RAPiD: Rotation-Aware People Detection in Overhead Fisheye Images
在这项工作中,我们开发了一种端到端的旋转感知的人检测方法,称为RAPID,它使用任意方向的包围盒来检测人。我们的完全卷积神经网络使用周期损失函数直接回归每个包围盒的角度,该函数考虑了角度的周期性。
我们还创建了一个新的数据集,其中包含旋转边界框的时空注释,用于人的检测以及头顶鱼眼视频中的其他视觉任务。
1. Introduction
使用一个架空的鱼眼相机,视野为360◦。然而,为侧视、标准镜头图像开发的人检测算法,由于其独特的径向几何形状和桶形失真,在头顶、鱼眼图像上表现不佳。

图1:使用各种边界框方向约束的算法在头顶、鱼眼图像(图中显示的四分之一)上的典型人员检测结果的图解;人类对齐的边界框最适合人体。
在标准图像中,站立的人通常以直立的位置出现,检测与图像轴对齐的边界框的算法,如YOLO[21]、SSD[15]和R-CNN[24]都很好地工作。
然而,这些算法在头顶的鱼眼图像上表现不佳[12],通常缺少非直立的身体(图1a)。
在这样的图像中,由于相机的上方放置,站着的人沿着图像半径出现,并且需要旋转的边界框。
为了适应这种旋转,最近提出了几种人的检测算法,大多基于YOLO[2,30,11,12,27,34],每一种算法都以不同的方式处理径向几何形状。
[2] An-Ti Chiang and Yao Wang. Human detection in fisheye images using hog-based detectors over rotated windows.
Proc. IEEE Intern. Conf. on Multimedia and Expo Workshops, pages 1–6, 2014. 1, 2[30] T. Wang, C. Chang, and Y. Wu. Template-based people detection using a single downward-viewing fisheye camera. In Intern. Symp. on Intell. Signal Process. and Comm. Systems,
pages 719–723, Nov 2017. 1, 2[11] O. Krams and N. Kiryati. People detection in top-view fisheye imaging. In Proc. IEEE Int. Conf. Advanced Video and
Signal-Based Surveillance, pages 1–6, Aug 2017. 1, 2[12] S. Li, M. O. Tezcan, P. Ishwar, and J. Konrad. Supervised
people counting using an overhead fisheye camera[27] Masato Tamura, Shota Horiguchi, and Tomokazu Murakami.
Omnidirectional pedestrian detection by rotation invariant
training. In Proc. IEEE Winter Conf. on Appl. of Computer
