一、oracle课程介绍
Oracle是当今世界最强大的数据库软件。
二、oracle安装
准备安装程序 Oracle 10g setup.exe
1、oracle的启动
三种方式:
1、计算机管理工具——服务——打开oracle相关服务配置。
2、将一下脚本程序更改为.bat文件
Sc start”OracleOraDb10g_home1iSQL*Plus”
Sc start”OracleOraDb10g_home1TNSListener”
Sc start”OracleServiceORCL”
3、在dos命令窗口执行命令
C:\lsnrctl start
C:\net start OracleServiceORCL
2、服务别名设置
二种方式:
1、使用Net Manager工具———新建服务别名
2、修改配置文件为
C:\oracle\product\10.2.0\db_1\network\ADMINtnsnames.ora
3、sqlplus登陆方法
系统用户登陆
Sqlplus username/password@serviceName as sysdba
普通用户登录
Sqlplus username/password@serviceName
说明:service是服务实例名SID,可以连接本机也可以连接远程服务器。
远程登录
Sqlplus username/password@serviceName(orcl2) as sysdba
Sqlplus user/password@192.168.1.155/orcl
例:
服务实例名orcl2——主机192.168.1.155/orcl
4、sqlplus常用命令
Show user ----------------常看当前连接用户
Connect scott/tiger-------采用用户scott连接数据库
Desc 表名----------------查看表结构
Quit/exit-------------------退出
Disconnect----------------断开连接
Clear screen--------------清屏
Select * from tab--------查看当前用户所有表
@path---------------------执行path指定的脚本文件
5、用户锁定与解锁
锁定用户
Alter user 用户名 account lock;
解锁用户
Alter user 用户名 account unlock;
三、简单查询
Select * from emp;
Select empno,ename,sal form emp ;
去重复:
select distinct job from emp;
四、条件查询
1、逻辑运算符
Or----------取交集
And--------取并集
Not---------取反
优先顺序:
Not>and>or
2、Between and
例:
select * from emp where sal between 1500 and 3000;
3、字符串的比较
Select * from emp where ename = “SMITH”;
注:列值区分大小写。
4、in、not in
Select * from emp where empno in(7369,7788,7621);
Select * from emp where deptno not in(10,20);
5、Like 模糊查询
‘_’ 匹配一个字符
‘%’匹配0或多个字符
例:
select * from emp where ename like’_a%’;
Select * from emp where empno like ‘%22%’;
6、order by 排序
Asc 升序(默认)
Desc 降序
例:
Select * from emp where sal>=1500 order by sal;
Select * from emp where sal>=1500 order by sal desc,hiredate asc;
五、列函数与分组
1、常用列函数
Sum()---------求和
Max()---------求最大值
Min()---------求最小值
Avg()---------求平均值
Count()-------统计记录数
Count(distinct)-----去重复统计
例:
select count(*),sum(sal),min(sal),max(sal) from emp ;
Select sum(sal)+sum(comm)from emp;
2、group up 分组
语法(书写顺序):
Select .... From ......where....group by.....having.....order by
注:如果在select语句中出现不在列函数中的列,则该列一定要出现在group by 之后。
例:
Select deptno,avg(sal) from emp where deptno in(10,20) group by deptno having avg(sal)>2000 order by avg(sal);
六、标量函数
1、字符函数的使用
转换为大写字母
Select upper(‘smith’) from emp;
转换为大写字母
Select lower(‘SMITH’)from emp;
首字母大写
Select initcap(‘hello word’) from dual;
连接字符串
Select concat(‘hello’,’world’) from dual;
Select ‘hello’||’world’||’hello’ from dual;
注:concat不如 || 好用,一般用 || 连接。
2、字符函数的使用
求子串
Select empno,substr(ename,1,3) from emp;
截取时从0开始和从1开始效果一样。
Select ename,substr(ename,-3) from emp;
效果为显示姓名和姓名后三位字符。
求长度
Select length(ename) from emp;
串替换
Select replace (‘hello world’,’wor’,’wel’) from emo;
效果是将hello world 中 wor 换成 wel
3、数值函数的使用
四舍五入
Select round(789.536) from dual; ——取整数
Select round(789.536,2) from dual;——取小数点后2位
Select round(789.536,-2)from dual;——取小数点前2位
截断小数位
Select trunc(789.536) from dual;——截取整数
Select trunc(789.536,2) from dual;——截取小数点后2位
Select trunc(789.536,-2)from dual;——截取小数点前2位
取余数
Select mod(10,3) from dual;——取余数 10/3
4、日期函数的使用
运算规律
日期+数字=日期
日期-数字=日期
日期-日期=数字(天数)
