Gaurav Chaware
Oct 27th, 2020
In the last couple of posts, I wrote about Open Policy Agent (OPA). People almost always ask one question – what is the difference between OPA and Gatekeeper when it comes to Kubernetes admission control? And, generally, follow up with another question – so should I use Gatekeeper instead of OPA?
Admittedly, the OPA documentation does a nice job explaining OPA and its use cases. It also has a brief section about difference between Gatekeeper and OPA. But for those just getting started with OPA, this difference isn’t always clear.
So, here in this blog post, I will clarify the difference between OPA and Gatekeeper. Or, to be precise, how Gatekeeper extends OPA.
Before we deep dive into differences, let’s make one thing clear. OPA is a general purpose policy engine. It has a number of use cases like API Authorization, SSH, Docker and more. Use of OPA is not tied to Kubernetes alone, neither Kubernetes is mandatory for using OPA. Kubernetes Admission Control is just one of OPA’s use cases. Please refer the OPA documentation for more use cases. And, note, this list is continuously expanding.
Gatekeeper on the other hand is specifically built for Kubernetes Admission Control use case of OPA. It uses OPA internally, but specifically for the Kubernetes admission control. So, we are going to focus only on this use case of OPA here.
Mandatory labels use case
Let’s consider you want to enforce a policy that pods running on your Kubernetes cluster must have appropriate labels. For e.g., a pod running in front-end namespace must have the app label with one of front-end or dashboard as value.
With OPA
The rego policy for this use case is as follows :
package k8s.labelsparameters.labels = {"front-end" : ["front-end", "dashboard"]}deny[msg] {namespace := input.request.namespacerequired := {label | label := parameters.labels[namespace][_]}provided := input.request.object.metadata.labels["app"]not required[provided]msg := sprintf("Missing required label %v",[required])
}
Now, this policy takes parameters.labels as the list of required labels per namespace. What happens when you want to add another namespace? Change the value for parameters.labels as {"front-end" : ["front-end", "dashboard"], "back-end" : ["reporting", "core"]}.
This requires the policy to be updated every time there is a change in labels or new namespace comes into picture. You can of course simplify the change management by using bundle APIs to centrally manage all the policies.
Now, let’s see how the same use case is solved by Gatekeeper.
With Gatekeeper
Gatekeeper uses OPA Constraint framework to define and enforce policies. To implement the labels use case, you will need to define a ConstraintTemplate and a Constraint using this template.
A ConstraintTemplate defines the policy that is used to enforce the constraint and also, the general schema of the constraint. The ConstraintTemplate for our labels use case will be as follows :
apiVersion: templates.gatekeeper.sh/v1beta1
kind: ConstraintTemplate
metadata:name: podrequiredlabels
spec:crd:spec:names:kind: PodRequiredLabelsvalidation:# Schema for the `parameters` fieldopenAPIV3Schema:properties:labels:type: arrayitems: stringtargets:- target: admission.k8s.gatekeeper.shrego: |package podrequiredlabelsviolation[{"msg": msg, "details": {"required_labels": required}}] {required := {label | label := input.parameters.labels[_]}provided := input.review.object.metadata.labels["app"]not required[provided]msg := sprintf("Missing required labels %v",[required])}
Now, using this ConstraintTemplate, create a Constraint as follows :
apiVersion: constraints.gatekeeper.sh/v1beta1 kind: PodRequiredLabels metadata:name: pod-required-labels spec:match:namespaces: ["front-end"]kinds:- apiGroups: ["apps"]kinds: ["Deployment"]- apiGroupts: [""]kinds: ["Pod"]parameters:labels: ["front-end","dashboard"]
So, did you notice the difference?
Let’s see these in closer details now.
Firstly, notice how the parameters are defined. In OPA version, we added parameters to the policy. In Gatekeeper ConstraintTemplate, we defined the schema for parameters. And defined the actual parameter value in Constraint. This allows one to use same template and define multiple constraints with different parameter values. So, for a new namespace, you simply need to define another Constraint as follows :
apiVersion: constraints.gatekeeper.sh/v1beta1 kind: PodRequiredLabels metadata:name: pod-required-labels spec:match:namespaces: ["back-end"]kinds:- apiGroups: ["apps"]kinds: ["Deployment"]- apiGroupts: [""]kinds: ["Pod"]parameters: labels: ["reporting","core"]
Notice also that you can define the scope of objects where a Constraint will apply through match field. The match field supports following matches : kind, namespaces, excludedNamespaces, labelSelector, namespaceSelector and scope.
So, you can define the template once and then, use multiple constraints with varying scopes to apply same policy with varying effect. With OPA version, you can write rego code to achieve the same.
