1.#pragma简介
(1)#pragma用于指示编译器完成一些特定的动作
(2)#pragma所定义的很多指示字是编译器特有的
(3)#pragma在不同的编译器间是不可移植的
(4)预处理器将忽略它不认识的#pragma指令
(5)不同的编译器可能以不同的方式解释同一条#pragma指令
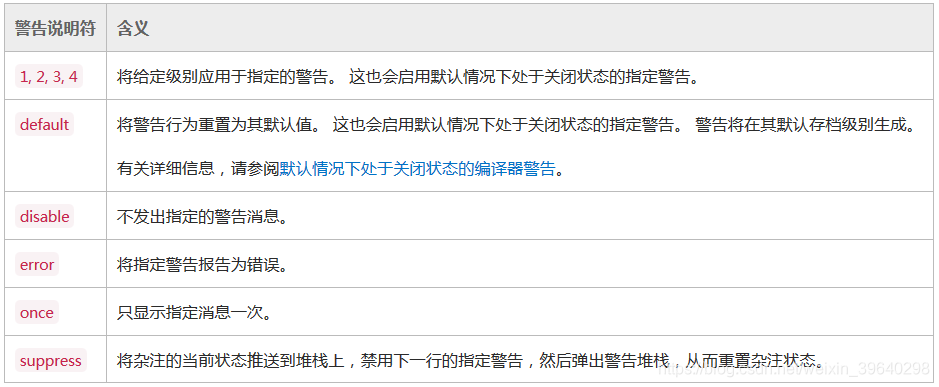
一般用法︰#pragma parameter
#pragma message
message参数在大多数的编译器中都有相似的实现
message参数在编译时输出消息到编译输出窗口中
message 用于条件编译中可提示代码的版本信息
#error和#warning不同,#pragma message仅仅代表一条编译消息,不代表程序错误。
将下列代码在gcc编译器中运行,查看结果
#include <stdio.h>#if defined(ANDROID20)#pragma message("Compile Android SDK 2.0...")#define VERSION "Android 2.0"
#elif defined(ANDROID23)#pragma message("Compile Android SDK 2.3...")#define VERSION "Android 2.3"
#elif defined(ANDROID40)#pragma message("Compile Android SDK 4.0...")#define VERSION "Android 4.0"
#else#error Compile Version is not provided!
#endifint main()
{printf("%s\n", VERSION);return 0;
}可以看见,编译的时候,通过#pragma message("Compile Android SDK 2.0...")语句,我们想要的提示信息已经被打印出来了,在不同的编译器对message这个参数处理的结果不一样,在VC和BCC编译器中运行的结果只是打印出了Compile Android SDK 2.0...,与GCC编译器编译的效果有所差异,但差异不大,

#pragma once
(1)#pragma once 用于保证头文件只被编译一次
(2)#pragma once是编译器相关的,不一定被支持
提出问题:这个方式和#ifndef 、#define、#endif有什么区别?
解释:
#ifndef 、#define、#endif来处理头文件的时候,嵌套处理还是执行了多次的,而#pragma once告诉预编译器只执行一次即可,所以#pragma once的执行效率会比其更高。
虽然#pragma once 的效率更高,但是不同的预编译器对其的支持度不同,所以在很多工程文件中,还是使用#ifndef 、#define、#endif来避免头文件重复包含用的多一点。
示例代码
#include <stdio.h>
#include "global.h"
#include "global.h"int main()
{printf("g_value = %d\n", g_value);return 0;
}global.h
#pragma onceint g_value = 1;在gcc进行编译,结果正常运行,原因就在于在头文件中已经使用#pragma once 进行了声明该头文件只被包含一次。
在bcc编译器进行编译,会报错,这款编译器不支持#pragma once ,被忽略了,所以头文件被包含了两次。
所以有一种推荐写法:即将#pragma once写在在中间部分
#ifndef _GLOBAL_H_
#define _GLOBAL_H_
#pragma once int g_value = 1;#endif
pragma pack
保证内存对齐,什么是内存对齐?
-----不同类型的数据在内存中按照一定的规则排列,而不一定是顺序的一个接一个的排列。
为什么需要内存对齐?
(1)CPU对内存的读取不是连续的,而是分成块读取的,块的大小只能是1、2、4、8、16…字节
(2)当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
(3)某些硬件平台只能从规定的相对地址处读取特定类型的数据,否则产生硬件异常(如STM32单片机)
#pragma pack 用于指定内存对齐方式
看下面的结构体,想想输出的结果是什么呢?
#include <stdio.h>struct Test1
{char c1;short s;char c2;int i;
};struct Test2
{char c1;char c2;short s;int i;
};int main()
{printf("sizeof(Test1) = %d\n", sizeof(struct Test1));printf("sizeof(Test2) = %d\n", sizeof(struct Test2));return 0;
}
分别是12和8