Vision, pages 1989–1998. IEEE, 2019. 1, 6, 7, 8[34] Yanzhao Zhou, Qixiang Ye, Qiang Qiu, and Jianbin Jiao.
Oriented response networks. In Proc. IEEE Conf. Computer
Vision Pattern Recognition, pages 519–528, 2017. 1,
例如,在性能最好的算法之一[12]中,图像以15个◦步长进行旋转,并对图像的顶部中心部分(人们通常是直立的)应用YOLO,然后进行后处理。然而,这需要24倍的YOLO应用。
最近的另一种算法[27]要求边界框与图像半径对齐,但通常无法检测非站立姿势(图1B)。
在本文中,我们介绍了旋转感知的人检测(RAPID),这是一个新的端到端的人检测算法,适用于头顶、鱼眼图像。
RAPID是一种单级卷积神经网络,它预测鱼眼图像中任意旋转的人的边界框(图1C)。
它扩展了最成功的标准图像目标检测算法之一YOLO[21,22,23]中提出的模型。
除了预测边界框的中心和大小外,Rapid还预测其角度。
这是通过基于普通回归损失的扩展的周期损失函数来实现的。
这使我们能够预测图像中每个边界框的准确旋转,而不需要任何假设和额外的计算复杂性。
由于RAPID是一种端到端的算法,我们可以训练或微调其在带注释的鱼眼图像上的权重。
事实上,我们表明,对标准图像上训练的模型进行这种微调可以显著提高性能。
这项工作的另一个方面是将多类目标检测算法[21,15,8,24]中常用的基于回归的损失函数替换为单类目标检测。
RAPID的推理速度与YOLO几乎相同,因为它只对每幅图像应用一次,不需要前/后处理。
我们评估了RAPID在两个公开可用的人检测数据集上的性能,这些数据集是由头顶鱼眼摄像头捕获的,镜像世界(MW)3和HABBOF[12]。
虽然这些数据集涵盖了一系列场景,但它们缺乏挑战性的情况,如不寻常的身体姿势,穿连帽衫或帽子,拿着物体,背背包,强烈的遮挡,或光线较弱。
因此,我们引入了一个新的数据集,称为从开销鱼眼图像中进行人物检测的挑战事件(CEPDOF),其中包括这样的场景。
在我们的评估中,Rapid在所有三个数据集上的性能都优于最先进的算法
The main contributions of this work can be summarized
as follows:
·我们提出了一种端到端的神经网络,它扩展了YOLO v3,用于在头顶鱼眼图像中进行旋转感知的人检测,并证明了我们的简单而有效的方法优于最先进的方法。
·提出了一种连续的周期性包围盒角度损失函数,与以往的方法不同,该方法方便了任意方向的包围盒,能够处理各种人体姿势。
·我们推出了一个新的数据集,用于从头顶上的鱼眼摄像头进行人员检测,其中包括一系列挑战;它也可以用于其他任务,如人员跟踪和重新身份识别。
2. Related work
使用侧视标准镜头摄像机的人物检测:在标准摄像机的传统人物检测算法中,最流行的算法是基于方向梯度直方图(HOG)[3]和聚合通道特征(ACF)[5]。
近年来,深度学习算法在目标和人物检测方面表现出了优异的性能[21,15,7,8,24,10]。
这些算法可以分为两类:两阶段法和一阶段法。
两阶段方法,如R-CNN及其变种[8,24,10],包括预测感兴趣区域(ROI)的区域建议网络(RPN)和细化边界框的网络头部。