查看当前日期
Select sysdate from dual;
显示部门编号为10的部门员工的入职星期数
Select empno,ename,round((sysdate-hiredate)/7) from emp where deptno=10;
在当前日期加上4个月后的日期
Select add_months(sysdate,4) from dual;
求给定日期范围的月数
Select empno,ename,months_between(sysdate-hiredate) from emp;
求当前日期的下一个给定日期是哪个日期
Select next_day(sysdate,’星期一’)from dual;
求出给定日期所在月份的最后一天日期
Select last_day(sysdate) from dual;
七、转换函数
1、to_char(可设置格式)
Select empno,ename,to_char(hiredate,’fmyyyy-mm-dd’) from emp;
注:使用fm去掉前导0
select empno,ename,to_char(sal,’$999999’)from emp;
注:9代表以为数字,$代表美元
2、to_number
Select to_number(‘123’)+to_number(‘123’) from dual;
3、To_date
Select to_date(2009-12-12’,’yyyy-mm-dd’) from dual;
4、nvl()
Select empno,ename,(sal+nvl(comm,0)) from emp;
注:nvl(comm,0) 效果为当comm为null时,相当于0
八、连接查询
1、自连接
为表命别名
查询员工姓名和上级领导姓名
Select e.ename,m.ename from emp e,emp m where e.mgr=m.empno;
2、多表关联
查询每个员工姓名,工资,工资等级,部门名称,领导姓名,领导工资等级
Select e.ename,e.sal,d.dname,s.grade,m.ename,ss.grade from emp e,emp m,dept d,salgrade s,salgrade ss where e.deptno=d.deptno and e.mgr=m.empno and e.sal between s.losal and s.hisal and m.sal between ss.losal and ss.hisal;
3、左右外连接
Select e.ename,d.deptno,d.dname from emp e ,dept d where e.deptno(+)=d.deptno;
注:(+)在左边表示右连接,会列出右表中出现但是没有出现在左表中的行
4、全连接
左连接与右连接的合体
Select * from emp full join dept;
5、交叉连接(用来产生笛卡尔积)
Select * from emp cross join dept;
6、自然连接
Select * from emp natural join dept;
九、子查询
1、where中子查询
查询工资比7654员工少的全部雇员信息
Select * from emp where sal>(select sal from emp where empno=7654);
2、from中子查询
查询在部门20、30中工资大于2000的员工
Select * from (select * from emp where deptno in(20,30)) where sal>2000;
3、in、any、all的使用
查询和SMITH或JONES在同一部门。同一职位工作的员工
Select * from emp where(deptno,job) in(select deptno,job from emp where ename in(‘SMITH’,’JONES’));
注:=any 与 in效果一样
>any只要大于子查询中任意一个值即可
<any 只要小于子查询中任意一个值即可
Select * from emp where(deptno,job) =any(select deptno,job from emp where ename =any(‘SMITH’,’JONES’));
Select * from emp where sal>any(select min(sal)from emp group by deptno);
注:>all 比最大值大 <ALL 比最小值小
4、decode的使用
Decode起判断作用,判断一下查询当sal=9000时,显示为’工资高’,sal=5000时显示为’还可以’,sal=3000时显示为’良好一般’,其余工资显示为’差’
select empno,
ename,
sal,
decode(sal,9000,'工资高',5000,'还可以',3000,'良好',2450,'良好一般','差')
from myemp;
select sum(count(empno)) 总人数,
sum(decode(to_char(hiredate,'yyyy'),1987,count(empno),0)) "1987", sum(decode(to_char(hiredate,'yyyy'),1980,count(empno),0)) "1980", sum(decode(to_char(hiredate,'yyyy'),1982,count(empno),0)) "1982",
sum(decode(to_char(hiredate,'yyyy'),1981,count(empno),0)) "1981"
from emp group by to_char(hiredate,'yyyy')
十、数据插入
1、复制表(备份表)
备份表
Create table myemp as select * from emp ;
注:只复制表结构:
Create table myemp as select * from emp where 1=2;
2、插入
Insert into dept (dname,deptno) values(‘account’,50);
Insert into myemp values(7898,’王五’,’清洁工’,null,’14-2月-1995’,9000,null,40);
Insert into myemp select * from emp;
注:1、若省略字段名则默认给所有字段赋值,且顺序要与表一致。
2、值列表个数、顺序与类型与字段列表相容。
十一、数据更新
1、修改
Update myemp set comm=100 where empno=7788;
注:执行修改操作时一定要使用where条件,否则会修改表中所有记录。
2、删除
Delete from myemp where empno=7788;
注:执行删除操作时,一定要使用where条件,否则会删除表中所有记录。
3、oracle中事务处理
事务提交
Commit
事务回滚
rollback
十二.表
1、oracle中常见的数据类型
