RE2
- Simple and Effective Text Matching with Richer Alignment Features
Simple and Effective Text Matching with Richer Alignment Features
论文提出了一种快速且高效的文本匹配模型,建议保留三个可用于序列间对齐的关键特征:原始点对齐特征、先前对齐特征和上下文特征。
模型结构(只给出一半):

虚线框起来的作为一个模块(block)
嵌入层+编码层,池化层
嵌入层采用GLOVE的word embedding,编码层采用一维卷积神经网络,池化层采用max-over-time pooling 操作(最大池化)。
Augmented Residual Connections
一种增强版的残差连接,首先,对于n个模块的输入为 X ( n ) = ( x 1 n , x 2 n , … , x l n ) X^{(n)} = (x_1^{n}, x_2^{n},\dots,x_l^{n}) X(n)=(x1n,x2n,…,xln),输出为 O ( n ) = ( o 1 n , o 2 n , … , o l n ) O^{(n)} = (o_1^{n}, o_2^{n},\dots,o_l^{n}) O(n)=(o1n,o2n,…,oln),其中 l l l表示输入序列的长度。
对于第一个模块的输入为嵌入向量,此外,令 O ( 0 ) O^{(0)} O(0)为一个零向量矩阵。那么对于n≥2的第n个模块,其输入为 x i n = [ x i 1 ; o i n − 1 + o i n − 2 ] x_i^{n}=[x_i^{1};o_i^{n-1}+o_i^{n-2}] xin=[xi1;oin−1+oin−2],其中;表示cat拼接。
在增强残差连接的情况下,Alignment Layer和fusion layer的输入分为三部分:原始点特征(嵌入向量)、先前模块的对齐特征(残差特征)和上下文特征。
Alignment Layer
对齐层:对两个序列作token上的对齐。
令 a = ( a 1 , a 2 , … , a l ) a = (a_1, a_2,\dots,a_l) a=(a1,a2,…,al), b = ( b 1 , b 2 , … , b l ) b = (b_1, b_2,\dots,b_l) b=(b1,b2,…,bl)
那么 a i a_i ai和 b j b_j bj之间的相似度得分为 e i j e_{ij} eij,即:
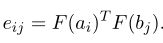
其中F为单一函数或单层前馈层。那么对齐层的输出为: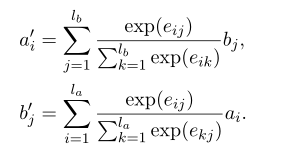
Fusion Layer
融合层利用三个角度来比较局部和对齐表示,然后将其融合在一起。其计算方式为:
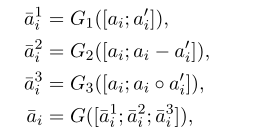
其中所有的G为单层前馈层。b与a运算一致
Prediction Layer
在池化层利用最大池化得到句子a和b对应的两个向量: v 1 v_1 v1和 v 2 v_2 v2。然后其预测方式为:
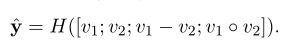
其中H表示多层前馈网络。
在诸如释义识别等对称任务中,其计算方式为:
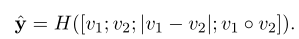
此外,简化版的预测方式:
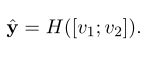
注:对于分类任务,利用softmax函数进行概率预测;对于回归任务,利用MSE损失函数进行优化。