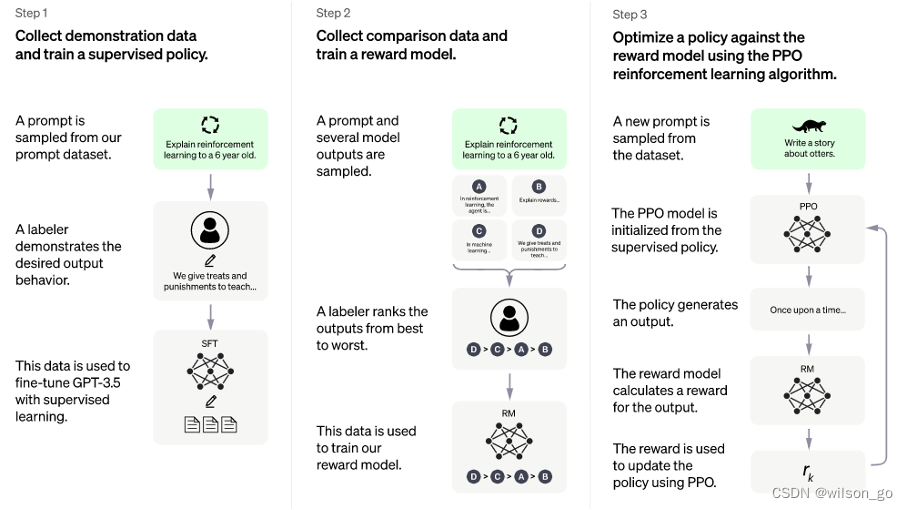
一次利用 ChatGPT 给出数据抓取代码,借助 NebulaGraph 图数据库与图算法预测体坛赛事的尝试。
作者:古思为
蹭 ChatGPT 热度
最近因为世界杯正在进行,我受到这篇 Cambridge Intelligence 的文章启发(在这篇文章中,作者仅仅利用有限的信息量和条件,借助图算法的方法做出了合理的冠军预测),想到可以试着用图数据库 NebulaGraph 玩玩冠军预测,还能顺道科普一波图库技术和图算法。
本来想着几个小时撸出来一个方案,但很快被数据集的收集工作劝退了,我是实在懒得去「FIFA 2022 的百科」抓取所需的数据,索性就搁浅、放了几天。
同时,另一个热潮是上周五 OpenAI 发布了 ChatGPT 服务,它可以实现各种语言编码。ChatGPT 可实现的复杂任务设计包括:
- 随时帮你实现一段指定需求的代码
- 模拟任意一个 prompt 界面:Shell、Python、Virtual Machine、甚至你创造的语言
- 带入给定的人设,和你聊天
- 写诗歌、rap、散文
- 找出一段代码的 bug
- 解释一段复杂的正则表达式的含义
ChatGPT 的上下文联想力和理解力到了前所未有的程度,以至于所有接触它的人都在讨论新的工作方式:如何掌握让机器帮助我们完成特定任务。
所以,当我试过让 ChatGPT 帮我写复杂的图数据库查询语句、解释复杂图查询语句的含义、解释一大段 Bison 代码含义之后,我突然意识到:为什么不让 ChatGPT 帮我写好抓取数据的代码呢?