Varchar/varchar2 -----------------字符串 最大长度为255
Number ----------number(n)为整数n为长度可以用int、 number(n,m)为小数,整数长度为n小数长度为m可以用float
Date---------------日期类型 必须按照标准日期格式存放
Clob---------------大对象,大文本数据 可以存放4G
Blow--------------大对象,存放二进制数据,如电影、图片、歌曲 可以存放4G
2、创建表
Create table person(
Pid varchar2(20),
Name varchar2(30),
Age number(3),
Birhdate date,
Sex varchar2 default’男’
);
创建表也可以直接复制一个表,在前面已说明。
3、删除表
Drop table 表名称
4、修改表结构
增加一列
Alter table 表名称 add(
列名称 数据类型 default 默认值
);
删除列
Alter table 表名称 drop column 列名称
修改列的数据类型
Alter table 表名称 modify(
列名称 要修改的类型 default 默认值
);
为表重命名
Rename 旧表名 to 新表名
截断表
Truncate table 表名
意义:清空表中所有数据,并且立刻释放资源,操作不可回滚。
十三、约束
1、主键约束
Primary key -------------表示唯一且不为空
例:
Create table person(
Pid varchar2(20) Primary key ,
Name varchar2(30),
Age number(3),
Birhdate date,
Sex varchar2 default’男’
);
2、非空约束
Not null --------------表示字段不能为空,插入时必须插入
例:
Create table person(
Pid varchar2(20) Primary key ,
Name varchar2(30) not null ,
Age number(3),
Birhdate date,
Sex varchar2 default’男’
);
3、唯一约束
Unique ---------------表示唯一不能重复
例:
Create table person(
Pid varchar2(20) Primary key ,
Name varchar2(30) unique ,
Age number(3),
Birhdate date,
Sex varchar2 default’男’
);
4、检查约束
Check------------------判断插入内容是否合法
例:
Create table person(
Pid varchar2(20) Primary key ,
Name varchar2(30),
Age number(3) check(age between 1 and 150) ,
Birhdate date,
Sex varchar2 default’男’
);
5、主外键约束
Primary key
Foreign key
注:在子表中设置的外键必须是父表中的主键,删除时先删除子表,再删除父表,也可以级联删除。
Drop table person cascade constraint
级联删除也可以在建表时(父表)定义:
On delete cascade
6、约束管理
约束名称规范(建议)
Primary key : 表名称_主键名称_pk
Unique : 表名称_字段名称_uk
Check : 表名称_字段名称_ck
增加约束
Alter table 表名称 add constraint 约束名称 约束类型 (约束字段)
例:
Alter table book add constraint book_bid_pk primary key (bid)
删除约束
Alter table 表名称 drop constraint 约束名称
十四、视图与序列
1、伪列的使用
Rownum-----------表示行号,是一个伪列,可以在每一个表中出现。
例:
查询表中记录的前五行
Select * from emp where rownum<=5;
查询表中6到10条记录
Select * from (select rownum num,empno,ename,sal from emp) where num between 6 and 10;
2、视图的优点
1、提高对数据库的访问效率
2、用户通过简单的查询可以从复杂的查询中得到结果。
3、维护数据的独立性,视图可从多个表检索数据。
4、对于相同的数据可产生不同的视图。
3、创建视图
Create view 视图名称 as 子查询
例:
Create view empv20 as select empno,ename,sal,deptno from emp where deptno=20;
注:创建视图时,视图的操作会影响表的操作,这是不安全的,一般创建视图时附加如下选项:
With check option -------------不能更新创建视图的条件
With read only -----------------创建只读视图
4、视图的用法
Select * from 视图名称
5、删除视图
Drop view 视图名称
注:当删除视图所在表时,视图将不能被使用。
6、创建序列
Create sequence 序列名称 参数
例:
Create sequence myseq minvalue 1 maxvalue 100 start with 1 increment by 1 cache 20;
7、序列的常用参数
Maxvalue ----------------------序列的最大值
Nomaxvalue-------------------不设置最大值
Minvalue-----------------------序列的最小值
Nominvalue--------------------不设置最小值
Increment by 1-----------------每次增加1
Start with 1 ---------------------从1开始计数
Cache 10 ------------------------设置缓存10个序列
Nocache--------------------------不设置缓存
Cycle------------------------------到头循环
Nocycle---------------------------一直累加不循环
8、序列的操作
Nextval-----------------------------取序列的下一个内容
Currval-----------------------------取序列当前的内容
例:
Create table testseq(
Next number,
Curr number
);
Insert into testseq values(myseq.nextval.myseq.currval);
9、删除序列
Drop sequence 序列名
