1.前期准备工作
各类软件以及工具包下载
2.网络环境配置
2.1 打开 VMware 找到编辑,点击虚拟网络配置
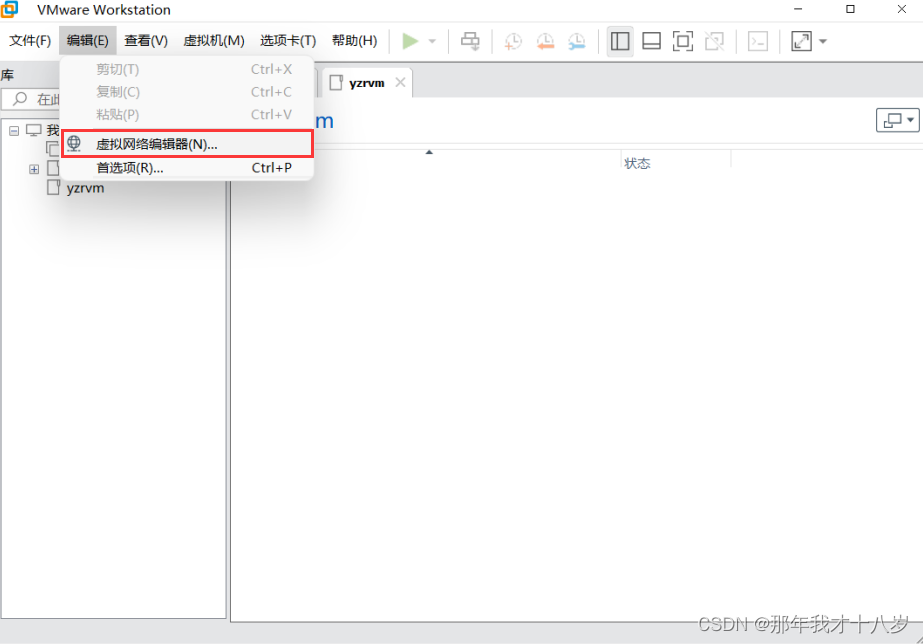
2.2 点击第二行,然后更改设置
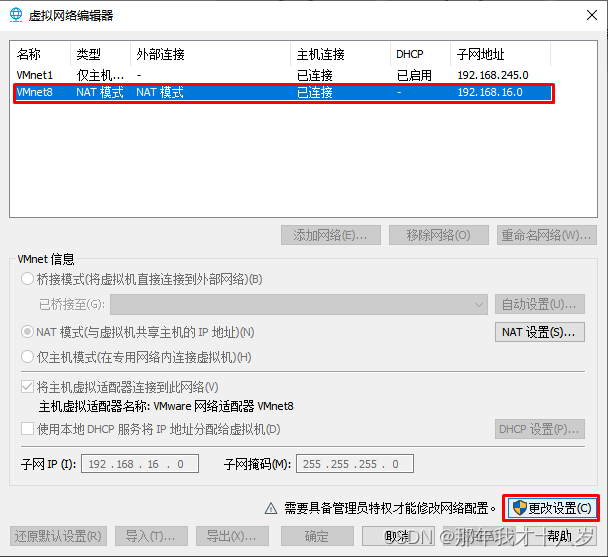
2.3 点击第三行VMnet8,把本地DHC服务将IP地址分配给虚拟机取消,配置子网,子网掩码,最后点击NAT设置
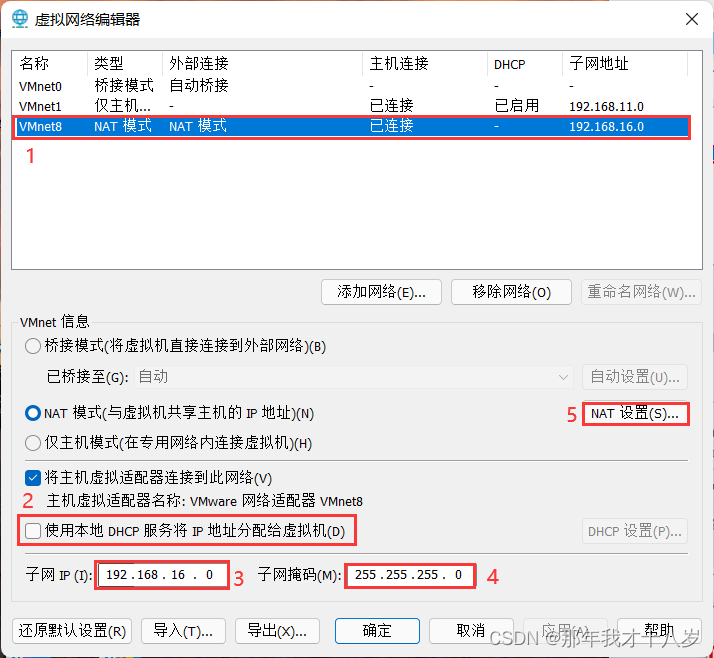
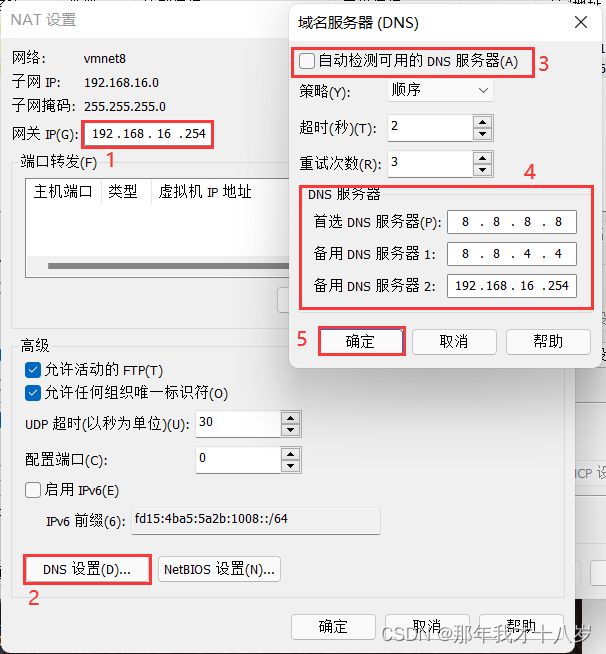
2.4 配置网关IP(记住你配置的IP地址),点击DNS设置,取消自动检测可用的DNS服务器,配置DNS服务器,最后确定
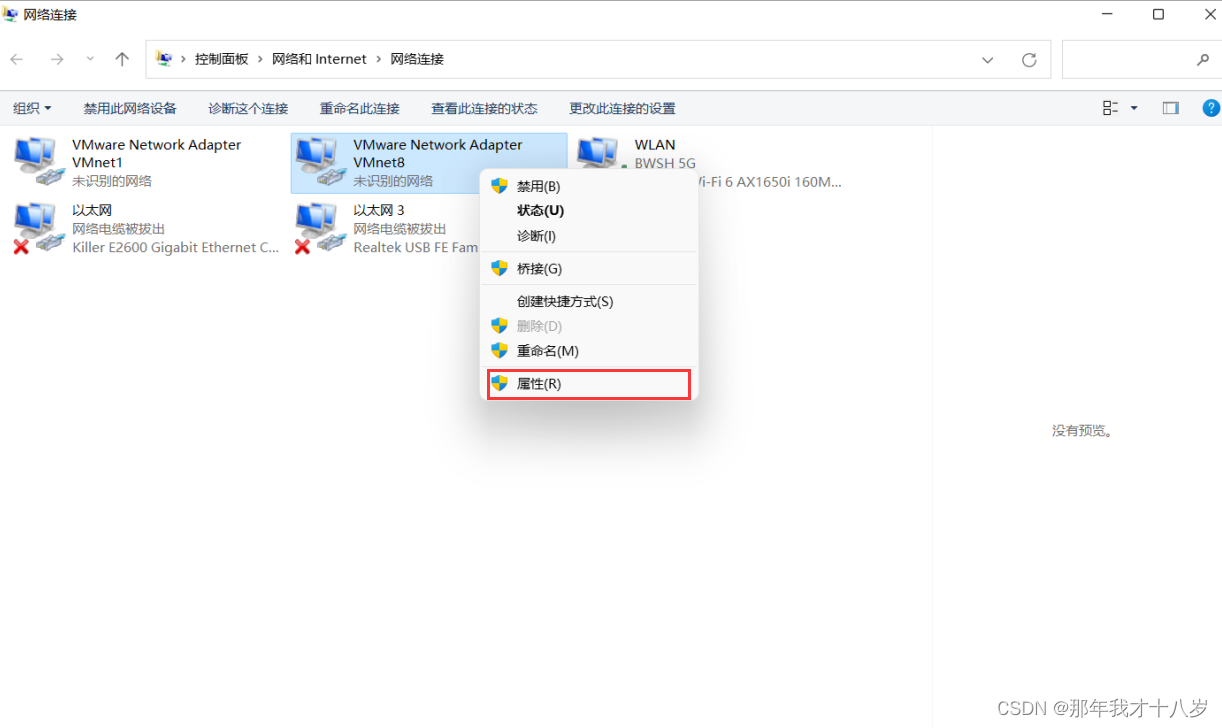
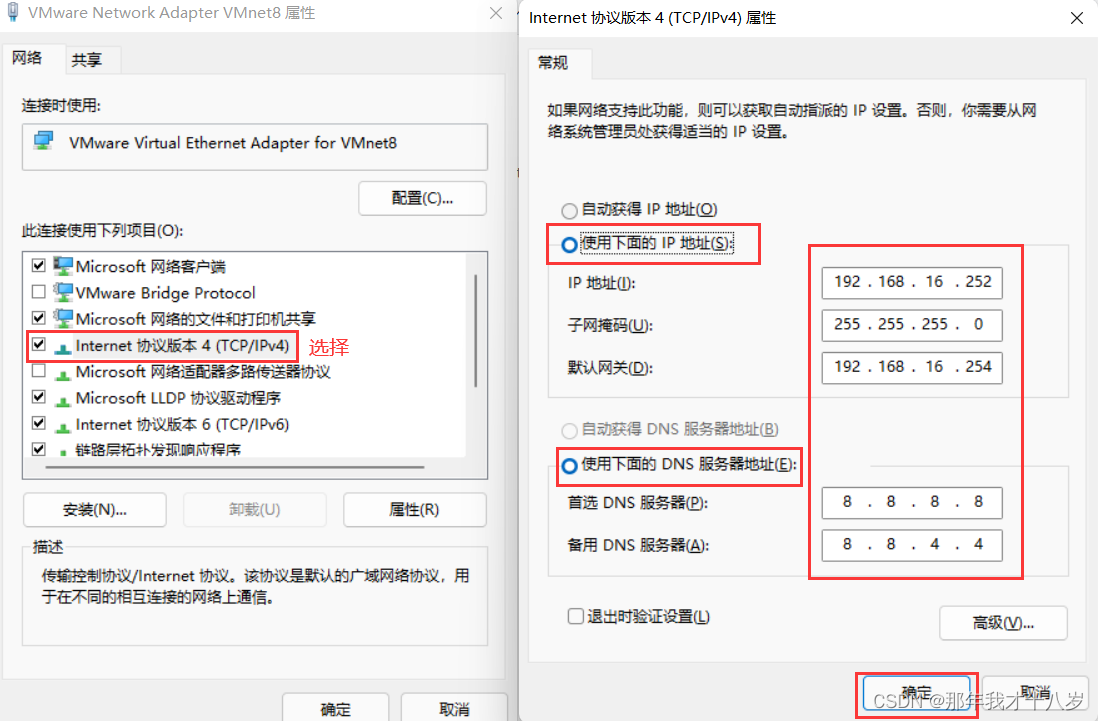
2.5 Windows的网络配置
打开网络和Internet设置 --> 点击更改适配器选项 --> 找到VMware Network Adapter VMnet8右键属性,打开后点击Internet协议版本4 ,然后这样配置 (默认网关要和刚刚虚拟机配置的ip路径一样,ip也要在一个网段)
3.虚拟机配置及虚拟机网络
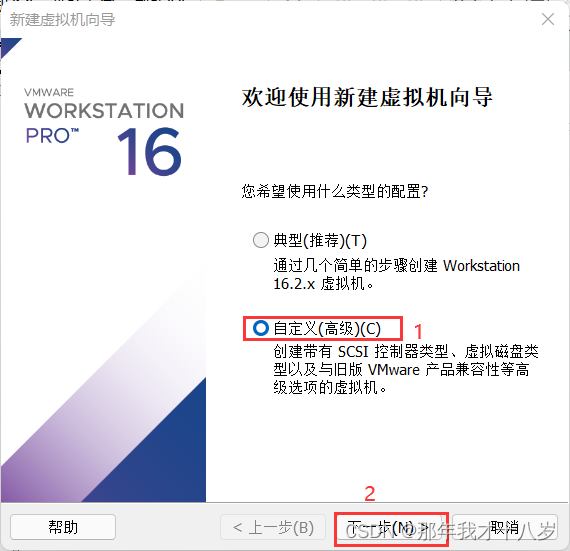
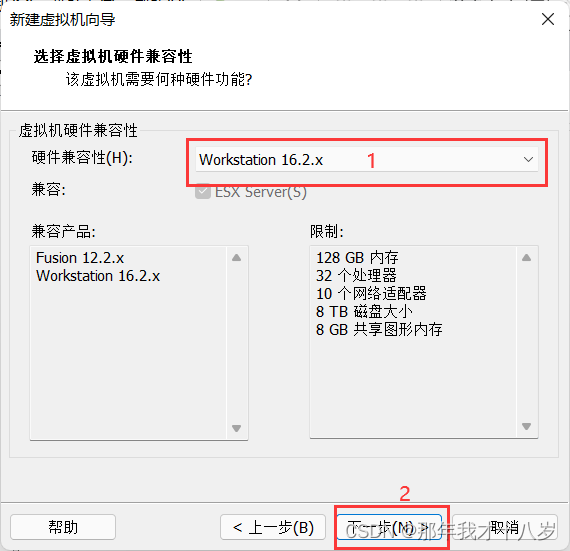
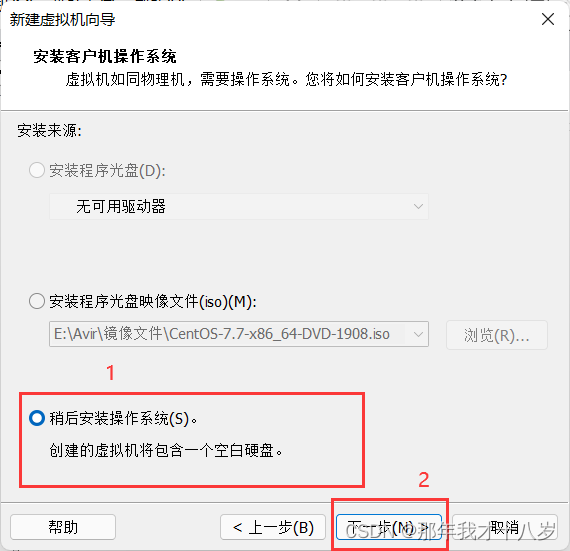
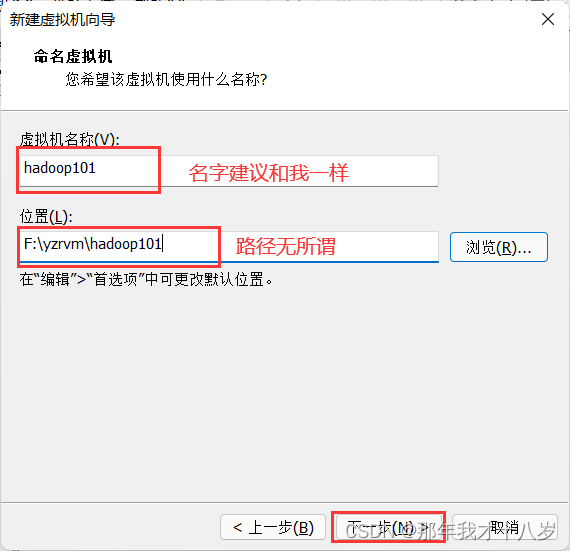
3.1 创建一台虚拟机,不细讲了,直接跟着文档走

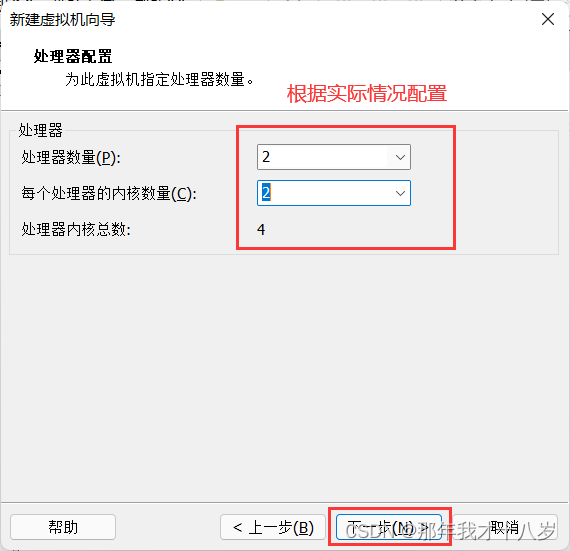
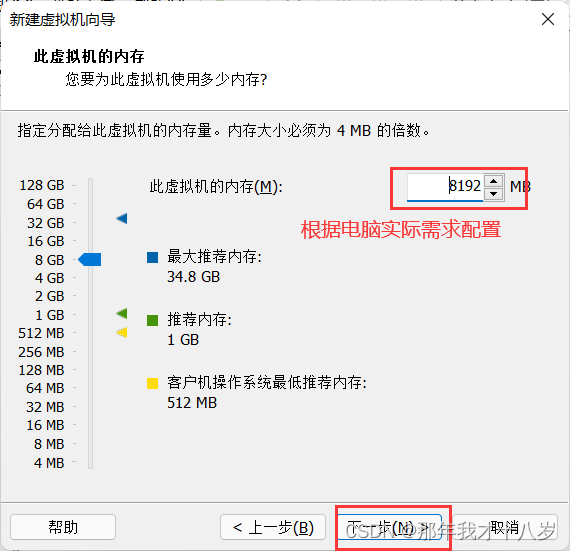