一阶段方法,如SSD[15,7]和YOLO[21,22,23]的变体,可被视为独立的区域方案网络。
在给定一幅输入图像的情况下,一步法直接通过CNN回归边界框。
最近,人们的注意力集中在快速单级检测器[33,28]和无锚检测器[29,32]上。
使用旋转边界框的目标检测:旋转边界框的检测在文本检测和航空图像分析中得到了广泛的研究[16,4,31,20]。
RRPN[16]是一种使用旋转锚盒和旋转感兴趣区域(RRoI)层的两阶段目标检测算法。
ROI-Transformer[4]通过首先计算水平感兴趣区域(HROI),然后学习从HROI到RROI的扭曲来扩展这一想法。
R3Det[31]提出了一种单级旋转包围盒检测器,通过使用特征精化层来解决感兴趣区域和特征之间的特征不对齐问题,这是单级方法的一个常见问题。
在另一种方法中,Nosaka等人[19]使用可感知方向的卷积层[34]来处理边界框方向和用于角度回归的平滑L1损失。
所有这些方法都对旋转的边界框(中心、宽度、高度和旋转角度的坐标)使用5分量向量,角度定义在[−π/2,0]范围内,并使用传统的回归损失。
由于对称性,具有宽度bw、高度bh和角度θ的矩形边界框与具有宽度bh、高度bw和角度(θ−π/2)的矩形边界框无法区分。
因此,即使当预测接近基本事实时,没有考虑到这一点的标准回归损失也可能招致很大的成本,例如,如果基本事实注释是(bx,by,bh,bw,−4π/10),预测(bx,by,bw,bh,0)可能看起来远离基本事实,但事实并非如此,因为基本事实等同于(bx,by,bw,bh,π/10)。
RSDet[20]通过引入调制旋转损耗来解决这个问题。
头顶鱼眼图像中的人检测:使用头顶鱼眼相机进行人检测是一个文献稀少的新兴领域。
在一些方法中,传统的人检测算法,如HOG和LBP,已被应用于鱼眼图像,并进行了轻微的修改,以考虑到鱼眼的几何形状[30,2,25,11]。
例如,Chiang和Wang[2]以小角度旋转每个鱼眼图像,并从图像的顶部中心部分提取猪特征。
随后,他们应用支持向量机分类器来检测人。
在另一种算法中,Kram和Kiryati[11]在侧视图像上训练了ACF分类器,并对从鱼眼图像中提取的ACF特征进行去失真以进行人检测。
最近,基于CNN的算法也被应用到这个问题上。
Tamura 通过在CoCo数据集的旋转版本[14]上训练网络,引入了YOLO的旋转不变版本[21]。
他们方法中的推理阶段依赖于鱼眼图像中的边界框与图像半径对齐的假设。
另一种基于YOLO的算法[26]将YOLO应用于从鱼眼图像提取的重叠窗口的去扭曲版本。
Li等人[12]以15个◦步长旋转每个鱼眼图像,并只将YOLO应用于图像的中心上部,在那里人们通常是直立的。
随后,他们应用后处理来删除对同一人的多个检测。
尽管他们的算法非常准确,但由于对每幅图像应用YOLO 24次,因此计算复杂。
在这项工作中,我们引入了角度感知损失函数来预测包围盒的准确角度,而不需要任何额外的假设。
我们还改变了旋转边界框的常用表示法以克服对称性问题(第3.2.2节)
3. Rotation-Aware People Detection (RAPiD)
我们提出了一种新的CNN,RAPID,除了位置和大小之外,它还估计了头顶上的鱼眼图像中每个边界框的角度。
在训练期间,RAPID包括旋转感知的回归损失,以解决这些角度。