十五、表空间与用户
注:在进行响应操作时,应具有相应权限。
1、创建表空间
Create tablespace 表空间名称 datafile ‘数据文件的全路径’ size 表空间大小;
例:
Create tablespace haha datafile’D:\zhuan\haha.dbf’ size 10M;
表空间大小为10M,超出一次增加1M,最大增加到2G
Create tablespace haha datafile’D:\zhuan\haha.dbf’ size 10M autoextend on next 1M maxsize 2G;
增加表空间大小
Alter tablespace 表空间名称 add datafile’全路径的数据文件名称’ size ***M;
2、删除表空间
Drop tablespace 表空间名;
3、用户的创建
Create user 用户名 identified by 密码 account unlock;
4、用户管理
授予连接权限
Grant connect to 用户名;
为用户授予查看scott用户下emp表的权限
Grant select on scott.emp to 用户名
修改用户的默认表空间
Alter user 用户名 default tablespace 表空间名;
修改用户密码
Alter user 用户名 identified by 新密码
锁定用户
Alter user 用户名 account lock;
解锁用户
Alter user 用户名 account unlock;
5、删除用户
Drop user 用户名 cascade
十六、索引
1、索引的优缺点
优点:
可加速连接多个表的查询
可用于实施值得唯一性
缺点:
创建索引需要花费时间
需要额外的存储空间
每次修改数据,索引都要更新
维护索引需要时间和资源,不应创建不频繁使用的索引
2、索引的创建
Create unique index 索引名 on 表名
Unique---------确保索引中没有重复值
例:
Create index dept_ind on dept(dname,deptno,loc);
3、索引的删除
Drop index 索引名
十七、同义词与DBLink
1、同义词的优点
引用对象不需要指出对象的持有者
引用对象不需要指出它所在的数据库
为对象提供另一个名字
2、同义词的创建
Create public synonym 同义词名 for 对象名
Public-------------------代表同义词的类型为公有,否则为私有
例:
Create public synonym emp for scott.emp;
3、同义词的相关实例
创建用户
Create user haha identified by haha fananrong account unlock;
Grant connect to haha;
Grant resource to haha;
创建同义词
Create public synonym emp for scott.emp@orcl;
授权
Grant select on emp to haha;
4、删除同义词
Drop public synonym 同义词名
5、创建DBLink(数据库连接)
Create database link 数据库连接名 connect to 用户名 identified by 密码 using ‘服务名’
例:
Create database link haha connect to scott identified by tiger using ‘server(192.168.1.155/orcl)’
如果创建全局DBLink,必须使用system或sys用户,在database前加public
6、DBLink的使用
Select * from emp@haha;
与同义词一起使用
Create synonym 表同义词名 for 表名@数据库连接名;
Select * from 表同义词名;
7、删除DBLink
Drop public database link 数据库连接名
十八、分区表
1、分区表的优点
增加可用性
维护方便
均衡I/O
改善查询性能
2、范围分区
按序号范围分区:
Create table material_test(
transaction_id number primary key,
Item_id number(8) not null,
transaction_date date not null
);
Partition by range(transaction_id)
(
Partition part_01 values less than(10) tablespace test1,
Partition part_02 values less than(100)tablespace test2,
Partition part_03 values less than(maxvalue) tablespace test3
)
3、hash分区(散列分区)
系统根据一定的算法自动进行分区
Partition by range(transaction_id)
(
Partition part_01 tablespace test1,
Partition part_02 tablespace test2,
Partition part_03 tablespace test3
)
4、列表分区
Create table material_test(
transaction_id number primary key,
Item_id number(8) not null,
transaction_date date not null,
City varchar2(100)
);
Partition by list(city)
(
Partition part_01 values (‘广东’,’沈阳’) tablespace test1,
Partition part_02 values (‘北京’,’上海’)tablespace test2,
Partition part_03 values (‘四川’) tablespace test3
)
希望能够对大家有所帮助,也欢迎大家一起探讨大数据相关的各种疑难杂症问题。---
更多文章关注公众号
oracle入门学习
article/2025/9/29 5:29:34
相关文章
菜鸟教程网oracle,Oracle数据库入门教程 Oracle数据库菜鸟教程
Oracle数据库,可以说是数据库界的老大了。只要你是对数据库感兴趣,或者说是想要从事数据库方面的工作的话,你都需要去了解接触一下oracle数据库的一些知识。但是对于很多刚刚开始学习oracle数据库的朋友来说,想要入门还是需要有一…
Oracle数据库安装教程--Oracle19c DataBase
#注意声明:本文继续留给有需要的Oracle开发学习者使用,作者将不再继续解答Oracle相关的问题。
首先,下载Oracle安装包的压缩文件 访问Oracle官网(https://www.oracle.com/index.html)下的数据库下载地址: …

