→E
配置bashrc文件
执行命令输入:
vi /etc/bashrc在bashrc文件末尾加入:
#hadoop config
export HADOOP_HOME=/opt/hadoop/hadoop
export CLASSPATH=$CLASSPATH:$($HADOOP_HOME/bin/hadoop classpath)
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"输入source命令,进行配置刷新:
source /etc/bashrc配置jdk文件
执行命令:
vi /opt/hadoop/hadoop/etc/hadoop/hadoop-env.sh找到 “ export JAVA_HOME ” 这行,用来配置jdk路径
修改为:export JAVA_HOME=/usr/local/java/jdk1.8.0_162/
如下图所示:(位于54行,gui页面可查看)

配置核心组件文件(只在master做)
Hadoop 的核心组件文件是 core-site.xml,位于 /opt/hadoop/hadoop/etc/hadoop 子目录下,用vi编辑 core-site.xml 文件,需要将下面的配置代码放在文件的 <configuration>和</configuration> 之间。
执行编辑 core-site.xml 文件的命令:
vi /opt/hadoop/hadoop/etc/hadoop/core-site.xml需要在<configuration>和</configuration>之间加入的代码:
<property><name>fs.defaultFS</name><value>hdfs://master:9000</value>
</property>
<property><!-- Hadoop 数据存放的路径,namenode,datanode 数据存放路径都依赖本路径,不要使用 file:/ 开头,使用绝对路径即可namenode 默认存放路径 :file://${hadoop.tmp.dir}/dfs/namedatanode 默认存放路径 :file://${hadoop.tmp.dir}/dfs/data--><name>hadoop.tmp.dir</name><value>/opt/hadoop/hadoop/hadoopdata</value>
</property>如下图所示:

编辑完成后,保存退出即可!
配置文件系统(只在master做)
Hadoop 的文件系统配置文件是 hdfs-site.xml ,位于 /opt/hadoop/hadoop/etc/hadoop 子目录下,用vi编辑该文件,需要将以下代码放在文件的<configuration>和</configuration>之间。
执行编辑hdfs-site.xml文件的命令:
vi /opt/hadoop/hadoop/etc/hadoop/hdfs-site.xml需要在<configuration>和</configuration>之间加入的代码:
<property><name>dfs.namenode.http-address</name><!-- Master为当前机器名或者IP地址 --><value>master:9001</value>
</property>
<property><name>dfs.namenode.name.dir</name><!-- 以下为存放节点命名的路径 --><value>file:/opt/hadoop/hadoop/hadoopdata/dfs/name</value>
</property>
<property><name>dfs.datanode.data.dir</name><!-- 以下为存放数据命名的路径 --><value>file:/opt/hadoop/hadoop/hadoopdata/dfs/data</value>
</property>
<property><name>dfs.replication</name><!-- 备份次数,因为有2台DataNode--><value>2</value>
</property>
<property><name>dfs.webhdfs.enabled</name><!-- Web HDFS--><value>true</value>
</property>
<property><name>dfs.permissions</name><value>false</value>
</property><property><name>dfs.namenode.secondary.http-address</name><value>Master:50090</value>
</property>如下图所示:

编辑完成后,保存退出即可!
配置 yarn-site.xml 文件(只在master做)
yarn 的站点配置文件是 yarn-site.xml ,位于 /opt/hadoop/hadoop/etc/hadoop 子目录下,依然用vi编辑该文件,将以下代码放在文件的<configuration>和</configuration>之间。
执行编辑yarn-site.xml文件的命令:
vi /opt/hadoop/hadoop/etc/hadoop/yarn-site.xml需要在<configuration>和</configuration>之间加入的代码:
<property><name>yarn.resourcemanager.hostname</name><!-- Master为当前机器名或者ip号 --><value>master</value></property><property><name>yarn.nodemanager.aux-services</name><!-- Node Manager辅助服务 --><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><!-- Node Manager辅助服务类 --><value>org.apache.hadoop.mapred.ShuffleHandler</value></property><property><name>yarn.nodemanager.resource.cpu-vcores</name><!-- CPU个数,需要根据当前计算机的CPU设置--><value>1</value></property><property><name>yarn.resourcemanager.admin.address</name><!-- Resource Manager管理地址 --><value>master:8033</value></property><property><name>yarn.resourcemanager.webapp.address</name><!-- Resource Manager Web地址 --><value>master:8088</value></property>如下图所示:

编辑完成后,保存退出即可!
配置MapReduce计算框架文件(只在master做)
在 /opt/hadoop/hadoop/etc/hadoop 子目录下,系统已经有一个 mapred-site.xml.template 文件,我们需要将其复制并改名,位置不变。
执行复制和改名操作命令:
cp /opt/hadoop/hadoop/etc/hadoop/mapred-site.xml.template /opt/hadoop/hadoop/etc/hadoop/mapred-site.xml可直接创建
然后用 vi 编辑 mapred-site.xml 文件,需要将下面的代码填充到文件的<configuration>和</configuration>之间。
执行命令:
vi /opt/hadoop/hadoop/etc/hadoop/mapred-site.xml需要在<configuration>和</configuration>之间加入的代码:
<property><name>mapreduce.framework.name</name><!-- MapReduce Framework --><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><!-- MapReduce JobHistory, 当前计算机的IP --><value>master:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><!-- MapReduce Web App JobHistory, 当前计算机的IP --><value>master:19888</value></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=/opt/hadoop/hadoop</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=/opt/hadoop/hadoop</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=/opt/hadoop/hadoop</value></property>如下图所示:
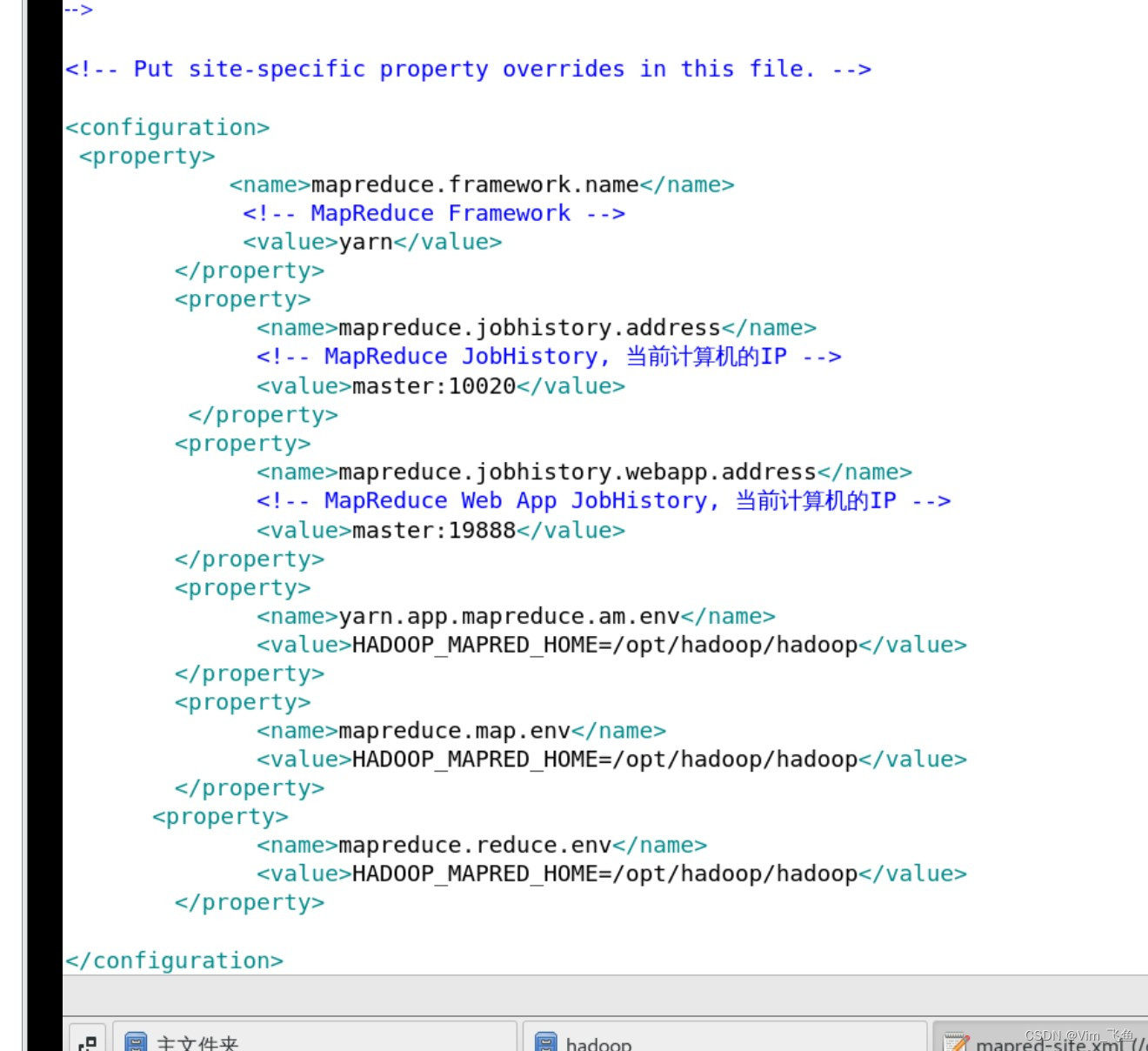
编辑完毕,保存退出即可!
配置master的slaves文件(只在master做)
workers 文件给出了Hadoop集群的 slave节点列表,该文件十分的重要,因为启动Hadoop的时候,系统总是根据当前 workers 文件中的 slave 节点名称列表启动集群,不在列表中的 slave 节点便不会被视为计算节点。
执行编辑slaves文件命令:
vi /opt/hadoop/hadoop/etc/hadoop/workers注意:用vi编辑slaves文件,应该根据读者您自己所搭建集群的实际情况进行编辑。
例如:我这里已经安装了slave1和slave2,并且计划将它们全部投入Hadoop集群运行。
所以应当加入以下代码:
slave1
slave2如下图所示:

注意:删除slaves文件中原来localhost那一行!
编辑完成,保存退出即可!
复制master上的Hadoop到slave节点(只在master做)
通过复制master节点上的hadoop,能够大大提高系统部署效率,假设我们有200台需要配置…笔者岂不白头,话不多说直接 scp
由于我这里有slave1和slave2,所以复制两次。
复制命令:执行命令即可
scp -r /opt/hadoop root@slave1:/opt
scp -r /opt/hadoop root@slave2:/optHadoop集群的启动-配置操作系统环境变量(三个节点都做master+slave1/2)
回到用户目录命令:
cd /opt/hadoop然后用vi编辑.bash_profile文件,命令:
vi /etc/profile最后把以下代码追加到文件的尾部:
#HADOOP
export HADOOP_HOME=/opt/hadoop/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH如下图所示:

保存退出后,执行命令:
source /etc/profilesource /etc/profile 命令是使上述配置变量生效(刷新)
提示:在slave1和slave2使用上述相同的配置方法,进行三个节点全部配置。
创建Hadoop数据目录(只在master做)
创建数据目录,命令是:
mkdir /opt/hadoop/hadoopdata通过Xftp可查看该hadoopdata
如下图所示:

格式化文件系统(只在master做)
执行格式化文件系统命令:
hadoop namenode -format或者执行:(推荐使用)
hdfs namenode -format启动和关闭Hadoop集群(只在master做)
首先进入安装主目录,命令是:
cd /opt/hadoop/hadoop/sbin提示:目前文件位置可在Xshell顶部栏观察
然后启动,命令是:
start-all.sh执行命令后,系统提示 ” Are you sure want to continue connecting(yes/no)”,输入yes,之后系统即可启动。
如下图所示:(未进入sbin目录,也并无大碍)

注意:可能会有些慢,千万不要以为卡掉了,然后强制关机,这是错误的。
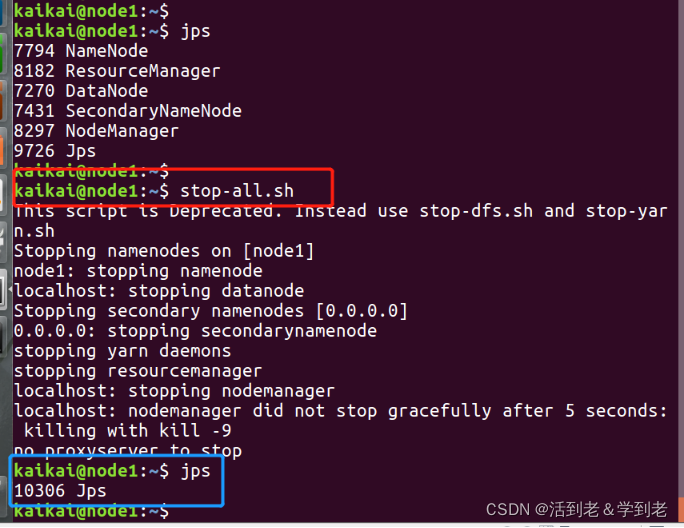
如果要关闭Hadoop集群,可以使用命令:
stop-all.sh如下图所示:

下次启动Hadoop时,无须NameNode的初始化,只需要使用 start-dfs.sh 命令即可,然后接着使用 start-yarn.sh 启动yarn。
实际上,Hadoop建议放弃(deprecated)使用start-all.sh和stop-all.sh一类的命令,而改用start-dfs.sh和start-yarn.sh命令。
start-dfs.shstart-yarn.sh验证Hadoop集群是否启动成功
读者您可以在终端执行jps命令查看Hadoop是否启动成功。
在master节点(名称节点),执行:
jps如果显示:SecondaryNameNode、 ResourceManager、 Jps 和NameNode这四个进程,则表明主节点master启动成功
如下图所示:

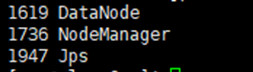
然后分别在slave0和slave1节点下执行命令:
jps如果成功显示:NodeManager、Jps 和 DataNode,这三个进程,则表明从节点即数据节点(slave1和slave2)启动成功
如下图所示:

显示上述页面即表示我们的hadoop集群,全部且完全搭建成功!💪
注意:
hdfs namenode -format
每次格式化都会重新你创建一个namenodeId,而在默认情况下tmp/dfs/data下包含了上次format下的id,格式化不会清空datanode下的数据,导致启动失败。
因此,避免重复多次修改配置文件,避免Hadoop多次格式化。
下次登陆,直接输入 start-dfs.sh 与start-yarn.sh 即可。
写到此处,此篇博客就完全结束了,如果各位大佬发现其中错误,欢迎指出!🙇
至此,此篇内容,完美结束!感谢浏览,发现问题,希望指正!💪