本文从实际情况出发,解决生产中单表数据过大,和数据被拖库导致的问题,并进行的解决方案。本案例使用的框架为轻量型的
jfinal,分表+数据库脱敏,均采用了Apache的shardingsphere。
首先我们要先明确这样一个业务场景,如果生产上某个表的数据在100w+,那么sql语句进行表操作,还不会出现什么瓶颈问题,如果数据量再增加到500w+,可以通过索引,备份等方式,减少数据库的单表压力。如果继续增加到1000w。或者单表一天的数据量就能达到1000w。那么建议索引就无法在解决在这个问题。这时候,我们就需要通过分表的操作,来降低单表的压力。
实现思路:
- 上面我们已经知道了问题所在,下面来分析一下解决方案。既然单个表无法满足生产上是数据量,那么就需要创建多个表。而如何将多个表进行关联起来,我们就需要用到分表组件:ShardingSphere中的
sharding-jdbc模块。
解决方案:(全部代码会在文末全部提供)
1.首先,我们数据库中只有一张表 t_blog。假设这张表的数据量已经达到的1000w的级别。接下来我们在创建8张表,表名为t_blog_x,这8张表的结构和原来的完全一样,这8张表我们把它称为真实表,而原来的t_blog表,我们称为逻辑表。

2.创建好表之后,接下来进行代码部分实现。主要核心的class有下列三个。HashPreciseShardingAlgorithm为分表策略。ShardingCacheKit为缓存分表结果(可有可无)。ShardingDruidPlugin分表数据源配置。
3.紧接着,我们需要在配置文件中,配置之分表内容。
# 主数据源
master.jdbcUrl = jdbc:mysql://localhost/jfinal_demo?characterEncoding=utf8&useSSL=false&zeroDateTimeBehavior=convertToNull
master.user = root
master.password =123456## 分表规则 :对t_blog进分表,分表规则为根据id进行分表,共分为8张真实表
sharding = t_blog:8:iddevMode = true4.在项目的主函数中配置分表代码。
/*** 配置插件*/public void configPlugin(Plugins me) {// 配置 druid 数据库连接池插件Map<String,DruidPlugin> dataSourceMap = new HashMap<String, DruidPlugin>();DruidPlugin masterPlugin = new DruidPlugin(p.get("master.jdbcUrl"), p.get("master.user"), p.get("master.password").trim());dataSourceMap.put("jf_master",masterPlugin);// 配置分表规则ShardingRuleConfiguration shardingRuleConfiguration = new ShardingRuleConfiguration();shardingRuleConfiguration.setDefaultDataSourceName("jf_master");shardingRuleConfiguration.setEncryptRuleConfig(getOrderEncryptRuleConfiguration());List<TableRuleConfiguration> tableRuleConfigurations = new LinkedList<>();// 读取分表配置,生成分表规则String sharding = p.get("sharding");String [] rule = sharding.split(":");if(!Objects.isNull(rule)){// 1. 获得真实表数目int num = Integer.parseInt(rule[1]);// 2.// 获得逻辑表名String tableName = rule[0];// 3.// 分表字段String shardingColumn = rule[2];ShardingCacheKit.me().setCache(tableName,num);// 4.分表规则和生成分表表达式TableRuleConfiguration tableRuleConfiguration =new TableRuleConfiguration(tableName,"jf_master." + tableName + "_${0.. " + (num -1 ) +"}");// 5.配置分表策略StandardShardingStrategyConfiguration shardingStrategyConfiguration =new StandardShardingStrategyConfiguration(shardingColumn,new HashPreciseShardingAlgorithm());tableRuleConfiguration.setTableShardingStrategyConfig(shardingStrategyConfiguration);// 6. 加入策略tableRuleConfigurations.add(tableRuleConfiguration);shardingRuleConfiguration.setTableRuleConfigs(tableRuleConfigurations);}Properties props = new Properties();props.setProperty(ShardingPropertiesConstant.SQL_SHOW.getKey(),"true");// 加入分表插件ShardingDruidPlugin shardingDruidPlugin = new ShardingDruidPlugin(shardingRuleConfiguration,dataSourceMap,props);me.add(shardingDruidPlugin);// 配置ActiveRecord插件ActiveRecordPlugin arp = new ActiveRecordPlugin(shardingDruidPlugin);// 所有映射在 MappingKit 中自动化搞定_MappingKit.mapping(arp);me.add(arp);// 配置缓存插件me.add(new EhCachePlugin());}
5.然后启动项目进行测试,在这里我写了一个简单的save方法,接口返回uuid和该数据存在的真实表表名。


- 接口调用两次后,我们可以看到,两次的数据保存在了不同的表中。
7.接下来我们配置数据库脱敏。
/*** 脱敏配置* @return*/private static EncryptRuleConfiguration getOrderEncryptRuleConfiguration() {EncryptRuleConfiguration encryptRuleConfiguration = new EncryptRuleConfiguration();Properties properties = new Properties();// 设置算法的密钥properties.setProperty("aes.key.value", "123456");// 将逻辑表t_blog的content列进行脱敏,算法采用AESEncryptorRuleConfiguration encryptorRuleConfiguration =new EncryptorRuleConfiguration("AES", "t_blog.content", properties);encryptRuleConfiguration.getEncryptorRuleConfigs().put("user_encryptor", encryptorRuleConfiguration);return encryptRuleConfiguration;}
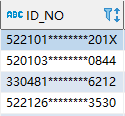
8.两次数据库中的内容如下


该项目源码地址:
GitHub项目地址
参考文档:
shardingsphere官方网站
欢迎关注本人个人公众号,交流更多技术信息









![[VS]网页连接数据库](https://img-blog.csdnimg.cn/f9e5d74128fd45608e620a83893708a5.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5aSn5a2m55Sf56CB5Yac,size_5,color_FFFFFF,t_70,g_se,x_16)