抓取世界杯数据
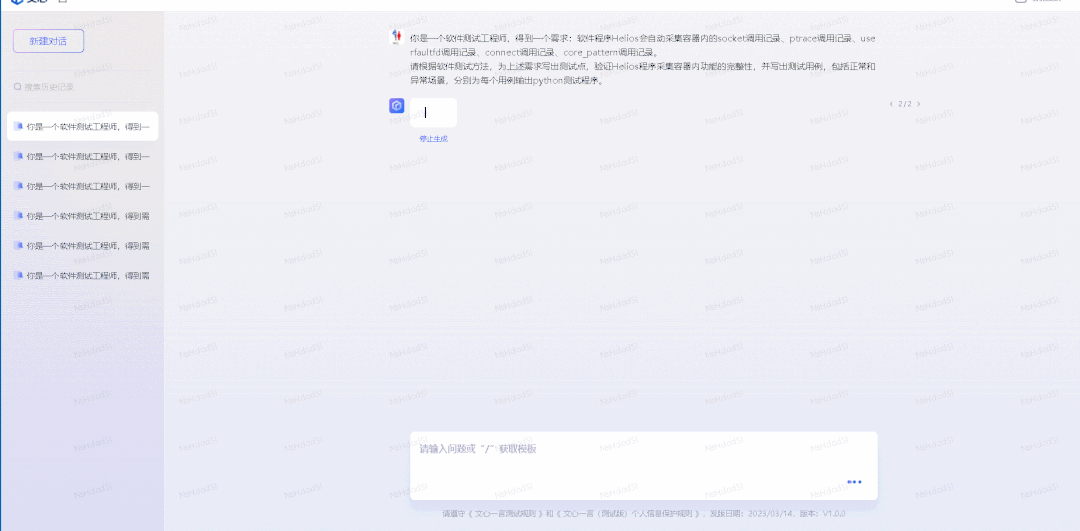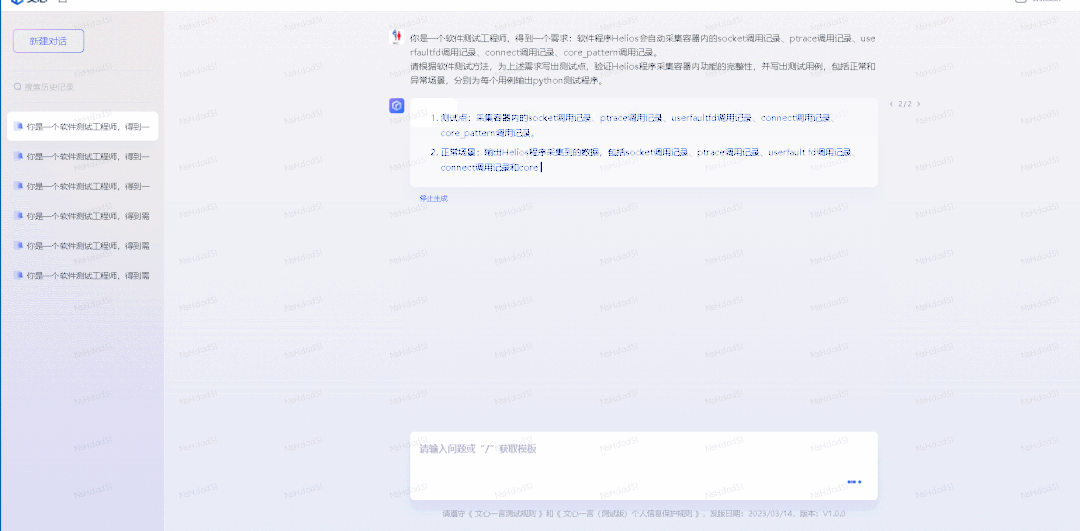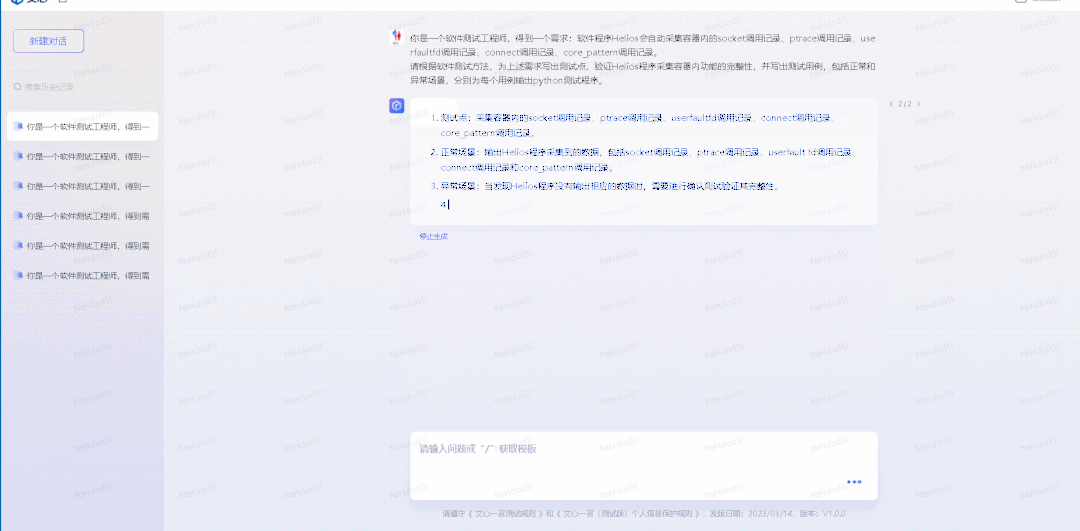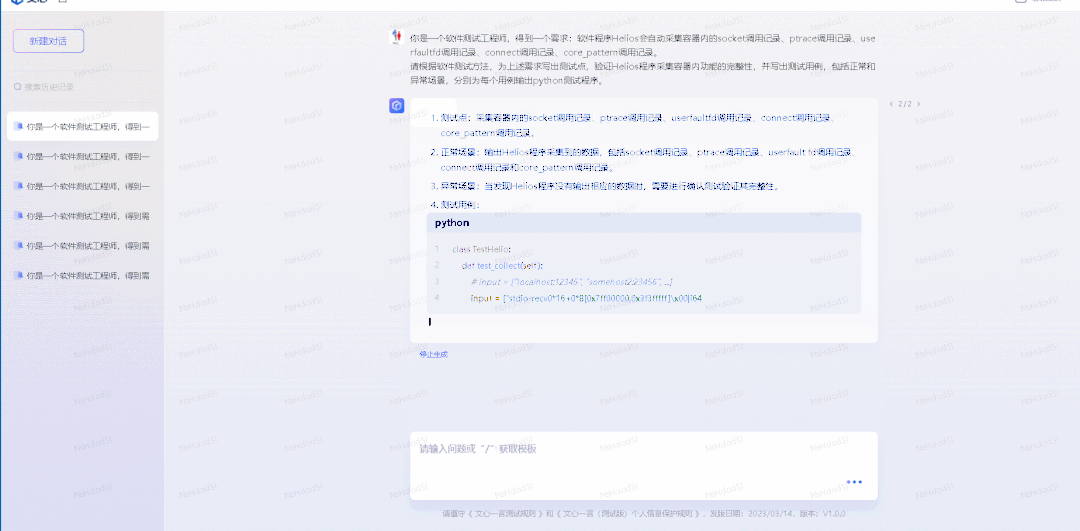
我真试了下 ChatGPT,结果是:完全可以,而且似乎真的很容易。
整个实现过程,基本上我像是一个代码考试的面试官,或是一个产品经理,提出我的需求,ChatGPT 给出具体的代码实现。我再试着运行代码,找到代码中不合理的地方,指出来并给出建议,ChatGPT 真的能理解我指出的点,并给出相应的修正,像是:
这一全过程我就不在这里列出来了,不过我把生成的代码和整个讨论的过程都分享在这里,感兴趣的同学可以去看看。
最终生成的数据是一个 CSV 文件:
- 代码生成的文件 world_cup_squads.csv
- 手动修改、分开了生日和年龄的列 world_cup_squads_v0.csv
上面的数据集包含的信息有:球队、小组、编号、位置、球员名字、生日、年龄、参加国际比赛场次、进球数、服役俱乐部。
Team,Group,No.,Pos.,Player,DOB,Age,Caps,Goals,Club
Ecuador,A,1,1GK,Hernán Galíndez,(1987-03-30)30 March 1987,35,12,0,Aucas
