1.代码如下
import time
import requests
import pandas as pd
import osdef getArticle(PMCID,NIHMSID,DOI,title,path):print(PMCID,NIHMSID,DOI,title,path)os.chdir(path)headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"}if (PMCID!="NA" and NIHMSID != "NA"):print("PMCID & NIHMSID")NIHMSID = str(NIHMSID).replace("NIHMS", "nihms")urls=f'https://www.ncbi.nlm.nih.gov/pmc/articles/{PMCID}/pdf/{NIHMSID}.pdf'r = requests.get(urls, headers=headers)with open(title + ".pdf", 'wb') as f:f.write(r.content)if (PMCID!="NA" and NIHMSID =="NA"):print("PMCID")DOI_after=DOI.split("/")urls = f'https://www.ncbi.nlm.nih.gov/pmc/articles/{PMCID}/pdf'r = requests.get(urls, headers=headers)with open(title + ".pdf", 'wb') as f:f.write(r.content)if (PMCID=="NA" and NIHMSID=="NA"):print("!PMCID & !NIHMSID")urls = f'https://sci.bban.top/pdf/{DOI}.pdf#view=FitH'print(DOI)headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"}r = requests.get(urls, headers=headers)with open(title+".pdf",'wb')as f:f.write(r.content)def getID(path,file):os.chdir(path)Article_info=pd.read_csv(file,header=0)Article_info=Article_info.fillna("NA")print(Article_info)for i in range(0,Article_info.shape[0]):#for i in range(4, 5):print(Article_info.loc[i])title=Article_info.loc[i,"Title"]title=str(title).replace(":","-").replace("\\","-")PMCID=Article_info.loc[i,"PMCID"]NIHMSID=Article_info.loc[i,"NIHMS ID"]DOI=Article_info.loc[i,"DOI"]print(PMCID,NIHMSID,DOI,title,path)try:getArticle(PMCID,NIHMSID,DOI,title,path)except:passtime.sleep(2)
def getPaperTable(path):allfile=os.listdir(path)string="title"+"\t"+"downloadResult"+"\n"os.chdir(path)for paper in allfile:if ".pdf" in paper:with open(paper,"rb") as fp:context=fp.read()if "404 Not Found" in str(context):string=string+paper+"\t"+"false"+"\n"else:string=string+paper+"\t"+"true"+"\n"with open("downloadResult.tsv",'w')as res:res.write(string)print("请输入存放文献信息表格的路径:")
path=input()
print("请输入存放文献信息表格的名字:")
file=input()
getID(path,file)
getPaperTable(path)2.使用
2.1 getArticle(PMCID,NIHMSID,DOI,title,path):
通过文章的PMCID或DOI从pubmed数据库或者SCI-hub数据库获取文章
2.2 getID(path,file):
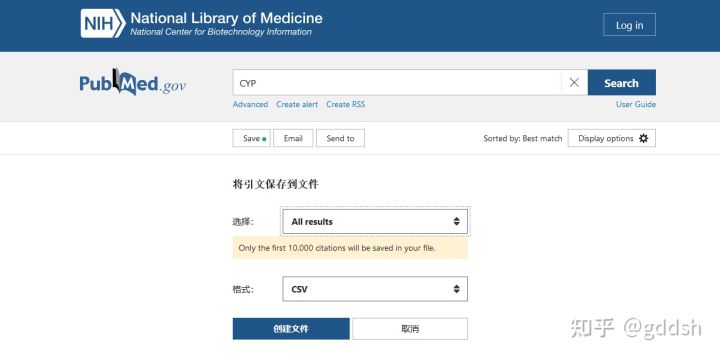
从pubmed获得的下载文献信息的表格读取要下载的文章。
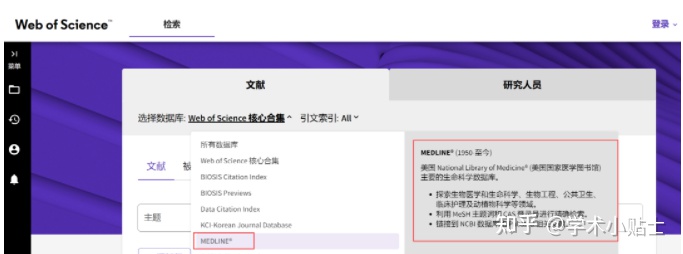
表格可以从pubmed一键导出(如下图):
2.3 getPaperTable(path):
获取文献下载情况的信息,由于文章信息的不完整,有个别文章会缺少DOI和PMCID,导致下载失败。
3.可执行文件
可通过pyinstaller自行打包。
也可通过回复文献批量下载器获取:
下面是淘宝链接:
https://item.taobao.com/item.htm?ft=t&id=675883011497