目录
介绍
常用的正则表达式匹配规则表格
1.match()
.group()
常用知识点
1.通用匹配
2.贪婪与非贪婪
3.修饰符
4.转义匹配
2.search()
3.findall()
4.sub()
总结
Hello大家好我是,PYmili!今天给大家带来正则表达式的使用教程即匹配规则表格。建议收藏!

介绍
在Python中的re库就是用于正则表达式的标准库。里面包含了正则表达式的所有规则。而且学会了正则表达式,可以对爬虫有很大提升!所以,快抓紧学起来!
常用的正则表达式匹配规则表格
| \w | 匹配字母和数字以及下划线 |
|---|---|
| \W | 匹配不是字母和数字以及下划线的字符 |
| \s | 匹配任意空白字符串,等价于 " \t \n \r \f " \S 匹配任意不是空白的字符串 |
| \d | 匹配任意数字,相当于[0-9] |
| \D | 匹配任意非数字的字符 |
| \A | 匹配是字符串开头 |
| \Z | 匹配是字符串结尾,如果有换行,只匹配到换行前的结束字符串 |
| \z | 匹配是字符串结尾,如果有换行,同时还会匹配到换行符 |
| \G | 匹配最后匹配完成的位置(数字) |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的结尾 |
| . | 匹配任意字符串,换行符除外 |
| [...] | 表示一组字符,单独列出,比如[PYmili] |
| [^...] | 表示不在[]中的字符串,比如[^PYmili]不匹配字符串PYmili |
| * | 匹配0个或多个表达式 |
| + | 匹配1个或多个表达式 |
| ? | 匹配0个或1个前面的表达式定义的片段,非贪婪方式 |
| {n} | 匹配n个前面的表达式 |
| {n,m} | 匹配n到m次由前面正则表达式的片段,贪婪方式 |
| a|b | 匹配a或b |
| () | 匹配括号里的表达式 |
1.match()
re库中的match函数是一个常用的匹配方法。往里面写入参数就可以检测到这个字符串。
示例:
import re # 导入正则表达式text = "PYmili is the most handsome !" # 要检测的字符串
print(len(text)) # 字符串个数
r = re.match('PYmili', text) # 匹配PYmili字符串
print(r) # 返回
结果:
![]()
<re.Match object; span=(0, 6), match='PYmili'> span返回一个数组表示字符串个数,match返回字符串。
这时候,有个问题。这样返回很麻烦,可以直接返回字符串和数字吗?有办法!
print(r.group()) # 返回字符串
print(r.span()) # 返回数组
.group()
.group()获取结果。我们可以通过索引的方式。获取到内容。
示例:
import re # 导入正则表达式text = "PYmili is the most handsome !" # 要检测的字符串
print(len(text)) # 字符串个数
r = re.match('PYmili\s(\S+)\sthe', text) # 匹配PYmili字符串
print(r)
print(r.group(0)) # 返回索引0位置
print(r.group(1)) # 返回索引1位置

常用知识点
1.通用匹配
刚刚我们写的正则表达式都很繁琐!还要一个一个匹配。那我们可以直接省略里面的符号,字符串,数字。直接返回到结尾吗?当然可以!看示例:
import re # 导入正则表达式text = "PYmili is the most handsome !" # 要检测的字符串
print(len(text)) # 字符串个数
r = re.match('^PYmili.*!$', text) # 匹配PYmili字符串
print(r)
print(r.group())
print(r.span())

可以看到我们制定为: ^PYmili开头 .*用于省略所有 !$结尾 是不是很简单?
2.贪婪与非贪婪
import re # 导入正则表达式text = "PYmili 123456789 numbers test a" # 要检测的字符串
print(len(text)) # 字符串个数
r = re.match('^PYmili.*(\d+).*a$', text) # 匹配PYmili字符串
print(r)
print(r.group())
print(r.group(1))

这里获取他们之间的数字(/d+)用.group()输出但是,如果常理来的话应该是 123456789 但是这里只有一个 9 这是因为。.*会匹配字符\d+在.*后面了。被理解为,单独提出一个数字。那我们要怎么解决这种问题呢?很简单在前面加一个 ? 就可以了
r = re.match('^PYmili.*?(\d+).*a$', text) # 匹配PYmili字符串
print(r)
print(r.group())
print(r.group(1))
3.修饰符
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别匹配 |
| re.M | 多行匹配,影响^和$ |
| re.S | 使.匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响\w,\W,\b和\B |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式更易于理解 |
re.S修饰符在网页匹配中经常用到,因为html会经常换行 。
示例:
import re # 导入正则表达式text = """
<body><h1>标题<h1>
</body>
"""# 要检测的字符串
print(len(text)) # 字符串个数
r = re.match('^\s.*\s$', text, re.S)
print(r)
print(r.group())

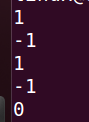
如果没有加 re.S 就会这样

4.转义匹配
import re # 导入正则表达式text = "(PYmili的CSDN博客)https://blog.csdn.net/qq_53280175?spm=1000.2115.3001.5343"# 要检测的字符串
print(len(text)) # 字符串个数
r = re.match('^\(PYmili的CSDN博客\).*\w$', text, re.S)
print(r)
print(r.group())

当遇见这种特殊符字符时在前面添加 \ 转义
没添加 \ 会怎么样?

2.search()
import rehtml = """
<body><div><img scr="http://47.108.189.192/Pymili/image/PYmili.jpg"><img scr="http://47.108.189.192/Pymili/image/R-C.jpg"></div>
</body>
"""img = re.search('<div.*?<img.*?scr="(.*?)>.*?<img.*?scr="(.*?)">.*?</div>', html, re.S)
print(img)
print(img.group())
print(img.group(1))
print(img.group(2))

与match()大致相同!
3.findall()
import rehtml = """
<body><div><img scr="http://47.108.189.192/Pymili/image/PYmili.jpg"><img scr="http://47.108.189.192/Pymili/image/R-C.jpg"></div>
</body>
"""img = re.findall('<div.*?<img.*?scr="(.*?)>.*?<img.*?scr="(.*?)">.*?</div>', html, re.S)
print(img)
for i in img:print(i[0])print(i[1])

可以看到,findall就是返回为列表形式。使用方法与前两个相同
4.sub()
import retext = "PYmili 6661314520bug改完了吗?"msg = re.sub('\s\d+', '你', text)
print(msg)

到这里就可以看出来了吧!这个就是一个替换函数!
总结
这里就讲解一些基本使用方法!接下来就由大家自行实践咯!好的,喜欢这篇论文的小伙伴,多多关照!可以加群共同学习:706128290 我是PYmili!下次再见!