站在巨人_啊哈、zstu_翊、lengye7、黑夜路人的肩膀上~
分析数据前,我们需要对数据去重,如何选择和设计文本的去重算法?
常见的去重算法有:余弦夹角算法、欧式距离、Jaccard相似度、最长公共子串、编辑距离等。这些算法是先将两篇文章分别进行分词,得到一系列特征向量,然后计算特征向量之间的距离(可以计算它们之间的欧氏距离、海明距离或者夹角余弦等等),从而通过距离的大小来判断两篇文章的相似度。这些算法对于数据量小的文本还比较好用,我们如何对于这些海量千万级的数据进行高效的合并去重?
sim哈希算法原理
参考论文:Similarity estimation techniques from rounding algorithms,论文分为以下几部分,如下图所示:
1. 分词。 去停用词后,为每个词加上tf-idf权重。我们假设权重分为5个级别(1~5)。
例如:“ 美国“51区”雇员称内部有9架飞碟,曾看见灰色外星人 ” ==> 分词后为 “ 美国(4) 51区(5) 雇员(3) 称(1) 内部(2) 有(1) 9架(3) 飞碟(5) 曾(1) 看见(3) 灰色(4) 外星人(5)”,括号里是代表单词在整个句子里重要程度,数字越大越重要。
2. 哈希算法。 每个词通过hash函数生成固定位数二进制哈希值,要把文章变为数字计算才能提高相似度计算性能。
例如:“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为 101011。
3. 加权。 根据步骤2哈希算法生成的结果,按照单词的权重形成加权数字串。
例如:“美国(4)”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”;“51区(5)”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。
4. 合并。 分别把单个句子每个词的序列值累加生成对应的一个序列串。
例如:将步骤3中每个单词的序列值相加,结果为“17 -17 1 -1 1 17”。
5. 降维。 将步骤4单个句子生成的序列串变成0-1串,形成我们最终的simhash签名值。大于0 记为 1,小于0 记为 0。
例如:将步骤4中结果转换为“1 0 1 0 1 1”。

图1 sim哈希的计算过程
sim哈希算法应用
每篇文档得到Sim哈希签名值后,接着计算两个签名的海明距离即可。根据经验值,对64位的Sim哈希值,海明距离在3以内的可认为相似度比较高。
- 海明距离的求法:异或,同0异1。两个二进制数“异或”后得到1的个数,即为海明距离的大小。
具体操作:
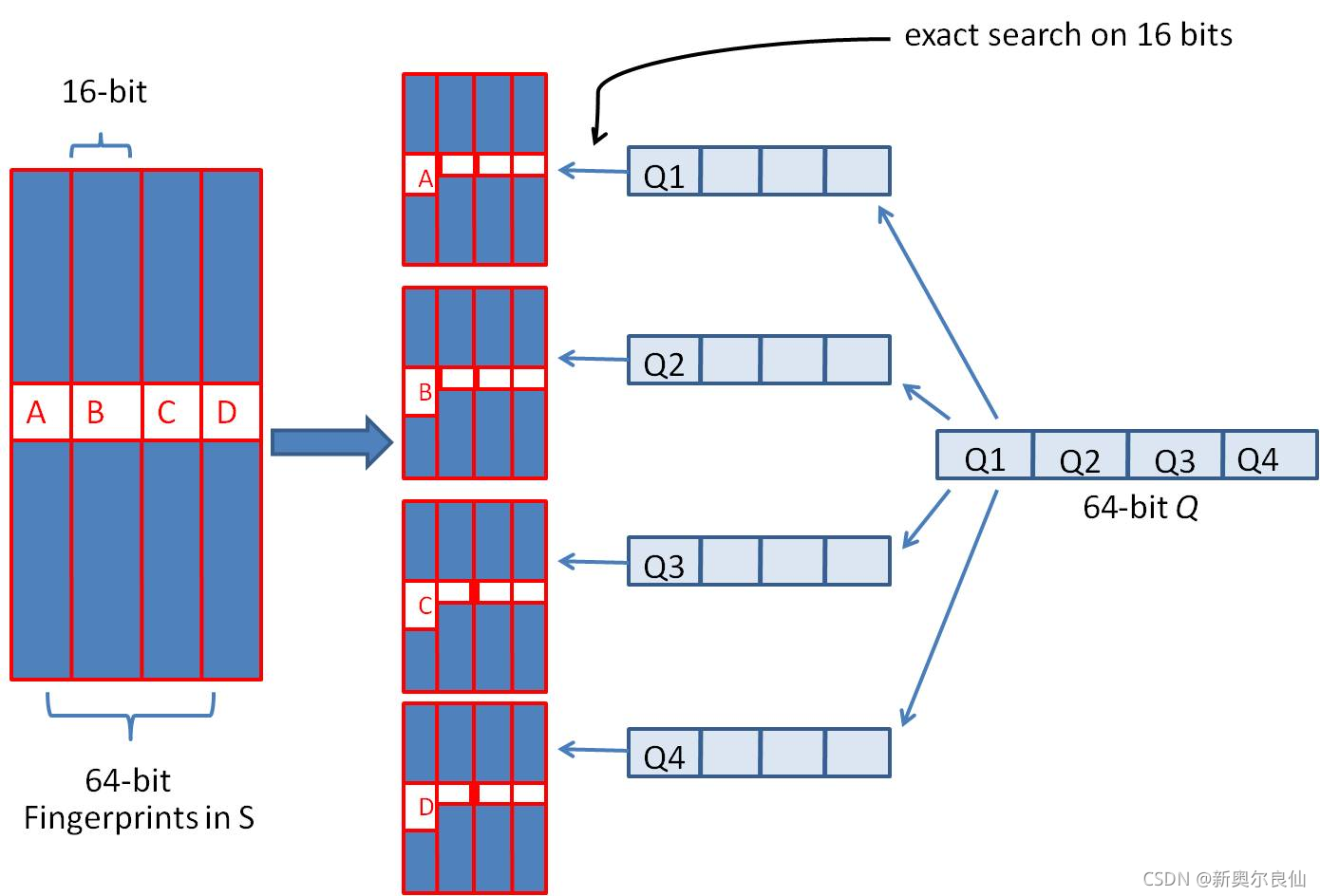
- 我们可以把 64 位的二进制simhash签名均分成4块,每块16位。根据鸽巢原理(也称抽屉原理),如果两个签名的海明距离在 3 以内,它们必有一块完全相同。如下图所示:

- 把分成的4 块中的每一个块(即16位)分别作为前16位,生成四份table来进行查找。
- 采用精确匹配的方式查找前16位
- 如果样本库中存有234(差不多10亿)的哈希指纹,则每个table返回2(34-16)=262144个候选结果,大大减少了海明距离的计算成本。