Ecuador,A,2,2DF,Félix Torres,(1997-01-11)11 January 1997,25,17,2,Santos Laguna
Ecuador,A,3,2DF,Piero Hincapié,(2002-01-09)9 January 2002,20,21,1,Bayer Leverkusen
Ecuador,A,4,2DF,Robert Arboleda,(1991-10-22)22 October 1991,31,33,2,São Paulo
Ecuador,A,5,3MF,José Cifuentes,(1999-03-12)12 March 1999,23,11,0,Los Angeles FC
这是手动删除了 CSV 表头的数据集 world_cup_squads_no_headers.csv。
图方法预测 2022 世界杯
图建模
本文用到了图数据库 NebulaGraph 和可视化图探索工具 NebulaGraph Explorer,你可以在阿里云免费申请半个月的试用。
图建模(Graph Modeling)是把真实世界信息以”点–>边“的图形式去抽象与表示。
这里,我们把在公共领域获得的信息映射成如下的点与边:
点:
- player(球员)
- team(球队)
- group(小组)
- club(俱乐部)
边:
- groupedin(球队属于哪一小组)
- belongto(队员属于国家队)
- serve(队员在俱乐部服役)
而队员的年龄、参加国际场次(caps)、进球数(goals)则很自然作为 player 这一类点的属性。
下图是这个 schema 在 NebulaGraph Studio/Explorer(后边称 Studio/Explorer) 中的截图:
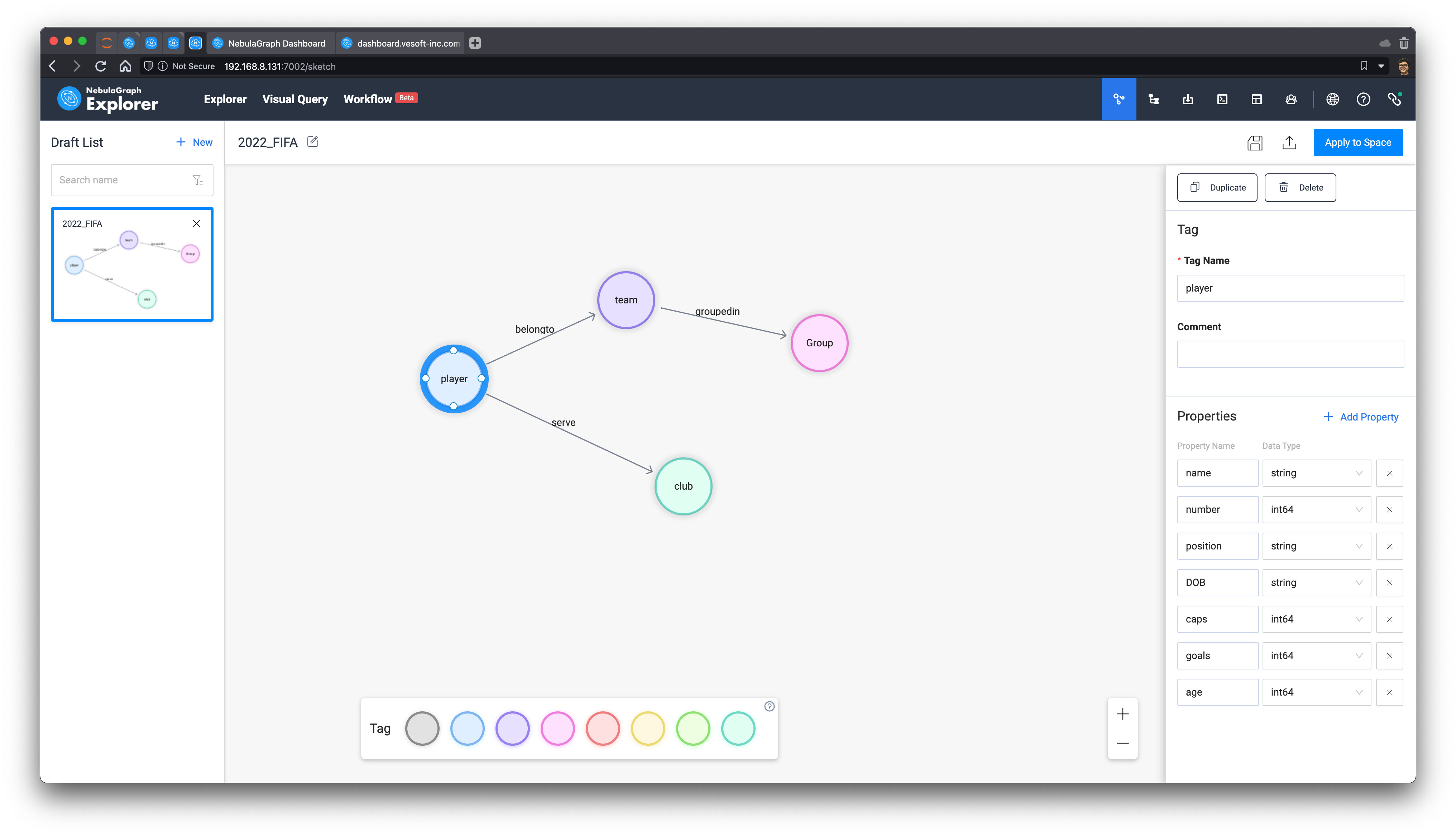
我们点击右上角的保存后,便能创建一个新的图空间,将这个图建模应用到图空间里。
这里可以参考下 Explore 草图的文档:https://docs.nebula-graph.com.cn/3.3.0/nebula-explorer/db-management/draft/
导入数据进 NebulaGraph
有了图建模,我们可以把之前的 CSV 文件(无表头版本)上传到 Studio 或者 Explorer 里,通过点、选关联不同的列到点边中的 vid 和属性:
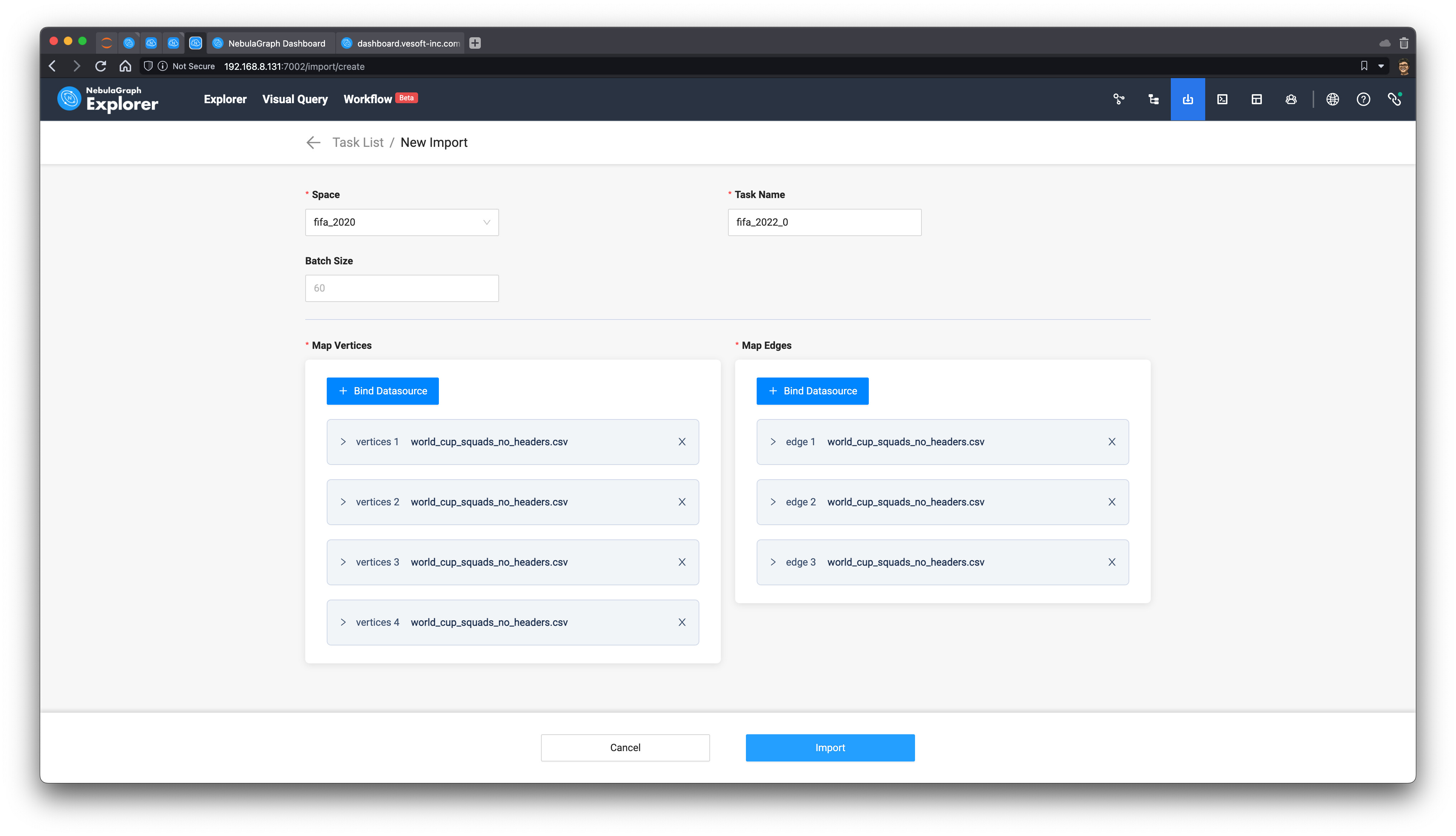
完成关联之后,点击导入,就能把整个图导入到 NebulaGraph。成功之后,我们还得到了整个 csv --> Nebula Importer 的关联配置文件:nebula_importer_config_fifa.yml,你可以直接拖拽整个配置,不用自己去配置它了。
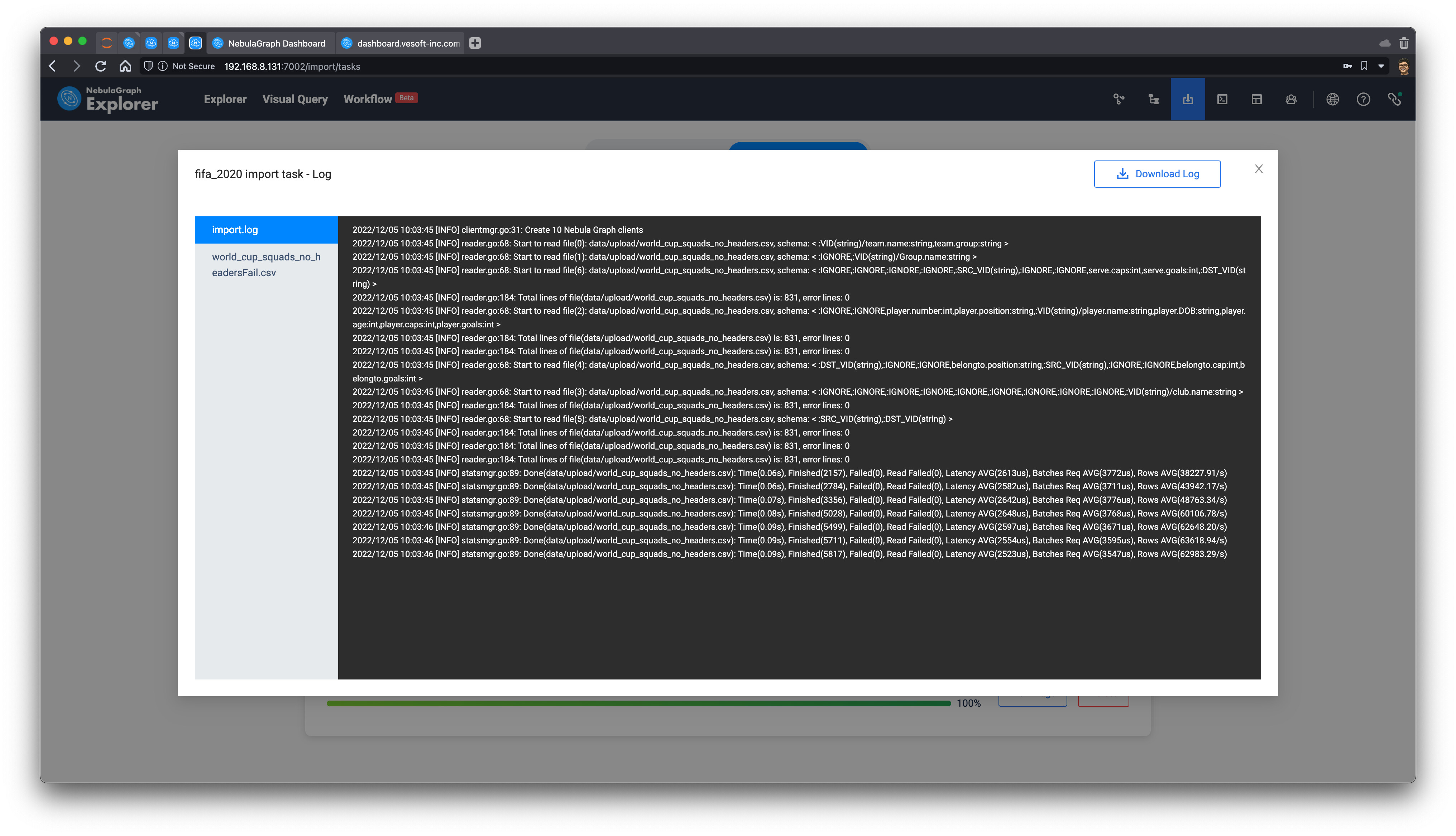
