先说要完成的功能:把填写好的信息转换成PDF文件,并且下载到本地,类似在智联上下载自己的简历,不过下载下来是PDF文件。
参考了网上的多篇博客,发现有两种方法,但两种方法都各有利弊。下边介绍这两种方法。
一、直接把html页面转化成图片,放到了PDF中,并下载到本地,这种方法实验了一下,导出的效果不好,图片不太清楚,好处就是比较简单,只要引入几个js即可实现:
1、需要进入的三个js:
1. <script src="./js/libs/jquery-2.0.2.js"></script> 2. <script src="./js/exportpdf/jspdf.debug.js"></script> 3. <script src="./js/exportpdf/html2canvas.js"></script> <button id="topdf" type="button" class="btn btn-success btn-sm " style="margin-left:30px" onclick="downPDF()"><i class="icon-edit"></i>下载PDF</button>/** 下载PDF*/
function downPDF(){ //要转成PDF的标签的范围。html2canvas($('#pdf'), { height:3000, onrendered: function(canvas) { var imgData = canvas.toDataURL('image/png'); var doc = new jsPDF('p', 'px','a3'); //第一列 左右边距 第二列上下边距 第三列是图片左右拉伸 第四列 图片上下拉伸 doc.addImage(imgData, 'PNG', -9, 0,650,1500); doc.addPage(); doc.addImage(imgData, 'PNG', -9, -900,650,1500); //test.pdf是下载的pdf的名称doc.save('test.pdf'); } });
}html2canvas 是将当前页面转换成图片;
$('#pdf') 是要转换为图片的页面范围;
height:3000,这个高度要根据页面的大小灵活调整;
var doc = new jsPDF('p', 'px','a3'); p:横向,a3:纸张大小,默认是a4;
doc.addImage(imgData, 'PNG', -9, 0,650,1500);将转换后的图片放到pdf文档上,后面四个参数可根据实际效果灵活调整;
doc.addPage(); 一页pdf显示不完整的时候,新增一页;
5、 效果图: 
二、第二种方法,个人认为第二种方法比较好,虽然写起了比较麻烦,但是,用起来比较灵活。这种方法不需要引入 js,使用IText进行转化。
先说相关的文件支持:3个jar包,一个中文字体。
iText-2.0.8.jar.jar
core-renderer.jar.jar
pebble-2.0.0.jar
simsun.ttc 新宋体(如果电脑里没有就去下载一个,电脑中安装的路径一般是C:/WINDOWS/Fonts/simsun.ttc)
1、pom文件中需要加入:
<!-- pdf begin --><dependency> <groupId>com.lowagie</groupId> <artifactId>itext</artifactId> <version>2.0.8</version> </dependency> <dependency> <groupId>org.xhtmlrenderer</groupId> <artifactId>core-renderer</artifactId> <version>R8</version> </dependency><dependency><groupId>com.mitchellbosecke</groupId><artifactId>pebble</artifactId><version>2.2.0</version></dependency><!-- pdf end--> import java.io.BufferedWriter;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.io.OutputStreamWriter;
import java.io.StringWriter;
import java.io.Writer;
import java.net.MalformedURLException;
import java.util.ArrayList;
import java.util.Date;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import org.xhtmlrenderer.pdf.ITextFontResolver;
import org.xhtmlrenderer.pdf.ITextRenderer;
import com.dongao.common.util.DateUtil;
import com.dongao.job.model.StudentVo;
import com.lowagie.text.DocumentException;
import com.lowagie.text.pdf.BaseFont;
import com.mitchellbosecke.pebble.PebbleEngine;
import com.mitchellbosecke.pebble.template.PebbleTemplate;/*** 下载PDF文件* @author xiao**/
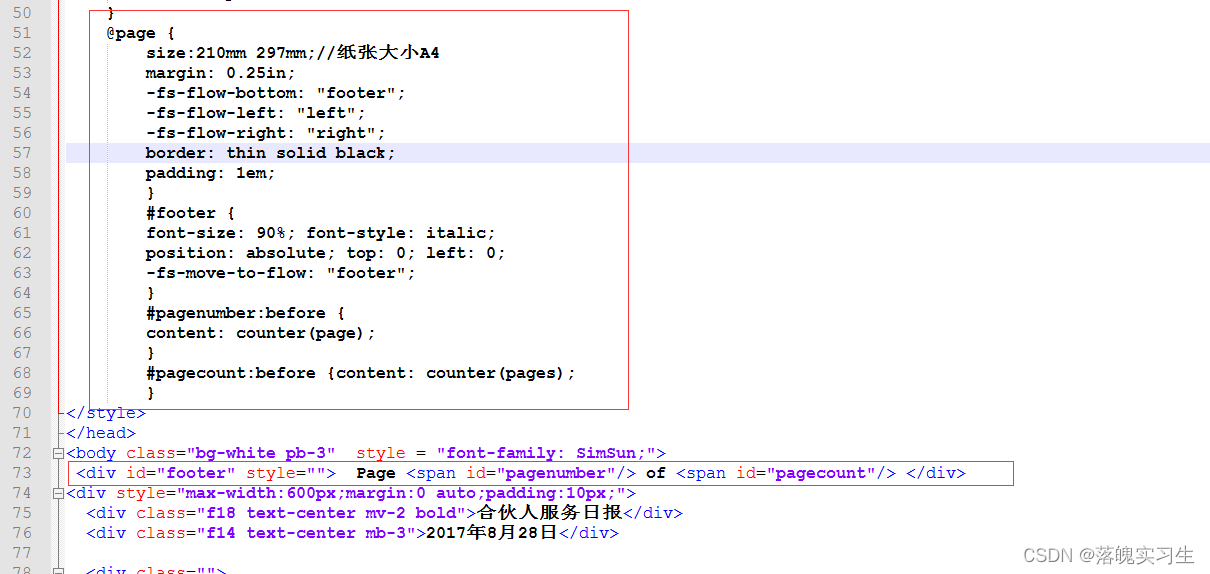
@Controllerpublic class DownPDFController extends BaseController {private static final String FONTPATH = "C:/WINDOWS/Fonts/simsun.ttc";//支持中文字体(放哪里都行) @RequestMapping("/exportPdf")@ResponseBodypublic String exportPdf( HttpServletResponse response,HttpServletRequest request) throws Exception{String html = createHtml("F:/"); String pdf = html2Pdf(html, "F:/测试.pdf"); //如果在控制类有response对象可以直接转换后的pdf文件,在控制类方法需要return null downloadFile(pdf, "我的PDF文件.pdf", response,request); //return null; System.out.println("create html success! 