一、JUC介绍
java.util.concurrent包(简称:JUC)。JUC主要是让开发者在多线程编程中更加简单、方便一些。 通过JDK内置了一些类、接口、关键字,补充完善了JDK对于并发编程支持的“短板”。
主要功能:(1)Executor:线程池(2)Atomic:原子操作类(3)Lock:锁(4)Tools:信号量工具类(4)并发集合:提供了线程安全的集合类。
二、线程池
(1)什么是线程池:
内存中的一块空间。这块空间里面存放一些已经实例化好的线程对象。当代码中需要使用线程时直接从线程池获取。当代码中线程执行结束或需要销毁时,把线程重新放入回到线程池,而不是让线程处于死亡状态。
(2)线程池的优缺点:
优点:(1)降低系统资源消耗。通过重用线程对象,降低因为新建和销毁线程产生的系统消耗。(2)提高系统响应速度。直接从内存中获取线程对象,比新建线程更快。(3)提供线程可管理性。通过对线程池中线程数量的限制,避免无限创建线程导致的内存溢出或CPU资源耗尽等问题。
缺点:默认情况下,无论是否需要使用线程对象,线程池中都有一些线程对象,也就是说会占用一定内存。
三、JUC中的线程池
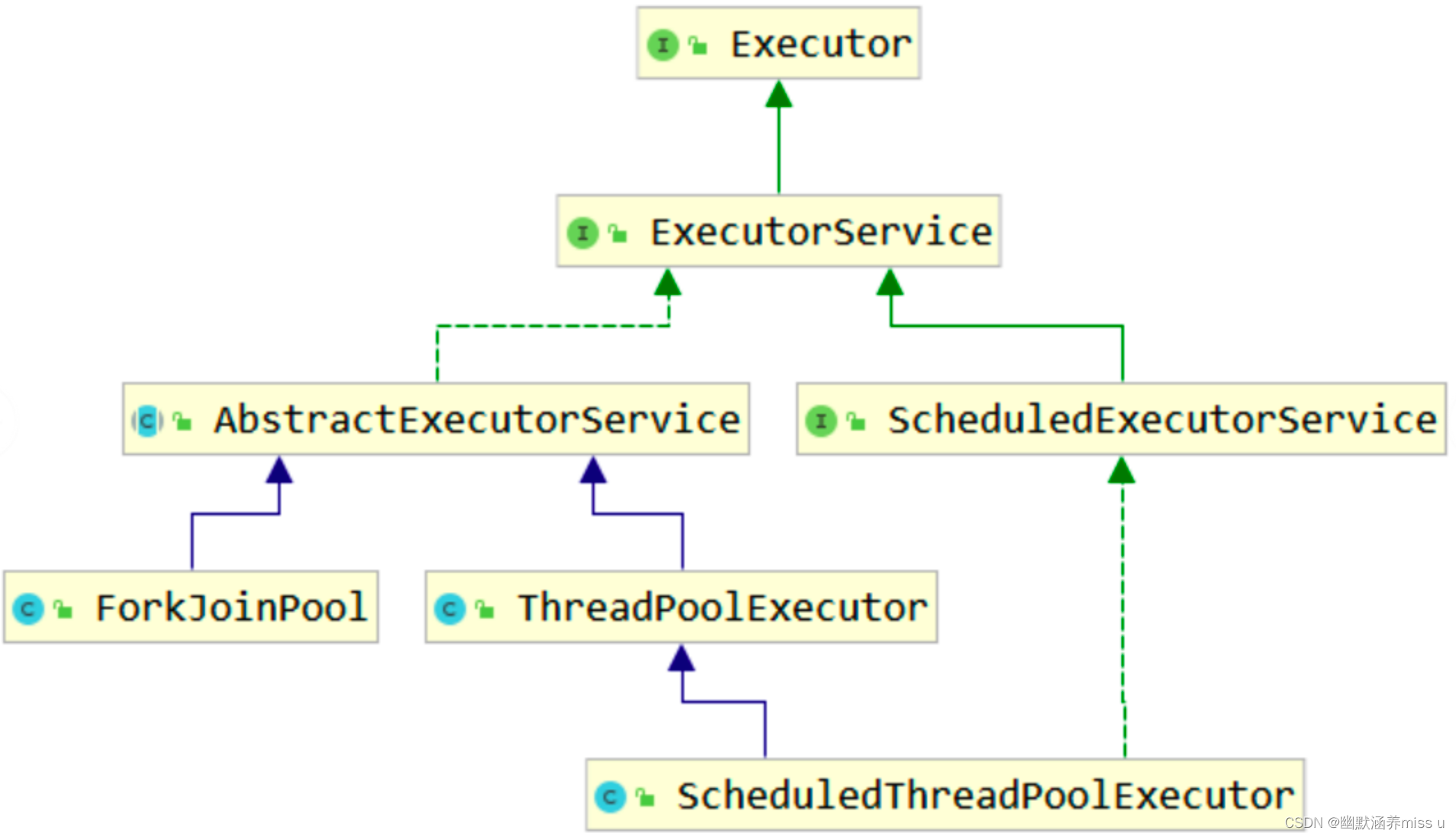
1. Executor介绍:
Executor 线程池顶级接口, 接口中只有一个execute()方法,方法参数为Runnable类型。
2.ThreadPoolExecutor:
是JUC中提供的默认线程池实现类, Executor的子类。
构造方法中的七个参数:
(1)int corePoolSize核心线程数:创建线程池后,默认线程池中并没有任何的线程,执行了从线程池获取线程执行任务的时候才会创建核心线程完成任务的执行。 如果没有达到指定corePoolSize, 即使有空闲的核心线程, 也会创建新的核心线程执行任务, 直到达到了corePoolSize。 达到corePoolSize后, 从线程池获取线程执行任务, 有空闲的核心线程, 空闲的线程会执行新任务。
(2)BlockingQueue<Runnable> workQueue阻塞队列:
理解:阻塞:当队列为空时,阻塞获取任务;当队列放满时,阻塞添加任务。
-
当线程池中的线程数目达到指定的corePoolSize后,并且所有的核心线程都在使用中, 再来获取线程执行任务, 会将任务添加到缓存任务的阻塞队列中,也就是workQueue。
-
队列可以设置queueCapacity 参数,表示任务队列最多能存储多少个任务。
(3)int maximumPoolSize最大线程数:
-
所有的核心线程都被使用中,且任务队列已满时,线程池会创建新的线程执行任务,直到线程池中的线程数量达到maximumPoolSize。
-
被使用的线程数等于maximumPoolSize ,且任务队列已满,则已超出线程池的处理能力,线程池会拒绝处理任务而抛出异常。
(4)long keepAliveTime线程最大空闲时间:
-
线程池中存在空闲的线程, 就会处于空闲(alive)状态, 只要超过keepAliveTime, 空闲的线程就会被销毁,直到线程池中的线程数等于corePoolSize。
-
如果设置了allowCoreThreadTimeOut=true(默认false),核心线程也可以被销毁。
(5)TimeUnit unitkeepAliveTime 时间单位:
TimeUnit是枚举类型。
public enum TimeUnit {//纳秒NANOSECONDS(TimeUnit.NANO_SCALE),//微妙MICROSECONDS(TimeUnit.MICRO_SCALE),//毫秒MILLISECONDS(TimeUnit.MILLI_SCALE),//秒SECONDS(TimeUnit.SECOND_SCALE),//分钟MINUTES(TimeUnit.MINUTE_SCALE),//小时HOURS(TimeUnit.HOUR_SCALE),//天DAYS(TimeUnit.DAY_SCALE);private static final long NANO_SCALE = 1L;private static final long MICRO_SCALE = 1000L * NANO_SCALE;private static final long MILLI_SCALE = 1000L * MICRO_SCALE;private static final long SECOND_SCALE = 1000L * MILLI_SCALE;private static final long MINUTE_SCALE = 60L * SECOND_SCALE;private static final long HOUR_SCALE = 60L * MINUTE_SCALE;private static final long DAY_SCALE = 24L * HOUR_SCALE;
}(6)ThreadFactory threadFactory线程工厂:创建线程对象。
(7)RejectedExecutionHandler handler线程池拒绝策略:
