一、前言
前面讲了关于 内存 方面的优化,那么接下来的文章我们主要聚焦于 性能 的优化,那么主要体现在优化程序 速度 上。程序的 速度 很大程度上会影响用户体验或者程序的实际效用,所以优化 性能速度 也是程序员需要关注的一个方面,从本文起接下来的几篇文章将讲述如何对 程序性能 进行优化。
二、优化思想
在讲解优化之前,我们先看一下 优化的思想,它可以保证我们在学习或者优化的过程中保持对问题的关注,让我们知道是在学习什么跟如何优化。
2.1 性能分析瓶颈分类
说到优化,一个程序运行慢可能是有多种原因构成的,那么前辈们就将这多种原因归结为以下 3类:
程序的运算量很大,导致 CPU 过于繁忙。称为 CPU 瓶颈。
程序需要做大量的 I/O,读写文件、内存操作等等,CPU 更多的是处于等待。称为 I/O 瓶颈。
程序之间相互等待,结果 CPU 利用率很低,但运行速度依然很慢,事务间的共享与死锁制约了程序的性能
2.2 优化基本原则
等效原则:优化前后程序实现的功能一致。
有效原则:优化后要比优化前运行速度快或占用存储空间小,或二者兼有。
经济原则:优化程序要付出较小的代价,取得较好的结果。
另外一般有 5 个基本纲领为我们提供优化思路:
Do it faster: 程序除了 实现功能 之外,还需要 提高其运行速度。
Do it in parallel:能够 并行执行程序 的话,我们就可以 充分利用CPU资源,从而加速程序运行速度。
Do it later:对于时间紧迫的功能,有些不必要的功能,可以考虑延后执行,使程序的任务减轻,从 而腾出资源,来做重要的事。
Don't do it at all:设计程序时,不要加入多余无用的代码 来实现 *模块化或者提高可读性。
Do it before:程序有可能并不需要一直工作,我们可以把一些工作在 系统空闲 时完成,这样可以减轻繁忙时程序的负担。
2.3 优化思路
在程序优化上,往往 20%的代码 占用了 80%的运行时间,所以我们需要找出这 20% 的代码。所以 如何找出需要优化的代码 是一个我们需要关注的问题,而这个问题我们可以有一些工具来解决,在下面的章节会提到。
第一步:找出 性能瓶颈的代码,在笔者看来,分析程序问题,找出性能瓶颈是重中之重。
第二步:进行 代码优化
2.4 优化经验总结:
下面是书中提到的一些 优化经验,在了解这些经验之前,我们需要了解几个概念:
提高程序的效率:程序的 时间效率是指运行速度
空间效率:是指程序 占用内存或者外存的状况
全局效率 是指站在 整个系统的角度上考虑的效率
局部效率 是指站在 模块或函数角度上考虑 的效率
书中经验总结如下:
不要一味地追求程序的效率,应当在满足 正确性、可靠性、健壮性、可读性 等质量因素的前提下,设法提高程序的效率。
以提高程序的 全局效率为主,提高 局部效率为辅。
在优化程序的效率时,应当先找出限制效率的 瓶颈,不要在无关紧要之处优化。
先优化 数据结构和算法,再优化 执行代码。
有时候 时间效率 和 空间效率 可能对立,此时应当分析那个更重要,作出适当的折衷。例如多花费一些内存来提高性能。
不要追求 紧凑的代码,因为 紧凑的代码 并不能产生 高效的机器码。
当心那些视觉上不易分辨的操作符发生 书写错误。 比如会把 == 误写成 =,像 ||、&&、<=、>= 这些符号也很容易发生 丢1失误。然而 编译器却不一定能自动指出这类错误。
变量(指针、数组) 被创建之后 应当及时把它们初始化,以 防止把未被初始化的变量当成右值使用。
当心变量的 初值、缺省值错误,或者精度不够。
当心 数据类型转换发生错误。尽量使用 显式 的数据类型转换,避免让 编译器轻悄悄地进行隐式的数据类型转换。
当心变量发生 上溢或下溢,数组的 下标越界。
当心忘记编写 错误处理程序,且要注意防止 错误处理程序本身有误。
当心 文件 I/O 有错误。
避免 编写技巧性很高代码。
不要设计 面面俱到、非常灵活的数据结构。
如果原有的代码质量比较好,尽量复用它。但是 不要修补很差劲的代码, 应当重新编写。
尽量使用 标准库函数,不要 发明已经存在的库函数。
尽量不要 使用与具体硬件或软件环境关系密切的变量。
把编译器的选择项设置为 严格状态。
如果可能的话,使用 PC-Lint、LogiScope 等工具进行代码审查。
2.5 优化的层次
在我们了解到了 程序瓶颈 之后,接下来我们就要考虑对代码进行优化:
程序的优化,主要包括四个层次:
算法和数据结构的优化
编译器优化
代码优化
硬加速
优化新手容易犯的错误就是:找到 程序热点 时,过于兴奋,急匆匆的就开始 局部代码 的优化。但我们需要在 更大的范围内分析,是什么导致这个 程序瓶颈 的存在,有时可能根本就不需要改动你的程序。
三、性能评估
一般情况下,我们可以把 性能优化 分为 2 个部分
性能评估:一般而言,程序都有 二八法则。20%的代码影响80%的速度。我们需要找出这20% 的代码进行优化,对其进行 瓶颈分析,找出影响速度的原因。
性能优化:找出原因和需要优化的代码后,利用 编译、硬件 及 算法和数据结构 等对其进行优化。
3.1 系统及进程性能评估
据上面所讲,性能评测 是至关重要的一个环节,如果不知道哪里出了问题,那么优化就无从下手。程序性能的问题是有很多原因的,我们先看看一般的问题分析:
/proc目录下系统相关的文件
/proc目录下进程相关的文件
3.1.1 proc系统相关
