##加载程序包
from openpyxl import load_workbook #利用openpyxl程序包向指定excel单元格写入值
from sklearn.preprocessing import StandardScaler #利用StandardScaler数据标准化处理
import pandas as pd #利用pandas加载excel,得到dataframe结构
dataset = pd.read_excel('123.xlsx') #加载excel,利用dataframe结构预处理,excel文件在程序所在文件夹下
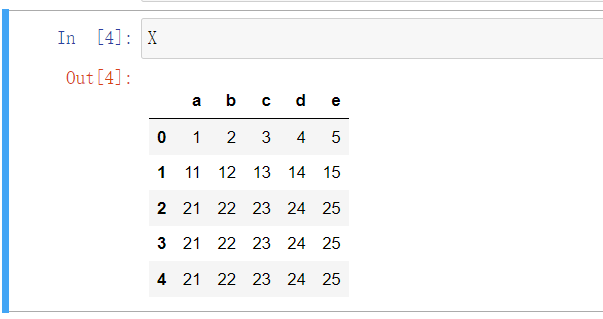
X = dataset.iloc[:,2:-1]
y = dataset['target']
scaler = StandardScaler()
data = scaler.fit_transform(X) #标准化处理'''
array([[-1.75, -1.75, -1.75, -1.75, -1.75],[-0.5 , -0.5 , -0.5 , -0.5 , -0.5 ],[ 0.75, 0.75, 0.75, 0.75, 0.75],[ 0.75, 0.75, 0.75, 0.75, 0.75],[ 0.75, 0.75, 0.75, 0.75, 0.75]])
'''