说明
最近遇到这么一个需求:统计区间在0-2000,2000-3000,3000-4000,4000-5000,5000+工资的人数。
快速开始
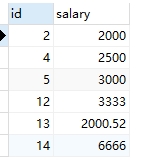
数据如下:
开始看到这个问题,想都没想就开始写了下面的代码:
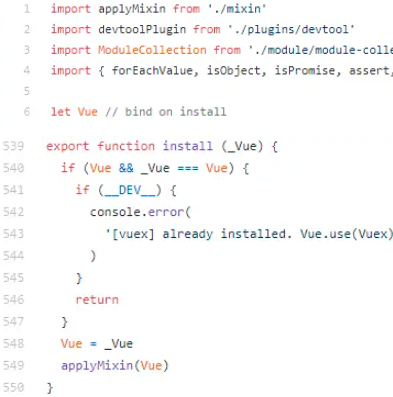
SELECT casewhen salary < 2000 then '[0, 2000)'when salary >= 2000 and salary < 3000 then '[2000, 3000)'when salary >= 3000 and salary < 4000 then '[3000, 4000)'when salary >= 4000 and salary < 5000 then '[4000, 5000)'when salary >= 5000 then '[5000+)'end c,COUNT(*)
FROM salary_list
GROUP BY c
执行结果:
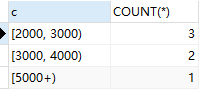
但其实我们要的结果是
[0,2000] 0
[2000,3000) 3
[3000,4000) 2
[4000,5000) 0
[5000+) 1
那么这个SQL不对啊!这个SQL把没有数据的组给吃了!所以我们得想办法将缺失的组补回来!
解决方案1(推荐)
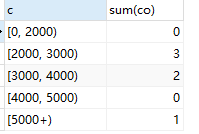
参考了sql 分组统计,数据为空时显示0,我将SQL改为了下面的
select c,sum(co)
from
(SELECT casewhen salary < 2000 then'[0, 2000)'when salary >= 2000 and salary < 3000 then'[2000, 3000)'when salary >= 3000 and salary < 4000 then'[3000, 4000)'when salary >= 4000 and salary < 5000 then'[4000, 5000)'when salary >= 5000 then'[5000+)'end c,COUNT(*) co
from salary_list
group by c
UNION SELECT '[0, 2000)' as c,'0' as co
UNION SELECT '[2000, 3000)' as c,'0' as co
UNION SELECT '[3000, 4000)' as c,'0' as co
UNION SELECT '[4000, 5000)' as c,'0' as co
UNION SELECT '[5000+)' as c,'0' as co) as temp
group by c分析:这个方法非常的巧妙,使用我们前面的方法分组后再 UNION(并集) 我们需要的组并将新加的数据记为0,然后再次使用group按照名称再次分组(得到分组为空的情况),然后再使用sum将我们之前计算的人数再+0就能得到我们所需要的结果
解决方案2(推荐)
SELECT count(case when salary <2000 then 1 end) as '[0, 2000)',count(case when salary >=2000 and salary <3000 then 1 end) as '[2000, 3000)',count(case when salary >=3000 and salary <4000 then 1 end) as '[3000, 4000)',count(case when salary >=4000 and salary <5000 then 1 end) as '[4000, 5000)',count(case when salary >=5000 then 1 end) as '[5000+)'
from salary_list分析:既然是group by导致的分组丢失,那不如自己写分组,也就是说在select count的时候在count里自己来写分组的条件(这种方法应该比较容易理解)
解决方案3(不推荐)
通过方案1得到的一种扩展性思维,我们也可以再创建一张临时表,包括所有的分组名称和统计值(记为0),然后将我们第一个SQL执行的结果和这张临时表进行left join或者right join连接起来(这个方案操作太麻烦,就不讨论了)