系统相关属性 我们可以通过下面 2 个文件来了解。
3.1.1.1. /proc/stat
我们使用 cat /proc/stat 来获取 系统相关 的信息,这样可以知道我们 系统效率 的具体细节
运行结果.png
下面 按行 说明各行数据的意义:
cpuN:其数值分别代表着 CPU 在 不同状态 下所用的时间,其单位为 jiffies(0.01s)。
user:从 系统启动 开始累计到 当前时刻,用户态的 CPU时间,不包含 nice值为负 的进程。 在图中的值为 19。
nice:从 系统启动 开始累计到 当前时刻,nice值为负 的进程所占用的 CPU时间。 在图中的值为 0。
system:从 系统启动开始累计到 当前时刻,内核 所占用的 CPU时间。 在图中的值为 166。
idle:从 系统启动 开始累计到 当前时刻,除 硬盘IO等待时间 的以外其它等待时间。 在图中的值为 218632。
iowait:从 系统启动 开始累计到 当前时刻,硬盘IO 等待时间。 在图中的值为 73。
irq:从 系统启动 开始累计到 当前时刻,硬中断时间。在图中的值为 0。
softirq:从 系统启动 开始累计到 当前时刻,软中断时间。在图中的值为 0。
stealstolen:在 虚拟化环境中 运行时在 其他操作系统 上花费的时间
guest:Linux内核 控制下为 虚拟操作系统 运行 虚拟CPU 所花费的时间
intr:从 系统启动 开始累计到 当前时刻,发生的 所有中断的次数。每个数 对应一个特定的 中断。
ctxt:从 系统启动 开始累计到 当前时刻,CPU 发生的 上下文交换 的次数。
btime:从 系统启动 开始累计到 当前时刻 的 时间,单位为秒。
processes:从 系统启动 开始累计到 当前时刻 ,系统所创建的 任务数目。
procs_running:当前 运行队列 的任务数目。
procs_blocked:当前 被阻塞 的任务数目。
3.1.1.2. CPU利用率
CPU利用率是指CPU工作时间占总时间的比重, 简单地理解为 单位时间内 CPU处于忙状态的时间占比。
摘抄附录《CPU利用率与Load Average的区别?》中的说法:
CPU利用率 可以看出在某一个时间段内CPU被占用的情况,如果CPU被占用时间很高,那么就需要考虑CPU是否已经处于超负荷运作,长期超负荷运作对于机器本身来说是一种损害,因此必须将CPU的利用率控制在一定的比例下,以保证机器的正常运作。
有一种情况需要注意的是:使用 自旋锁 等 忙等处理的锁会导致 CPU利用率的上升,此时 CPU利用率 并不能很好的反映 CPU的使用情况。
CPU时间 = user + system + nice + idle + iowait + irq + softirq
CPU利用率 = 1 - (idle) / CPU时间。用于测量当前系统的 CPU负载情况。
CPU用户态利用率 = (user+nice) / CPU时间。用于测量 用户程序 对 CPU的占用率。
CPU内核态利用率 = (system) / CPU时间。如果程序有大量的 系统调用,导致 Linux内核 占用了大量的 CPU,可以使用该数值来测量。
IO利用率 = iowait / CPU时间,测量 FLASH、内存 等存储介质的 交互和等待时间。
3.1.1.3. /proc/loadavg
运行结果.png
loadavg 主要检查当前系统的 负载情况:下面 按从左到右 逐个说明:
1分钟 的平均负载
5分钟 的平均负载
15分钟 的平均负载
在采样时刻,运行队列的任务的数目,与 /proc/stat 的 procs_running 表示相同意思
在采样时刻,系统中 活跃的任务个数(不包括运行已经结束的任务)
最大的 pid值,包括 轻量级进程(即线程)。
更多关于 CPU负载 的讲述可以参考 3.2.1.2小节。
3.1.2 proc进程相关
3.1.2.1 proc进程相关属性
要查看 进程状态 ,先需要进入 进程 在 proc目录 下的文件夹,然后使用 cat stat 查看其状态,
如图:
进程stat
下面按顺序逐个介绍各个数据的意义:
pid:进程号(包括线程) ,在图中值为 89。
comm:应用程序 的名字,在图中值为 sshd。
task_state:任务的状态,,在图中值为 S。其各个状态如下:
R:runnign,即 运行态
S:sleeping(TASK_INTERRUPTIBLE),即 睡眠态(可被打断)
D:deep sleep(TASK_UNINTERRUPTIBLE),即 睡眠态(不可被打断)
T:stopped,即 停止态
t:tracing stop,即 暂停态(可被继续)
Z:zombie,即僵尸态
X:dead,即死亡态
ppid:父进程ID,在图中值为 1。
pgid:线程组号,在图中值为 89。
sid:该任务所在的 会话组ID,在图中值为 89。
tty_nr:该任务的 tty终端设备号,在图中值为 0。
tpgid:终端的 进程组号,即当前运行在该任务所在终端的前台任务 (包括shell及应用程序) 的 PID,在图中值为 -1。
task_flags:进程标志位,查看该任务的特性,在图中值为 4194624。
min_flt:该任务不需要从硬盘拷数据而发生的 次缺页次数,在图中值为 107。
