目录
Mybatis持久层框架
结果集进行ORM映射
步骤解析
1、获取结果集及结果映射入口
2、开始ORM映射接口
3、数据库结果集解析,完成ORM映射
4、保存并获取ORM映射后的结果集
参数传递方式
顺序传参法
@Param注解传参法
Map传参法
Java Bean传参法
mybatis #{ } 和 ${ } 防止SQL注入(#{} 占位符,${} 拼接符)
${}可以使用的情况
#{}推荐使用情况
mybatis缓存
Mybatis持久层框架
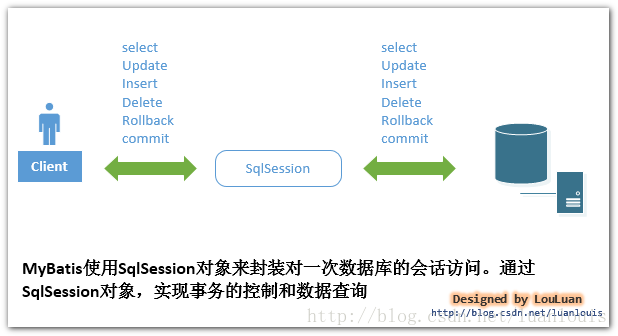
mybatis是一个用Java编写的持久层框架,它使用ORM实现了结果集的封装。
跟hibernate一样,也是需要拥有两个配置文件,全局配置文件 和 映射文件,在编写这两个映射文件之前,必须创建mybatis环境(引入jar包或者maven工程导入坐标)
ORM是Object Relational Mapping 对象关系映射。简单来说,就是把数据库表和实体类及实体类的属性对应起来,让开发者操作实体类就实现操作数据库表。
它封装了jdbc操作的很多细节,使开发者只需要关注sql语句本身,而无需关注注册驱动,创建连接等烦杂过程
结果集进行ORM映射
通过 Mapper 执行 Statement 已经从数据库中获取到数据的基本值,但是并没有和 Java pojo 进行映射,本篇讲继续解析 MyBatis 中的属性映射

步骤解析
1、获取结果集及结果映射入口
* PreparedStatementHandler
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {// 转换Statement为JDBC原生的PreparedStatementPreparedStatement ps = (PreparedStatement) statement;// 通过JDBC底层执行, 并将执行结果封装到PreparedStatement中ps.execute();// resultSetHandler:结果集处理器, 对查询结果进行ORM映射return resultSetHandler.<E> handleResultSets(ps);
}2、开始ORM映射接口
* DefaultResultSetHandler:通过 handleResultSets() 方法开始映射
public List<Object> handleResultSets(Statement stmt) throws SQLException {ErrorContext.instance().activity("handling results").object(mappedStatement.getId());final List<Object> multipleResults = new ArrayList<Object>();int resultSetCount = 0;// 获取执行结果集, 并封装为ResultSetWrapperResultSetWrapper rsw = getFirstResultSet(stmt);// 获取Statement的结果映射, 后台会自动将resultType解析为一个ResultMapList<ResultMap> resultMaps = mappedStatement.getResultMaps();int resultMapCount = resultMaps.size();validateResultMapsCount(rsw, resultMapCount);while (rsw != null && resultMapCount > resultSetCount) {// 逐个resultMap, 进行结果集解析ResultMap resultMap = resultMaps.get(resultSetCount);// 处理结果集, 映射数据库查询数据到reslutMap指定VO中handleResultSet(rsw, resultMap, multipleResults, null);rsw = getNextResultSet(stmt);cleanUpAfterHandlingResultSet();resultSetCount++;}String[] resultSets = mappedStatement.getResultSets();if (resultSets != null) {while (rsw != null && resultSetCount < resultSets.length) {ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);if (parentMapping != null) {String nestedResultMapId = parentMapping.getNestedResultMapId();ResultMap resultMap = configuration.getResultMap(nestedResultMapId);handleResultSet(rsw, resultMap, null, parentMapping);}rsw = getNextResultSet(stmt);cleanUpAfterHandlingResultSet();resultSetCount++;}}// 返回处理结果集return collapseSingleResultList(multipleResults);
}* DefaultResultSetHandler:通过 getFirstResultSet(),获取数据库返回的结果集,并封装为 ResultSetWrapper
private ResultSetWrapper getFirstResultSet(Statement stmt) throws SQLException {ResultSet rs = stmt.getResultSet();while (rs == null) {// move forward to get the first resultset in case the driver// doesn't return the resultset as the first result (HSQLDB 2.1)if (stmt.getMoreResults()) {rs = stmt.getResultSet();} else {if (stmt.getUpdateCount() == -1) {// no more results. Must be no resultsetbreak;}}}return rs != null ? new ResultSetWrapper(rs, configuration) : null;
}public ResultSetWrapper(ResultSet rs, Configuration configuration) throws SQLException {super();// 获取类型映射注册信息this.typeHandlerRegistry = configuration.getTypeHandlerRegistry();// 获取结果集this.resultSet = rs;// 获取数据库元数据列final ResultSetMetaData metaData = rs.getMetaData();final int columnCount = metaData.getColumnCount();// 逐行解析元数据列, 获取元数据列基本信息for (int i = 1; i <= columnCount; i++) {// 数据库列名, 支持别名columnNames.add(configuration.isUseColumnLabel() ? metaData.getColumnLabel(i) : metaData.getColumnName(i));// 数据库列字段类型jdbcTypes.add(JdbcType.forCode(metaData.getColumnType(i)));// 数据库列字段类型映射的Java数据类型classNames.add(metaData.getColumnClassName(i));}
