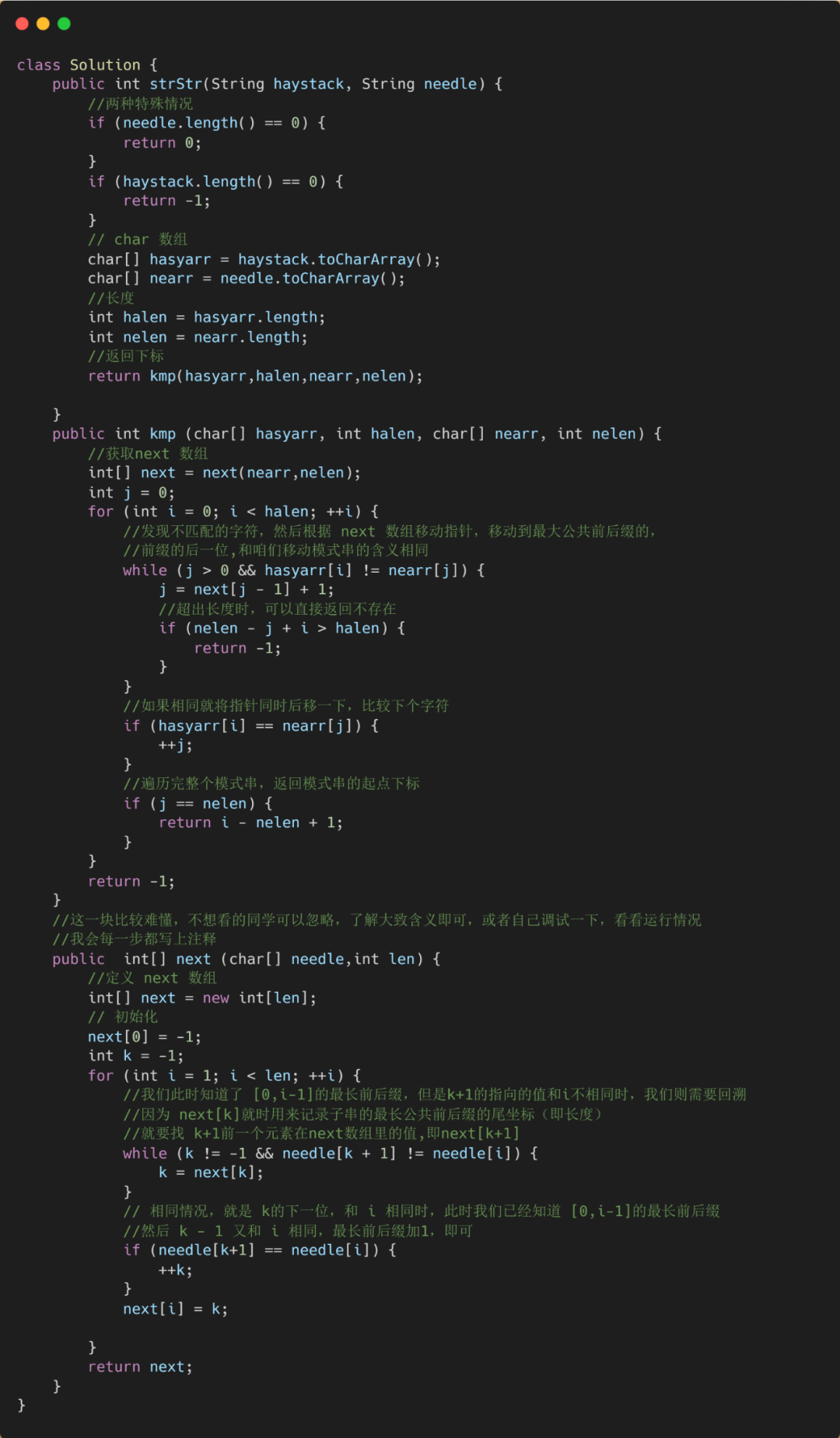
BF算法
描述: BF,Brute Force,暴力匹配的意思,是最简单直观的字符串匹配算法。假设有主串s1和子串s2,根据BF算法判断s1是否包含s2的步骤如下:
- 初始下标指针 i, j 分别指向s1, s2的首位置,若s1[ i ]与s2[ j ]匹配成功,则 i++, j++ 继续匹配s1和s2的下一位;
- 若匹配失败主串下标指针 i 回溯到本趟起始匹配位置的下一位,继续从子串首位开始匹配;
- 重复以上操作,直到s1或s2被全部匹配完,根据 j 与子串的长度大小关系可以确定子串是否被包含。
java代码
public class MatchBF {// 匹配成功返回子串在主串第一次出现的起始下标index(index>0),否则返回0public static int BF(String str1, String str2) {char[] s1 = str1.toCharArray();char[] s2 = str2.toCharArray(); // 转为字符数组int i = 0, j = 0, k = i; // 字符数组下标从0开始,所以i,j初始为0while (i < s1.length && j < s2.length) {if (s1[i] == s2[j]) {i++;j++; // 如果匹配成功则继续匹配主串子串下一位} else {i = ++k; // 否则主串回到起始匹配的下一位重新匹配j = 0; // 子串回到首位}}if (j == s2.length)return k + 1; // 匹配成功返回在主串中下标,起始下标1return 0; // 匹配不成功返回0}public static void main(String[] args) {String str1 = "aabcabc";String str2 = "abca";String str3 = "abd";System.out.println(BF(str1, str2)); // 打印2System.out.println(BF(str1, str3)); // 打印0}
}
空间复杂度
设主串长度n,字串长度m,主串子串的起始位置都是1:
- 最好情况下,每趟不成功的匹配都发生在子串的第一个字符和主串字符的比较,假设从主串的第 i个位置匹配成功,则前面比较了 i-1次;第 i次成功匹配的比较次数是m,总的比较次数 i-1+m;对于成功匹配的子串,其在主串的起始位置1~(n-m+1),假设每个位置上的匹配成功概率相等,则匹配成功的平均比较次数为: ∑ i = 1 n − m + 1 p i ( i − 1 + m ) = 1 n − m + 1 ∑ i = 1 n − m + 1 i − 1 + m = 1 2 ( n + m ) \sum_{i=1}^{n-m+1}{p_i}{(i-1+m)} = \frac{1}{n-m+1} \sum_{i=1}^{n-m+1}{i-1+m} = \frac 1 2 (n+m) i=1∑n−m+1pi(i−1+m)=n−m+11i=1∑n−m+1i−1+m=21(n+m)即最好情况下平均时间复杂度 O ( n + m ) Ο(n+m) O(n+m)。