cmin_flt:该任务的累计所有的 waited-for进程 曾经发生的 次缺页次数,在图中值为 364。
maj_flt:该任务需要从硬盘拷数据而发生的 主缺页次数 ,在图中值为 0。
cmaj_flt:该任务累计的所有的 waited-for进程 曾经发生的 主缺页次数,在图中值为 0。
utime:该任务在 用户态 运行的时间(单位为jiffies),在图中值为 0。
stime:该任务在 核心态 运行的时间(单位为jiffies),在图中值为 0。
cutime:该任务累计所有的 waited-for进程 曾经在 用户态 运行的时间(单位为jiffies),在图中值为 12。
cstime:该任务累计所有的 waited-for进程 曾经在 核心态 运行时间(单位为jiffies),在图中值为 7。
priority:任务的 动态优先级,在图中值为 20。
nice:任务的 静态优先级,在图中值为 0。
num_threads:该任务所在的 线程组里的 线程个数,在图中值为 1。
it_real_value:由于 计时间隔 导致的下一个 SIGALRM 发送进程的时延(单位为jiffies), 在图中值为 0。
start_time:在系统启动后,到与该任务启动时的间隔(单位为jiffies), 在图中值为 247。
vsize:该任务的 虚拟地址空间大小,在图中值为 4268032。
rss:该任务当前 驻留物理地址空间的大小,这些页可能用于 代码、数据和栈 。在图中值为 416。
rlim:该任务能驻留物理地址空间的 最大值 (单位为byte),在图中值为 4294967295。
start_code:该任务在虚拟地址空间的 代码段 的起始地址,在图中值为 4648960。
end_code:该任务在虚拟地址空间的 代码段的结束地址,在图中值为 5267368。
start_stack:该任务在虚拟地址空间的 栈的结束地址,在图中值为 3198615200。
kstkesp:sp指针(堆栈指针) 的当前值, 与在进程的内核堆栈页得到的一致,在图中值为 0。
kstkeip:ip指针(指令指针)的当前值,指向将要执行的 指令指针,在图中值为 0。
pendingsig:待处理信号 的位图,记录发送给进程的普通信号,在图中值为 0。
blocksig:阻塞信号 的位图 ,在图中值为 0。
sigignore:忽略信号 的位图,在图中值为 4096。
sigcatch:被俘获信号 的位图 ,在图中值为 81925。
wchan:如果该进程是 睡眠状态,该值给出 调度的调用点 ,在图中值为 1。
nswap:被 swapped 的页数 (当前没用) ,在图中值为 0。
cnswap:所有子进程被 swapped 的页数的 和 (当前没用),在图中值为 0。
exit_signal:该进程结束时,向父进程所发送的信号,在图中值为 17。
processor:运行的 CPU编号 ,在图中值为 0。
rt_priority:实时进程 的 相对优先级别,在图中值为 0。
task_policy:进程的调度策略,其各个值如下,在图中值为 0:
0:非实时进程
1:FIFO实时进程
2:RR实时进程
delayacct_blkio_ticks:累计的 块I/O延迟,以 clock tick 为单位。在图中值为 0:
guest_time:为虚拟操作系统运行虚拟CPU所花费的时间,以 clock tick 为单位。在图中值为 0。
cguest_time:进程的 子进程 用于用户操作系统的时间,以 clock tick 为单位。在图中值为0。
start_data:进程的 数据段 和 BSS段 的 起始地址。在图中值为 5335032。
end_data:进程的 数据段 和 BSS段 的 结束地址。在图中值为 5342208。
start_brk:进程的 堆 的 起始地址。在图中值为 5365760。
arg_start:进程存放 命令行参数 的 起始地址。在图中值为 3198615427。
arg_end:进程存放 命令行参数 的 结束地址。在图中值为 3198615442。
env_start:进程存放 环境变量 的 起始地址。在图中值为 3198615442。
env_end:进程存放 环境变量 的 结束地址。在图中值为 3198615533。
exit_code:进程的 退出码。在图中值为 0。
3.1.2.2 使用proc进程相关属性计算CPU占有率
先看看下面的公式:
进程CPU占用率 = 进程占用CPU时间 / 系统总的时间。
进程占用 CPU 时间:可以从 进程的stat文件 获得,包括 utime、stime、cutime、cstime。
系统总的时间:可以通过 /proc/stat 或者 gettime函数 获得。
想要计算 CPU占有率 还对 进程的运行采样,一般需要 2个采样点:
采样点1:
系统时间记为 sys1
进程时间分别记为:utime1、stime1、cutime1、cstime1
采样点2:
系统时间记为 sys2
进程时间分别记为:utime2、stime2、cutime2、cstime2
经过计算和采样后可以按照下面的公式来计算:
进程CPU占用率 = ((utime2+stime2-cutime2-cstime2)-(utime1+stime1-cutime1-cstime1)) / (sys2-sys1)