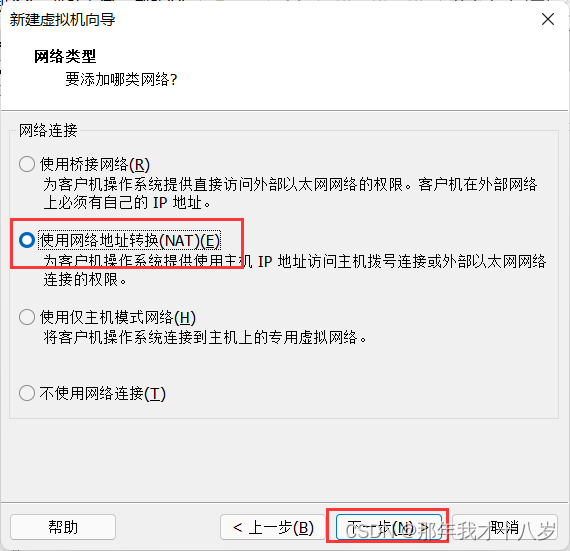
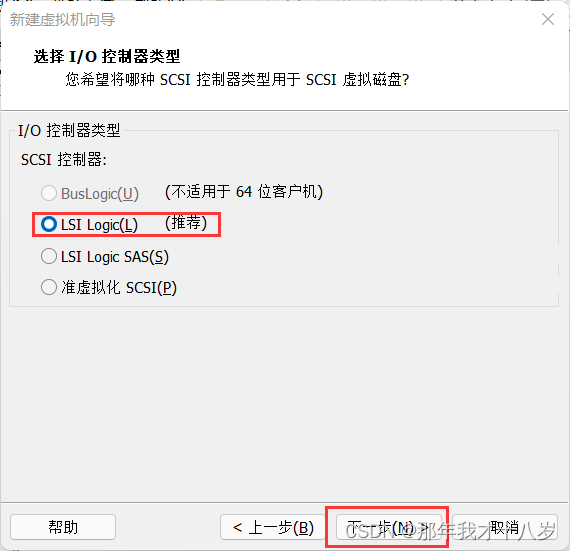
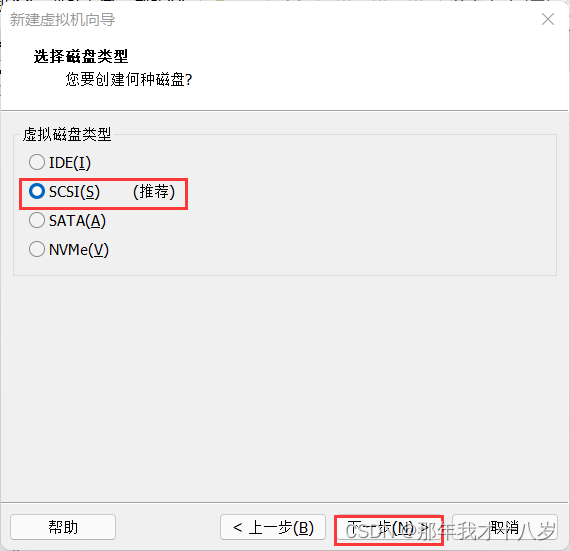
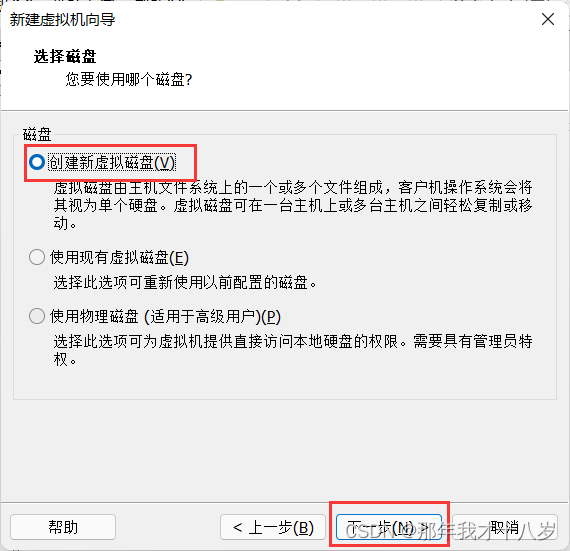
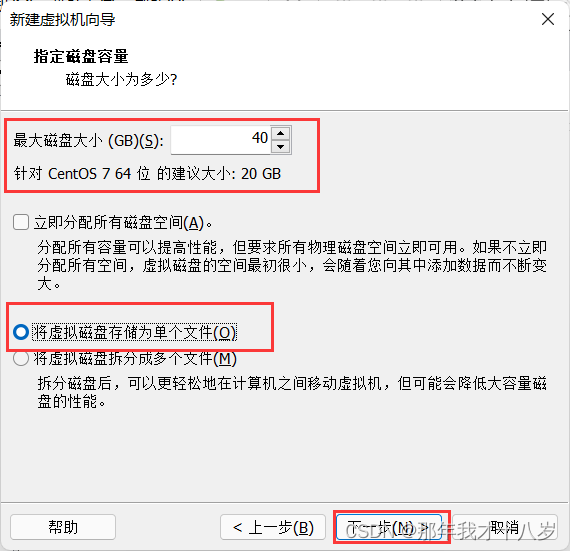
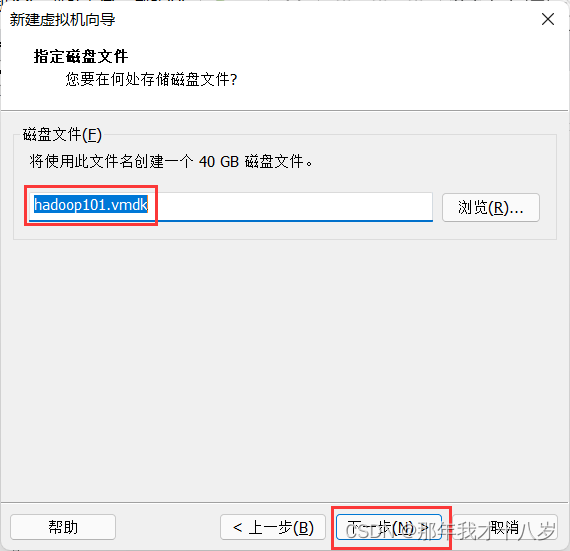
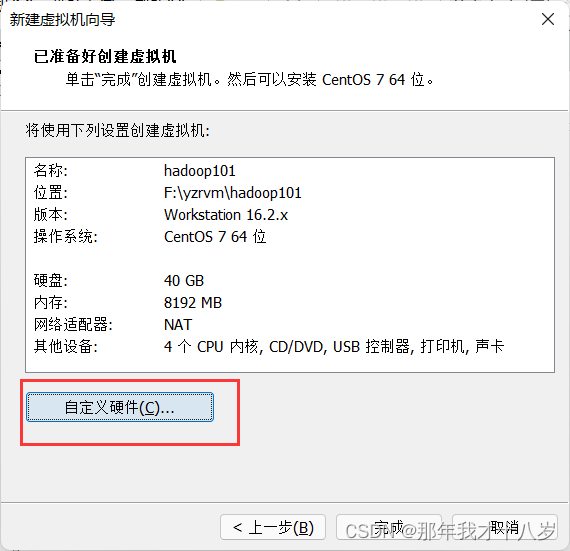
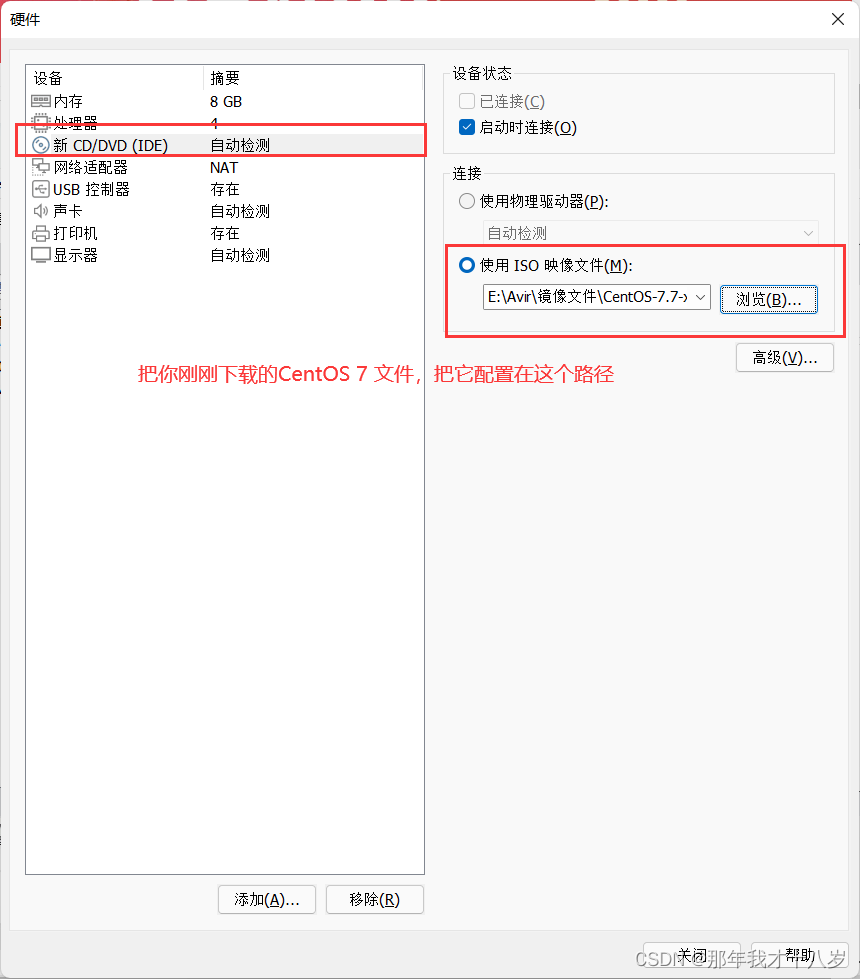
然后点击完成
3.2 开始虚拟机的安装
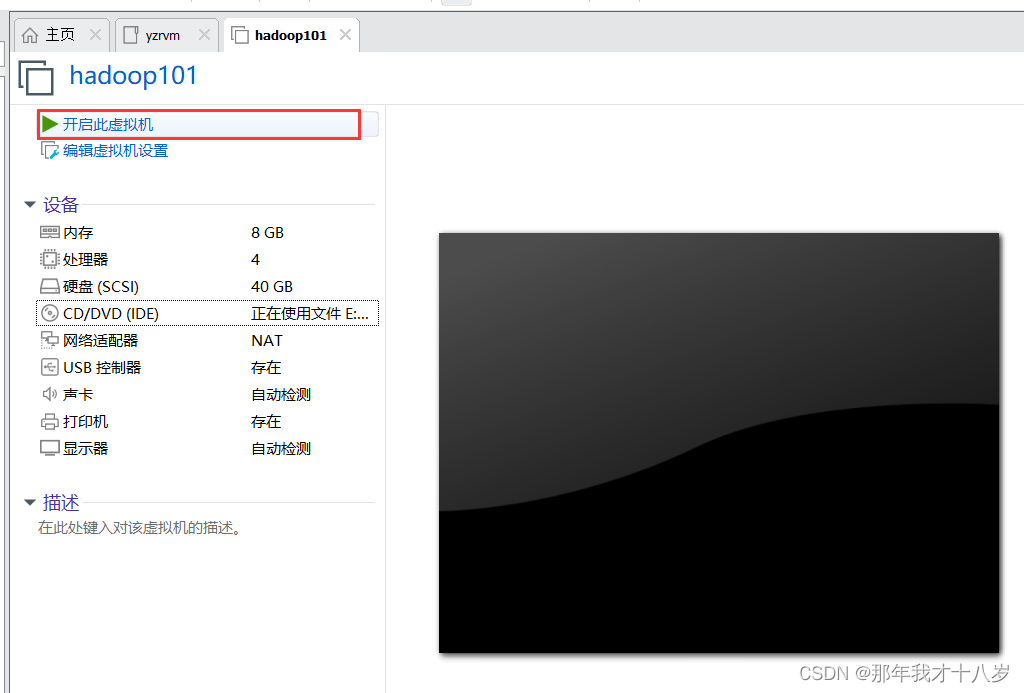
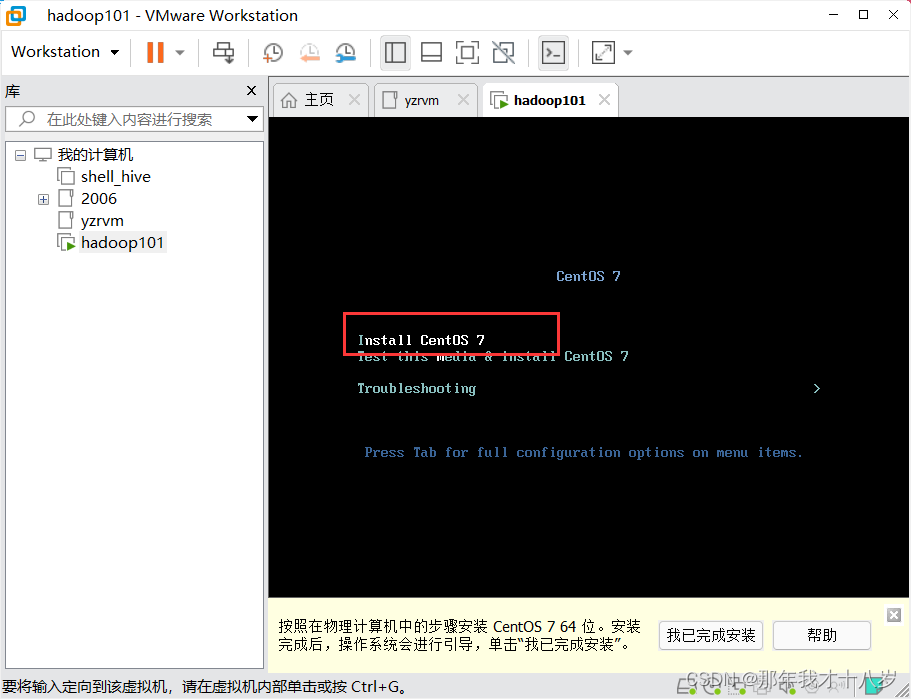
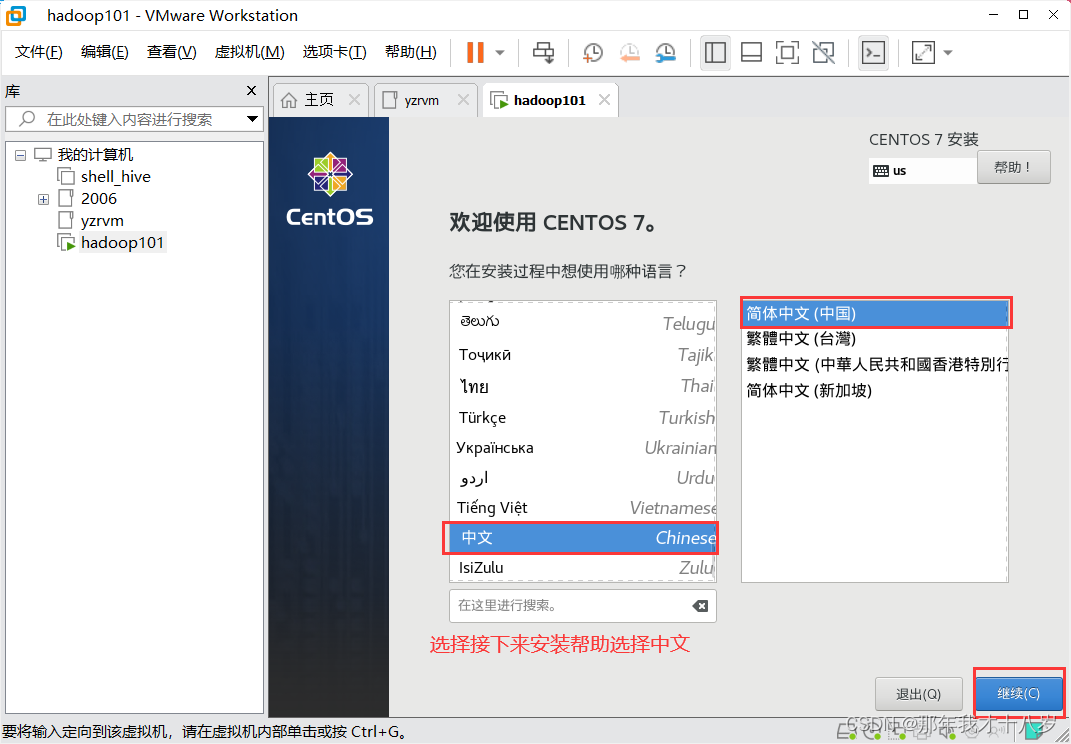
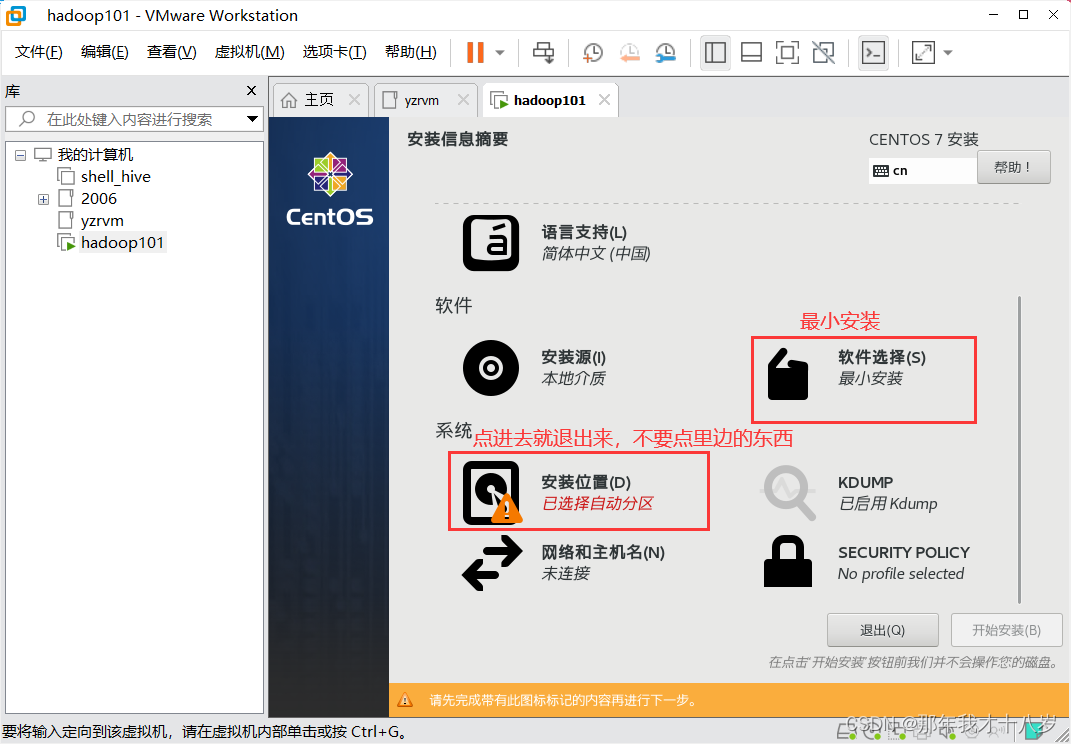

然后就等待一段时间,好了就直接重启
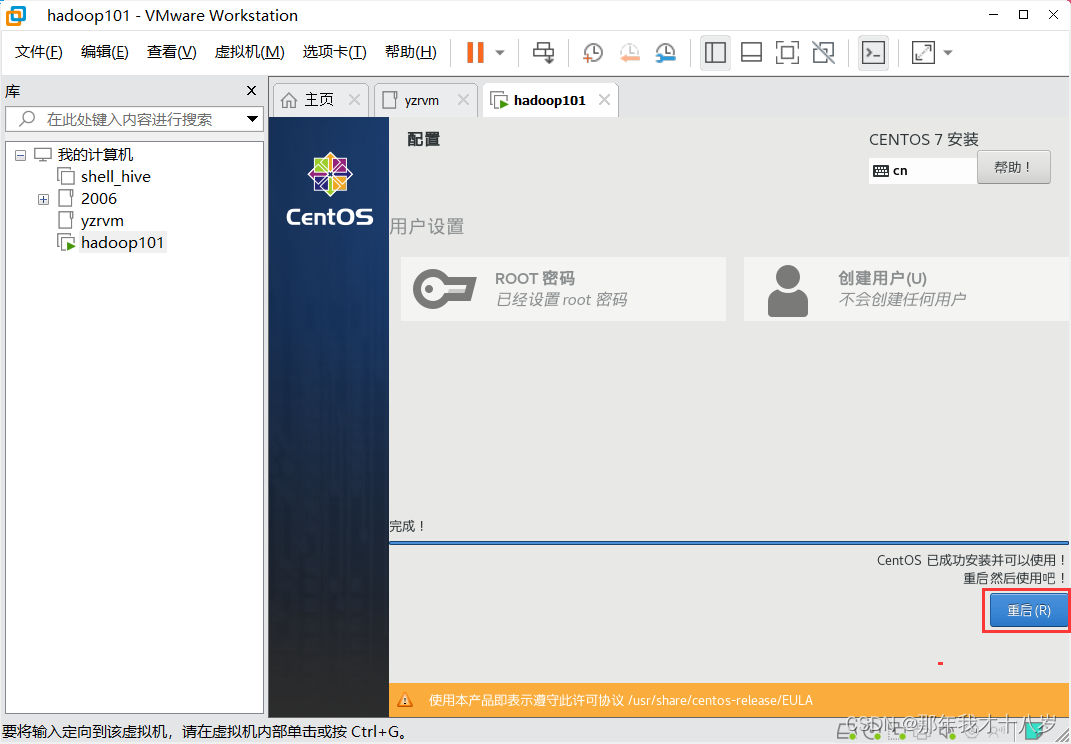
3.3修改虚拟机IP地址为静态IP,方便节点服务器间的相互通信
登录虚拟机之后,在命令行输入这串指令
vi /etc/sysconfig/network-scripts/ifcfg-ens33开始配置 把虚拟机ip 设置成静态 ip 按着我这样配置就行
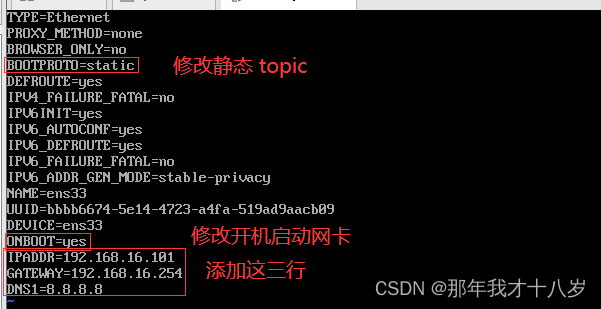
然后 :wq 存盘退出
在命令行输入“systemctl restart network” 来重启网络,重启后可用“ifconfig”来查看当前IP
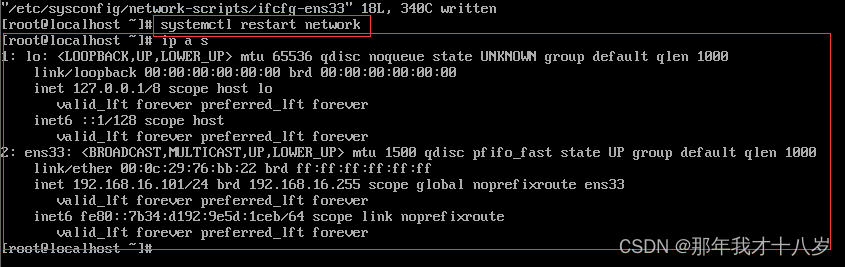