- 最坏情况下,每趟不成功的匹配都发生在子串的最后一个字符与主串字符的比较,假设从主串的第 i个位置匹配成功,则在前 i-1趟中比较了(i-1) x m次,第 i趟成功匹配的比较次数m,则总的比较次数 i x m,同样对于成功匹配的子串,其在主串的起始位置1~(n-m+1),假设每个位置上的匹配成功概率相等,则匹配成功的平均比较次数为: ∑ i = 1 n − m + 1 p i ( i ∗ m ) = 1 n − m + 1 ∑ i = 1 n − m + 1 i ∗ m = 1 2 m ( n − m + 2 ) \sum_{i=1}^{n-m+1}{p_i}{(i*m)} = \frac{1}{n-m+1} \sum_{i=1}^{n-m+1}{i*m} = \frac 1 2 m (n-m+2) i=1∑n−m+1pi(i∗m)=n−m+11i=1∑n−m+1i∗m=21m(n−m+2)一般 n ≫ m n \gg m n≫m,所以最坏情况平均时间复杂度 O ( n ∗ m ) Ο(n*m) O(n∗m)。
BF算法虽然简单直观,但因匹配失败时主串的指针总是回到本次起始比较位置的下一个位置,子串指针回到首位置重新比较,所以算法时间复杂度较高。KMP算法对此进行了优化。
KMP算法
描述: 该算法由Knuth、Morris和pratt共同提出,所以简称KMP。KMP与BF非常相似,唯一区别就是每次发生不匹配时主串指针不回溯,子串指针调整到合适位置再和主串比较。那什么是合适的位置,比如下图:

为方便描述主串子串都从1开始进行编号,当主串位置6处B与子串位置6处A不匹配时,BF的做法是主串回到第二位也就是B,与子串的首位A重新比较,但KMP的做法是,主串指针不回溯,即仍然指向第6位B,将子串向后移动三个位置,移动后的位置:

为什么要移动到这个位置而不是其它位置?这正是KMP的长处所在,即利用了子串不匹配处以前的“部分匹配”信息,也就是说当子串第6位开始与主串不匹配时,那么子串的前5位与主串一定是匹配的。那么可以让子串向后滑动一段距离,尽可能长的使子串重新比较的位置之前的所有字符与主串匹配,这样便省去了前面的重复比较而直接与主串不匹配位置比较,为不匹配位置寻找到一次匹配成功的机会,这里就要引入最长公共前后缀的概念:
字符串:ABBABA
前缀:{A,AB,ABB,ABBA,ABBAB},含头不含尾
后缀:{A,BA,ABA,BABA,BBABA},含尾不含头
最长公共前后缀:二者交集中长度最大的元素,本例是A
可见,当子串某个位置与主串发生不匹配时,子串应该向后滑动的距离与该位置前字符串的最长公共前后缀长度有关;同样可以看出,最长公共前后缀与主串无关,只取决于子串。 因此,可以事先将子串每个位置对应的最长公共前后缀长度求出来制成一张表,在某个位置与主串发生不匹配时供程序查询调用,这个表的名字就叫做next数组。
next数组
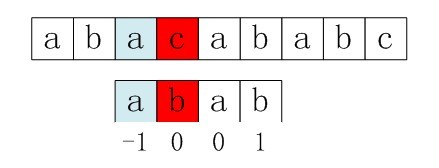