这里可以参考 Explorer 数据导入的文档:https://docs.nebula-graph.com.cn/3.3.0/nebula-explorer/db-management/11.import-data/
数据导入后,我们可以在 schema 界面查看数据统计。可以看到,有 831 名球员参加了 2022 卡塔尔世界杯,他们服役在 295 个不同的俱乐部:

这里我们用到了 Explorer 的 schema 创建的文档:https://docs.nebula-graph.com.cn/3.3.0/nebula-explorer/db-management/10.create-schema/#_6
探索数据
查询数据
下面,我们试着把所有的数据展示出来看看。
首先,借助 NebulaGraph Explorer,我用拖拽的方式画出了任意类型的点(TAG)和任意类型点(TAG)之间的边。这里,我们知道所有的点都包含在至少一个边里,所以不会漏掉任何孤立的点。
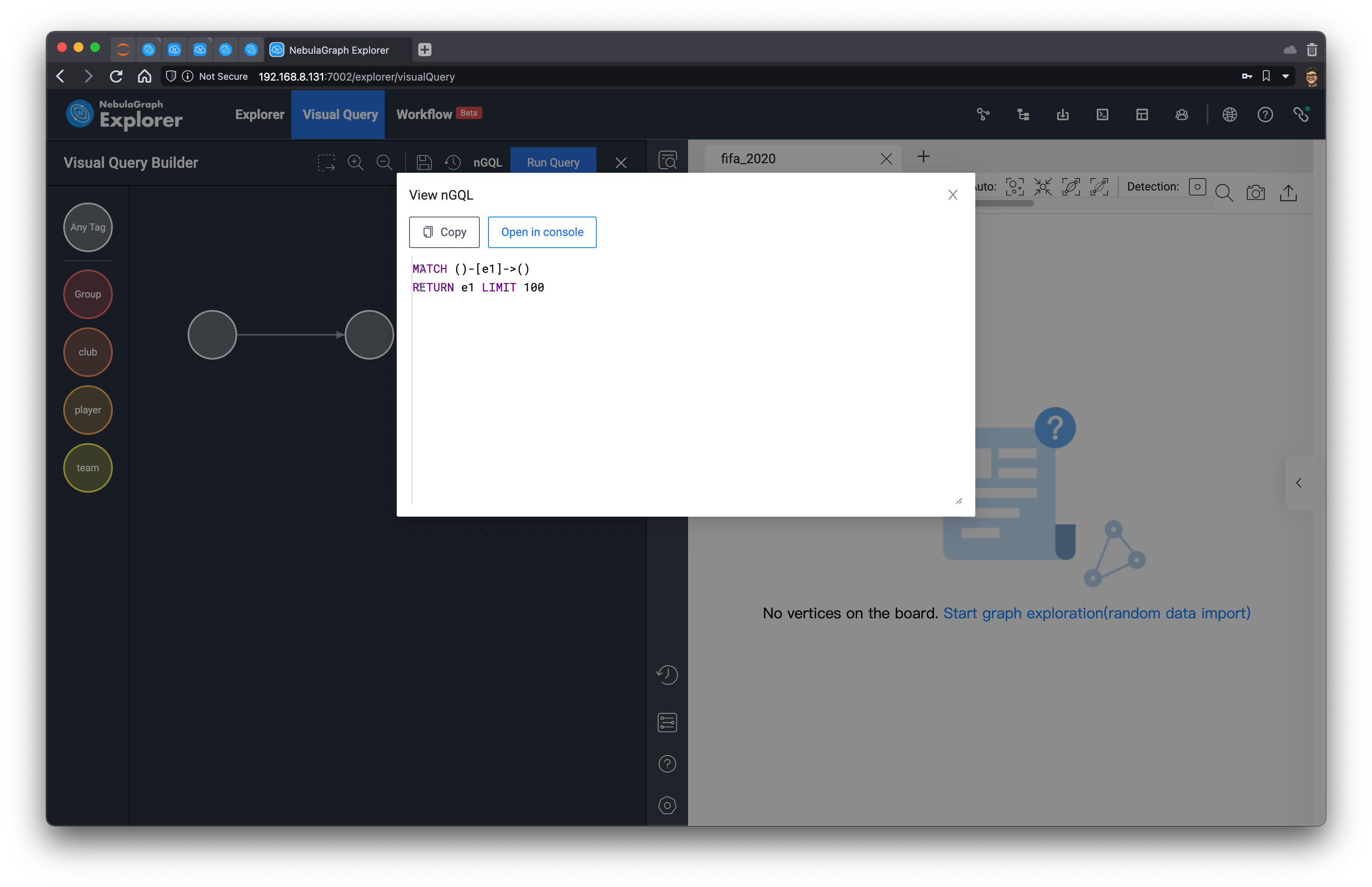
让 Explorer 它帮我生成查询的语句。这里,它默认返回 100 条数据(LIMIT 100),我们手动改大一些,将 LIMIT 后面的参数改到 10000,并让它在 Console 里执行。
初步观察数据
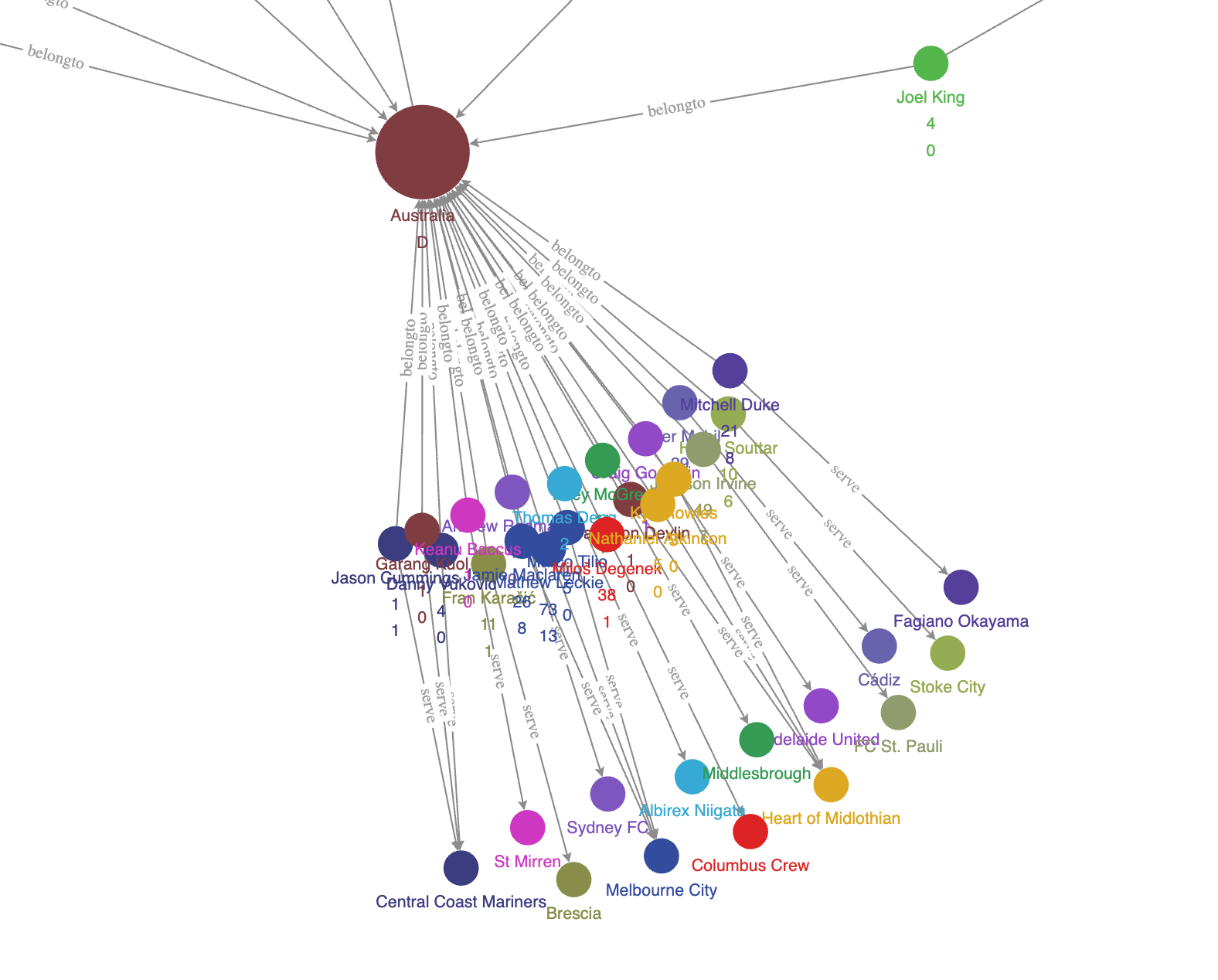
结果渲染出来是这样子,可以看到结果自然而然地变成一簇簇的模式。
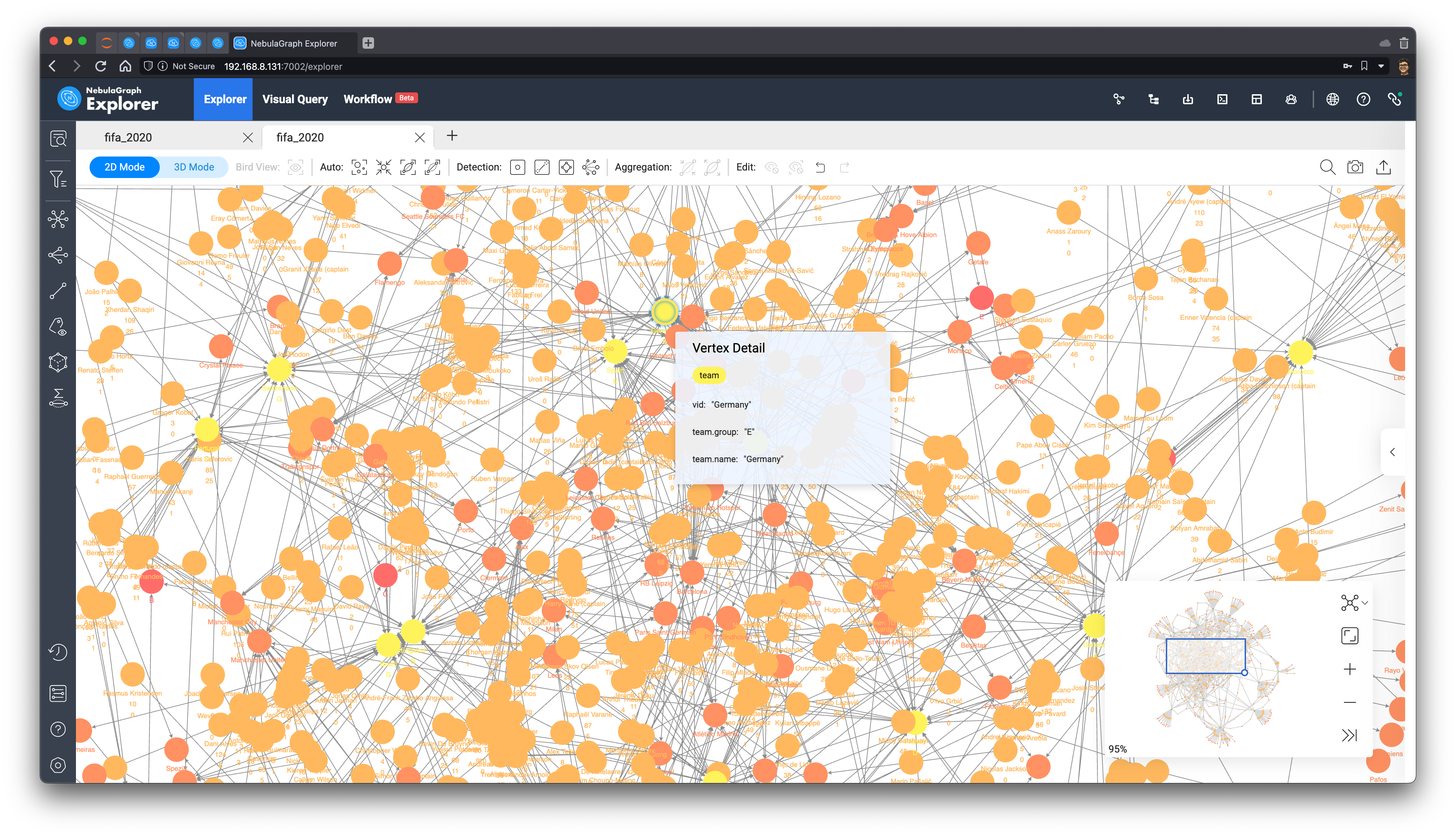