注意: 要保证Linux系统ifcfg-ens33文件中IP地址、虚拟网络编辑器地址和Windows系统VM8网络IP地址相同
3.4修改主机名和Hosts文件
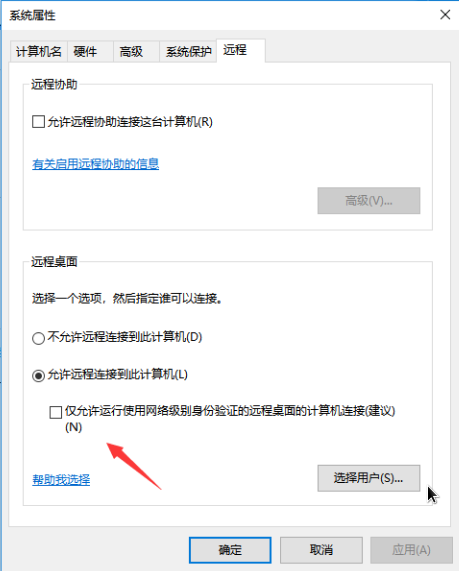
先用打开远程连接工具连接本台虚拟机(要保证当前ip是可用的)
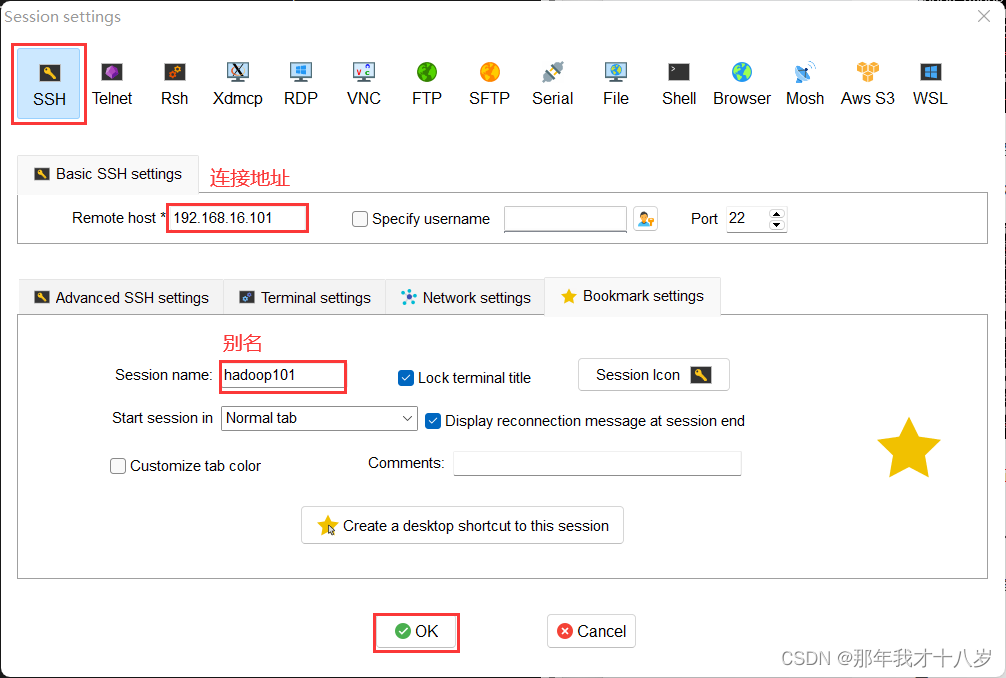
3.4.1 修改主机名: vi /etc/hostname

本台虚拟机的名称 hadoop101
3.4.2 修改Hosts文件: vi /ect/hosts

删除里边原有的信息,添加以下信息,然后存盘退出
192.168.16.101 hadoop101
192.168.16.102 hadoop102
192.168.16.103 hadoop103
3.5虚拟机环境准备
3.5.1 安装软件包
(以下操作都是在 root 家目录下)我不想截图了,太麻烦了
使用yum安装虚拟机需要网络,因此yum安装之前可以先测试下虚拟机的联网情况,可以选择:ping www.baidu.com,确认网络无误后后输入
yum install -y epel-release注意:若是选择了最小化安装(GHOME安装不需要此操作),还需要安装以下工具
1.net-tool:包含ifconfig等查看网络地址的命令
yum install -y net-tools2.vim:编辑器
yum install -y vim3.其他工具
yum install -y psmisc nc rsync lrzsz ntp libzstd openssl-static tree iotop git3.6 创建一个普通管理员用户
3.6.1 创建用户账号和密码