要理解next数组,最好从一个被称为部分匹配表(Partial Match Table)的数组说起。对于字符串“abababca”,它的PMT值如下表所示:
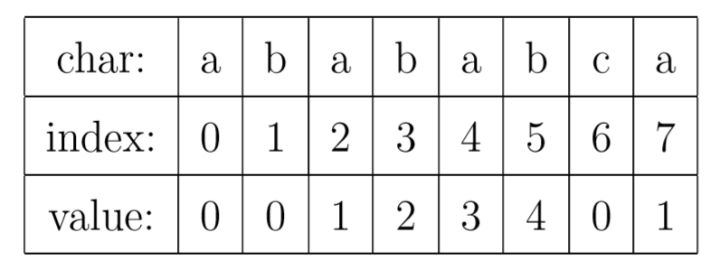
就像例子中所示的,如果字符串有8个字符,那么PMT就会有8个值。根据前面的最长公共前后缀定义可以看出,PMT中的值是字符串的前缀集合与后缀集合的交集中最长元素的长度。 例如对于字符串aba,最长公共前后缀长度为1,所以在PMT表中对应的值就是1。再比如对于字符串ababa,最长公共前后缀长度为3,所以在PMT表中对应的值就是3。
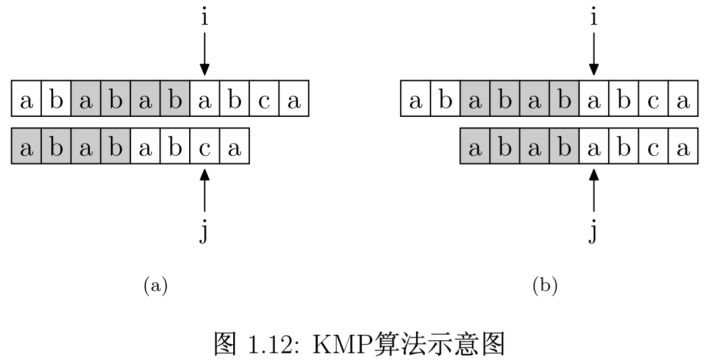
知道了这个表是什么之后,再来看如何使用这个表来加速字符串的查找,以及这样用的道理是什么。如图 1.12 所示,要在主串"ababababca"中查找子串"abababca"。如果在 j 处字符不匹配,那么子串与主串中 i, j 指针的前6位字符串一定是相同的,该字符串的前4位前缀和后4位后缀是相同的,所以我们推知主串i之前的4位和子串开头的4位是相同的,就是图中的灰色部分,那这部分就不用再比较了。这样一来,我们就可以将这些字符段的比较省略掉。具体的做法是,保持 i 指针不动,然后将 j 指针指向子串的PMT[j −1]位即可。
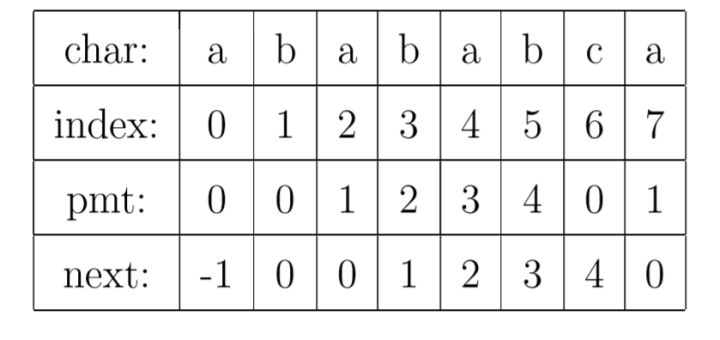
有了上面的思路,我们就可以使用PMT加速字符串的查找了。可以看到如果是在 j 位失配,那么影响 j 指针回溯的位置的其实是第 j −1 位的 PMT 值,所以为了编程方便,并不直接使用PMT数组,而是将PMT数组向后偏移一位,把新得到的这个数组称为next数组。其中要注意的一个技巧是,在把PMT进行向右偏移时,第0位的值将其设成了-1,这只是为了编程的方便,并没有其它意义。在本例中,next数组如下表所示:
有了这个next数组,便可以写出KMP主体代码
public static int KMP(String str1, String str2) {char[] s1 = str1.toCharArray();char[] s2 = str2.toCharArray();int i = 0, j = 0;while (i < s1.length && j < s2.length) {if (j == -1 || s1[i] == s2[j]) {i++;j++;} else {j = next[j];}}if (j == s2.length)return i - j + 1; // 匹配成功返回在主串中下标,起始下标1return 0; // 匹配失败返回0
}
到这KMP主体部分已经完成。
现在要解决的问题是,如何通过程序快速求得next数组,这个问题也是KMP的难点所在。
