文章目录
- 一、前言
- 二、GaussDB中的定义
- 三、存储过程的使用场景
- 四、存储过程的使用优缺点
- 五、存储过程的示例及示例解析
- 1、GaussDB存储过程语法格式
- 2、GaussDB存储过程语法示例
- 3、存储过程的调用方法
- 七、总结
一、前言
华为云数据库GaussDB是一款高性能、高安全性的云原生数据库,在数据库领域处于领先地位。而在GaussDB中,存储过程是一个不容忽视的重要功能。本文将深入介绍GaussDB存储过程的使用场景、使用优缺点、示例及示例解析、调用方法等方面,为读者提供全方位的指导与帮助。
存储过程是一个可重用的、批处理的SQL语句代码块,可以包含多条SQL语句,通常用于执行复杂的数据操作、提高数据库的性能和安全性,以及简化数据库应用程序的开发和维护。在GaussDB中,存储过程的使用可以使数据库应用程序更具灵活性、数据完整性更高、执行速度更快。
二、GaussDB中的定义
商业规则和业务逻辑可以通过程序存储在GaussDB中,这个程序就是存储过程。 存储过程是SQL、PL/SQL、Java语句的组合。存储过程使执行商业规则的代码可以从应用程序中移动到数据库。从而,代码存储一次能够被多个程序使用。
三、存储过程的使用场景
存储过程是一种储存在数据库中的预编译的程序,它被定义为一系列的SQL语句,并且被用来执行一系列的数据库操作。在实际运用中,存储过程可以提高性能、提高开发效率,同时也具备良好的安全性能。
1、下面列举几个存储过程的适用场景
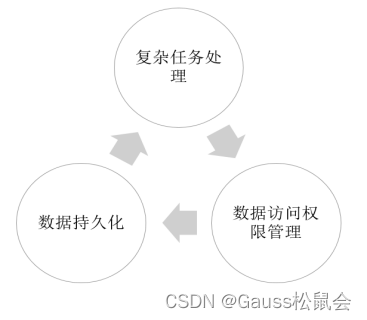
- 复杂任务处理:存储过程可以用于一些需要处理复杂任务的场景,例如一个较为复杂的SQL语句,需要处理多个条件和大量的数据,使用存储过程可以提高效率。
- 数据持久化:存储过程可以在服务器端创建和存储处理逻辑,而客户端通过调用存储过程即可处理需要的数据。
- 数据访问权限管理:存储过程可以通过设置不同的访问权限来提高数据访问的安全性。
2、存储过程特点: - 频繁的、重复性、可封装、易管理。
- 复杂的数据事务处理,可以使用存储过程实现事务的一致性和数据完整性,同时提高执行效率。
- 对于常用的查询,可以把它们封装成存储过程,并将其缓存到内存中,在每次执行时,不需要从磁盘中读取数据,提高查询速度。
四、存储过程的使用优缺点
在使用存储过程时,我们需要充分了解其使用优缺点,从而在实际开发过程中进行有针对性的选择,下面罗列了一些常见的存储过程的使用优缺点。
1、优点:高效率、可复用、可维护
- 在执行大量的操作时,存储过程可以减少数据库客户端与数据库的通信次数,从而提高了执行效率。
- 在多次使用同一函数时,存储过程所需要的内存资源和CPU时间较少,因此,存储过程可以被看作一种可复用的数据库对象。
- 在维护和升级方面,存储过程具有良好的维护性,可以被视为一种良好的API,简化系统的维护过程。
- 存储过程的安全性和可维护性更高,减少了数据库维护的工作量。
2、缺点:难度较高、对数据库依赖性强 - 存储过程需要使用专门的SQL软件进行开发,所以对开发人员的技能水平要求比较高,并且使用错误可能会抛出不可预知的异常。
- 存储过程涉及到多个数据库对象,使用不当有可能产生不可预知的结果。当数据库结构发生变化时,存储过程也需要进行相应调整,因此,存储过程对数据库的依赖性比较强。
- 开发和维护存储过程需要一定的技术水平,对于小型数据库来说,使用存储过程的必要性较小。