useradd yzr #用户名echo ? | passwd --stdin yzr #创建密码为 ? visudo #进入文件中:set nu #命令模式输入显示行号的,然后找到 100行yzr ALL=(ALL) NOPASSWD:ALL #需要添加的内容 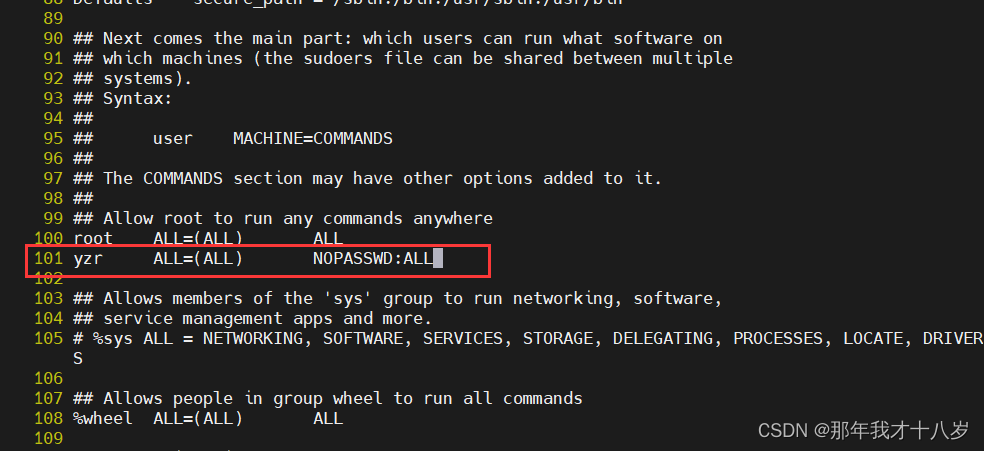
3.7 关闭防火墙和开机自启动(重点)我他妈吃了好几次亏了
sudo systemctl stop firewalld
sudo systemctl disable firewalld.service3.8 在/opt目录下创建文件夹,并修改所属主、所属组
3.8.1创建文件夹
mkdir -p /opt/module /opt/software3.8.2修改所所属主、所属组
chown master:master /opt/module
chown master:master /opt/software注意:以上修改完成后需重启虚拟机才能生效:命令行输入“reboot”指令或者图形化界面点击
4. 克隆虚拟机
利用创建的hadoop101虚拟机再另外克隆二台虚拟机:hadoop102 hadoop103
注意:克隆时,要先关闭被克隆的虚拟机
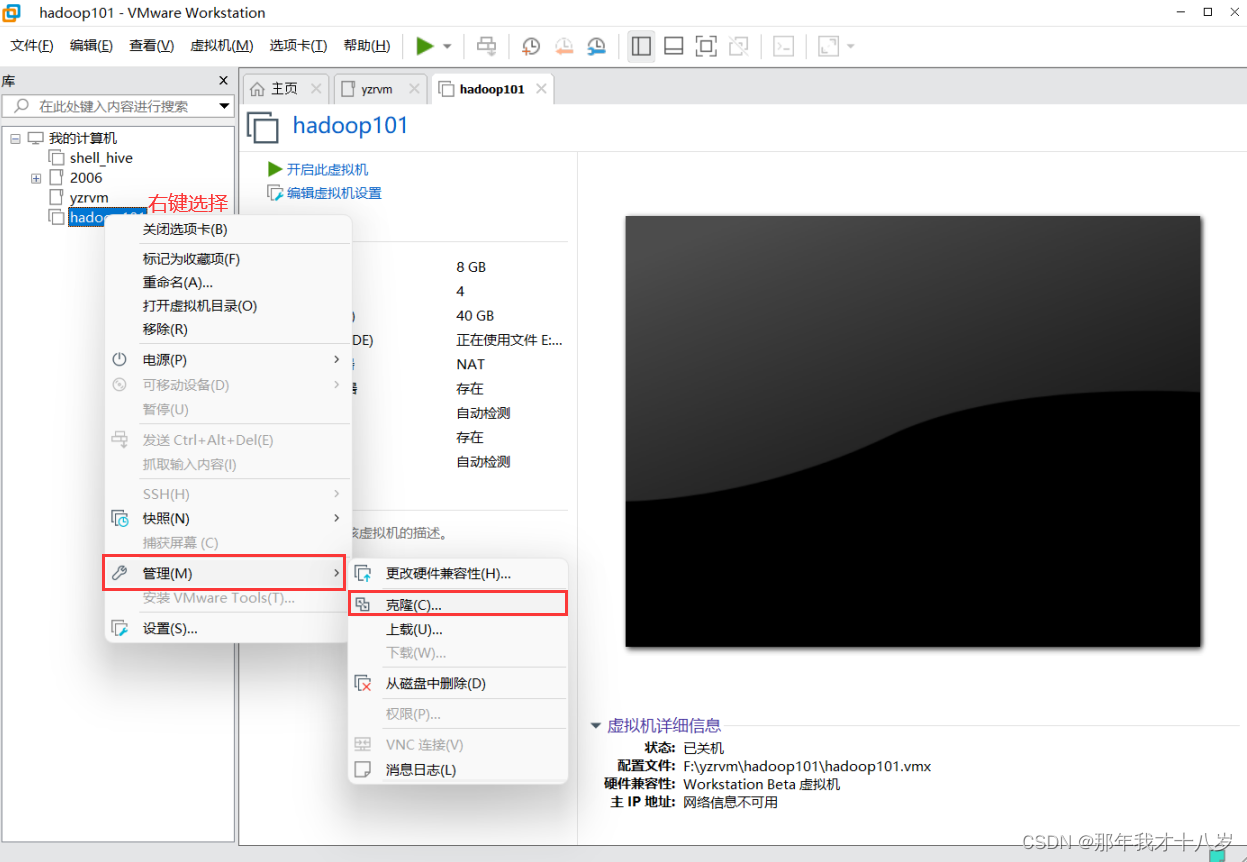
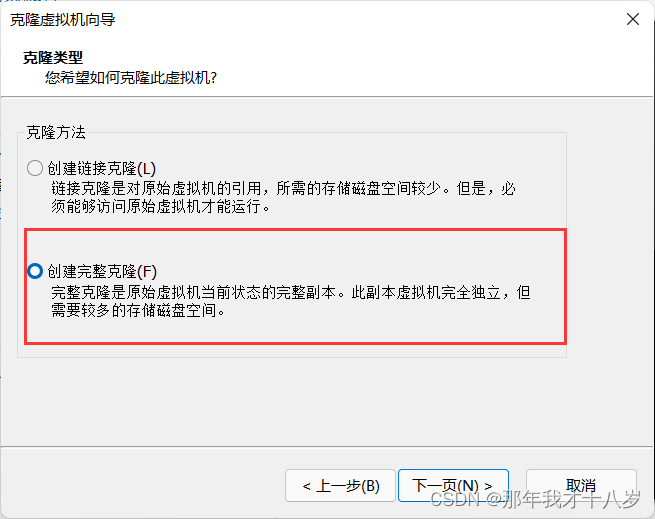
然后点击下一页,下一页,选择完整克隆
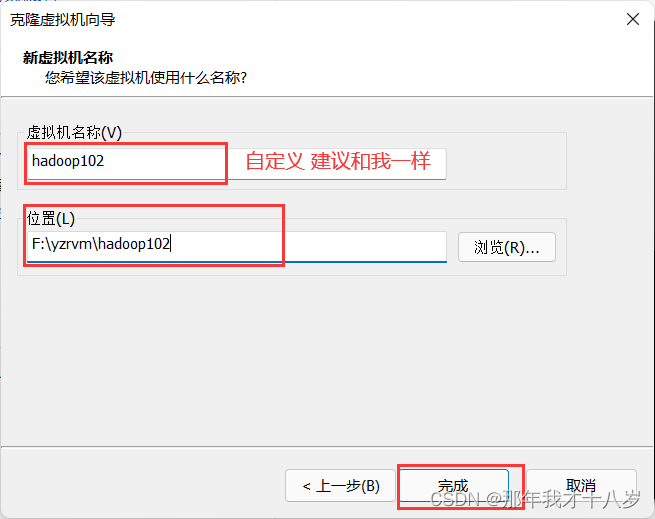
根据上边的步骤,再把hadoop103克隆一下
注意:不要同时启动三台刚克隆好的虚拟机,因为此时网络IP主机名都相同,修改完成后重启
克隆完成后,分别启动,然后对应Hosts文件修改主机名和IP地址
4.1.修改IP地址(root用户下修改):
vim /etc/sysconfig/network-scripts/ifcfg-ens33 hadoo102: 192.168.16.102hadoo103: 192.168.16.1034.2.修改主机名(root用户下修改):