}3、数据库结果集解析,完成ORM映射
* DefaultResultSetHandler:调用 handleResultSet() 处理结果集
private void handleResultSet(ResultSetWrapper rsw, ResultMap resultMap, List<Object> multipleResults, ResultMapping parentMapping) throws SQLException {try {// parentMapping 方法传参为nullif (parentMapping != null) {handleRowValues(rsw, resultMap, null, RowBounds.DEFAULT, parentMapping);} else {// DefaultSqlSession.selectList方法中, 初始化resultHandler时为nullif (resultHandler == null) {DefaultResultHandler defaultResultHandler = new DefaultResultHandler(objectFactory);// 映射查询数据到VO中, 并添加最终VO到结果集中handleRowValues(rsw, resultMap, defaultResultHandler, rowBounds, null);// multipleResults结果集添加ORM映射后的数据multipleResults.add(defaultResultHandler.getResultList());} else {handleRowValues(rsw, resultMap, resultHandler, rowBounds, null);}}} finally {// issue #228 (close resultsets)closeResultSet(rsw.getResultSet());}
}* DefaultResultSetHandler:handleRowValues() 处理所有数据行
public void handleRowValues(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {if (resultMap.hasNestedResultMaps()) {ensureNoRowBounds();checkResultHandler();handleRowValuesForNestedResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);} else {// 不存在嵌套的单条数据查询, 走此方法handleRowValuesForSimpleResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);}
}private void handleRowValuesForSimpleResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping)throws SQLException {DefaultResultContext<Object> resultContext = new DefaultResultContext<Object>();// 此处基于分页处理, 当前不涉及skipRows(rsw.getResultSet(), rowBounds);// 遍历每一个数据库查询对象, 进行数据ORM映射while (shouldProcessMoreRows(resultContext, rowBounds) && rsw.getResultSet().next()) {// 此处应该意为区分不同的resultMap, 当前只存在一个resultMap, 暂时忽略// 此时resultMap只存在一个有效属性, 即type为resultType对应的VOResultMap discriminatedResultMap = resolveDiscriminatedResultMap(rsw.getResultSet(), resultMap, null);// 映射当前数据库数据到JavaBean, 此行结束后, 返回结果即为JavaBean对象Object rowValue = getRowValue(rsw, discriminatedResultMap);// 保存结果集到DefaultResultHandler中, 外部通过该对象获取结果集storeObject(resultHandler, resultContext, rowValue, parentMapping, rsw.getResultSet());}
}* DefaultResultSetHandler:处理每一行数据映射 getRowValue()
private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap) throws SQLException {final ResultLoaderMap lazyLoader = new ResultLoaderMap();// 初始化JavaBean对象, 初始化为零值, 此时未进行数据赋值Object rowValue = createResultObject(rsw, resultMap, lazyLoader, null);// hasTypeHandlerForResultObject : 判断当前结果集在JDBC->java的默认集合中是否存在if (rowValue != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) {final MetaObject metaObject = configuration.newMetaObject(rowValue);boolean foundValues = this.useConstructorMappings;// 判断是否需要自动映射if (shouldApplyAutomaticMappings(resultMap, false)) {// 进行自动映射foundValues = applyAutomaticMappings(rsw, resultMap, metaObject, null) || foundValues;}// 涉及ResultMap映射处理foundValues = applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, null) || foundValues;foundValues = lazyLoader.size() > 0 || foundValues;// 返回结果集rowValue = foundValues || configuration.isReturnInstanceForEmptyRow() ? rowValue : null;}return rowValue;