Now that we have basic understanding of the different approaches, let’s take a look at other Gatekeeper and OPA differences.
Loading data and policies
Let’s see how policies and data is loaded in OPA and/or Gatekeeper.
OPA kube-mgmt integration
This is also Gatekeeper v1.0 – OPA as admission controller with kube-mgmt sidecar. Basically, kube-mgmt sidecar watches the various configured Kubernetes Objects. It loads any configmaps labeled with openpolicyagent.org/policy=rego into OPA as policies. It also loads any JSON from configmaps labeled with openpolicyagent.org/data=opa
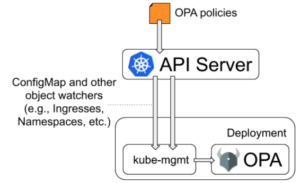
In addition, kube-mgmt also loads various Kubernetes Objects in OPA as JSON. This is useful to make contextual decisions for scenarios where current state of objects in Kubernetes is necessary. An example being a policy to enforce unique ingress hostnames.
As an alternative to loading policies through configmaps, you can use bundle APIs. Here, you can manage the policies at a central place, say an S3 bucket, and configure OPA to periodically download the updated policies and data. This is a powerful feature that allows you to centrally manage the policies and also, use distributed OPA deployments to enforce policies uniformly.
Gatekeeper evolved from this model, into its current v3.0 and higher.
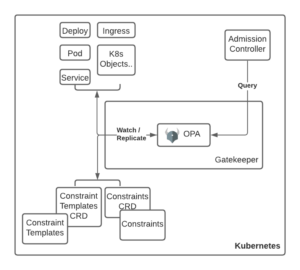
Gatekeeper v3.0
With Gatekeeper v3.x, integrates the admission controller with OPA constraint framework. You write policies as ConstraintTemplates. And then declaratively configure the policies through Constraints. So, compared to the kube-mgmt approach –
- Policies are defined as constraint templates & constraints instead of configmaps/remote bundles
- To sync Kubernetes Objects into OPA, use the sync config resource.
Logging and Auditing
Both Gatekeeper and OPA kube-mgmt print logs to stdout. These can be forwarded to external log aggregation systems like ELK, Datadog etc.
For decision logging, you can configure OPA to send the decisions to an external HTTP server. You can then process these decision logs to configure alerts, generate insights and so on.
Auditing existing objects with OPA kube-mgmt requires some work with policies and replication. Basically, you need to configure kube-mgmt to replicate the needed Kubernetes objects into OPA. Then, run the policies against these objects to generate compliance audit.
Whereas Gatekeeper provides an audit feature in-built. All violations are stored in the status field of the failed Constraint.
Dry-run
Gatekeeper provides a dry-run functionality which enables testing a Constraint on a live cluster without actually enforcing it. Set the enforcementAction: dryrun on the Constraint to enable dry-run. Default value is deny. So, when it is set to dryrun, the Constraint will be evaluated against live objects. But no request will be denied even if the Constraint fails. This allows you to test the Constraints without adversely impacting the cluster operations.
Mutating Webhook
You can deploy OPA kube-mgmt as both validating webhook as well as mutating webhook configurations. Whereas, Gatekeeper currently does not support mutating admission control scenarios. This is work in progress, and I hope it will be available soon with Gatekeeper.
Shift-left in the CICD toolchain
Using OPA as an admission controller, we can prevent any non-standard workloads from running in our Kubernetes cluster. But, we all want to catch the non-conformance as early as possible. You can use OPA as a CLI tool to validate manifests during PR checks. Or even simply run OPA tests as a validation step in your deployment pipeline. Most importantly, you can use the same policies for these validations that will be enforced by OPA admission controller. Also checkout Conftest which allows you to write tests for your configuration files using Rego policies.
With Gatekeeper, you can maintain the constraint templates and constraints in source control system and enable continuous deployment. To enable validation of your deployment manifests in the deployment pipeline, you will need to employ other tools like Konstraint.
Finally..
So, like we saw, Gatekeeper is specifically built for Kubernetes admission control use case of OPA. It uses OPA and provides ConstraintTemplates to declaratively configure the policies. It does add some nice features like auditing, dry run. And, also has some missing pieces like the mutating webhook support. You can always use OPA and Gatekeeper simultaneously to support both validating and mutating webhook scenarios.
How has your experience been with Gatekeeper or OPA? Please let me know your feedback or reach out for general discussions on gaurav@infracloud.io / @Gaurav on OPA slack / @GGCTwts on twitter.
References:
- OPA Documentation – https://www.openpolicyagent.org/docs/latest/
- Gatekeeper Documentation – https://github.com/open-policy-agent/gatekeeper
- OPA Gatekeeper: Policy and Governance for Kubernetes