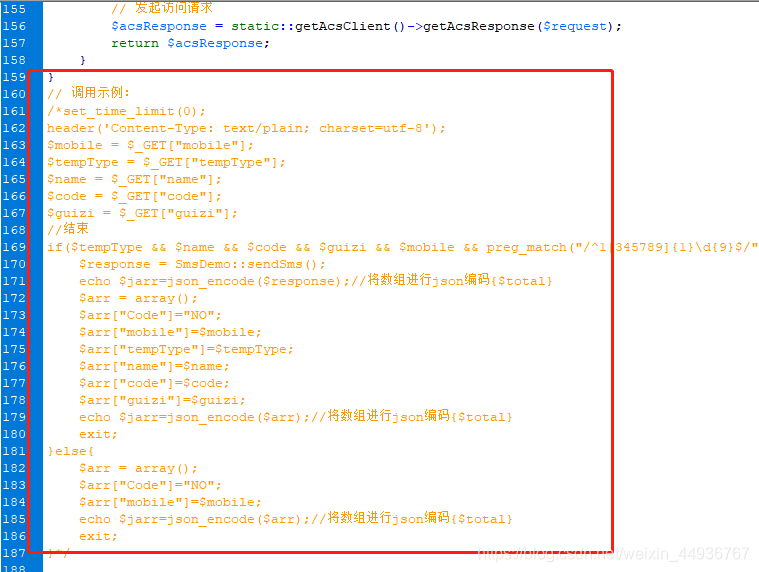
要获取淘宝联盟的数据第一步当然是分析淘宝联盟的 html 啦。
话不多少说,我们开始吧。
-
首先我们进入淘宝客的主站 https://pub.alimama.com/

-
随便点一个进入商品推广页面,如女装尖货(女人的钱是最好赚的啦!)。

-
按 F12 打开元素审查,选择 Network 选项卡,再刷新下页面,仔细观察网络请求变化。我们可以看到有如下一个请求,这个请求是干嘛的呢?这个请求的当然就是请求的可以进行推广的商品啦。

-
点击
preview进入到预览,让我们看一看请求的数据结构,pageList就是我们需要的商品信息啦。

-
那么我就可以用上面的请求去爬取优惠券信息啦。通过上面,可以看到这是一个
Http-get请求,得到的是一个标准的Json结构的数据。那么我们就可以使用requests来模拟get请求,然后使用json将数据解析出来。
def crawler_product(cookie, dit):for i in range(1 if dit['start_page']==0 else dit['start_page'], 1000 if dit['end_page']==0 else dit['end_page']):end = crawler_product_page(dit, i, cookie)if end:print u'======================== 结束 ========================'breakdef crawler_product_page(dit, page, cookies):print u'============================= 开始抓取第 ' + str(page) + u'页 ============================='print u'url ==> ' + get_product_url(dit['product_url'], page)print '\n'r = requests.get(get_product_url(dit['product_url'], page), cookies=cookies)info = r.json()['data']
源码
- Github:https://github.com/iQuick/TB-Crawler