点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
ChatGPT有多火?
用一个通俗易懂的话来表达,ChatGPT就是爱豆中的鹿晗、蔡徐坤、杨超越;脱口秀界的李诞、徐志胜;足球界的梅西、C罗、姆巴佩...
前段时间,HuggingFace发表了一篇博客,详细讲解了ChatGPT背后的技术原理—RLHF。
RLHF,全称:Reinforcement Learning from Human Feedback,即从人类反馈中学习强化学习。
RLHF是一个具有挑战性的概念,因为它涉及多模型训练过程和不同的部署阶段。在语言模型流行之前, RLHF 就已经有相关的研究出现。
首先,我们来看看4篇早于语言模型的关于 RLHF 的论文:
1. TAMER:Training an Agent Manually via Evaluative Reinforcement论文详情页
提出了一个学习的代理,其中人类提供迭代采取的行动的分数以学习奖励模型。
2. Interactive Learning from Policy-Dependent Human Feedback论文详情页
本文研究了使用积极和消极回归的互动学习行为的问题,并就此提出了实验结果:证明了这种假设是否是真的,即人类教练对于做出一个决定不受教练目前政策的影响。
作者认为,除了普遍的现象外,政策依赖的回归还使得应该从中获益的训练策略可供借鉴。基于这个洞察,本文介绍了由人类主导的主动角色批评算法(COACH)学习的算法。最后,本文表明,即使在没有嘈杂的照片特征的情况下,COACH也能成功地学习多个行为,即使是有噪音的图像特征。
3. Deep Reinforcement Learning from Human Preferences论文详情页
本文展示了如何成功训练复杂的创新行为,这些行为和环境比以前从人类反馈中学习到的任何事情都要复杂得多,这大大降低了人类监督成本,使其能够应用于最先进的RL系统。
论文表明,我们可以成功地训练复杂的新行为。这些行为和环境比以前从人类反馈中学习到的任何事情都更复杂。
此外,还提出了一种新的基于经验的方法来解决复杂的机器翻译任务。该方法不需要获得奖励函数,但可以有效地解决复杂的机器翻译。这种方法将人类监督成本大幅削减,从而可用于实际应用。
4. Deep TAMER: Interactive Agent Shaping in High-Dimensional State Spaces论文详情页
论文扩展了TAMER框架,其中使用深度神经网络对奖励预测进行建模。
具体来说,论文提出一种新的深度激励学习算法,它利用大脑神经网络的表示能力来学习复杂任务。证明了这种方法在仅15分钟内训练一个比人类好得多的agent的能力,并使用这项技术培训了一个比人类好得多的agent。
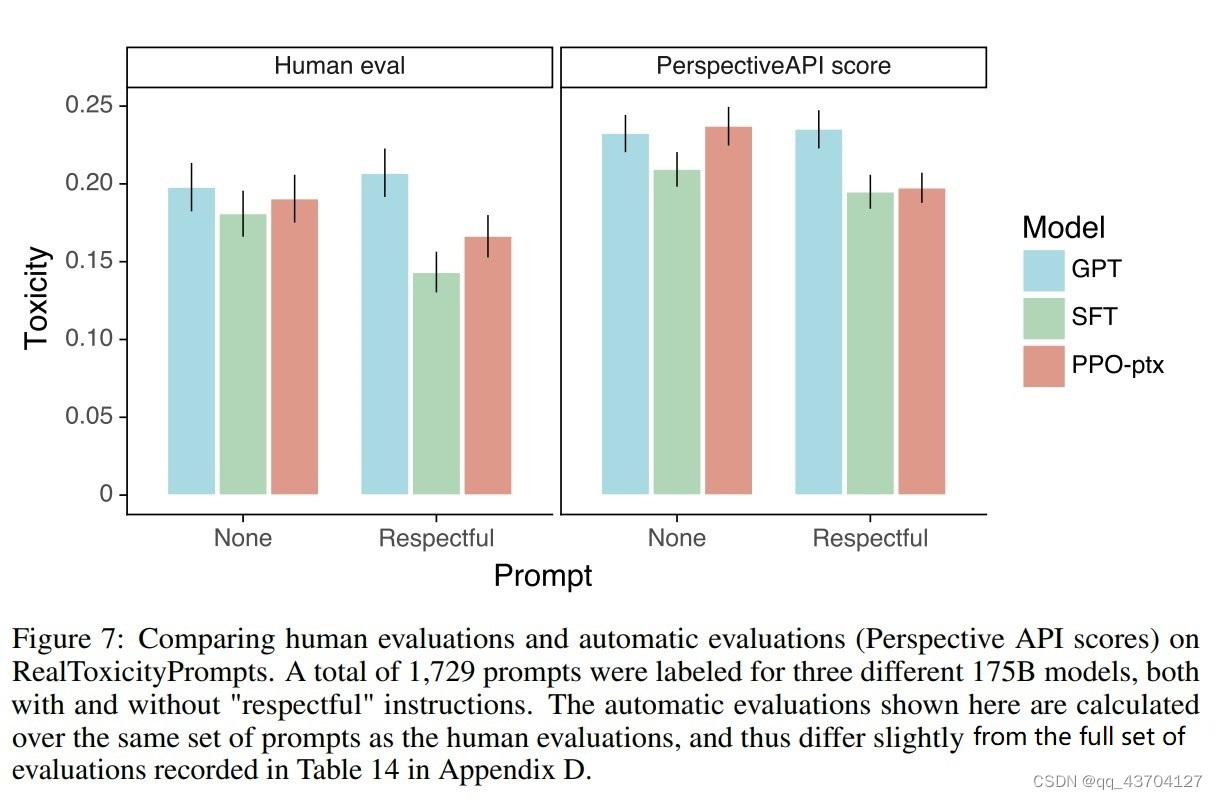
随着语言模型的流行,ChatGPT更是掀起了刷屏网络的热潮,RLHF对语言模型的性能影响得到更加充分的展现。
1. Fine-Tuning Language Models from Human Preferences论文详情页
这是一篇研究奖励学习对四项特定任务影响的早期论文。
本文将奖励学习应用于四个自然语言任务:①继续文本,②情感③physically描述的语言④摘要任务。本文提出了一种新的生成训练方法,该方法利用了人类对标记器的启发式训练,并展示了如何将自然语言的训练应用于句法和句子摘要。
2. Learning to summarize with human feedback论文详情页
本文提到:机器学习研究人员越来越依赖于训练和评估数据与指标。所以这篇文章展示了如何训练一个模型来预测人类的参考摘要,并通过优化总结策略来提高这些摘要的质量。本文收集了一个大型、高质量的摘要数据集,训练了一个模型来 predict人类偏好的摘要,以及使用激励学习来调整总结政策,并发现我们的模型明显优于仅依赖监督学习。
3. WebGPT: Browser-assisted question-answering with human feedback论文详情页