Rapid的设计在很大程度上是由YOLO推动的。
记法:我们使用b=(bx,by,bw,bh,bθ)∈R5来表示地面真实边界框,其中bx,by是边界框中心的坐标;bw,bh是宽度和高度,bθ是边界框顺时针旋转的角度。
类似地,ˆb=(bbx,bby,bbw,bbh,bbθ,bbconf)∈R6表示预测边界框,其中附加元素bbconf表示预测的置信度分数。
论文中使用的所有角度都是弧度。
3.1. Network Architecture
我们的目标检测网络可以分为三个阶段:骨干网络、特征金字塔网络(FPN)[13]和包围盒回归网络,也称为检测头:
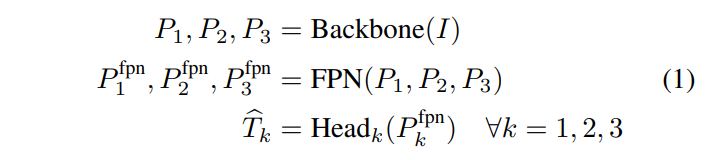
其中,i∈[0,1]3×h×w是输入图像,{Pk}3k=1表示多维特征矩阵,并且{Tbk}3k=1表示在三个分辨率级别的变换记数法(Tb和ˆb之间的关系将很快被定义-参见公式(2))的预测边界框的列表。
图2显示了整个快速体系结构,下面我们将对每个阶段进行一些深入的描述。
欲了解更多细节,有兴趣的读者请参考[23]。
主干:主干网络,也称为特征抽取器,获取输入图像I并输出来自网络不同部分的特征列表(P1、P2、P3)。
主要目标是提取不同空间分辨率(P1最高,P3最低)的特征。
通过使用这种多分辨率金字塔,我们希望利用从图像中提取的低级别和高级别信息。
特征金字塔网络(FPN):将主干计算的多分辨率特征送入F-P-N,以提取与目标检测相关的特征,记为(P-FPN-1,Pfpn2,Pfpn3)。
我们期望P FPN 1包含关于小对象的信息,而P FPN 3包含关于大对象的信息。
检测头:在fpn之后,对每个特征向量p fpn k,k∈{1,2,3}应用单独的cnn,以产生包围盒预测的变换版本,表示为tbk-具有h3,h/sk,w/sk,6i维的4维矩阵。
第一个维度表示在TBK中使用了三个锚定框,第二个和第三个维度表示预测网格,其中h×w是输入图像的分辨率,SK是如图2所示的分辨率级别k上的步幅,最后一个维度表示每个网格单元的预测边界框的变换版本。
我们将网格单元(i,j)中Headk的第n个变换边界框预测表示为Tbk[n,i,j]=(btx,bty,btw,bth,btθ,btconf),由此可以如下计算边界框预测

3.2. Angle-Aware Loss Function
Our loss function is inspired by that used in YOLOv3
[23], with an additional bounding-box rotation-angle loss:
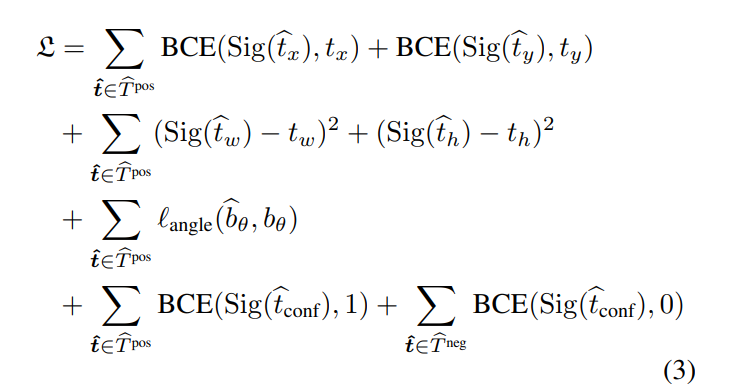
其中bce表示二进制交叉熵,角度是我们在下一节中提出的新的角度损失函数,Tbpos和Tbneg分别是来自预测的正样本和负样本,如YOLOv3中所述,Bbθ在公式(2)中计算,Tx,ty,tw,th根据地面事实计算如下:
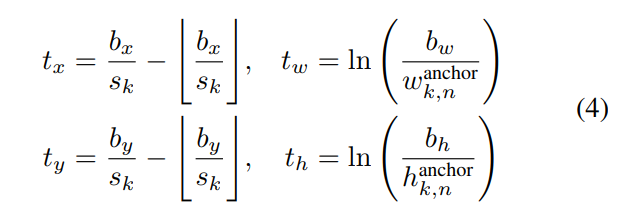
请注意,我们没有使用类别分类损失,因为我们在问题中只使用了一个类别(Person)。
传统上,基于L1或L2距离的回归函数用于角度预测[16,4,31]。
然而,这些度量没有考虑角度的周期性,并且由于旋转边界框的参数化中的对称性,可能会导致误导性的代价值。
我们分别通过使用周期损失函数和改变参数来解决这些问题。