只有当任务队列已满,且线程数量已经达到maximunPoolSize才会触发拒绝策略。
-
AbortPolicy: 丢弃新任务,抛出异常,提示线程池已满(默认)。
-
DisCardPolicy: 丢弃任务,不抛出异常。
-
DisCardOldSetPolicy: 将消息队列中最先进入队列的任务替换为当前新进来的任务。
-
CallerRunsPolicy: 由调用该任务的线程处理, 线程池不参与, 只要线程池未关闭,该任务一直在调用者线程中。
package com.java.test;import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;/*
* 使用实例
* */public class Test01 {public static void main(String[] args) {ThreadPoolExecutor te = new ThreadPoolExecutor(2,4,5, TimeUnit.SECONDS,new ArrayBlockingQueue<Runnable>(5));te.execute(new Runnable() {@Overridepublic void run() {System.out.println(Thread.currentThread().getName());}});te.execute(new Runnable() {@Overridepublic void run() {System.out.println(Thread.currentThread().getName());}});te.execute(new Runnable() {@Overridepublic void run() {System.out.println(Thread.currentThread().getName());}});}
}
3.Executors
(1)介绍:Executors时线程池的工具类,返回值都是ExecutorService接口的实现类, 底层大多是调用ThreadPoolExecutor()。
(2)newThreadPoolExecutor()方法:单线程
//源码public static ExecutorService newSingleThreadExecutor() {return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));
}效果总结:
-
它只会创建一条工作线程处理任务;
-
采用的阻塞队列为LinkedBlockingQueue, 它是一个无界队列, 底层为链表。
package com.java.test;import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/*
* 使用方式
* */
public class Test02 {public static void main(String[] args) throws InterruptedException {ExecutorService es = Executors.newSingleThreadExecutor();while (true) {es.execute(new Runnable() {@Overridepublic void run() {System.out.println(Thread.currentThread().getName());// while (true){}}});Thread.sleep(1000);}}
}
(3)newFixedThreadPool(int nThreads)方法:自定义线程数
//源码public static ExecutorService newFixedThreadPool(int nThreads) {return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());}效果总结:
-
它是一种固定大小的线程池;
-
corePoolSize和maximunPoolSize都为用户设定的线程数量nThreads;
-
keepAliveTime为0,意味着一旦有多余的空闲线程,就会被立即停止掉;但这里keepAliveTime无效;
-
阻塞队列采用了LinkedBlockingQueue,它是一个无界队列, 底层为链表;
-
由于阻塞队列是一个无界队列,因此永远不可能拒绝任务;
-
由于采用了无界队列,实际线程数量将永远维持在nThreads,因此maximumPoolSize和keepAliveTime将无效。
package com.java.test;import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;public class TestnewFixedThreadPool {public static void main(String[] args) throws InterruptedException {ExecutorService executorService = Executors.newFixedThreadPool(5);while (true){executorService.submit(new Runnable() {@Overridepublic void run() {System.out.println(Thread.currentThread().getName());}});Thread.sleep(1000);}}