vim /etc/hostnamehadoop102
hadoop103完成以后重启生效 reboot
5.jdk和hadoop的安装和配置
5.1 安装
注意:从此刻开始尽量不要再使用root用户来操作了, 用刚刚创建的 yzr用户来操作
打开三台虚拟机,在hadoop101上边操作
将 jdk和 hadoop安装包上传到/opt/software目录下
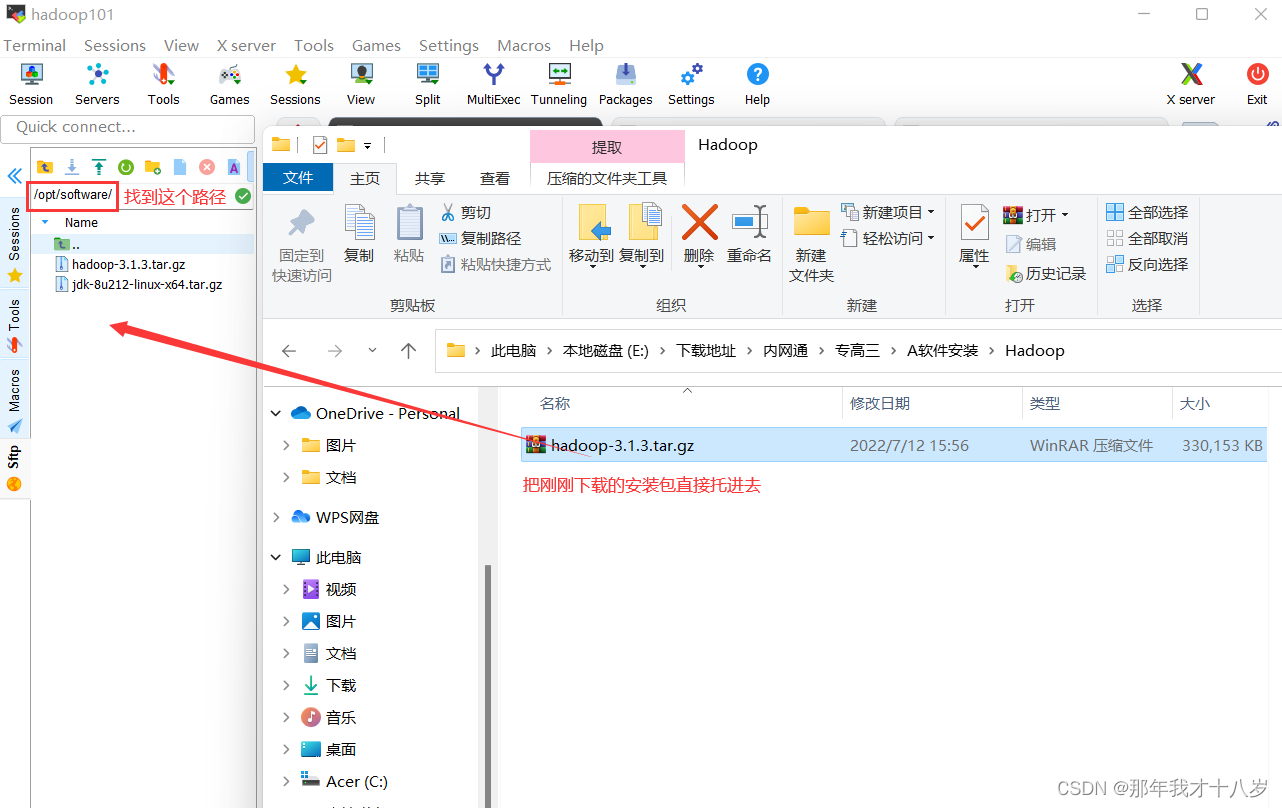
命令查看是否有这个包

解压jdk和hadoop的安装包到 /opt/module文件夹下
5.1.1 解压 jdk
tar -zxvf /opt/software/jdk-8u212-linux-x64.tar.gz -C /opt/module/5.1.2 解压hadoop
tar -zxvf /opt/software/hadoop-3.1.3.tar.gz -C /opt/module/5.2配置环境变量
5.2.1 在/etc/profile.d/目录下新建一个enviroment.sh文件用来配置jdk和hadoop的环境变量
sudo vim /etc/profile.d/enviroment.sh5.2.2 输入以下内容
#!/bin/bash
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin5.2.3 加载环境变量
source /etc/profile测试一下,分别输入“java -version”和“hadoop version”出现以下内容证明环境变量配置成功
[yzr@hadoop101 ~]$ java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)[yzr@hadoop101 ~]$ hadoop version
Hadoop 3.1.3