3.2.1 Periodic Loss for Angle Prediction
由于边框在被π旋转后保持不变,因此角度损失函数必须满足π(θb)=角度(π,θb+π),即必须是关于θb的角度周期函数。
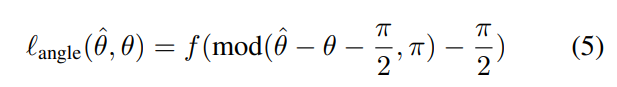
其中mod(·)表示模运算,f是任意对称回归函数,例如L1或L2范数。
由于∂/∂Xmod(x,·)=1,所以该损失函数相对于ˆθ的导数可以计算如下。
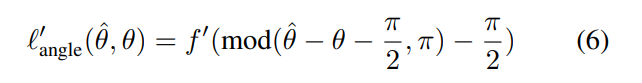
除了对整数k有ˆθ−θ=(kπ+π/2)的角,其中角是不可微的。
然而,我们可以在反向传播过程中忽略这些角度,就像通常对其他非光滑函数所做的那样,例如L1距离。
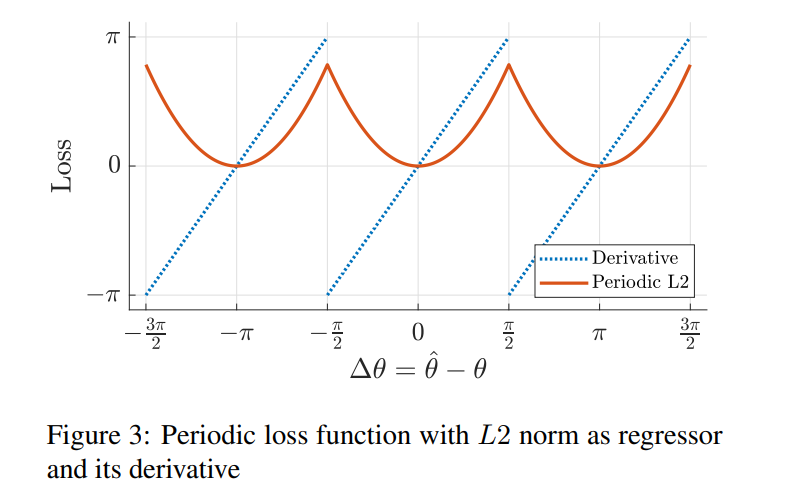
图3显示了具有L2距离的`角度(ˆθ,θ)及其相对于∆θ=ˆθ−θ的导数的示例图。
3.2.2 Parameterization of Rotated Bounding Boxes
在以往的旋转包围盒检测工作中,大多采用[−π/2,0]范围来表示角度。
这确保了所有的θ可以唯一地表示为(bx,by,bw,bh,bθ∈[−π),其中b RBS/2,0]。
然而,如第2节和[20]中所讨论的,即使当预测由于表示的对称性,即(bx,by,bw,bh,bθ)=(bx,by,bh,bw,bθ−π/2)接近基本事实时,这种方法也可能导致较大的成本。
我们通过在地面真实标注中实施以下规则来解决这个问题:bw<bh并将地面真实角度范围扩展到[−π/2,π/2),以能够表示所有可能的RBB。
对于精确正方形的边界框,我们只需将随机边减少1像素,这是一种罕见的情况。
根据这一规则,每个边界框将对应于唯一的5-D矢量表示。
鉴于地面真实角度θ定义在[−π/2,π/2)范围内,通过在公式(2)中指定(ˆθ/2)来强制预测角度α,β)=(π,π在相同范围内似乎是合乎逻辑的。
然而,当π/2<ˆθ−θ<π时,这就产生了一个梯度下降的问题,因为角度损失的导数(6)将是负的(图3)。
在这种情况下,渐变下降将倾向于增加ˆθ,这将使其进一步远离实际角度θ。
显然,网络应该学会将角度估计为θ+π而不是θ(图4)。
为了允许这种行为,我们将允许的角度预测范围扩展到[−π,π],方法是指定(α,β)=(2π,π)。
注意,如果网络最终学习预测参数化规则bbw≤bbh,则我们的新的rbb参数化将不会具有上面解释的对称性问题,这很可能考虑到所有基本事实rbb满足bw≤bh的事实。
事实上,基于我们在第4.4.3节中的实验,我们表明,RAPID预测的几乎所有RBBS都满足BBW≤BBH。
总之,通过1)将[−π/2,π/2)定义为地面真实角度范围并强制地面真实BW<bh,2)使用我们提出的周期角度损失函数,以及3)将预测角度范围设置为(−π,π),我们的网络可以学习预测任意方向的RBBS,而不会遇到以前RBB方法所遇到的问题。
基于第4.4.2节的实验结果,我们选择周期L1作为我们的角度损失函数。
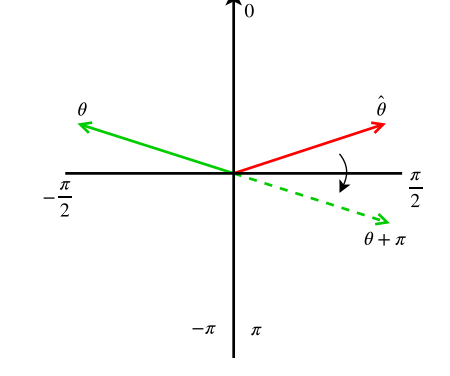
图4:扩大预测角度值范围的必要性的图解。
应用于预测角度ˆθ的渐变下降(红色箭头)可能会顺时针旋转,并远离地面真实角度θ(绿色箭头)。
