最近写产品用到了sqlite3作为单机数据库,碰到一个挺有意思的问题。需求大体是两张表,查询需要连表查询,更新也需要连表更新;总共只有几百条数据,但运行过程中出现明显的超时和异常,以为是sqlite有问题,但想想觉得不可能,不至于扛不住几百条数据的并发查询,后来发现似乎是因为sqlite的锁是个库级别的完全单线程锁引起的。
代码是用go写的,model部分如下:
package maintype App struct {Id int `gorm:"id;primary_key"`Name string `gorm:"name"`UpdateAt int64 `gorm:"updateAt"`
}type Task struct {Id int `gorm:"id;primary_key"`Name string `gorm:"name"`AppId int `gorm:"appId"`AppName string `gorm:"-"`updateAt int64 `gorm:"updateAt"`
}
其中 task表的AppName字段需要去app表查询,通过appId作为外键。
为了对比,这里同时使用mysql和sqlite作为数据库。
如果单纯查询,两种数据库都没有问题:
package mainimport ("fmt""github.com/jinzhu/gorm"_ "github.com/jinzhu/gorm/dialects/mysql"_ "github.com/jinzhu/gorm/dialects/sqlite""time"
)func main(){count := 0flag := 3for i:=0;i < flag;i++ {go func(name string) {sqliteSearch(name)count++}("sqlite")}for ;count < flag; {time.Sleep(time.Second)}
}func mysqlSearch(name string){fmt.Println(name)conn,err := gorm.Open("mysql","root:root@tcp(localhost:3306)/test?charset=utf8&parseTime=True&loc=Local")if err != nil {fmt.Println(err)return}defer conn.Close()tasks,err := search(conn)if err != nil{fmt.Println(err)return}p(tasks)
}func sqliteSearch(name string){fmt.Println(name)conn,err := gorm.Open("sqlite3","D:\\code\\go\\learning\\src\\main\\db.db")if err != nil {fmt.Println(err)return}defer conn.Close()tasks,err := search(conn)if err != nil{fmt.Println(err)return}p(tasks)
}func p(tasks []*Task){for _,task := range tasks{fmt.Println(task.Id,task.Name,task.AppName)}
}func updateApp(conn *gorm.DB,task *Task) error {appId := task.AppIdapp := &App{}err := conn.Table("app").Where("id = ?",appId).Find(app).Errorif err != nil{return err}task.AppName = app.Namereturn nil
}func search(db *gorm.DB) ([]*Task,error){tasks := make([]*Task,0)rows,err := db.Table("app").Raw("select id,name,appId from task").Rows()if err != nil{return nil,err}defer rows.Close()for rows.Next(){task := &Task{}err = rows.Scan(&task.Id,&task.Name,&task.AppId)if err != nil{return nil, err}err = updateApp(db,task)if err != nil{return nil, err}tasks = append(tasks,task)}return tasks,err
}
同时开启多个协程去查询表格,数据都可以被正常查出来。
如果在查询过程中有更新或者更新查询同时有,问题就来了:
package mainimport ("fmt""github.com/jinzhu/gorm"_ "github.com/jinzhu/gorm/dialects/mysql"_ "github.com/jinzhu/gorm/dialects/sqlite""time"
)func main(){count := 0flag := 3for i:=0;i < flag;i++ {go func(name string) {sqliteSearch(name)count++}("sqlite")}for ;count < flag; {time.Sleep(time.Second)}
}func mysqlSearch(name string){fmt.Println(name)conn,err := gorm.Open("mysql","root:root@tcp(localhost:3306)/test?charset=utf8&parseTime=True&loc=Local")if err != nil {fmt.Println(err)return}defer conn.Close()tasks,err := search(conn)if err != nil{fmt.Println(err)return}p(tasks)