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579
Compiled by ztang on 2019-09-12T02:47Z
Compiled with protoc 2.5.0
From source with checksum ec785077c385118ac91aadde5ec9799
This command was run using /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-common-3.1.3.jar6.集群搭建
6.1 ssh 免密登录配置(必要配置)
在根目录输入“ll -a”查看是否有“.ssh”目录 如果没有:
先输入“ssh localhost”,根据提示输入“yes”,输入密码(当前用户密码)
[yzr@hadoop101 ~]$ ssh localhost
The authenticity of host 'localhost (::1%1)' can't be established.
ECDSA key fingerprint is SHA256:LgdTcQaHMt19sNAtd+9oSH3eFv4to0EtqTqUDDHvMsY.
ECDSA key fingerprint is MD5:aa:9d:5b:65:ac:02:b0:83:db:5c:6a:02:52:fb:7c:66.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
yzr@localhost's password:
Last login: Wed Nov 9 13:54:47 2022 from 192.168.16.252
进入 .ssh目录,生成公钥和密钥文件
ssh-keygen -t rsa #执行命令后按三次回车效果
[yzr@hadoop101 ~]$ cd .ssh/
[yzr@hadoop101 .ssh]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/yzr/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/yzr/.ssh/id_rsa.
Your public key has been saved in /home/yzr/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:P/sbm8Thrt1scvckDZKawX9XdmsJCsjaS7uZbXTvSJY yzr@hadoop101
The key's randomart image is:
+---[RSA 2048]----+
| |
| |
| |
| . .. . |
| oS.o +.. +|
| o o.Ooo.+=|
| . o. *EB o++|
| . *.o*oO++.|
| *o.o+O*o.o|
+----[SHA256]-----+
[yzr@hadoop101 .ssh]$
把公钥发给三台机器(包括自身hadoop101)执行时需要输入目标机器的登录密码
ssh-copy-id hadoop101
ssh-copy-id hadoop102
ssh-copy-id hadoop103效果
[yzr@hadoop101 .ssh]$ ssh-copy-id hadoop101
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/yzr/.ssh/id_rsa.pub"
The authenticity of host 'hadoop101 (192.168.16.101)' can't be established.
ECDSA key fingerprint is SHA256:LgdTcQaHMt19sNAtd+9oSH3eFv4to0EtqTqUDDHvMsY.