这些外围、形成的簇多是由不怎么知名的足球俱乐部,和不怎么厉害的国家队的球员组成,因为通常这些俱乐部只有一两个球员参加世界杯,而且他们还集中在一个国家队、地区,所以没有和很多其他球员、国家队产生连接。
图算法辅助分析
在我点击了 Explorer 中的两个按钮之后(详细参考后边的文档链接),在浏览器里,我们可以看到整个图已经变成:

这里可以参考 Explorer 的图算法文档:https://docs.nebula-graph.com.cn/3.3.0/nebula-explorer/graph-explorer/graph-algorithm/
其实,Explorer 这里利用到了两个图算法来分析这里的洞察:
- 利用点的出入度,改变它们的显示大小突出重要程度
- 利用 Louvain 算法区分点的社区分割
可以看到红色的大点是鼎鼎大名的巴塞罗那,而它的球员们也被红色标记了。
预测冠军算法
为了能充分利用图的魔法(与图上的隐含条件、信息),我的思路是选择一种利用连接进行节点重要程度分析的图算法,找出拥有更高重要性的点,对它们进行全局迭代、排序,从而获得前几名的国家队排名。
这些方法其实就体现了厉害的球员同时拥有更大的社区、连接度。同时,为了增加强队之间的区分度,我准备把出场率、进球数的信息也考虑进来。
最终,我的算法是:
- 取出所有的
(球员)-服役->(俱乐部)的关系,过滤其中进球数过少、单场进球过少的球员(以平衡部分弱队的老球员带来的过大影响) - 从过滤后的球员中向外探索,获得国家队