进程用户态占用率 = ((utime2-cutime2)-(utime1-cutime1)) / (sys2-sys1)
进程内核态占用率 = ((stime2-cstime2)-(stime1-cstime1)) / (sys2-sys1)
3.2 系统性能评估工具
3.2.1 top
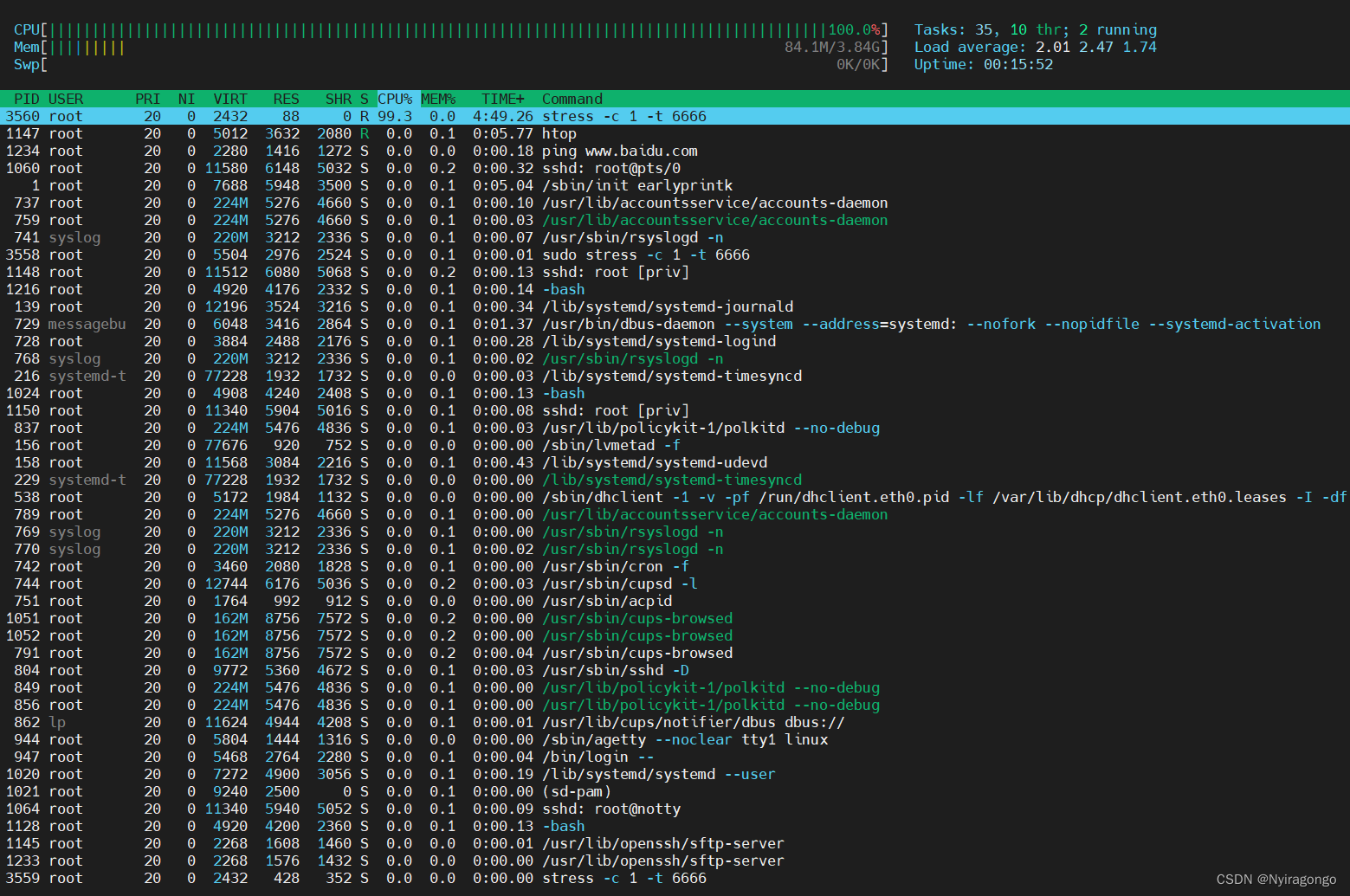
top 是一个常用的 性能分析 软件,运行结果如下图所示:
运行结果
下面将 top 分 2 点来讲述:
内存分析
CPU及负载分析
3.2.1.1 内存分析
运行结果如下图所示:
内存
可以看到它统计的内存有:used、free、shrd、buff、cached。
各个内存的含义在前面的 内存分析 文章中已经说过,这里不再赘述
3.2.1.2 CPU及负载分析
1. CPU负载
Load Average 即 CPU负载 ,该数据是 每隔5秒钟 检查一次活跃的进程数,然后按特定算法计算出的数值。
Load Average 可以理解为 CPU 的带载情况,即有多少进程需要 CPU 来处理。它并不是描述 CPU的使用情况,其本质应该是 在单位时间内,CPU正在处理的进程数以及等待CPU处理的进程数之间的和,也就是CPU进程队列的统计信息。
Load Average 越高说明越多的进程在抢占CPU,因而会导致 CPU资源的竞争越来越激烈,对于CPU资源的申请和维护的成本也会加大
理想情况下是一个CPU带一个进程,这样就不会发生CPU资源抢占。所以在一般情况下,如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。
CPU利用率和CPU负载的区别:
CPU利用率指的是 程序在运行期间实时占用的CPU百分比
CPU负载指的是 一段时间内正在使用和等待使用CPU的平均任务数。
两者之间并没有太大的关联。比如一个进程一直在使用CPU进行运算,那么此时CPU利用率会达到100%,但平均负载则趋近于 1。反过来说,当CPU的工作负载越大,代表CPU必须要在不同的工作之间进行频繁的工作切换。
按照笔者的理解:
CPU密集型进程容易让CPU利用率升高
I/O 密集型进程容易导致平均负载升高
频繁调度进程容易让平均负载和CPU利用率升高
2. CPU利用率及负载
CPU及负载
usr:用户空间 占用CPU的百分比。
sy:内核空间 占用CPU的百分比。
nic:改变过优先级的进程占用CPU的百分比
id:空闲 CPU百分比
io: IO等待 占用CPU的百分比
irq:硬中断 占用CPU的百分比
sirq:软中断 占用CPU的百分比
Load average:指 CPU的 负载均衡,后面的三个数分别是 1分钟、5分钟、15分钟的负载情况。
2.2.1.3 进程分析
image.png
PID:进程ID
PPID:父进程ID
USER:进程所有者
STAT:当前进程的状态,其值可以参考 进程stat 的 task_state
VSZ:进程的 虚拟大小
%CPU:上次更新到现在的CPU时间占用百分比
COMMAND:运行的 命令行
3.2.2 vmstat
在嵌入式设备上,busybox 是不带有该工具,而该工具的源码也不是独立的,而是在 procps 这个中聚集中。关于 procps 的交叉编译请参考附录中的:
json-c 交叉编译(undefined reference to rpl_malloc )
交叉编译Procps-ng-3.3.11
编译完成后将相应的文件拷贝到设备端上就可以使用 vmstat 工具了,运行结果如下:
运行结果
该命令的意思是:每隔1秒运行1次vmstat,一共运行5次。
数据含义如下:
procs:系统中的进程状态
r(running):运行队列中的进程数量。
b(block): 在阻塞等待IO的进程数量。
memory:系统的内存使用情况
swpd:使用的虚拟内存 大小。如果 swpd 的值不为0且 SI,SO的值长期为0,这种情况不会影响系统性能。
free:空闲物理内存 大小。
buff:用作 文件缓冲 的内存大小。
cache:用作 缓存 的内存大小,如果cache值大,说明缓存的文件数多,如果频繁访问到的文件都能被cache中,那么磁盘的 读IO(bi) 会非常小。
swap:内存交换情况
si:每秒从交换区写到内存的大小,由磁盘调入内存。
so:每秒写入交换区的内存大小,由内存调入磁盘。
注意: 内存够用的时候,这2个值都是 0。如果这2个值长期大于0时,系统性能会受到影响,磁盘IO 和 CPU资源 都会被消耗。不能因为观察到 空闲内存(free) 很少或接近于0时,就认为内存不够用了。还需要结合 si 和 so。如果 闲内存(free)很少,同时si 和 so 也很少(大多时候是0),那么此时说明内存刚好够用,系统性能暂时不会受到影响的。
IO:系统IO的使用情况,如果值越大
bi:每秒读取 的块数
bo:每秒写入 的块数
注意:随机磁盘读写的时候,bi** 和 bo 值越大,能看到 CPU 的 IO等待(wa) 也会越大。**
system:系统情况
in:每秒中断数,包括时钟中断。
cs:每秒上下文切换数。
注意: 随机磁盘读写的时候,in 和 cs 值越大,能看到 CPU 的 内核消耗的CPU时间(sy) 也会越大。
CPU:CPU 的使用情况,以 百分比表示