文件存放路径:" + pdf); return "导出成功!";}/*** 参数和模板组装* @return* @throws Exception*/public static String getPepple() throws Exception{Map<String, Object> context = new HashMap<String, Object>();context.put("resumeName", "张三");context.put("sex", "女");context.put("educationName", "大学");context.put("workYear", "3年");List<StudentVo> list=new ArrayList<StudentVo>();StudentVo s1=new StudentVo();s1.setAge(222);s1.setName("张一");StudentVo s2=new StudentVo();s2.setAge(333);s2.setName("张二");list.add(s1);list.add(s2);context.put("list", list);//一下是模板的创建PebbleEngine engine = new PebbleEngine.Builder().build();// 加载模版PebbleTemplate compiledTemplate = engine.getTemplate("template/test.html");Writer writer = new StringWriter();compiledTemplate.evaluate(writer, context);String output = writer.toString();System.out.println(output);return output;}/** * html转换pdf文件 * 注:支持中文,目前iText只支持上面FONTPATH定义的这种字体,所以html文件中也需要用样式设置字体为:SimSun * htmlPath 需要转换的html源文件 * pdfPath 转换后pdf文件存放地址 */ public String html2Pdf(String htmlPath, String pdfPath) { try { String url = new File(htmlPath).toURI().toURL().toString(); OutputStream output = new FileOutputStream(pdfPath); ITextRenderer renderer = new ITextRenderer(); renderer.setDocument(url); //解决中文支持问题(html的中文必须用SimSun字体,Java只能支持这1种字体) ITextFontResolver fontResolver = renderer.getFontResolver(); fontResolver.addFont(FONTPATH, BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED); renderer.layout(); renderer.createPDF(output); output.close(); //删除模板替换生成的新html文件 File htmlFile = new File(htmlPath); if(htmlFile.exists()){ htmlFile.delete(); } return pdfPath; } catch (MalformedURLException e) { e.printStackTrace(); return null; } catch (FileNotFoundException e) { e.printStackTrace(); return null; } catch (DocumentException e) { e.printStackTrace(); return null; } catch (IOException e) { e.printStackTrace(); return null; } } /** * 根据传入变量的字符串生成新的html文件 * @param htmlPath html文件地址 * @param targetPath 替换模板生成新html的存放地址 * @return */ public static String createHtml(String targetPath) { try { String htmlContext = getPepple();// 写入新的html文件 targetPath = targetPath + DateUtil.date2DateStr(new Date(), "yyyyMMddHHmmsss") + ".html"; BufferedWriter bw = new BufferedWriter(new OutputStreamWriter( new FileOutputStream(new File(targetPath)), "UTF-8")); bw.write(htmlContext); bw.flush(); bw.close(); return targetPath; } catch (Exception e) { e.printStackTrace(); return null; } }/** * 文件下载-支持中文名称 * @param sourcePath下载文件全路径(F:/test.pdf) * @param fileName需要生成的下载文件名(HTML转PDF测试.pdf) * @param response * @throws Exception */ public static void downloadFile(String sourcePath, String fileName, HttpServletResponse response,HttpServletRequest request) throws Exception { // 读到流中 InputStream inStream = null; try { inStream = new FileInputStream(sourcePath);// 文件的存放路径 // 设置输出的格式 response.reset(); String name = new String((fileName)); response.addHeader("Content-Disposition", "attachment; filename="+ new String(name.getBytes(), "iso-8859-1")); // 循环取出流中的数据 byte[] b = new byte[100]; int len; while ((len = inStream.read(b)) > 0) { response.getOutputStream().write(b, 0, len); } response.getOutputStream().flush(); } catch (IOException e) { e.printStackTrace(); } finally { try { inStream.close(); response.getOutputStream().close(); //删除源文件 /* File sourceFile = new File(sourcePath); if(sourceFile.exists()){ sourceFile.delete(); } */ } catch (IOException e) { e.printStackTrace(); } } }
}<body style = "font-family: SimSun;" >字符串举例:<div class="div-item fonts14"><p class="em-mart5">{{resumeName}}|{{sex}}|{{educationName}}|{{workYear}}工作经验|{{provinceName}}</p></div><br/><br/>集合和if条件遍历举例: <br/>{% for st in list %}{% if st.name == "张一" %}{{ st.age }} {{ st.name }}{% elseif st.name == "张二" %}{{ st.age }} {{ st.name }}{% else %}<p>Please select a category</p>{% endif %}{% endfor %} </body>
个人认为第二种方法虽然麻烦了点,但是灵活性比较好,可以随意的改变模板。个人还是比较偏向于第二种的。