Oracle数据库教程(一)
目录:导读 一、简介二、数据类型常用数据类型 三、数据定义建表约束 四、数据操纵增加数据删除数据修改数据查询语句数据提交/回退 五、SQL操作符算术操作符比较操作符逻辑操作符连接操作符操作符优先级 一、简介
Oracle 数据库是 Oracle(中文名称叫甲骨…

Oracle数据库安装教程
一、安装前准备
1.在官网下载oracle数据库的安装包。(官方下载地址为:https://www.oracle.com/database/technologies/oracle-database-software-downloads.html) 2.需要注意的是下载安装包时File1和File2都需要下载。下载会出现登录界面&am…

Oracle数据库基础入门
Oracle数据库基础入门
一,了解Oracle数据库
1.1 什么是数据库
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库
1.2 常见的数据库
Oracle,MySQL,DB2,SQLserver等
1.3 DBMS数据库管理系统
数据库管理系统(Data…
oracle数据库菜鸟入门
所有应用软件之中,数据库可能是最复杂的。
MySQL的手册有3000多页,PostgreSQL的手册有2000多页,Oracle的手册更是比它们相加还要厚。 但是,自己写一个最简单的数据库,做起来并不难。Reddit上面有一个帖子,…
Oracle 学习(一)入门
一、学习目标
Oracle介绍Oracle安装Oracle体系结构Oracle与PL/SQL是什么关系DML、DQL、DCL、DDL基本查询条件查询单行函数多行函数
二、Oracle介绍
Oracle :关系型的数据库 , 端口号:1521 ,收费(学习是免费的&#…