}private boolean applyAutomaticMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject, String columnPrefix) throws SQLException {// 获取还没有建立属性映射的数据库字段List<UnMappedColumnAutoMapping> autoMapping = createAutomaticMappings(rsw, resultMap, metaObject, columnPrefix);boolean foundValues = false;if (!autoMapping.isEmpty()) {// 未建立映射字段不为空, 为当前属性分别set值for (UnMappedColumnAutoMapping mapping : autoMapping) {final Object value = mapping.typeHandler.getResult(rsw.getResultSet(), mapping.column);if (value != null) {foundValues = true;}if (value != null || (configuration.isCallSettersOnNulls() && !mapping.primitive)) {// gcode issue #377, call setter on nulls (value is not 'found')metaObject.setValue(mapping.property, value);}}}return foundValues;
}* 如果存在自定义 Property 映射,会执行下面方法
private boolean applyPropertyMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject, ResultLoaderMap lazyLoader, String columnPrefix)throws SQLException {final List<String> mappedColumnNames = rsw.getMappedColumnNames(resultMap, columnPrefix);boolean foundValues = false;final List<ResultMapping> propertyMappings = resultMap.getPropertyResultMappings();for (ResultMapping propertyMapping : propertyMappings) {String column = prependPrefix(propertyMapping.getColumn(), columnPrefix);if (propertyMapping.getNestedResultMapId() != null) {// the user added a column attribute to a nested result map, ignore itcolumn = null;}if (propertyMapping.isCompositeResult()|| (column != null && mappedColumnNames.contains(column.toUpperCase(Locale.ENGLISH)))|| propertyMapping.getResultSet() != null) {Object value = getPropertyMappingValue(rsw.getResultSet(), metaObject, propertyMapping, lazyLoader, columnPrefix);// issue #541 make property optionalfinal String property = propertyMapping.getProperty();if (property == null) {continue;} else if (value == DEFERED) {foundValues = true;continue;}if (value != null) {foundValues = true;}if (value != null || (configuration.isCallSettersOnNulls() && !metaObject.getSetterType(property).isPrimitive())) {// gcode issue #377, call setter on nulls (value is not 'found')metaObject.setValue(property, value);}}}return foundValues;
}最终返回ORM映射后的 Java POJO
4、保存并获取ORM映射后的结果集
* 保存结果集:映射完成后,会调用 DefaultResultSetHandler.storeObject() 方法,保存结果到 DefaultResultHandler.list属性中
// 保存结果集到DefaultResultHandler中, 外部通过该对象获取结果集
// org.apache.ibatis.executor.resultset.DefaultResultSetHandler#handleRowValuesForSimpleResultMapstoreObject(resultHandler, resultContext, rowValue, parentMapping, rsw.getResultSet());private void storeObject(ResultHandler<?> resultHandler, DefaultResultContext<Object> resultContext, Object rowValue, ResultMapping parentMapping, ResultSet rs) throws SQLException {// parentMapping传递为空if (parentMapping != null) {linkToParents(rs, parentMapping, rowValue);} else {callResultHandler(resultHandler, resultContext, rowValue);}
}private void callResultHandler(ResultHandler<?> resultHandler, DefaultResultContext<Object> resultContext, Object rowValue) {resultContext.nextResultObject(rowValue);((ResultHandler<Object>) resultHandler).handleResult(resultContext);
} public void handleResult(ResultContext<? extends Object> context) {list.add(context.getResultObject());}* 获取结果集:映射完成后,会从 DefaultResultHandler.list中获取有效结果集
// org.apache.ibatis.executor.resultset.DefaultResultSetHandler#handleResultSet