us:用户进程执行时间百分比(us) 的值比较高时,说明 用户进程消耗的CPU时间多。如果该值长期超 50%,那么我们就该考虑对程序进行优化。
sy: 内核系统进程执行时间百分比(sy) 的值高时,说明 系统内核消耗的CPU资源多。此时系统的情况比较糟糕,我们需要排查原因并优化
wa:IO等待时间百分比(wa) 的值高时,说明 IO等待 比较严重。这可能由于 磁盘大量作随机访问造成,也有可能 磁盘出现瓶颈(块操作)。
id:空闲时间百分比
四、查找性能瓶颈
在分析程序的时候,往往需要找个程序的 性能瓶颈。从而对 性能瓶颈 进行优化,这样可以取得比较大的收益。我们一般都使用功能来查找 性能瓶颈,一般有 gprof、OProfile 或者 perf 等。本文着重说明一下 perf 的使用方法,及如何将 perf 获取到的数据转换为 火焰图 来分析程序性能。
4.1 perf
4.1.1 perf编译
perf 依赖于几种库,分别如下:
zlib
elfutils
binutils
其中 binutils 就是我们常用的 readelf、ar 等编译器工具,一般情况下我们的 交叉编译链 都有自带,所以我们需要自行编译 zlib 和 elfutils
1. zlib交叉编译
点击 zlib 源码。
解压并进入 zlib的目录
使用命令导出 交叉编译工具,命令举例如下:
export CC=arm-linux-gnueabihf-gcc
使用命令进行配置,该命令会直接将编译出来的库自动加入到我们的 库路径,我们就不再需要去指定 库路径 了。如下:
./configure --host=arm-linux-gnueabihf --prefix=/your_compiler_path/arm-linux-gnueabihf/libc/usr
附录
编译安装
make -j12 && make install
2. elfutils交叉编译
我们编译 elfutils 是需要其里面的库 libelf。编译过程依赖 2 个工具 m4 和 bison。在编译前请检查编译机是否有安装该工具。编译步骤如下:
点击 elfutils 源码。
解压并进入目录
使用命令进行配置:
./configure --host=arm-linux-gnueabihf --prefix=/your_compiler_path/arm-linux-gnueabihf/libc/usr/ --disable-debuginfod
编译安装
make -j12 && make install
3. perf交叉编译
perf源码 在我们开发板上 linux 的源码中,其路径一般是 /your_linux_path/tool/perf。
编译步骤如下:
进入 perf 源码目录
使用命令进行编译
make LDFLAGS=-static ARCH=arm CROSS_COMPILE=arm-linux-gnueabihf- DEBUG=1 HAVE_CPLUS_DEMANGLE=1
编译完成后在 perf目录下 有个叫 perf 的执行文件。将 perf、libz 和 libelf 拷贝到开发板上对应的位置,就是 库路径和执行文件路径
4.1.2 perf概念
perf 的原理是通过对 系统事件 进行 统计采样 得到 统计数据,再通过分析 统计数据 得出性能瓶颈的结果。
perf 中能采样 系统事件 分为以下 3 类:
Hardware Event:由 PMU部件或芯片硬件如cache等 产生,在特定的条件下探测 硬件系统事件是否发生以及发生的次数。
Software Event:是内核产生的事件,分布在各个功能模块中,统计和操作系统相关性能事件。比如进程切换,clock_tick数等。
Tracepoint Event:tracepoints 是散落在内核源码中的一些 hook函数,它们可以在特定的代码被执行到时触发,比如 slab分配器的分配次数。根据一特性,perf 将 tracepoints 产生的时间记录下来,生成报告,通过分析这些报告对性能做出准确的判断。
4.1.2 perf使用方法
perf 是一个工具集,一共包含 20多种 工具,下面看看常用的 5种工具。
1. perf list
perf 的运行原理就是对 系统事件 进行采样,从而得到相关数据来分析。我们可以使用perf list 来查看编译出来的 perf 支持哪些 系统事件。每个 linux版本 的 perf 可能有所不同。笔者的运行结果如下:
运行结果
可以看到一共有 10种软件事件 和 3种硬件事件。笔者编译出来的 peff 比较简陋,所以本文主要讲述 软件事件 相关的分析。
2. perf stat
perf stat 可以统计 程序 的 整体情况,它能够显示出 程序 的 系统事件 统计数据。一般用于 分析程序的整体性能
常用选项如下 :
-a(--all-cpus):显示 所有CPU上的统计信息。
-C(--cpu ):显示 指定CPU的统计信息。
-D(--delay ):指定 命令的延迟统计时间,单位为 毫秒。
-d(--detailed):显示更多细节信息。
-e(--event ):统计 指定事件 的数据。
-o(--output ):输出统计信息到文件。
-p(--pid ):对指定 pid的进程 进行统计。
-t(--tid ):对指定 tid的线程 进行统计。
-r(--repeat ):重复命令 n次 并显示 平均结果