ECDSA key fingerprint is MD5:aa:9d:5b:65:ac:02:b0:83:db:5c:6a:02:52:fb:7c:66.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are al ready installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to ins tall the new keys
yzr@hadoop101's password:Number of key(s) added: 1Now try logging into the machine, with: "ssh 'hadoop101'"
and check to make sure that only the key(s) you wanted were added.[yzr@hadoop101 .ssh]$ ssh-copy-id hadoop102
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/yzr/.ssh/id_rsa.pub"
The authenticity of host 'hadoop102 (192.168.16.102)' can't be established.
ECDSA key fingerprint is SHA256:LgdTcQaHMt19sNAtd+9oSH3eFv4to0EtqTqUDDHvMsY.
ECDSA key fingerprint is MD5:aa:9d:5b:65:ac:02:b0:83:db:5c:6a:02:52:fb:7c:66.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
yzr@hadoop102's password:Number of key(s) added: 1Now try logging into the machine, with: "ssh 'hadoop102'"
and check to make sure that only the key(s) you wanted were added.[yzr@hadoop101 .ssh]$ ssh-copy-id hadoop103
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/yzr/.ssh/id_rsa.pub"
The authenticity of host 'hadoop103 (192.168.16.103)' can't be established.
ECDSA key fingerprint is SHA256:LgdTcQaHMt19sNAtd+9oSH3eFv4to0EtqTqUDDHvMsY.
ECDSA key fingerprint is MD5:aa:9d:5b:65:ac:02:b0:83:db:5c:6a:02:52:fb:7c:66.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
yzr@hadoop103's password:Number of key(s) added: 1Now try logging into the machine, with: "ssh 'hadoop103'"
and check to make sure that only the key(s) you wanted were added.[yzr@hadoop101 .ssh]$
在另外的两台机器上也要执行这个操作(生成公钥到发送公钥的过程),以使每台虚拟机都可以免密登录到其他的虚拟机
完了就测试一下
[yzr@hadoop101 .ssh]$ ssh hadoop102
Last login: Wed Nov 9 13:54:47 2022 from 192.168.16.252
[yzr@hadoop102 ~]$ ssh hadoop103
Last login: Wed Nov 9 13:54:47 2022 from 192.168.16.252
[yzr@hadoop103 ~]$ ssh hadoop101
Last login: Wed Nov 9 14:26:26 2022 from localhost6.2 编写集群分发脚本(必须在ssh免密登录的基础上)
创建目录
[yzr@hadoop101 ~]$ mkdir bin
[yzr@hadoop101 ~]$ vim bin/xsync编写分发脚本
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
thenecho Not Enough Arguement!exit;
fi#2. 遍历集群所有机器
for host in hadoop101 hadoop102 hadoop103
doecho ==================== $host ====================#3. 遍历所有目录,挨个发送for file in $@do#4. 判断文件是否存在if [ -e $file ]then#5. 获取父目录pdir=$(cd -P $(dirname $file); pwd)#6. 获取当前文件的名称fname=$(basename $file)ssh $host "mkdir -p $pdir"rsync -av $pdir/$fname $host:$pdirelseecho $file does not exists!fidone
done脚本授权
[yzr@hadoop101 ~]$ chmod u+x bin/xsync
上述过程完成后,进入root(管理员)用户把xsync复制到相同位置
[yzr@hadoop101 ~]$ su -
[root@hadoop101 ~]# mkdir bin
[root@hadoop101 ~]# cp /home/yzr/bin/xsync /root/bin/jdk和hadoop以及变量环境分发
[root@hadoop101 ~]# bin/xsync /opt/module
[root@hadoop101 ~]# sudo bin/xsync /etc/profile.d/enviroment.sh 环境变量配置文件群发到另外两台机器上后要分别执行以下内容重新加载环境变量
[yzr@hadoop102 .ssh]$ source /etc/profile
[yzr@hadoop102 .ssh]$ java -version
[yzr@hadoop102 .ssh]$ hadoop version[yzr@hadoop103 .ssh]$ source /etc/profile
[yzr@hadoop103 .ssh]$ java -version
[yzr@hadoop103 .ssh]$ hadoop version
NameNode、SecondaryNameNode、ResourceManager这三个要分开不要配置在同一台虚拟机上
6.3集群配置
修改集群的配置文件,主要是以下四个
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml、workers
进入配置文件所在的目录
[yzr@hadoop101 ~]$ cd /opt/module/hadoop-3.1.3/etc/hadoop/6.3.1 core-site.xml(核心配置文件)
vim core-site.xml
在<configuration>配置内容</configuration>中添加如下内容
<!-- 指定NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop101:8020</value></property><!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.1.3/data</value></property><!-- 配置HDFS网页登录使用的静态用户为master --><property><name>hadoop.http.staticuser.user</name><value>master</value></property>6.3.2 hdfs-site.xml(hdfs配置文件)
vim hdfs-site.xml
在<configuration>配置内容</configuration>中添加如下内容
<!-- nn web端访问地址--><property><name>dfs.namenode.http-address</name><value>hadoop101:9870</value></property><!-- 2nn web端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop103:9868</value></property>6.3.3 yarn-site.xml(yarn配置文件)
vim yarn-site.xml
在<configuration>配置内容</configuration>中添加如下内容
<!-- 指定MR走shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定ResourceManager的地址--><property><name>yarn.resourcemanager.hostname</name><value>hadoop102</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property><!-- 如果要程序的运行日志信息上传到HDFS系统上,可配置日志聚集(选择配置) --><!-- 开启日志聚集功能 -->
<property><name>yarn.log-aggregation-enable</name><value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property> <name>yarn.log.server.url</name> <value>http://hadoop101:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value>
</property>6.3.4 mapred-site.xml(mapred配置文件)
vim mapred-site.xml
在<configuration>配置内容</configuration>中添加如下内容
<!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property><!-- 如果要看程序的历史运行情况,可以配置历史服务器(选择配置) --><!-- 历史服务器端地址 -->
<property><name>mapreduce.jobhistory.address</name><value>hadoop101:10020</value>
</property><!-- 历史服务器web端地址 -->
<property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop101:19888</value>
</property>6.3.5 workers
vim workers
删除其中的localhost并在其中添加如下内容
hadoop101
hadoop102
hadoop1036.3.6 分发文件
[yzr@hadoop101 ~]$ bin/xsync /opt/module/hadoop-3.1.3/etc/hadoop/7.启动集群
7.1格式化NameNode
第一次启动需要在hadoop101节点先格式化NameNode
[yzr@hadoop101 ~]$ hdfs namenode -format注意:此步骤忘记进行或者出现其它问题需要重新格式化,先删除三个节点/opt/module/hadoop-3.1.3/目录下的data和logs文件夹(未出现问题不要执行此操作),删除命令为
[yzr@hadoop101 hadoop-3.1.3]$ rm -rf data/ logs/7.2 启动hdfs
[yzr@hadoop101 ~]$ /opt/module/hadoop-3.1.3/sbin/start-dfs.sh
正常情况下会出现如下内容

7.3 在hadoop102上启动YARN
[yzr@hadoop102 .ssh]$ /opt/module/hadoop-3.1.3/sbin/start-yarn.sh
若以上步骤都没问题,集群就启动成功了
然后查看各个集群的节点
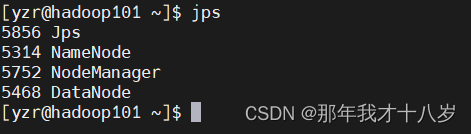

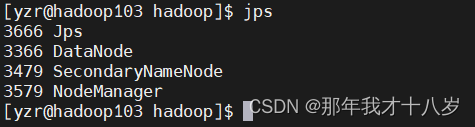
7.4 在web端查看
web端查看HDFS的NameNode 192.168.16.101:9870
web端查看YARN的ResourceManager 192.168.16.102:8088
web查看历史服务器(如果配置了) 192.168.16.101:19888/jobhistory
7.5集群测试
自己去测试 上传 下载
8.常用脚本配置
8.1 hdfs,yarn,historyserver (可以不启动)启动脚本
进入hadoop101的 /bin目录下边创建启动脚本 vim had
#!/bin/bashif [ $# -lt 1 ]
thenecho 参数个数不能为0exit ;
ficase $1 in
"start")echo " =================== 启动 hadoop集群 ==================="echo " --------------- 启动 hdfs ---------------"ssh hadoop101 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"echo " --------------- 启动 yarn ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
;;
"stop")echo " =================== 关闭 hadoop集群 ==================="echo " --------------- 关闭 yarn ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"echo " --------------- 关闭 hdfs ---------------"ssh hadoop101 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)echo 参数错误
;;
esac添加执行权限
chmod u+x hadhad start #启动
had stop #停止8.2查看全部节点当前的启动状态
在/bin目录下边创建 vim jpsall
#!/bin/bashfor host in hadoop101 hadoop102 hadoop103
doecho =============== $host ===============ssh $host jps $1 |grep -v Jps
donechmod u+x jpsall
现在整个集群就搭建完成了,后边将会更新关于其他工具的安装