从上面知道,next数组是由部分匹配表PMT的数组整体右移一位得到,那么由PMT中值的含义可以看出,对于下标 j 处 next[ j ] 的值其实就是下标 0~j-1 的串的最长公共前后缀长度。其实,求next数组的过程可以看成模式串也就是子串与自身匹配的过程,即以模式串为主字符串,以模式串的前缀为子字符串。具体来说,就是从模式串的第一位(注意,不包括第0位)开始对自身进行匹配运算,在任一位置能匹配到的最大长度其实就是相邻下个位置的next值,如下图所示:





前面知道next[0]处值为了编程方便设为-1,又由最长公共前后缀长度的定义知道next[1]=0,在指针 i 与指针 j 所指字符匹配的过程中,可能出现两种情况:
(1) 匹配成功,则说明next[i+1]=j+1,执行next[i++]=j++;
(2) 匹配失败,则循环的将next[j]的值赋给 j,使子串的前缀尽可能少的回退(这样才能找出最长公共前后缀);直到满足情况(1)或者 j=0。
这里有一个小技巧,当 j=0时,i, j 所指字符还要再比较一次才能确定next[i+1]值是0还是1,很显然当相同时回到情况(1),对应的执行next[i+1]=0+1=1符合情况,当不相同时就要用到这个技巧,即同样将next[j]的值赋给 j,也就是 j=next[0]=-1,此时将 j=-1也作为(1)中next[i++]=j++的循环入口,则正好符合next[i+1]=0。
将以上描述写成代码
private static int[] getNext(String str) {char[] s = str.toCharArray();int[] next = new int[s.length];next[0] = -1;int i = 0, j = -1;while (i < s.length - 1) { if (j == -1 || s[i] == s[j]) {i++;j++;next[i] = j;} else {j = next[j];}}return next;
}
完整KMP代码
public class MatchKMP {private static int[] getNext(String str) {char[] s = str.toCharArray();int[] next = new int[s.length];next[0] = -1;int i = 0, j = -1;while (i < s.length - 1) {if (j == -1 || s[i] == s[j]) {i++;j++;next[i] = j;} else {j = next[j];}}return next;}public static int KMP(String str1, String str2) {int[] next = getNext(str2);char[] s1 = str1.toCharArray();char[] s2 = str2.toCharArray();int i = 0, j = 0;while (i < s1.length && j < s2.length) {if (j == -1 || s1[i] == s2[j]) {i++;j++;} else {j = next[j];}}if (j == s2.length)return i - j + 1; // 匹配成功返回在主串中下标,起始下标1return 0; // 匹配失败返回0}public static void main(String[] args) {String str1 = "abcabcabd";String str2 = "abd";System.out.println(KMP(str1, str2)); // 打印7}