-S(--sync):在开始执行前使用 sync函数。
运行结果如下:
image.png
perf stat 显示的默认 统计信息如下:
task-clock-msecs:指 CPU利用率。该值越高,说明程序花费越多的时间在 CPU计算 上而不 文件IO。
context-switches:指 进程切换次数,记录了程序运行过程中发生 进程切换 的次数。应当尽量避免频繁的进程切换。
cache-misses:指 **程序运行过程中的 cache非命中次数。如果该值越高,说明程序的 cache命中率越低。
cache-references:指 **程序运行过程中的 cache命中次数。如果该值越高,说明程序的 cache命中率越高。
CPU-migrations:表示 进程 在运行过程中发生的 CPU迁移次数。
cycles:处理器时钟周期,一条机器指令可能需要多个 cycles。
instructions:指 程序的机器指令数目。
IPC:指 instructions/cycles 。该值越大,说明 程序越充分利用了处理器
3. perf top
perf top 与 top 不同的是。top 常用于分析系统的整体性能。而 perf top 可以精确到系统或程序中 函数级的运行情况
常用选项如下 :
-e :指明要分析的性能事件。
-p :仅分析 pid目标进程及其创建的线程。
-k :带符号表的内核映像所在的路径,用于注释函数。
-K:不显示属于内核或模块的符号。
-U:不显示属于用户态程序的符号。
-d :界面的 刷新周期,默认为 2s。因为 perf top 默认 每2s 从 mmap 的内存区域读取一次性能数据。
--call-graph fractal:路径上的调用率为 相对值,加起来为100%。调用顺序为 从下往上。
perf top --call-graph graph:路径调用率为 绝对值,加起来为该函数的 热度。
运行结果如下:
image.png
第一列:符号引发的 性能事件的比例,默认指 占用的cpu周期比例。
第二列:符号所在的 DSO(Dynamic Shared Object),可以是 应用程序、内核、动态链接库、模块。
第三列:DSO的类型。
[.]:表示此符号属于 用户态的ELF文件,包括 8可执行文件与动态链接库*。
[k]:表述此符号属于内核或模块。
第四列:符号名。如果有些符号 不能解析为函数名,只能用 地址 表示。
4. perf record
perf record 可以 用于记录perf统计的数据 并输出到 文件perf.data,并使用相关工具生成 可视化 图像来分析程序。配合 perf report 可以精确的分析程序
常用选项:
-e:指定记录的 系统事件
-a:指定记录 所有CPU的事件
-p:记录指定 pid进程的事件
-o:指定 保存数据的文件名
-g:指定 生成函数调用图
-C:记录 指定CPU的事件
-F:设置统计频率
这里不展开说 perf report,我们使用另一个强有力的工具 火焰图FlameGraph,可以在 github 上找到火焰图的项目,点击下载火焰图生成软件
下面我们通过一个例程来说明:
#include
#include
#include
#include
#include
void* func_test1(void* arg)
{
int j = 0;
for(int i = 0; i < 90000000; i++)
j=i;
return NULL;
}
void* func_test2(void* arg)
{
int j = 0;
for(int i = 0; i < 120000000; i++)
j=i;
return NULL;
}
int main()
{
pthread_t test1 = 0;
pthread_t test2 = 0;
pthread_create(&test1, NULL, func_test1, NULL);
pthread_create(&test2, NULL, func_test2, NULL);
pthread_join(test1,NULL);
pthread_join(test2,NULL);
return 0;
}
注意,在使用时需要注意要加参数 -g。
步骤如下:
在设备上运行 perf record -a -g your_program
使用命令 perf script -i perf.data > perf.unfold 将生成的 perf.data 转换为 perf.unfold
将生成的 perf.unfold 拷贝到宿主机上
使用 FlameGraph 中的工具执行命令 ./stackcollapse-perf.pl perf.unfold > perf.fold
使用命令 ./flamegraph.pl perf.fold > perf.svg 生成 svg文件
使用 浏览器 打开 svg文件 (笔者使用的是chrom)
结果如下:
运行结果
可以看到 func_test1 和 func_test2 占据了 执行时间 的大头,在旁边还有 2个 函数在执行。
点击 左侧红框 查看如下:
左侧
从结果中可以看到是 perf 自身的调用情况。
再点击 右侧红框 查看如下:
右侧
可以看到是一个名为 swapper 的函数在执行,而这个函数是干什么用的呢?