- 存储过程的执行需要对存储过程进行编译,对于频繁修改的存储过程,可能会影响数据库的性能。
五、存储过程的示例及示例解析
1、GaussDB存储过程语法格式
CREATE [ OR REPLACE ] PROCEDURE procedure_name[ ( {[ argname ] [ argmode ] argtype [ { DEFAULT | := | = } expression ]}[,...]) ][{ IMMUTABLE | STABLE | VOLATILE }| { SHIPPABLE | NOT SHIPPABLE }| {PACKAGE}| [ NOT ] LEAKPROOF| { CALLED ON NULL INPUT | RETURNS NULL ON NULL INPUT | STRICT }| {[ EXTERNAL ] SECURITY INVOKER | [ EXTERNAL ] SECURITY DEFINER | AUTHID DEFINER | AUTHID CURRENT_USER}| COST execution_cost| SET configuration_parameter { [ TO | = ] value | FROM CURRENT }][ ... ]{ IS | AS }
plsql_body
/
–说明:定义存储过程,在SQL语句末,需要输入“/” (执行)。
参数说明
•OR REPLACE
当存在同名的存储过程时,替换原来的定义。
•procedure_name
创建的存储过程名称,可以带有模式名。 取值范围:字符串,要符合标识符的命名规范。
•argmode
参数的模式。 须知:VARIADIC用于声明数组类型的参数。 取值范围: IN,OUT,INOUT或VARIADIC。缺省值是IN。只有OUT模式的参数后面能跟VARIADIC。并且OUT和INOUT模式的参数不能用在RETURNS TABLE的过程定义中。
•argname
参数的名称。 取值范围:字符串,要符合标识符的命名规范。
•argtype
参数的数据类型。可以使用%ROWTYPE间接引用表的类型,或者使用%TYPE间接引用表或复合类型中某一列的类型。 取值范围:可用的数据类型。
•IMMUTABLE、STABLE等
行为约束可选项。各参数的功能与CREATE FUNCTION类似,详细说明见CREATE FUNCTION
•plsql_body
PL/SQL存储过程体。 须知:当在存储过程体中进行创建用户等涉及用户密码相关操作时,系统表及csv日志中会记录密码的明文。因此不建议用户在存储过程体中进行涉及用户密码的相关操作。
说明:argname和argmode的顺序没有严格要求,推荐按照argname、argmode、argtype的顺序使用。
2、GaussDB存储过程语法示例
我们来看几个具有代表性的GaussDB数据库存储过程示例,以进一步了解其编写和使用方式。
示例一:
下面是一个简单的GaussDB存储过程示例:
–创建一个存储过程。
CREATE OR REPLACE PROCEDURE prc_add
(param1 IN INTEGER,param2 IN OUT INTEGER
)
AS
BEGINparam2:= param1 + param2;dbe_output.print_line('result is: '||to_char(param2));
END;
/–调用此存储过程。