由于角度为θ+π的边界框与角度为θ的边界框相同,我们需要扩展角度范围以包括θ+π(虚线绿色箭头),否则在渐变推动下,θb将停止在π/2。
3.3 推理
在推理过程中,将一幅图像I∈R3×h×w输入到网络中,得到三组来自三个特征分辨率的边界框。
应用置信度阈值来选择最佳边界框预测。
之后,应用非最大值抑制(NMS)来去除对同一人的冗余检测。
旋转感知的人检测:正如在第3.2节中所讨论的,我们引入了一种新的损失函数来实现快速旋转感知。
我们没有将对象的角度设置为沿着视场半径,而是向每个预测的边界框添加了参数BBθ,并使用周期性的L1损失来训练网络。
如表4最后一行所示,角度预测进一步提高了RAPID的性能。
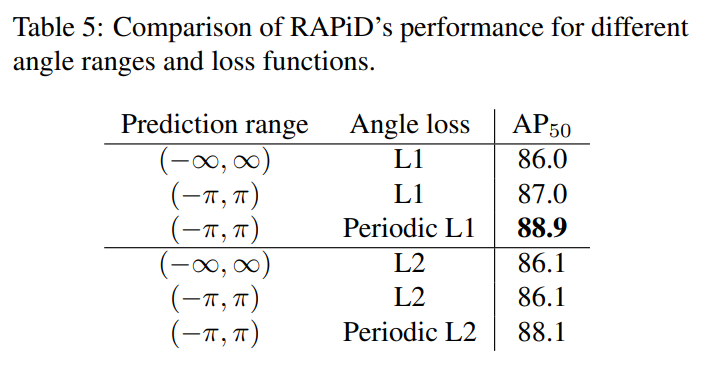
4.4.2不同角度损失函数的比较。
为了分析损失函数对角度预测的影响,我们在保持其他部分不变的情况下,快速地消融了角度值范围和角度损失。
我们将我们提出的周期损失与两个基线进行比较:标准无界回归损失和有界回归损失。
我们对L1和L2损失执行相同的实验。
如表5所示,周期性L1损耗的性能最佳,周期性L1和周期性L2损耗的性能均优于非周期性损耗。
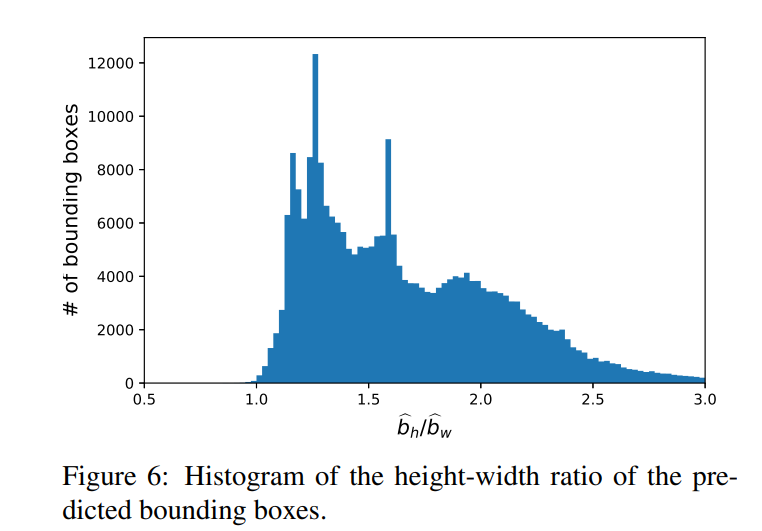
4.4.3预测纵横比分析。
如第3.2.2节所讨论的,我们将角度范围放宽到[−π/2,π/2]内,并在地面实况注释中强制bw<bh,以便每个边界框对应于唯一的表示。
在同一节中,为了处理包围盒对称问题,我们假设网络可以学习预测包围盒,使得BBW<BBH。
为了证明情况确实如此,我们分析了我们的网络在HABBOF和CEPDOF数据集上的输出。
图6显示了BBH/BBW的直方图。
我们观察到几乎所有的预测包围盒都满足bbw<bbh(即bbh/bbw>1),这验证了我们的假设
4.5. 照明的影响。
表6显示了CEPDOF数据集中每个视频的RAPID性能。
显然,当运行在1024x1024像素分辨率时,Rapid在使用AP50AP94.0的常光视频(午餐会议1/2/3、边缘案例和高活动)上表现得非常好。
然而,对于All-Off和IRFilter视频,AP50和F-MEASure都会显著下降。
我们观察到,RAPID对这两个视频的准确率相对较高,但召回率很低,即它错过了很多人。
通过将RAPID的输出与地面事实注释进行比较,我们发现RAPID中的人通常与背景无法区分(例如,见图5H)。
即使对人类来说,从一个视频帧中检测出这种几乎看不见的人也是一项非常具有挑战性的任务。
值得注意的是,当打开红外线照明(IRill视频)时,Rapid的性能大大提高,与普通光线视频相比,性能仅略低于平均水平。
5.结论。
在本文中,我们提出了一种新的快速的高空鱼眼图像的人检测算法。
我们的算法将使用轴对齐边界框的目标检测算法(如YOLO)扩展到使用人类对齐边界框进行人物检测的情况。
我们证明了我们提出的周期损失函数在角度预测方面优于传统的回归损失函数。
通过旋转感知的边界框预测,快速方法在不引入额外计算复杂性的情况下,大大超过了以前最先进的方法。
不足为奇的是,对于在光线极低的场景下拍摄的视频,快速视频的性能会显著下降,因为在这种场景中,人与背景几乎无法区分。
需要进一步的研究来解决这种情况。
我们还引入了一个新的数据集,它由25K帧和173K人注释组成。
我们相信我们的方法和数据集都将有益于使用开销、鱼眼图像和视频的各种真实世界的应用和研究
cites
paper