- 在以上的子图上运行 Betweenness Centrality 算法,计算节点重要度评分
算法过程
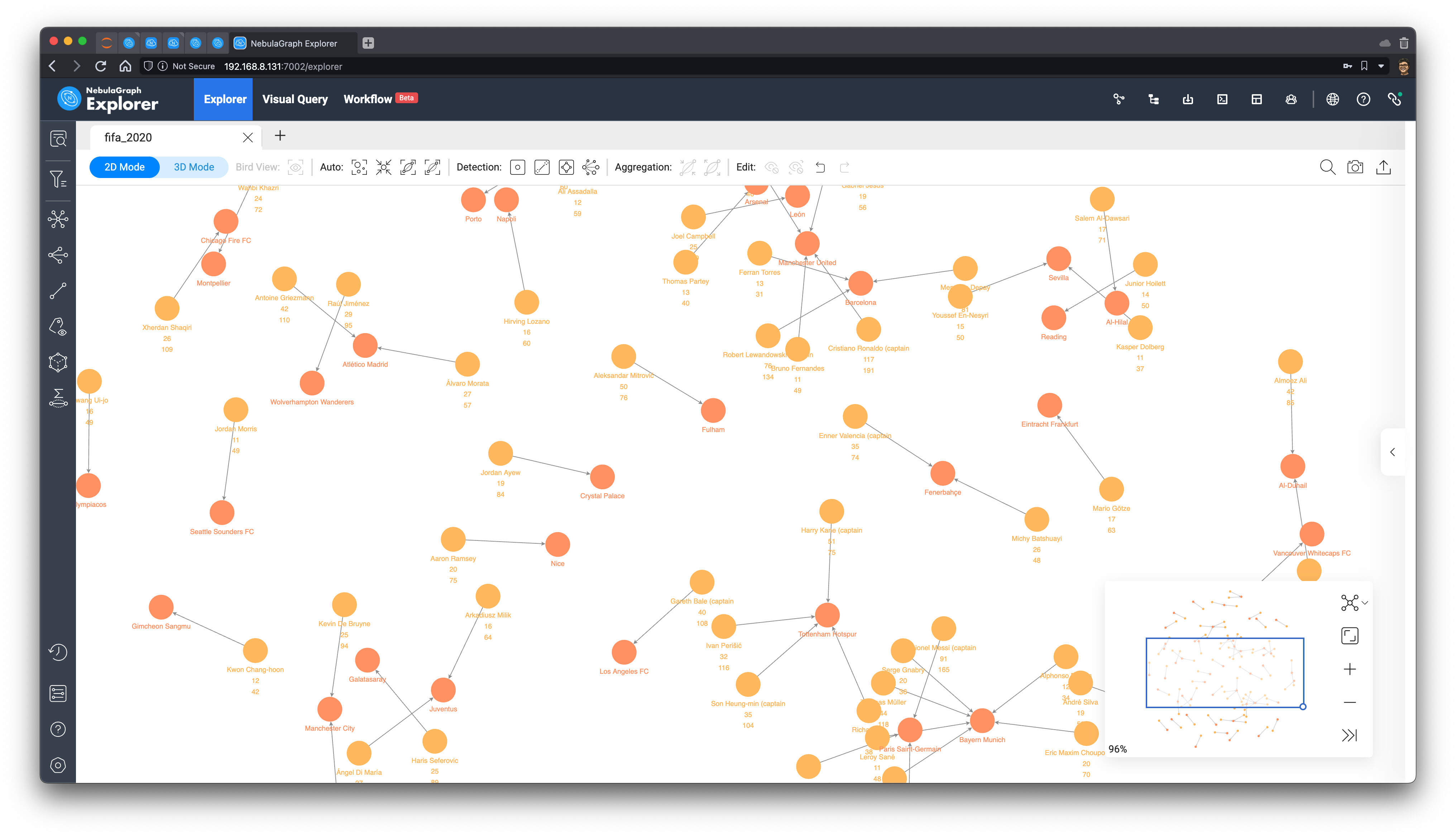
首先,我们取出所有进球数超过 10,场均进球超过 0.2 的 (球员)-服役->(俱乐部) 的子图:
MATCH ()-[e]->()
WITH e LIMIT 10000
WITH e AS e WHERE e.goals > 10 AND toFloat(e.goals)/e.caps > 0.2
RETURN e
为了方便,我把进球数和出场数也作为了 serve 边上的属性了。
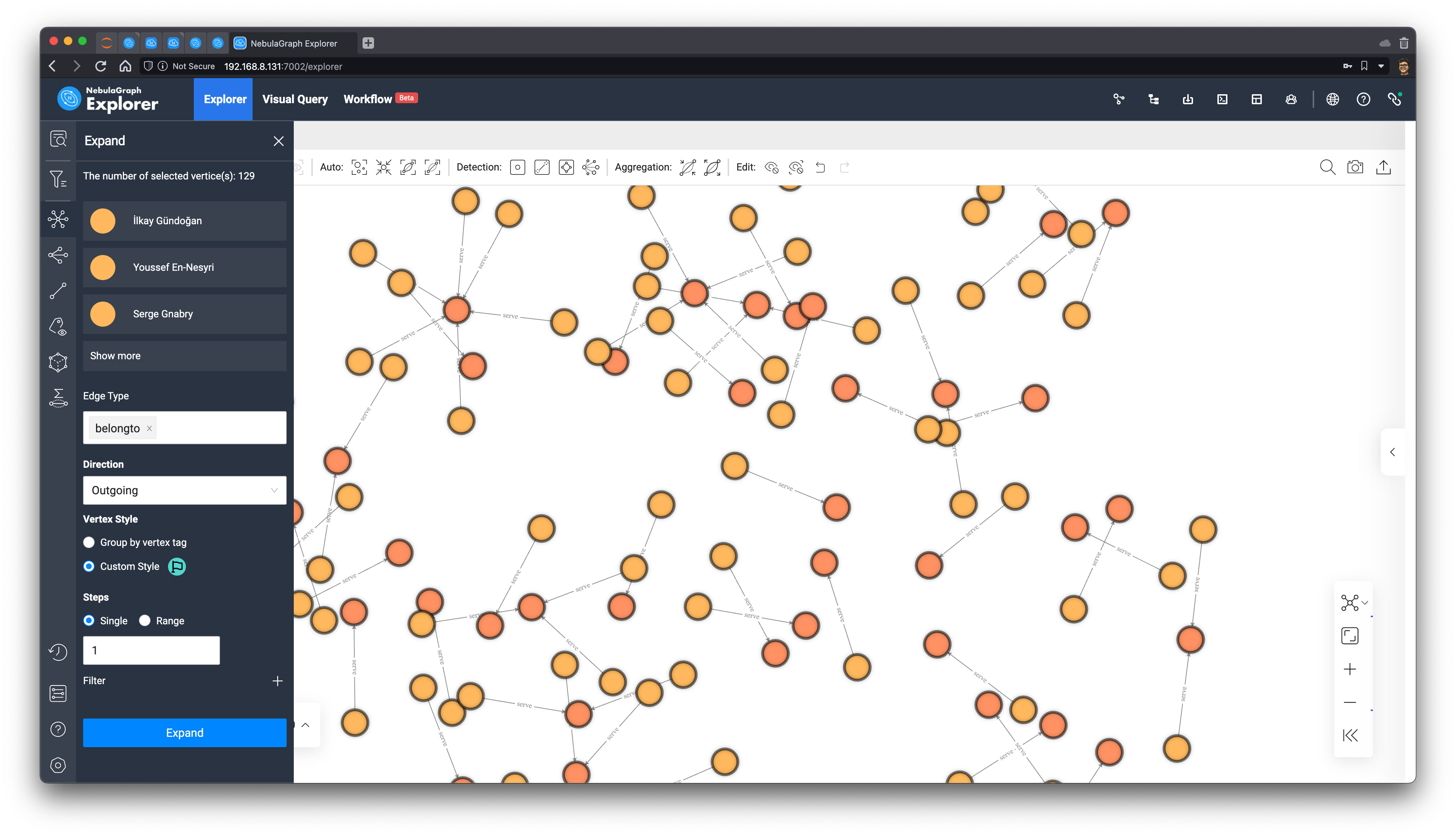
然后,我们全选图上的所有点,点击左边的工具栏,选择出方向的 belongto 边,向外进行图拓展(遍历),同时选择将拓展得到的新点标记为旗帜的 icon:
现在,我们获得了最终的子图,我们利用工具栏里的浏览器内的图算法功能,执行 BNC(Betweenness Centrality)
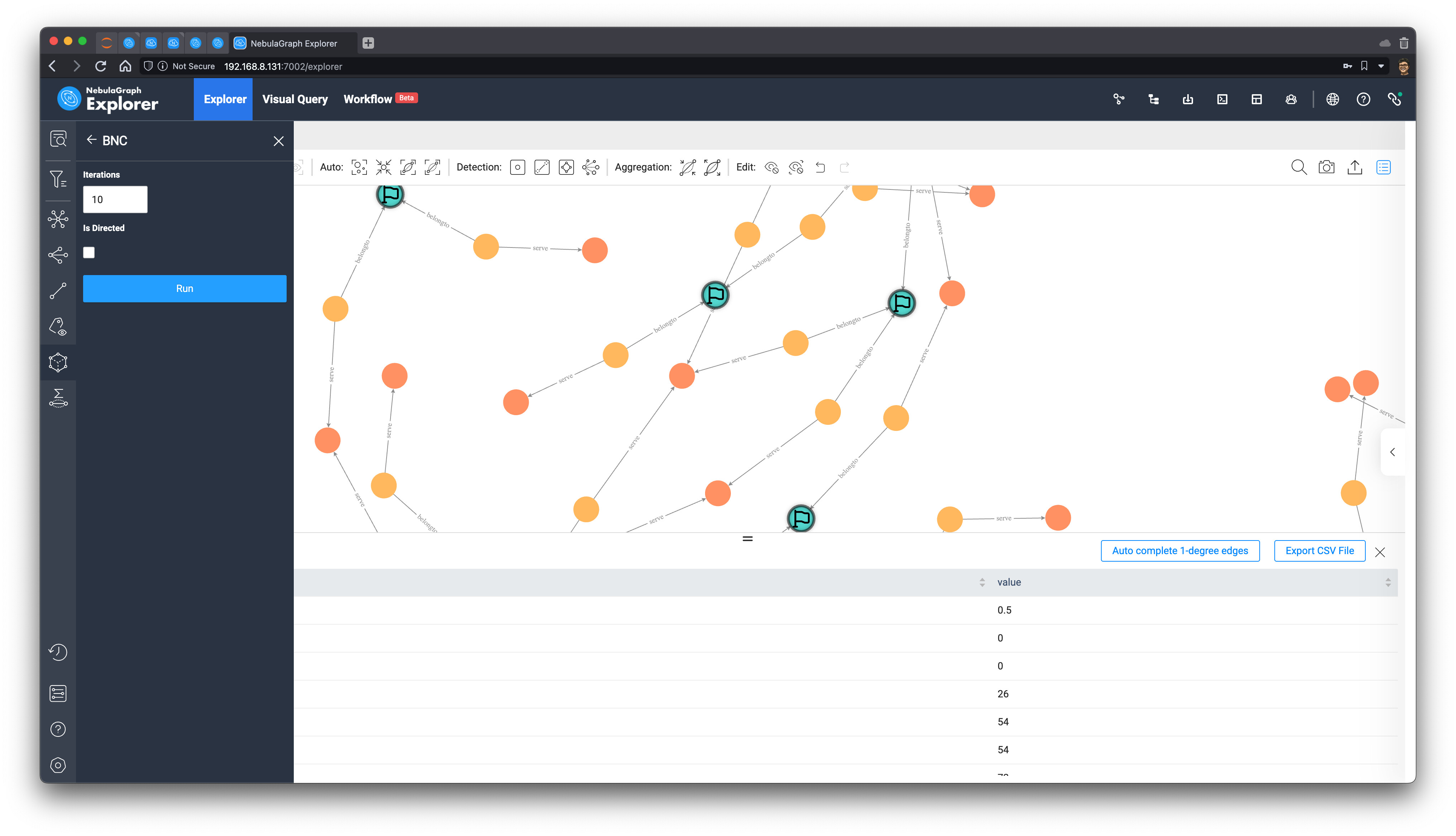
最后,这个子图变成了这样子:
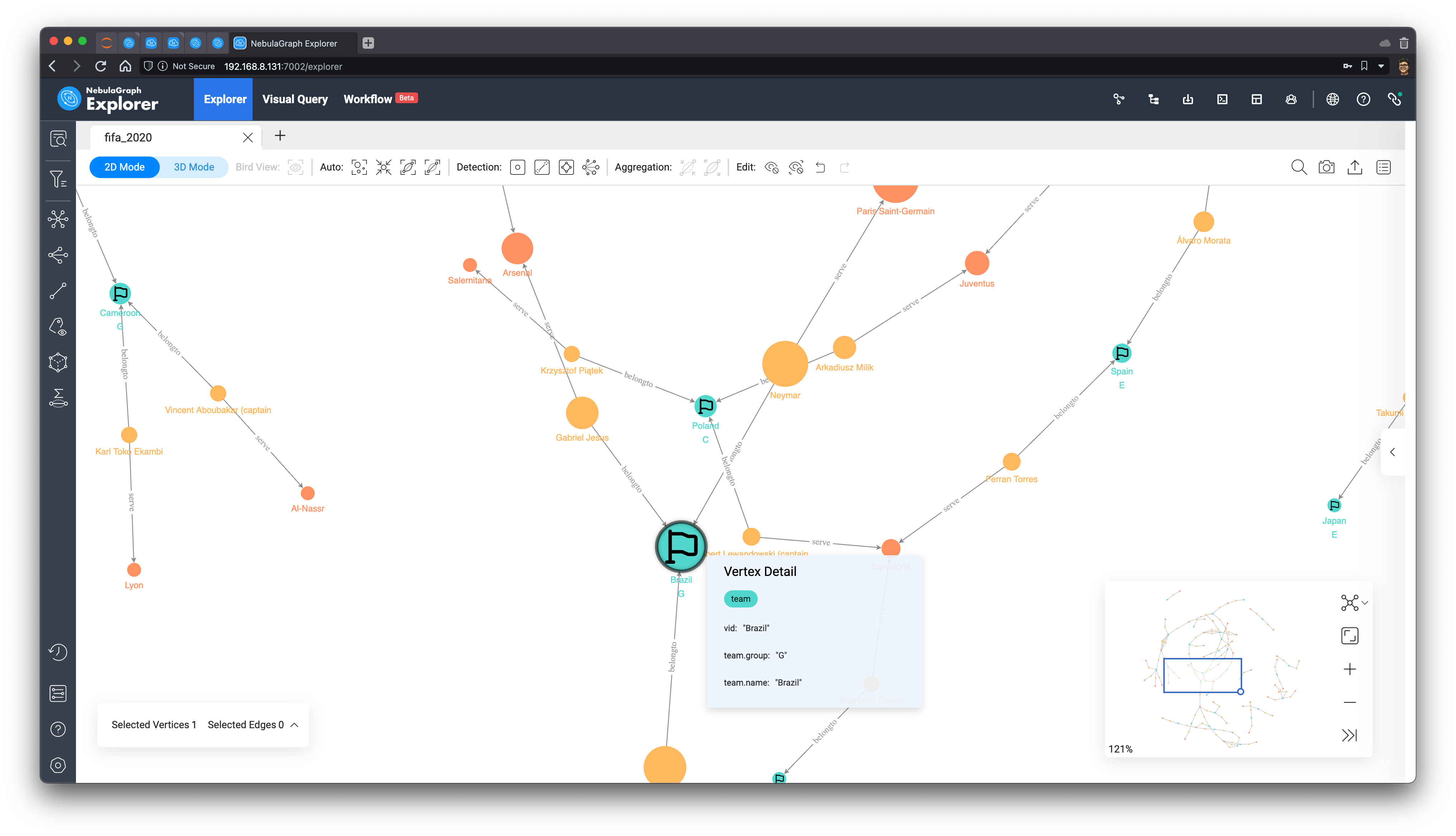
预测结果
最终,我们根据 Betweenness Centrality 的值排序,可以得到最终的获胜球队应该是:巴西 🇧🇷!
其次是比利时、德国、英格兰、法国、阿根廷,让我们等两个礼拜回来看看预测结果是否准确吧 😄。
注:排序数据(其中还有非参赛球队的点)
| Vertex | Betweenness Centrality |
|---|---|
| Brazil🇧🇷 | 3499 |
| Paris Saint-Germain | 3073.3333333333300 |
| Neymar | 3000 |
| Tottenham Hotspur | 2740 |
| Belgium🇧🇪 | 2587.833333333330 |
| Richarlison | 2541 |
| Kevin De Bruyne | 2184 |
| Manchester City | 2125 |
| İlkay Gündoğan | 2064 |
| Germany🇩🇪 | 2046 |
| Harry Kane (captain | 1869 |
| England🏴 | 1864 |
| France🇫🇷 | 1858.6666666666700 |
| Argentina🇦🇷 | 1834.6666666666700 |
| Bayern Munich | 1567 |
| Kylian Mbappé | 1535.3333333333300 |
| Lionel Messi (captain | 1535.3333333333300 |
| Gabriel Jesus | 1344 |
原文地址:https://discuss.nebula-graph.com.cn/t/topic/11584
谢谢你读完本文 (///▽///)