内存空间的存储方式是这样的。

结构体计算要遵循字节对齐原则,结构体大小结果要为成员中最大字节的整数倍,编译器在默认情况下是是4字节对齐的。参考文章:结构体字节对齐
struct占用的内存大小,重要的几点在下面列出:(务必掌握)
1.第一个成员起始于0偏移处
2.每个成员按其类型大小和pack参数中较小的一个进行对齐
3.偏移地址必须能被对齐参数整除(坑人)
4.结构体成员的大小取其内部长度最大的数据成员作为其大小
5.结构体总长度必须为所有对齐参数的整数倍(这个最重要)
Test1结构体中,
对齐参数 偏移地址 大小
char c1; 1 0 1
short s; 2 2 2
char c2; 1 4 1
int i; 4 8 4
对于short s对齐参数是2,偏移地址必须是对齐参数的整数倍,那么偏移位置不能是1了,只能是2。
同理,int i对齐参数是4,偏移地址起始地址不能是5了,因为要满足对齐参数的整数倍,只能是8才行。那么最后一个变量i的偏移地址是8,大小是4,所以8+4=12,且12是所有对齐参数的整数倍,该结构体的大小就为12个字节了。我们的分析与上图的示意图是一致的。
Test2结构体中,
对齐参数 偏移地址 大小
char c1; 1 0 1
char c2; 1 1 1
short s; 2 2 2
int i; 4 4 4
最后一个变量i的偏移地址是4,大小是4,所以4+4=8,且8是所有对齐参数的整数倍,该结构体的大小就为8个字节了。
编译器默认4字节对齐的意思就是,下面的代码和没有加#pragma pack(4)、#pragma pack()组合算出来结构体的大小结果是一样的。
#pragma pack(4)
struct Test1
{char c1;short s;char c2;int i;
};
#pragma pack()#pragma pack(4)
struct Test2
{char c1;char c2;short s;int i;
};
#pragma pack()
训练一下,
例子1
#include <stdio.h>#pragma pack(2)
struct Test1
{ //对齐参数 偏移地址 大小char c1; // 1 0 1short s; // 2 2 2char c2; // 1 4 1int i; // 4 6 4
};
#pragma pack()#pragma pack(4)
struct Test2
{ //对齐参数 偏移地址 大小 char c1;// 1 0 1char c2;// 1 1 1short s;// 2 2 2int i;// 4 4 4
};
#pragma pack()int main()
{printf("sizeof(Test1) = %d\n", sizeof(struct Test1));printf("sizeof(Test2) = %d\n", sizeof(struct Test2));return 0;
}
结果是10和8
例子2
#include <stdio.h>#pragma pack(8)struct S1
{ //对齐参数 偏移地址 大小 short a; // 2 0 2long b; // 4 4 4
};struct S2
{ //对齐参数 偏移地址 大小 char c;// 1 0 1struct S1 d;// 4 4 8double e;// 8 16 8
};#pragma pack()int main()
{printf("%d\n", sizeof(struct S1));printf("%d\n", sizeof(struct S2));return 0;
}不同编译器处理的结果是不同的,gcc编译器不支持八字节对齐,double的对齐参数只能为4计算,所以得到结构体2的大小为20,但是在BCC编译器大小就为24了。
2.小结
(1)#pragma用于指示编译器完成一些特定的动作
(2)#pragma所定义的很多指示字是编译器特有的
(3)#pragma message 用于自定义编译消息
(4)#pragma once 用于保证头文件只被编译一次
(5)#pragma pack 用于指定内存对齐方式