multipleResults.add(defaultResultHandler.getResultList()); // org.apache.ibatis.executor.result.DefaultResultHandler#getResultListpublic List<Object> getResultList() {return list;}参数传递方式
在mapper中传递多个参数的方式有四种:
顺序传递法
@Param注解传参法
Map传参法
Java Bean传参法;顺序传参法
xxMapper.java
public User selectUser(String name, int deptId);xxMapper.xml
<select id="selectUser" resultMap="UserResultMap">select * from userwhere user_name = #{0} and dept_id = #{1}
</select>#{}里面的数字代表传入参数的顺序。这种方法不建议使用,sql层表达不直观,且一旦顺序调整容易出错。
@Param注解传参法
public User selectUser(@Param("userName") String name, int @Param("deptId") deptId);<select id="selectUser" resultMap="UserResultMap">select * from userwhere user_name = #{userName} and dept_id = #{deptId}
</select>
#{}里面的名称对应的是注解@Param括号里面修饰的名称。这种方法在参数不多的情况还是比较直观的,(推荐使用)。
Map传参法
public User selectUser(Map<String, Object> params);<select id="selectUser" parameterType="java.util.Map" resultMap="UserResultMap">select * from userwhere user_name = #{userName} and dept_id = #{deptId}
</select>
#{}里面的名称对应的是Map里面的key名称。这种方法适合传递多个参数,且参数易变能灵活传递的情况。
Java Bean传参法
public User selectUser(User user);<select id="selectUser" parameterType="com.jourwon.pojo.User" resultMap="UserResultMap">select * from userwhere user_name = #{userName} and dept_id = #{deptId}
</select>
#{}里面的名称对应的是User类里面的成员属性。这种方法直观,需要建一个实体类,扩展不容易,需要加属性,但代码可读性强,业务逻辑处理方便,推荐使用。(推荐使用)。
parameterType(输入类型)
简单类型
pojo对象类型
pojo包装对象
resultType(输出类型)
一般数据类型(单条)
JavaBean 类型(单条)
List类型(多条)
Map类型
mybatis #{ } 和 ${ } 防止SQL注入(#{} 占位符,${} 拼接符)
#占位符对应的SQL是占位作用的,也就是形成的SQL对应的位置会用引号括起来,对于SQL来说就是一个参数而已。
$它是拼接符号,不是引号括起来的,它对应一串字符是可以与SQL拼在一起的,相当于成为SQL的一部分,这就很危险了,你拼接的东西可以破坏原有的SQL执行逻辑。
比如说你有一个根据id查询信息的SQL,这时候有个坏人想查看你全部的信息,他会怎么做?
他肯定不会去找id一个去一个的试,最简单的方式是SQL注入写一串有问题的参数传过去。
例如:
dao 接口
public String findById(@param("userId")String userId);1、假设mapper.xml文件中sql查询语句为:
<select id="findById" resultType="String">select name from user where id = #{userid};
</select>
当传入的参数为 3;drop table user; 当我们执行时可以看见打印的sql语句为:sql编译结果如下
select name from usre where id = "3;drop table user;";
不管输入何种参数时,都可以防止sql注入,因为mybatis底层实现了预编译,底层通过prepareStatement预编译实现类对当前传入的sql进行了预编译,预先编译好SQL,然后把#{userId} 站位替换引号引起了"3;drop table user;" 作为一个整体条件,这样就可以防止sql注入了。
2、假设mapper.xml文件中sql查询语句为:
<select id="findById" resultType="String">select name from user where id = ${userid};
</select>当传入的参数为 3;drop table user; 当我们执行时可以看见打印的sql语句为:
select name from user where id = 3;drop table user ;没有进行预编译语句,它先进行了字符串拼接,然后进行了预编译。这个过程就是sql注入生效的过程。
${}可以使用的情况
Order by 传递参数可能要用$算是一种特殊情况外一般来说$通常我们写linux脚本传递参数的时候会用到,这个一定不能是用户来接触使用的内部写定好的参数,比如说数据库,表名什么的可以使用${},#{}推荐使用情况
外界客户端传递参数查询的推荐使用#{}1、预编译语句在执行时会把"select name from user where id= ?"语句事先编译好,这样当执行时仅仅需要用传入的参数替换掉?占位符即可。而对于第一种不符合规范的情况,程序会先生成sql语句,然后带着用户传入的内容去编译,这恰恰是问题所在。
2、第二种避免SQL注入攻击的方式:存储过程。存储过程(Stored Procedure)是一组完成特定功能的SQL语句集,经编译后存储在数据库中,用户通过调用存储过程并给定参数(如果该存储过程带有参数)就可以执行它,也可以避免SQL注入攻击
mybatis缓存
须知缓存1.存在内存中的临时数据2.将用户经常查询的数据放在缓存(内存)中,用户去查询数据就不用从磁盘上(关系型数据库数据文件)查询,从缓存中查询,从而提高查询效率,解决了高并发系统的性能问题优点减少和数据库的交互次数,减少系统开销,提高系统效率使用前提经常查询并且不经常改变的数据mybatis缓存mybatis包含一个非常强大的查询缓存特性,它可以非常方便地定制和配置缓存。缓存可以极大的提升查询效率。mybatis系统中默认定义了两级缓存:一级缓存和二级缓存。-默认情况下,只有一级缓存开启(sqlSession级别的缓存,也称为本地缓存)-二级缓存需要手动开启和配置,它是基于namespace级别的缓存。-为了提高扩展性,Mybatis定义了缓存接口Cache。操作者可以通过实现Cache接口来自定义二级缓存一级缓存含义一级缓存也叫本地缓存:内容与数据库同一次会话期间查询到的数据会放在本地缓存中以后如果需要获取相同的数据,直接从换缓存中拿,没必须再去查询数据库