}
(4)newCachedThreadPool():缓存线程池
//源码public static ExecutorService newCachedThreadPool() {return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());
}效果总结:
-
它是一个可以无限扩大的线程池;
-
它比较适合处理执行时间比较小的任务;
-
corePoolSize为0,maximumPoolSize为无限大,意味着线程数量可以无限大;
-
keepAliveTime为60S,意味着线程空闲时间超过60S就会被杀死;
-
采用SynchronousQueue(同步队列)装等待的任务,这个阻塞队列没有存储空间,这意味着只要有请求到来,就必须要找到一条工作线程处理他,如果当前没有空闲的线程,那么就会再创建一条新的线程。
package com.java.test;import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;public class TestnewCachedThreadPool {public static void main(String[] args) throws InterruptedException {ExecutorService executorService = Executors.newCachedThreadPool();while (true){executorService.submit(new Runnable() {@Overridepublic void run() {System.out.println(Thread.currentThread().getName());while (true){}}});Thread.sleep(1000);}}
}
(5) newScheduledThreadPool():
//源码public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {return new ScheduledThreadPoolExecutor(corePoolSize);
}public ScheduledThreadPoolExecutor(int corePoolSize) {super(corePoolSize, Integer.MAX_VALUE,DEFAULT_KEEPALIVE_MILLIS, MILLISECONDS,new DelayedWorkQueue());
}效果总结:
-
它采用DelayQueue存储等待的任务
-
它会根据time的先后时间排序,若time相同则根据sequenceNumber排序;
-
DelayQueue也是一个无界队列;
-
工作线程会从DelayQueue取已经到期的任务去执行;
-
执行后也可以将任务重新定时, 放入队列中;
-
支持定时, 周期性执行。
package com.java.test;import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;public class TestnewScheduledThreadPool {public static void main(String[] args) {ScheduledExecutorService ses = Executors.newScheduledThreadPool(5);//定时执行: 3秒后执行一次/* ses.schedule(new Runnable() {@Overridepublic void run() {System.out.println(Thread.currentThread().getName());}}, 3, TimeUnit.SECONDS);*///周期执行: 参数1: 延时时间 参数2: 周期性执行, 隔多少时间执行一次ses.scheduleAtFixedRate(new Runnable() {@Overridepublic void run() {System.out.println(Thread.currentThread().getName());}}, 0, 3, TimeUnit.SECONDS);}
}
(6)newWorkStealingPool():工作窃取池
工作原理(工作窃取算法):把一个Thread 分叉(fork)成多个子线程。让多个子线程执行本来一个线程应该执行的任务。最后把多个线程执行结果合并。
如果在分叉后一个线程执行完成,另外的线程还没有结束,会从双端队列中尾部处理任务,另一个线程从头部取任务,防止出现线程竞争。