其实在 CPU 执行程序时,空闲的时候就会调用 swapper 函数,此时 CPU 处于 idle状态。
五、程序优化
前面我们讲了 程序优化 的几个层次,分别是:
算法和数据结构的优化
编译器优化
代码优化
硬加速
其中 算法和数据结构的优化 不在本文内容计划之内。使用 SIMD指令硬加速 已经在笔者的其他博客 neon指令 系列一将说到。 下面主要简单地讲述一下 编译器优化 和 代码优化。
5.1 编译器优化
编译器按照 arm-linux-gcc 系列来说明。下面将按书中所写,列举出 gcc 的相关编译优化选项。如果你想 关掉 某一个优化选项, 你可以在 -f 和 优化选项 之间增加 no。
在编译时,我们一般回加入 -O1、-O2和-O3 等选项,其实它们的作用就是让编译器进行不同程度的优化,那么每种优化打开的编译选项都不同,下面看看每种优化都打开了哪些选项。
5.1.1 -O1优化
-fcprop-registers:
即 复写传播,一般情况下该选项会与 常量折叠 一起出现。因为在函数中把寄存器分配给变量,所以编译器执行二次检查以便 减少调度依赖性 并且 删除不必要的寄存器复制操作。以下面的代码作说明。
const int i = 2*2;
编译器确实将 2*2 算成 4 了,以后碰到 i 就用 4 替换,这个计算 2*2 的过程据说叫 常量折叠(const folding),而用 4 替换 i 的过程叫做 复写传播(copy propagation)。
-fdefer-pop:
该优化选项与 函数返回 有关。 一般情况下,函数返回,输入参数被立即弹出堆栈后。但该优化选项会 推迟弹出函数调用的输入参数,等必要时与几个函数调用参数一起弹出。这样可以 节省处理时间,但也 会使堆栈中的内容有些杂乱。
-fdelayed-branch:
该选项会让编译器 试图根据指令周期时间重新安排指令, 把尽可能多的指令 移动到条件分支前,以便充分的利用处理器的 缓存。
-fguess-branch-probability:
该选项直译为 猜测分支可能性,该选项试图让编译器 确定条件分支可能的结果,并且移动相应的指令。这有可能导致不同的编译器会编译出迥然不同的目标代码。
-fif-conversion:
if-then 语句应该是程序中仅次于循环的最消耗时间的语句。简单的if-then语句可能在最终的 汇编代码 中产生 较多条件分支。 通过 减少或者删除条件分支 ,以及使用 条件传送、设置标志 和 运算技巧 来替换 if-then语句。由此编译器可以减少 if-then语句 花费的时间量。
-fif-conversion2:
相比于 -fif-conversion , -fif-conversion2 加入更高级的 数学特性, 减少实现 if-then语句 所需的 条件分支 。
-floop-optimize:
优化循环 通常可以很大程度地 提高程序性能。一般情况下,程序会存在 大型且复杂的循环。通过删除在循环内没有改变值的变量赋值操作,可以 减少循环内执行指令的数量,在很大程度上提高性能。 同时也优化那些确定何时离开循环的条件分支, 以便减少分支的影响。
-fmerge-constants:
尝试(string constants and floating point constants)
该选项会让编译器试图 横跨编译单元合并同样的常量。这一特性有时候会导致 很长的编译时间。
5.1.2 -O2优化
-falign-functions:
这个选项用于使 函数对准内存中特定边界的开始位置。大多数处理器按照页面读取内存,并且确保全部函数代码位于单一内存页面内。这样 同一函数就不需要读取到多个内存页中。
-fcaller-saves:
该选项可以让编译器对 函数调用 只进行一次 寄存器的保存和恢复操作,而不是在每个函数调用中都进行。 如果调用多个函数, 这样能够节省时间。
-fcrossjumping:
该选项让编译器 跨越跳转的转换代码进行处理, 以便组合分散在程序各处的相同代码。 这样可以 减少代码的长度, 但是有可能不会对程序性能产生直接影响。
-fcse-follow-jumps:
CES即通用子表达式消除技术(common subexpression elimination)。在程序中,有时候会有一些 无法到达的代码,该选项让编译器查找程序中的此类代码,然后跳过该代码的 跳转指令。最常见的就是 if-else 的 else部分
-fdelete-null-pointer-checks:
该选项让编译器扫描 汇编语言代码,检查可能存在 空指针的代码。 编译器假设间接引用空指针将 停止程序。
-fexpensive-optimizations:
该选项让编译器执行 代价高昂的各种优化技术(编译时的角度)。但是不一定保证运行时性能能提升,有可能对运行时的性能产生负面影响。
-fforce-mem:
该选项让编译器在做算术操作前,强制将内存数据copy到寄存器 中以后再执行。对于只涉及 单一指令的变量来说,这样也许不会有很大的优化效果。但是对于 很多指令中都涉及到的变量(比如数学操作) 来说,这时有显著的优化。因为和访问内存中的值相比,处理器访问寄存器中的值要快的多。
该选项有可能导致 内存与寄存器之间的数据不一致。对于某些依赖 内存操作顺序而进行的逻辑,需要做 严格的处理 后才能进行优化。例如采用 volatile关键字限制变量的操作方式或者 利用barrier迫使cpu严格按照指令序执行。
-fgcse:
该选项让编译器 所有汇编代码执行全局通用表达式消除。该操作 试图分析汇编代码并且结合通用片段,消除冗余的代码段。如果代码使用 计算性的goto,推荐 使用-fno-gcse选项关闭该优化选项。
-foptimize-sibling-calls:
该选项可以优化 尾递归的调用。一般情况下 递归的函数 可以被 展开为一系列一般的指令, 而不是使用分支。 这样处理器的指令缓存能够加载展开的指令并且处理他们。和 需要分支操作的函数相比这样更快。
-fregmove:
该选项让编译器试图 重新分配 mov 指令中使用的寄存器,并且将其作为 其他指令的操作数,以便 最大化捆绑的寄存器的数量。说实在的,笔者目前也不清楚书中所讲关于该选项的内容,有知道的读者还请不吝赐教
-freorder-functions:
该选项让编译器重新安排指令块以便改进 分支操作 和 代码局部性。
-frerun-cse-after-loop:
该选项让编译器在对 任何循环 已经进行过优化之后执行 运行通用子表达式消除。这样确保在展开循环代码之后更进一步地优化代码
-fsched-interblock:
该选项让编译器能够 跨越指令块调度指令。 这可以非常灵活地 移动指令以便等待期间完成的工作最大化。
-fschedule-insns:
该选项让编译器将 重新安排指令,以让等待数据的处理器可以执行其他操作。 比如对于在进行浮点运算时有延迟的处理器来说, 这使处理器在等待浮点结果时可以加载其他指令
-fstrength-reduce:
该选项让编译器对循环执行优化并且 删除迭代变量。迭代变量 是 捆绑到循环计数器的变量,类似于for循环中常用的 i,j。
-fstrict-aliasing:
该选项让编译器强制实行高级语言的严格变量规则,确保不在数据类型之间共享变量。比如 int 和 float 不使用相同的内存区域。
-fthread-jumps:
在某些情况下, 一条跳转指令可能转移到另一条分支语句。 通过一连串跳转,编译器确定多个跳转之间的终目 标并且把第一个跳转重新定向到终目标。 也就是直接优化从第一个跳转到最后一个目标代码
-funit-at-a-time:
该选项让编译器在优化程序之前读取 整个汇编代码。 这使编译器可以 重新安排不消耗大量时间的代码以便优化指令缓存。 缺点是编译时 花费相当多的内存,对于 小型计算机可能是一个问题
5.1.3 -O3优化
-fgcse-after-reload:
完全重新加载生成的且优化后的汇编语言代码之后执行第二次gcse优化,帮助消除不同优化代码方式创建的任何冗余段.
-finline-functions:
该选项让编译器 不为函数创建单独的汇编语言代码, 而是把函数代码包含在调度程序的代码中。按照笔者理解将多个函数集成到一个函数中。该优化选项可用充分的利用指令缓存,而不是在每次函数调用时进行分支操作,由此提高性能。
5.2 代码优化
按照笔者理解,代码优化 更加考验一个人的经验积累。本节不会详细介绍书中每种 代码优化技巧 的原理,主要是总结 代码优化技巧 的 结论。可以快速应用于 开发 中。
数据类型:针对 8位和16位,ARM 是在将数据加载到寄存器中,完成 符号位扩展。数据加载指令 ldr、ldrsb、ldrb、 lsdh、lsdsh、ldr等,它们的 指令周期是一样的。所以 char、short、int 其效率是相同的。
if与switch:如果 case值 变化不大(太大的话,会导致跳转表过大,造成内存的浪费),有足够的分支(大 于 4 个分支),switch 会带来性能极大的提升。
循环:
展开循环分支,降低循环的次数,减少 分支语句 对循环的影响。
合并循环,既可以 提高程序性能并减少代码尺寸,同时不影响功能。
流水线级数越高,对分支操作越加敏感。在程序正常运行期间处理当前代码时,预取模块 会 读取并解码 下一部分指令而 不使存储总线闲置下来。如果遇到 分支语句,则会 清除流水线而立刻使预先进行的读取和解码工作无效。流水线 级数越多 ,系统就花费越多的时间 来填充流水线。在这期间 CPU会闲置下来。因此,分支语句越少,性能越高。
数组:尽量使用数组的大小是 4或8 的倍数,用此倍数展开循环体 一维数组和多维数组 。
函数:
函数的参数最好 不多于 4 个。
尽量限制函数内部循环所用局部变量的数目,最好 不超过12个,以便编译器能把 变量分配到寄存器。
如果不需要 返回值,则尽量定义为 void,这样可以 节省 一个 寄存器R0。 如果需要返回值,则最好 限定在4个字节,使用一个 寄存器R0 即可。
六、参考链接