oracle入门教程
推荐一个Oracle入门学习教程
点击下面链接进入自学网站 学习网站:http://www.51zxw.net/study.asp?vip16229363
点击图片箭头所指按钮——请点击进入学习 在下面方框里面搜索Oracle 第一个搜索结果就是小姐姐Oracle视频讲解课程 入门教程部分
永久表空间 存储数据库中需要永…

Oracle数据库 - 安装教程
前言:初次使用Orcale,安装并使用自己感觉好痛苦,不断试错,经验分享,少走弯路 一天阅读上百个网页是小事
下载
官网:项目客户要求Oracle Database 19c Enterprise Edition 19.3.0.0.0 (自己用建…
在Windows 10系统下安装Oracle 11g数据库
1.准备工作
(1)去官网https://www.oracle.com下载Oracle数据库,具体操作看图:
①把官网设置为中文
②找到专门下载数据库专栏
③详细下载过程,本次安装Oracle 11g(32位)数据库,数据库多少位数都可以,也就是说3…

Oracle数据库入门教程(作者原创)
文章目录 Oracle 是什么常规命令基础表查询SQL基础,约束,表关系表之间的关系SQL语言基础Oracle简单查询语句函数及分组Oracle高级查询语句最后 Oracle 是什么 Oracle系统,即是以Oracle关系数据库为数据存储和管理作为构架基础,构建出的数据库…
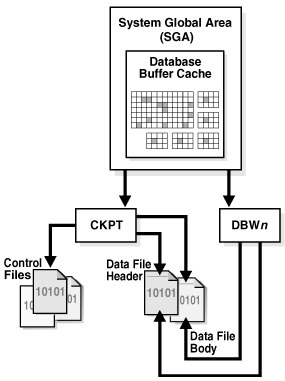
Oracle数据库教程
原文连接:https://www.w3cschool.cn/oraclejc/oraclejc-eswu2qqq.html Oracle数据库教程 Oracle数据库是什么?数据文件(dbf)表空间用户 数据库和实例1 Oracle数据库1.1 物理存储结构1.2 逻辑结构 2 Oracle实例主要的Oracle数据库的…

Rational Rose
rational Rose 是一种建模工具,它可以在Rose建模中提供建立、视图、修改和操作组件的能力。 Rose 运行环境。 ——windows NT ,Windows 95 ——UNIX(Solaris ,HP/UX ,ALX ,DEC Unix) Rose 支持Unified,Booch ,OMT标记法 …

Rational Rose 使用技巧
1、浏览区 2、菜单项 其中Format选项中: 决定各项是否显示,也可以通过右击—option选择 3、常用快捷键: F1:任何时候都可以按F1获得相关帮助,把鼠标放在某条菜单上按F1可以获得这条菜单的相关帮助。 F2:刷新…

安装rational rose软件教程
一、下载相关文件 二、安装DAEMON Tools Lite
按照正常的安装流程开始安装 路径选择自己想要的路径,直到弹出许可证选择同意就好了。 三、安装rational rose
打开DAEMON Tools Lite软件,并点击“快速装载” 然后选择rational rose的映像文件 在下方就…

使用Rational Rose绘制各种图
发生了一件事:论文中需要绘制几种图
我感觉:以前没有学好也没有太大的关系,现在用中学自己需要的部分,效率特别高。我不反对以后会有用的这句话,但相比于眼前就有用或是未来肯定有用的,我自然优先选择后者…

Rational Rose 7.0安装及科学使用教程
Rational Rose 7.0科学的使用 Rational Rose 7.0安装及科学使用教程下载安装挂载镜像准备安装开始安装前序工作正式安装安装完毕 Rational Rose 7.0安装及科学使用教程 Rational Rose是Rational公司出品的一种面向对象的统一建模语言的可视化建模工具。用于可视化建模和公司级水…

Rational Rose2007的安装
UML:统一建模语言(Unified Modeling Language,UML)是一种为面向对象系统的产品进行说明、可视化和编制文档的一种标准语言,是非专利的第三代建模和规约语言。UML是面向对象设计的建模工具,独立于任何具体程序设计语言。 我们用rational rose2…
Rational rose 2007 下载和安装教程
文章目录 Rational rose 简介一,下载Rational rose 2007二,安装Rational rose 2007三,激活Rational Rose 2007四,启动Rational Rose 2007 Rational rose 简介
Rational Rose是Rational公司出品的一种面向对象的统一建模语言的可视…

我遇到了Rational Rose
前言 学到了UML,在视频中提到了Rational Rose这个工具,对它很感兴趣,想知道它到底是什么东西,所以也就找同学拷了这个安装包,但是安装的时候它提示我这个一个病毒软件,所以就只能把它卸载了。后来就又找同学…