SELECT prc_add(2,3);
–删除存储过程
DROP PROCEDURE prc_add;
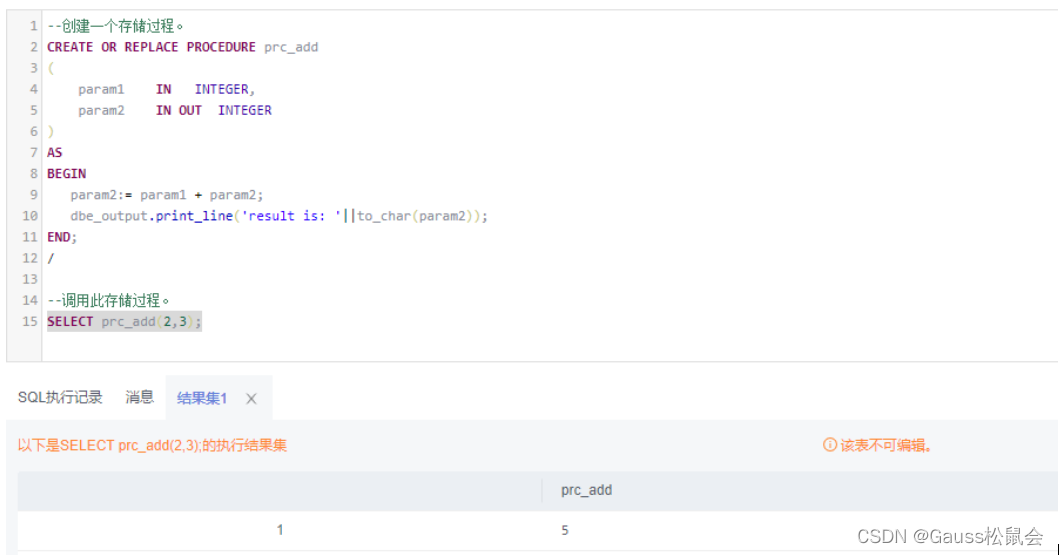
解析:上面的代码是创建了一个名为prc_add的存储过程,该存储过程有两个参数,一个输入参数param1和一个输入/输出参数param2,数据类型均为整型(INTEGER)。 在存储过程的主体中,对输入/输出参数param2进行了修改,将其值赋为param1 + param2。在调用存储过程时,输入2作为输入参数param1的值,3作为输入/输出参数param2的值。最后,存储过程的结果输出到dbe_output控制台,显示“result is: 5”。
总的来说,这个存储过程的功能是将输入参数param1与输入/输出参数param2的值相加,并将相加后的结果输出。它可以在程序中多次使用,以简化代码。
示例二
–创建一个存储过程,将带着调用它的用户的权限执行。
CREATE TABLE tb1(a integer);
CREATE OR REPLACE PROCEDURE insert_data(v integer)
SECURITY INVOKER
AS
BEGININSERT INTO tb1 VALUES(v);
END;
/
–调用此存储过程。
CALL insert_data(123);
–查看结果
select * from tb1;
–删除存储过程
DROP PROCEDURE insert_data;
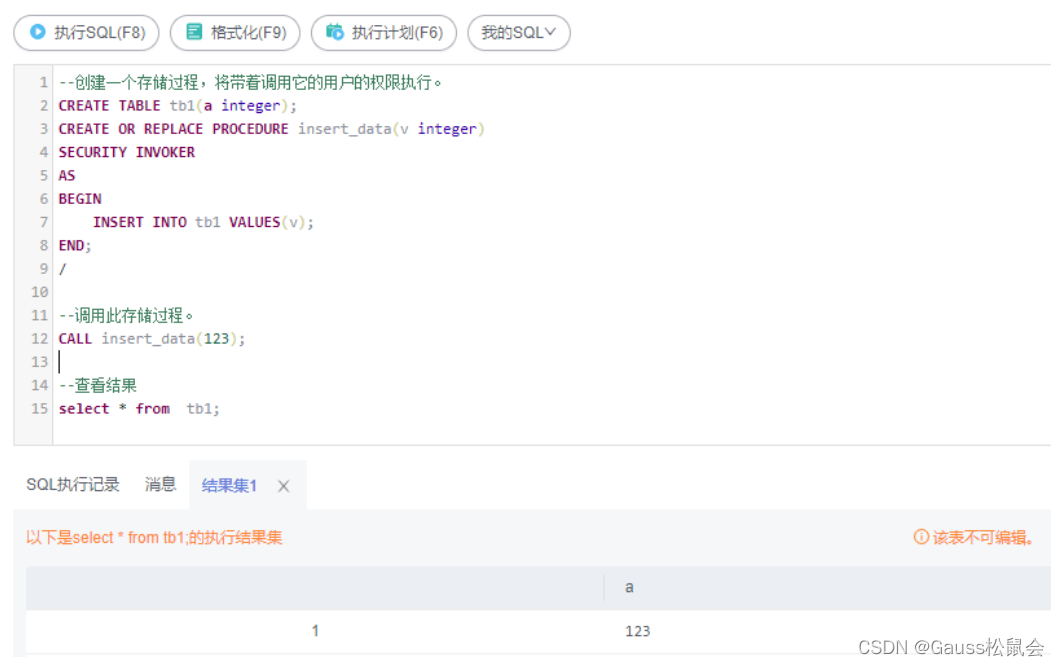
解析:上述代码实际上创建了一个带有一个输入参数的存储过程insert_data,并将其定义为以调用者的权限来运行。当调用该存储过程时,将传递一个整数参数作为输入,该参数将插入一个新行到tb1表中,该新行的值为该整数。然后通过执行select语句查看tb1表中的所有数据行。执行完整段代码后,将看到只有一行数据,该行的值为123,这是由insert_data存储过程插入的。
3、存储过程的调用方法
存储过程的调用方法主要有两种:通过客户端请求调用和通过触发器自动调用。通过客户端请求调用通常是手动调用,通常使用以下两种方法调用存储过程:
1)CALL语句
CALL stored_procedure_name(…)
2)SELECT语句
SELECT stored_procedure_name(…)
通过触发器自动调用通常是在特定操作的情况下自动执行存储过程。例如,当插入一条记录时,可以设置触发器来自动执行存储过程。
七、总结
本文详细介绍了GaussDB存储过程的使用场景、使用优缺点、示例及示例解析、调用方法等内容。使用存储过程可以提高效率、可维护性,同时具备良好的安全性能。在使用存储过程之前,我们需要充分了解其使用优缺点,从而在实际开发过程中进行有针对性的选择。只有深入了解GaussDB的存储过程的使用方法和技巧,才能在开发过程中得心应手,更好地配合GaussDB实现高效的数据管理和业务处理。
对于需要频繁重复执行的SQL语句,我们可以将其封装成一个存储过程,方便管理和提高效率。当存储过程执行达到一定规模时,我们需要注意存储过程的维护和优化,以确保存储过程的执行性能。作为一个高可靠性的全球化分布式关系型数据库,华为云数据库GaussDB提供了丰富的存储过程支持,为存储过程的开发、管理和执行提供了更多的优化策略和高可用性保障。
本次介绍就到此,欢迎大家测试、交流!