}func sqliteSearch(name string){fmt.Println(name)conn,err := gorm.Open("sqlite3","D:\\code\\go\\learning\\src\\main\\db.db")if err != nil {fmt.Println(err)return}defer conn.Close()tasks,err := search(conn)if err != nil{fmt.Println(err)return}p(tasks)
}func p(tasks []*Task){for _,task := range tasks{fmt.Println(task.Id,task.Name,task.AppName)}
}func updateApp(conn *gorm.DB,task *Task) error {appId := task.AppIdapp := &App{}err := conn.Table("app").Where("id = ?",appId).Find(app).Errorif err != nil{return err}task.AppName = app.Namereturn nil
}func search(db *gorm.DB) ([]*Task,error){tasks := make([]*Task,0)rows,err := db.Table("app").Raw("select id,name,appId from task").Rows()if err != nil{return nil,err}defer rows.Close()for rows.Next(){task := &Task{}err = rows.Scan(&task.Id,&task.Name,&task.AppId)if err != nil{return nil, err}now := time.Now().Unix() // 这里在查询时更新表格err = db.Table("task").Where("id = ?",task.Id).Update("updateAt",now).Errorif err != nil{return nil, err}err = updateApp(db,task)if err != nil{return nil, err}tasks = append(tasks,task)}return tasks,err
}上面代码在查询时,更新了目标表的updateAt字段,此时就会出现如下报错:
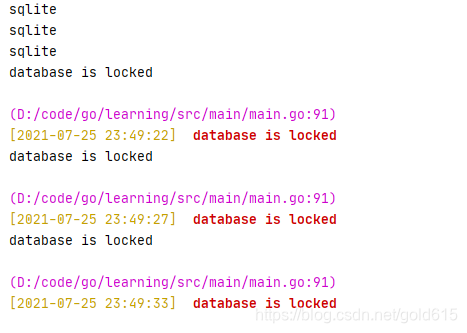
先声明,这个报错mysql是不会出现的。
sqlite只有一把库级别的锁,当多个请求同时执行查询请求时,请求不会被阻塞;但是如果多个写请求发生,就会涉及到对锁的抢夺;如果各个请求都是很明确的读或者写区分开,那么也没什么问题,写请求被sqlite串行执行即可;但如果一个请求中有读有写,就会有问题;上面的代码中,查表时读多条数据,因此需要迭代,我怀疑这里虽然是读,极可能对表加了锁;而在通过appId查询appName时,进行了写操作,此时就造成了死锁;这种情况甚至不是因为多个请求并发引起的,将上面的flag变量改为1,使整个请求只有一条,依然会有锁死的问题。
解决这个问题的方案是访问sqlite时,每次都只进行读或者写操作,不允许同时进行,上面代码改为:
func search(db *gorm.DB) ([]*Task,error){lock.Lock()defer lock.Unlock()tasks := make([]*Task,0)rows,err := db.Table("app").Raw("select id,name,appId from task").Rows()if err != nil{return nil,err}defer rows.Close()for rows.Next(){task := &Task{}err = rows.Scan(&task.Id,&task.Name,&task.AppId)if err != nil{return nil, err}err = updateApp(db,task)if err != nil{return nil, err}tasks = append(tasks,task)}now := time.Now().Unix()for _,task := range tasks {err = db.Table("task").Where("id = ?",task.Id).Update("updateAt",now).Errorif err != nil{return nil, err}}return tasks,err
}
上面有两点注意:
1 引入了锁,限制请求的并发数,这个似乎是必须的,如果不加锁依然会有锁超时的问题;
2 都查询完毕后,再循环对每一条数据进行更新;
这样操作,表锁死的问题就没有了;但代价有点儿高,没法多路写库。
另外查到其它一些方案,但并没有什么用,比如这里 https://blog.csdn.net/weixin_43851310/article/details/100709797 提到的建立连接时设置&_busy_timeout=9999999,使等待锁的时间无限长(默认为5秒,5秒后如果没有轮到锁就会报database is locked错误),但并没什么用,这个仅针对表非常大确实需要比较长时间等待才有用,这里的场景下几百条数据都要等待很久是不科学的;其它方案中还提到,比如忘记Close等,也确实可能引起这个问题,如上面循环查询时,一定要defer rows.Close().