1、求最大元素和最小元素
max():求向量或矩阵的最大元素。
min( ):求向量或矩阵的最小元素。
(1)当参数为向量时,函数有两种调用格式:
①y=max(X):返回向量X的最大值存入y,如果X中包含复数元素,则按模取最大值。
②[y,k]=max(X):返回向量X的最大值存入y,最大值元素的序号存入k,如果X中包含复数元素,则按模取最大值。
>> x = [1 2 -5 85 -2 0];
>> y = max(x)y =85>> [y k] = max(x)y =85
k =4
>> x = [ 1 2 3 -5 3+9i -2 0];
>> y = max(x)y =3.0000 + 9.0000i>> [y k] = max(x)y =3.0000 + 9.0000i
k =5
(2)当参数为矩阵时,函数有三种调用格式:
① max(A):返回一个行向量,向量的第i个元素是矩阵A的第i列上的最大值。
②[Y,U]=max(A):返回行向量Y和U,Y向量记录A的每列的最大值,U向量记录每列最大值元素的行号。
③ max(A,[ ],dim): dim取1或2。dim取1时,该函数的功能和max(A)完全相同;dim取2时,该函数返回一个列向量,其第i个元素是A矩阵的第i行上的最大值。
对矩阵按行求最大元素,仅使用第一种格式,能够做到吗?
答:将矩阵转置即可。
例1:求矩阵A的每行及每列的最大元素,并求整个矩阵的最大元素。
>>A = [13 -56 78;25 63 -235;78 25 563;1 0 -1]A =13 -56 7825 63 -23578 25 5631 0 -1>> a1 = max(A) %返回一个行向量,存储各列元素的最大值a1 =78 63 563 >> [y1 u1] = max(A) %行向量y1存储每列元素的最大值,行向量u1存储各列最大值元素的行号y1 =78 63 563
u1 =3 2 3 >> a2 = max(A,[],1) %与max(A)功能一样a2 =78 63 563>> a3 = max(A,[],2) %返回列向量a3,存储每行的最大值a3 =7863563>> [y2 u2] = max(A,[],2) %列向量y2存储每行元素的最大值,列向量u2存储各行最大值元素的列号y2 =78635631
u2 =3231
用什么方法只调用一次max函数就能求得整个矩阵的最大值?
>> max(A(:)) %将A矩阵元素堆叠变成-个列向量ans =563
2、求平均值和中值
有了平均值,为什么还要中值?
平均值容易受极端数据影响。
(1)mean( ):求算术平均值。
(2)median( ):求中值。
>> x = [1200 800 1500 1000 5000];
>> mean(x)ans =1900>> median(x)ans =1200
3、求和与求积
(1)sum():求和函数。
(2)prod( ):求积函数。
4、累加和与累乘积
 (1)cumsum():累加和函数。
(1)cumsum():累加和函数。
(2)cumprod():累乘积函数。
例2:求向量X=1,2,3,4,5,6,7,8,9,10]的和、累加和、积与累乘积。
>> x = 1:10x =1 2 3 4 5 6 7 8 9 10>> y0 = sum(x) %求和y0 =55>> y1 = cumsum(x) %求累加和y1 =1 3 6 10 15 21 28 36 45 55>> y2 = prod(x) %求积y2 =3628800>> y3 = cumprod(x) %求累加积y3 =1 2 6 24 120 720 5040 40320 362880 3628800
5、标准差与相关系数
(1)标准差用于计算数据偏离平均数的距离的平均值,其计算公式为:
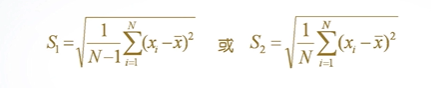 S1为样本标准差,S2为总体标准差
S1为样本标准差,S2为总体标准差
std():计算标准差函数。调用格式:
①std(X):计算向量X的标准差。
②std(A):计算矩阵A的各列的标准差。
③std(A,flag,dim): flag取0或1,当flag=0时,按S1所列公式计算样本标准差;当flag=l时,按S2所列公式计算总体标准差。dim=1按列计算,dim=2按行计算。默认情况下,flag=0,dim=1。
例3:生成满足正态分布的20x4随机矩阵,用不同的形式求其各列之间的标准差。
>> x = randn(50000,4);
y1 = std(x,0,1) %0按样本标准差S1计算,1按列计算y1 =1.0023 0.9994 0.9972 0.9990>> y2 = std(x,1,1) %1按总体标准差S2计算,1按列计算y2 =1.0023 0.9994 0.9972 0.9990>> x1 = x';
y3 = std(x1,0,2) %0按样本标准差S1计算,2按行计算y3 =1.00230.99940.99720.9990>> y4 = std(x1,1,2) %0按样本标准差S1计算,2按行计算y4 =1.00230.99940.99720.9990
(2)相关系数:能够反映两组数据序列之间相互关系,其计算公式为
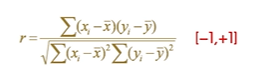 取值在+1和-1之间,其值越接近于0,说明数据越不相关,其值的绝对值越接近于1,说明数据之间相关程度越高。
取值在+1和-1之间,其值越接近于0,说明数据越不相关,其值的绝对值越接近于1,说明数据之间相关程度越高。
corrcoef( ):相关系数函数。调用格式:
①corrcoef(A):返回由矩阵A所形成的一个相关系数矩阵,其中,第i行第j列的元素表示原矩阵A中第i列和第j列的相关系数。
②corrcoef(X,Y):在这里X、Y是向量,它们与corrcoef([X,Y])的作用一样,用于求X、Y向量之间的相关系数。
6、排序
sort():排序函数。调用格式:
① sort(X):对向量X按升序排列。
②[Y,I]=sort(A,dim,mode)
其中,dim指明对A的列还是行进行排序。mode指明按升序还是降序排序,若取“ascend”,则按升序;若取“descend”,则按降序,默认为升序。输出参数中,Y是排序后的矩阵,而l记录Y中的元素在A中位置。
例4:对矩阵A进行各种排序
>> A = [1 -8 5;4 12 6; 13 7 -13]A =1 -8 54 12 613 7 -13>> y1 = sort(A) %对矩阵A按列升序y1 =1 -8 -134 7 513 12 6>> y2 = sort(A,2,'descend') %对矩阵A按行降序排列y2 =5 1 -812 6 413 7 -13>> [y3 m3] = sort(A) %对矩阵A每列按升序排序,并把各元素在原矩阵中的位置保存在矩阵m3中y3 =1 -8 -134 7 513 12 6
m3 =1 1 32 3 13 2 2>> [y4 m4] = sort(A,'descend') %对矩阵A每列按降序排序,并把各元素在原矩阵中的位置保存在矩阵m4中y4 =13 12 64 7 51 -8 -13
m4 =3 2 22 3 11 1 3