}
KMP优化
KMP优化实际就是对next数组优化。比如,如果用之前的next数组方法求模式串“abab”的next数组,可得其next数组为-1 0 0 1,当它跟下图中的文本串去匹配的时候,发现b跟c失配,于是 j 指针回溯,j=next[3] = 1。
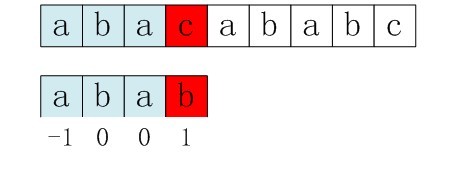
指针 j 回溯后,b又跟c失配。事实上,因为在上一步的匹配中,已经得知s2[3] = b,与s1[3] = c失配,而回溯后,让s2[ next[3] ] = s2[1] = b 再跟s1[3]匹配时,必然失配。问题出在哪呢?
问题出在不该出现s2[j] = s2[ next[j] ]。为什么呢?理由是:当s2[j] != s1[i] 时,下次匹配必然是s2[ next [j]] 跟s1[i]匹配,如果s2[j] = s2[ next[j] ],必然导致后一步匹配失败(因为s2[j]已经跟s1[i]失配,然后还用跟s2[j]等同的值s2[next[j]]去跟s1[i]匹配,很显然必然失配),所以不能允许s2[j] = s2[ next[j] ]。如果出现了咋办呢?如果出现了,则需要再次递归,即令next[j] = next[ next[j] ]。
优化后的next数组代码
private static int[] getNextVal(String str) {char[] s = str.toCharArray();int[] next = new int[s.length];next[0] = -1;int i = 0, j = -1;while (i < s.length - 1) {if (j == -1 || s[i] == s[j]) {i++;j++;if (s[i] != s[j])next[i] = j;else// 这句可能有人会有疑惑,其实这里只是将上面描述的递归以迭代形式表示next[i] = next[j]; } else {j = next[j];}}return next;
}
总结
- KMP算法时间复杂度 O ( n + m ) Ο(n+m) O(n+m),其中n,m为主串与模式串的长度,时间复杂度根据摊还分析得出,看了下没太弄明白,明白后补上。
- 虽然BF算法最坏时间复杂度 O ( n ∗ m ) Ο(n*m) O(n∗m),但一般情况下实际的执行时间近似 O ( n + m ) Ο(n+m) O(n+m)。
- KMP算法仅当模式串与主串之间存在许多“部分匹配”的情况下,才显得比BF算法快得多。
- KMP算法因主串指针不用回溯,可以边读入边匹配,所以对处理从外部设备输入的庞大文件很有优势。
- KMP中的next数组部分引用了知乎中的内容。