本文将GPT-3改进为回答长形式问题时使用webbrowsing环境的任务。通过设置任务,这样人类就可以执行任务,并使用imitation学习来训练模型。为了使事实的事实精确性更容易,模型必须在搜索时收集参考。本文的模型应用于雷丁问答的eli5数据集。
4. GopherCite: Teaching language models to support answers with verified quotes论文详情页
本文使用RLHF训练 LM 以返回带有特定引用的答案。本篇文章从人类偏好中归纳出的再现学习来训练开放书QA模型。GopherCites模块能够生成高质量的回答,并且在不确定的情况下拒绝回答所有问题。然而,在反对派真证QA数据集上的分析表明,引用只是总体安全和信誉战略的一小部分。
5. Sparrow: distributed, low latency scheduling论文详情页
大规模数据分析框架正在转向为短任务时间和更大的并行性。为了在合适的机器上安排数百万个任务,需要在适当的机器上部署数百万个任务。本文证明了一种分散式、随机抽样方法可以提供接近最优性能,而避免中央化的设计带来的延迟性和可扩展性限制。
6. Scaling Laws for Reward Model Overoptimization:研究学习偏好模型在 RLHF 中的缩放特性。论文详情页
本文研究了黄金奖励模型的评分变化,在预测人类偏好时,使用一种固定的"黄金标准"奖励模型扮演人类角色。本文发现,这种关系依赖于不同方法的不同函数形式,并且在每个情况下其权重呈不同的顺序。本文还探讨了对这些实证结果对理论考虑的影响。
7. Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback论文详情页
本文将人类反馈的偏好建模和强化学习应用于NLP评估,发现这种对齐训练在几乎所有NLP评估中提高了性能,并且与特殊技能培训的相关课程完全兼容。
本文还探讨了一个迭代在线的学习模式,其中偏好模型和RL策略以每周轮班顺序更新,有效改善了数据集和模型。最后,本文还研究了LRHF的鲁棒性和可扩展性,并确定LRHF培训的平均线性关系与政策和其初始化之间的约束相关联。
8. Dynamic Planning in Open-Ended Dialogue using Reinforcement Learning:使用 RL 来增强开放式对话代理的会话技能。论文详情页
本文开发了一个开放式、可持续的对话系统,该系统使用增强学习(RL)技术来赋予人类bot的说话技能。本文将该系统与SOTA(监督)语言模型相结合,该模型特别适用于变化的动态行动空间。
9. Is Reinforcement Learning(Not)for Natural Language Processing?: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization论文详情页
本文讨论 RLHF 中开源工具的设计空间并提出新算法NLPO(自然语言策略优化)作为 PPO 的替代方案。
文章解决了将大型语言模型(LMs)与人类偏好的对齐问题。如果学术界认为文本生成作为顺序决策问题的自然概念框架,强化学习(RL)似乎是一种自然的概念框架。然而,对于基于LM的生成器来说,这项任务面临的实证挑战,包括训练不稳定性以及缺乏开放资源和改进度量。因此,研究社区提出了一个问题:是否是RL实践性的?
——结束———
以上这些论文展示了RLHF的前途和影响力,但仍然存在明显的局限性。这些模型虽然好,但仍然可以在没有任何不确定性的情况下输出有害或事实上不准确的文本。
这种不完美代表了RLHF的长期挑战和动力——在一个固有的人类问题领域中运行意味着永远不会有一条明确的最终线可以让模型被标记为完整。
扫描下方二维码还可获取RLHF相关必读论文!

好了,以上就是本期的分享内容,喜欢的同学欢迎点赞加收藏哦~
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了900多位海内外讲者,举办了逾450场活动,超500万人次观看。

我知道你
在看
哦
~

点击 阅读原文 解锁更多精彩!